基于CFCC-PCA的说话人辨识方法
2015-09-21刘雪燕袁宝玲
刘雪燕*,李 明,袁宝玲
(1.中山火炬职业技术学院 信息工程系,广东 中山528436;2.兰州理工大学 计算机与通信学院,兰州 730050)
基于CFCC-PCA的说话人辨识方法
刘雪燕1*,李 明2,袁宝玲1
(1.中山火炬职业技术学院 信息工程系,广东 中山528436;2.兰州理工大学 计算机与通信学院,兰州 730050)
针对说话人训练和识别时间长、噪音环境下识别率低的问题,提出一种CFCC-PCA特征参数的说话人辨识方法。首先提取具有听觉特性的CFCC特征参数,然后对其进行PCA变换,找出具有分辨能力的参数,最后再用这些参数在云服务器中训练和识别说话人。实验表明:该方法可以提高说话人辨识的鲁棒性和识别率,云服务可提高系统实时性。
CFCC-PCA;说话人辨识;支持向量机;云服务器
说话人辨识技术因其不容易模仿、随身携带等生物特证优点,在身份识别领域中具有广泛的应用[1]。现有的说话人辨识技术在安静环境下识别率很高,但在噪音环境中识别率低、识别实时性不强,因此不能得到广泛的应用[2-3]。很多学者做了大量的研究来提高实时性和鲁棒性,文献[4]提出耳蜗倒谱系数(Cochlear Filter Cepstral Coefficients,CFCC)的特征参数以提高在噪音环境下的识别率;文献[5]提出将软件能力成熟度模型(Capability Maturity Model,CMM)说话人模型的距离定义为相似度,即将声音类似的说话人聚集为同一类。CFCC特征参数具有很好的抗噪声能力,其性能优于Mel倒谱系数(Mel Cepstrum Coefficients,MFCC),但是其分类能力不强。文献[6]提出高斯混合模型(Gaussian Mixture Model,GMM)是一种概率统计说话人模型,随着注册用户的增多,语音特征参数之间重叠比较严重,系统识别率降低很快。文献[7]指出主成分分析(Principal Component Analysis,PCA)是不需要训练的分类器,直接可由语音特征参数得到,实现比较快速、简单。文献[8]指出支持向量机(Support Vector Machine,SVM)是一种基于结构风险最小化原则的模式识别方法,在处理非线性、高维数样本时具有很大的优势,在基于语音样本的说话人辨识上有良好的效果。本文提出一种融合PCA分类和CFCC特征参数的辨识方法,以提高鲁棒性,并用云服务器训练SVM模型,提高系统实时性。
1 算法
说话人辨识的前期工作有语音信号的录入、语音特征参数的提取、说话人模型的训练等。当进行说话人身份识别时,录入待测语音,系统根据待测语音提取语音特征参数,然后与已经训练好的说话人模型进行匹配,从而确定身份,完成说话人辨识。语音特征参数的提取、说话人模型的训练及匹配都是通过算法来完成,因数据比较大,处理这些数据会花费较多的时间,影响系统的实时性,为减少运算时间,本研究将这些算法搬移到搭建的云服务器中进行。
1.1 耳蜗倒谱系数CFCC
CFCC参数是人耳听觉感知特征,PCA具有很好的分类能力,本实验先提取注册说话人语音的CFCC特征参数,得到分类能力比较好的重构信号。将n个需要注册的说话人描述为s∈(1,n),每一个注册说话人的语音用M段需要训练的语音段)组成,这些语音段反映了注册说话人的不同发音以及语音韵律等特征。根据文献[4]提出的基于听觉变换的CFCC语音特征参数算法,将录入的语音信号,代入CFCC变换公式,得到经过听觉变换的T(a,b):
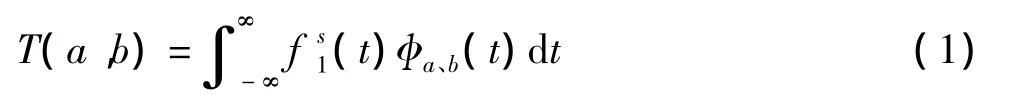
其中:耳蜗滤波函数为:
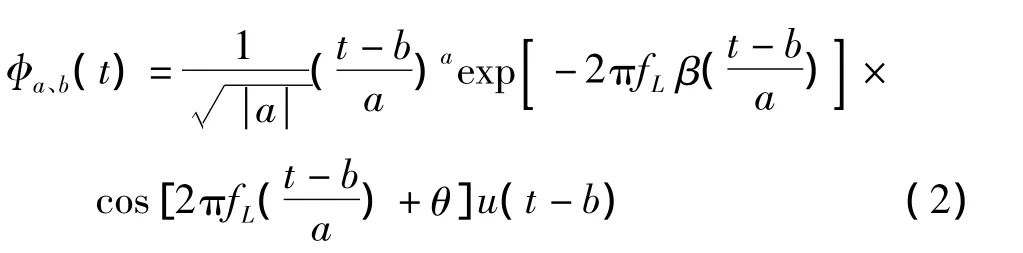
耳蜗滤波函数满足的条件:

其中:α>0;β>0;θ为初始相位,取值满足式(3);u(t)为单位步进函数;b为随时间可变的参数;a=fL/fc为尺度变量,且0<a≤1;fc为最低滤波器组的中心频率;fL为当前要实现滤波器的最低中心频率。
人耳能够听到的声音的频率范围为20 Hz~20 kHz,且对于频率的分辨能力是非均匀的。α和β的取值会影响降噪效果,经多次实验证明:当α=3,β=0.2时,降噪效果良好。由此得到的T(a,b)的频谱变换平滑,没有噪音。下面对T(a,b)进行变换,以得到基于人耳耳蜗的语音。
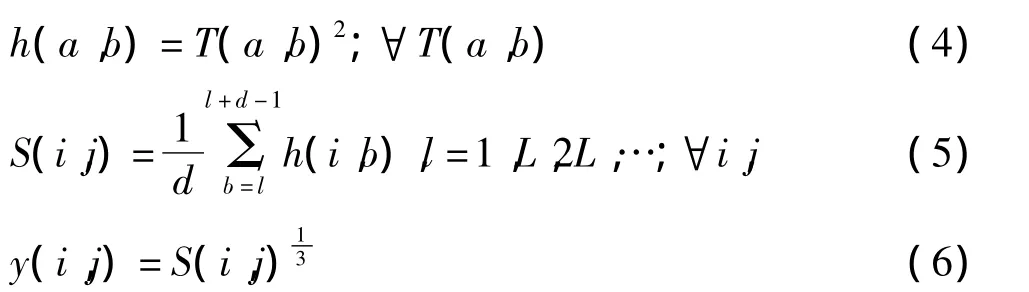
其中:d=max{3.5τi,20 ms};τj=1/fi;L=1/fc=10 ms。
最后将 y(i,j)进行离散余弦变换,从而得到CFCC特征参数:
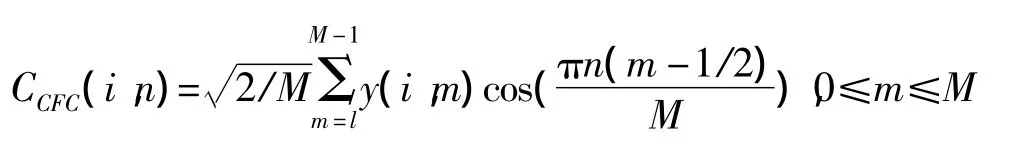
1.2 CFCC-PCA语音特征参数
1)计算语音特征参数矢量的均值向量:
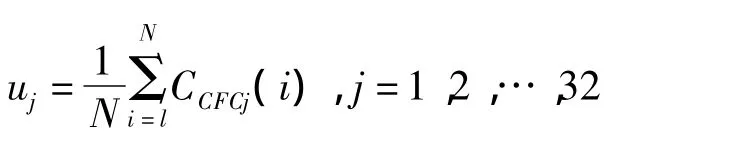
2)计算中心化的语音特征矢量:m'(i)=m(i)-u。
3)计算协方差矩阵:
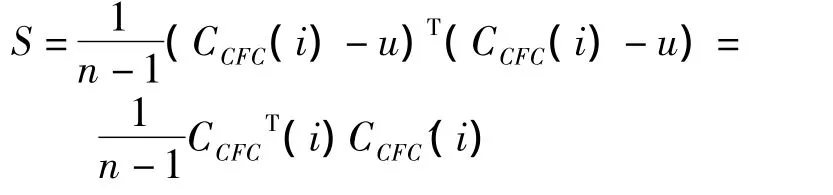
4)计算协方差矩阵的特征值λ1≥λ2≥…≥λ24和对应的特征矢量w1,w2,…,w32,取最具有分辨力的特征向量(特征值最大的前q个)组成变换矩阵W=(w1,w2,…,wq),再由 KL 变换公式得到主成分:Y(i)=WTX'(i),同时保存变换矩阵W,在二次判决中使用。
5)重构语音信号X^(i)=WY(i),得到降低维数和去除噪音后的语音。
1.3 计算平台
云计算平台具有运算能力强、服务虚拟化、安全性好、可靠性高等优点,正被应用于不同的领域[9-10]。Hadoop是一个基于云计算平台框架,可以把大量廉价硬件设备组成云计算集群,并进行大规模的计算。本实验利用Hadoop技术将现有的8台普通计算机和1台普通服务器组合在一起,普通计算机配置2.30 GHz,内存32.0 GB,64位操作系统,服务器配置为Intel Celeron(R)CPU 2.7 GHz。采用MapReduce并行数据处理模型,将语音特征参数的提取、说话人模型的训练及匹配等计算复杂度比较大的3个算法植入Hadoop MapReduce框架。
说话人模型训练:语音数据通过客户端的麦克风输入,然后客户端将语音发送到云服务器,因语音数据参数比较多,参数提取算法、说话人模型的训练算法等计算复杂度比较大,服务器将语音数据分块,存储在各个节点上。然后调用MapReduce编程框架中的CFCC倒谱系数、CFCC-PCA语音特征参数算法,对语音特征参数进行提取,并将提取之后的语音特征参数储存在各个节点,再调用SVM说话人模型训练算法程序,并行训练SVM子模型,从而完成说话人模型的训练。此方法可以节省大量的训练时间。
说话人辨识:将待测语音通过客户端输入,客户端将语音发送到云服务器,在云服务器和各节点提取CFCC-PCA语音特征参数,并与各节点储存SVM说话人子模型进行匹配,完成模式识别后,将识别结果返回客户端。

图1 云服务器说话人辨识模型
2 结果与讨论
2.1 系统的实时性
为检测实验的实时性,分别利用云服务器和普通PC机进行模型训练和识别。第1组:在1.3中描述的计算平台中进行,8台普通计算机和1台普通服务器;第2组:普通客户终端配置为2.30 GHz,内存32.0 GB,64位操作系统。第1组实验时,从客户端录入语音,传送至云服务器,由云服务器将语音数据分到各节点提取参数并训练模型。第2组:语音录入、参数提取、模型的训练和说话人识别都在普通PC机中进行。通过对比可以发现:云计算平台占有绝对优势,如图2、图3所示。
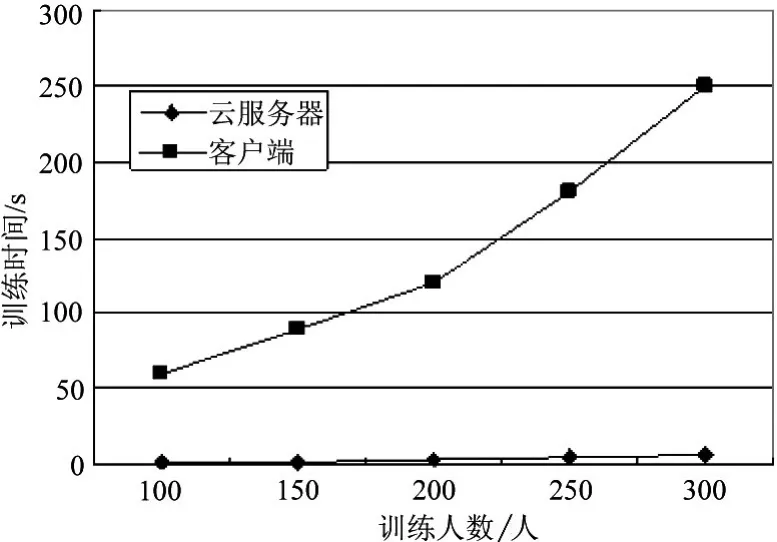
图2 训练时间对比

图3 识别时间对比
2.2 系统的鲁棒性
为检测基于CFCC-PCA特征参数的系统鲁棒性,抽取实验中的100人,分别提取32维的MFCC、LPCC、CFCC-PCA等不同的特征参数,测试在不同高斯白噪音下的正确识别率,测试结果如图4所示。由图4可知:基于CFCC-PCA特征参数的说话人辨识具有较好的鲁棒性。

图4 特征参数在噪音环境下的比较
3 结语
本研究提出基于PCA分类和CFCC听觉特性的特征参数提取方法,用CFCC-PCA特征参数训练说话人模型,并训练和识别说话人都在云服务器中进行,实验表明:CFCC-PCA特征参数具有很好的鲁棒性,而云服务器具有高效的处理能力,提高了识别效率,保证了系统的实时性。
[1]JAIN A K,HONG L,KULKARNI Y A.Multimodal biometric sys-tem using fingerprints,face and speech[C]//2nd Int'l Conferenceon Audio-and Video-based Biometric Person Authentication,Washington D.C.,1999:182-187.
[2]曹洁,余丽珍.改进的说话人聚类初始化和GMM的多说话人识别[J].计算机应用研究,2012,29(2):590-593.
[3]GARAU G,DIELMANN A,BOURLARD H.Audio-visual synchronisation for speaker diarisation[C]//Proc of International Conference on Speech and Language Processing.Makuhari,Chiba:[s n.],2010:2654-2657.
[4]LI Q,HUANG Y.An Auditory-based feature extraction algorithm for robust speaker identification under mismatched conditions[J].Audio,Speech,and Language Processing,IEEE Transactions on,2010,19(6):1791-1801.
[5]TSAIW H,CHHEN S S,WANG H M.Automatic speaker clutering using a voice characteristic reference space and maximum purity estination[J].IEEE Transactions on Audio Speech and Languager Processing,2013,15(4):1461-1471.
[6]LIUM H,XIEY L,YAO Z Q,et al.A new hybrid GMM/SVM for speaker verification[C]//The 18th International Conference on Pattern Recognition,Hong Kong:IEEE Press,2006:314-317.
[7]ZHANG W F,YANG Y C,WU Z H,Exploition PCA classifiers to speaker recognition[C]//Proceddings of the International Joint Conference on the Neural Networks Portland IEEE Press,2003(1):820-823.
[8]BURGES C L C.A tutorial on support vector machines for pattern recognition[J].Data Mining and Knowledge Discovery,1998,2(2):121-167.
[9]GAO Y,JIN L W,HE C,et al.Handwriting character recognition as a service:a new handwriting recognition system based on cloud Computing[C]//Document Analysis and Recognition(ICDAR),2011 International Conference on,2011:885-889.
[10]罗希,刘锦高.基于NIOS的ANN语音识别系统[J].计算机系统应用,2009(12):144-146.
Speaker Identification Based on CFCC-PCA
LIU Xueyan1* ,LI Ming2,YUAN Baoling1
(1.Department of Information Engineering,Zhongshan Torch Polytechnic,Zhongshan 528436,China;2.College of Computer&Communication,Lanzhou University Of Technology,Lanzhou 730050,China)
Training speaker system and speaker identification need a long time,and in the noise environment,the recognition rate is very low,A CFCC-PCA characteristic parameter method is proposed.Firstly,the acoustic characteristics of CFCC characteristic parameters are extracted.Then,
CFCC-PCA parameters are extracted by PCA transformation of CFCC characteristic parameters.Finally the speaker models are trained and recognized in cloud.Experiments show that the CFCC-PCA characteristic parameters can improve the robustness and recognition rate of the speaker,the cloud services with efficient processing ability to improve system real-time performance.
CFCC-PCA;speaker identification;Support Vector Machine(SVM);cloud server
TP391.4
A
2095-5383(2015)02-0032-03
10.13542/j.cnki.51-1747/tn.2015.02.010
2015-03-17
中山市科技发展专项基金项目“基于云计算的生物身份认证技术研究及应用”(2013A3FC0350);中山市科技发展专项基金项目“基于中山地貌的最优化无线网络模型研究”(2013A3FC0318)
刘雪燕(1980— ),女(汉族),河南周口人,讲师,硕士,研究方向:生物身份识别、模式识别,通信作者邮箱:hnqiaolu@163.com。
李明(1959— ),男(汉族),河北辛集人,教授,硕士,研究方向:智能信息处理。
