基于变精度加权平均粗糙度决策树的财务预警研究
2015-07-07鲍新中傅宏宇
鲍新中, 傅宏宇
(北京联合大学 管理学院, 北京 100101)
基于变精度加权平均粗糙度决策树的财务预警研究
鲍新中, 傅宏宇
(北京联合大学 管理学院, 北京 100101)
运用聚类方法把公司财务状况分为5个等级,分别为财务状况健康,良好,一般,预警和危机,与以往将研究样本分为ST和非ST两类的财务预警模型相比,5分类模型更加精确合理,贴近实际。同时基于指标相关性和指标重要度对33个财务指标进行了约简,得到9个能够反映企业财务状况的财务指标。以约简后的9个指标及5个等级的财务状况来建立决策树,指标体系和财务等级更加合理。树的生成过程运用粗糙集中的变精度加权平均粗糙度作为选择测试属性的方法,每次选择变精度加权平均粗糙度值最小的属性作为分支结点。变精度加权平均粗糙度的应用提高了决策树的防噪声能力,复杂性较低且能有效提高分类效果。实证研究表明将它应用到财务预警领域,提高了财务预警的分类精度。
财务危机;聚类分析;决策树;粗糙集
0 引言
企业财务预警模型经历了从统计模型到人工智能模型的发展历程。20世纪末到21世纪初是财务困境预测理论发展的高峰期。除了传统的统计方法之外,以人工智能技术为主的一些具有非线性、分布式运算能力的新方法也被引入到财务困境预测的相关研究中[1~4]。Frydman[5]等首先将决策树引入财务预警研究中,决策树在解决分类问题上具有简单、易于理解并对数据准备要求低等优点。
决策树是一种对大量数据集进行分类的非常有效的方法,通过决策树构造的模型,可以从大量信息中挖掘有效的数据,提取有价值的分类规则,从而获得有用的知识,帮助决策者准确地进行预测。它的基本算法是贪心算法,采用自顶向下的递归方式构造决策树。根据决策树的增长方法,也就是用来测试的属性的选择方法不同,前人提出了很多经典的决策树算法。Quinlan J. R.提出了决策树ID3算法,后来,他又提出了决策树C4.5算法,C4.5继承了ID3算法的所有优点,并且提出了增益比率的概念,通过合并具有连续值的属性,可以根据连续性属性进行分类,还可以处理缺少属性值的训练样本。之后有人在此基础上又提出了SLIQ、SPRINT、CHAID等一些算法,并且把这些方法运用到各个领域。
姚靠华[6]运用决策树进行财务预警的实证研究,应用决策树技术建立了中国上市公司的财务困境预警系统,他们使用差异系数下降最快的分割值作为最佳分割阈值,从而保证了同一组内目标变量的取值有最小的差异性,但作者同样没有对指标之间相关性等进行处理。陈晓红[7]运用CHAID算法对中小企业上市公司财务预警进行了研究,他们把每个类别属性分别与决策变量做交叉分类,产生一系列二维表,然后分别计算他们的卡方统计量,以统计量P值最大的二维表作为最佳初始分类表,并且对结论进行了分析,作者虽然把样本公司的财务状况分为3类,但主观性比较强,没有合理的选择标准。Sangjae Lee[8]运用数据包络分析和决策树方法进行效益分析和B2C控制推介,分为两个步骤对B2C控制进行评价,效率分析与控制推荐。
将粗糙集知识运用到决策树模型中可以有效防止决策树生成过程中的过度拟合的问题,从而提高分类的效果,因此本文将粗糙集理论与决策树理解相结合进行财务预警模型的建立。
1982年Z.Pawlak教授提出了粗糙集理论,运用粗糙集的方法可以对属性进行约简,把粗糙集的知识运用到决策树上,国内外学者提出了很多不同的建树方法并应用到不同领域。赵卫东[9]运用粗糙集知识对决策树进行了优化,通过引入粗糙集理论中可分辨的概念给出一种方法,这种方法通过优化降低了树的高度。蒋芸[10]等人提出了一种基于粗糙集构造决策树的方法,它基于粗糙集的理论提出了加权平均粗糙度的概念,将其作为选择分离属性的标准。高静[11]等人提出了一种新的基于粗糙集模型的决策树算法,引入了抑制因子,有效避免了划分过细的问题。鲍新中[12]将粗糙集理论和聚类方法运用到神经网络的输入输出层建立中,使得财务预警模型更加符合企业实践。Iftikhar U. Sikder和Toshinori Munakata[13]基于粗糙集和决策树对低地震活动前兆因素的描述,他们运用粗糙集和决策树的方法,使用了信息增益和熵产生一系列规则,对地震进行预警。Mu-Yen Chen[14]基于决策树分类算法和逻辑回归算法对公司的财务状况进行预警,他认为利用人工智能模型进行财务预警要优于传统的统计模型。
运用决策树方法形成一系列规则,对训练数据集进行分类,然后根据形成的规则对训练数据集之外的数据进行分类,应用在财务领域,可以对财务进行预警。与传统的财务预警方法将研究样本划分为两类不同的是,本文将样本划分为5类,分类更具渐进性,更加合理。并且文章从指标重要度与消除指标共线性两方面考虑约简财务指标,所获得财务指标有代表性。将粗糙集与决策树相结合,应用到财务预警领域,可以提高分类效果。
1 基于变精度加权平均粗糙度的决策树生成算法
1.1 变精度加权平均粗糙度介绍
我们选取测试属性的目的是使所选条件属性包含的确定性因素更多,而条件属性的变精度加权平均粗糙度越小,则相应的其包含的确定性因素就越多,因此,将其选为测试属性也更加合理。相关定义如下:
定义1 加权平均粗糙度
(1)
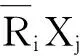
定义2 变精度加权平均粗糙度
(2)
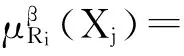
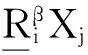
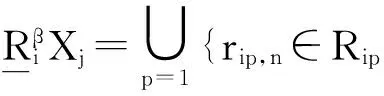
(3)
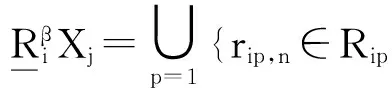
(4)
现实财务数据中不可避免存在很多噪声数据,使用变精度近似精度可以克服噪声数据对精确性的影响,在一定程度上消除噪声数据对刻画精度的影响。
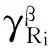
1.2 基于变精度加权平均粗糙度构造决策树过程描述
决策树的基本算法是贪心算法,采用自顶向下的递归方式构造决策树。也就是说决策树每次生长过程都是使用相同的标准来确定测试属性。
构造决策树过程,测试属性用来确定树的非叶子结点,树的每一次生长都要确定一个测试属性,所以说测试属性的选择至关重要,直接影响分类的质量。树的生长过程中,把变精度加权平均粗糙度作为决策树测试属性选择的标准,每次选择变精度加权平均粗糙度最小的属性作为树的测试结点。
决策树自顶向下生长,每次生长都选择变精度加权平均粗糙度值最小的属性作为树的测试属性。输入决策表和分类误差β,即可输出一棵决策树。
算法步骤如下:
步骤1 根据输入的决策表计算每一个条件属性的变精度加权平均粗糙度,并比较它们的大小;
步骤2 选择变精度加权平均粗糙度最小的属性ψ作为决策树测试的属性;
步骤3 用选择的属性ψ去划分训练集,相应的该属性的每一个取值产生一个分支(子表),这样训练集被划分为若干小的决策表;
步骤4 若子表中属于某一类别实例个数占表中总实例个数大于等于(1 -β)或表中没有可选的属性,则以该子表中占多数的实例类别标识该节点,并作为叶子结点;否则,将子表中的条件属性去掉已选划分属性ψ,重复以上步骤;
步骤5 返回。
算法步骤比较简单,决策树使用递归算法,对训练集划分,可以得到一个局部最优解。根据分类的结果可以形成一系列规则,根据这些规则可以对公司财务状况进行评价,进而对公司财务进行预警。树的生成过程运用粗糙集中的变精度加权平均粗糙度作为选择测试属性的方法,每次选择变精度加权平均粗糙度值最小的属性作为分支结点。这种方法复杂性较低,并能有效提高分类效果,应用到财务领域,对财务预警效果较好。
2 基于变精度加权平均粗糙度的决策树财务预警实证研究
2.1 基于粗糙集的决策树财务预警基本步骤
本文基于粗糙集和决策树理论对公司财务预警,以选取原始数据为出发点,最后建立一棵决策树,形成规则后对公司财务状况进行预警。文章结构主要分为5个部分。
步骤1 为增强可比性,应选取同一行业的财务数据,本文选取85家制造业上市公司数据,并使用可以反映企业财务状况的六方面共计33个财务指标构建原始指标体系;
步骤2 对选取的原始数据进行标准化处理,以消除不同量纲和奇异值对结果的影响;
步骤3 把选取的85家数据进行对象聚类,把它们分为5类,分别是财务状况危机、预警、一般、良好和健康,同时对数据进行离散化;
步骤4 将标准化后的数据按照指标聚类把33个指标分为9类,分别计算9类指标中每个指标的重要度,并分别对它们排序,选择每类中重要度最大者构建指标体系;
步骤5 根据约简后的指标体系,对象聚类结果和离散化后的数据计算变精度加权平均粗糙度,并依此构造一棵决策树。
基于粗糙集的决策树财务预警基本步骤如图1。
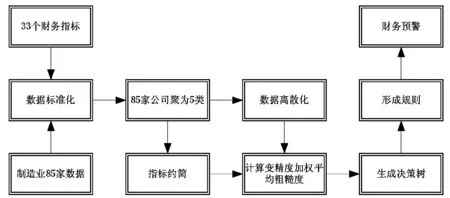
图1 基于粗糙集的决策树财务预警基本步骤
2.2 样本选取及原始指标体系构建
企业财务状况出现异常时,可能会对其营运能力、现金流量等方面产生影响。如,当企业陷入财务困境时,可能出现流动性不足,偿债能力下降,资产周转困难,盈利能力降低等情况。当然,流动性降低、资产周转不灵、盈利能力下降可能也是导致企业陷入财务困境的原因。为了研究企业财务指标与财务困境之间的关系,本文选取影响公司财务状况的六方面共计33个指标对企业财务状况进行评价。这六个方面分别是:营运能力、现金流量、资本结构、偿债能力、成长能力和盈利能力。
本文选用沪深两市制造业公司的财务数据为样本,剔除中小板A股股票70只、创业板14只、B股7只,数据不全的股票60只(含),最后得到沪深两市C4行业2009年A股主板85只股票的财务数据作为样本。即本文的样本数据为85家制造业公司2009年的33个财务指标。
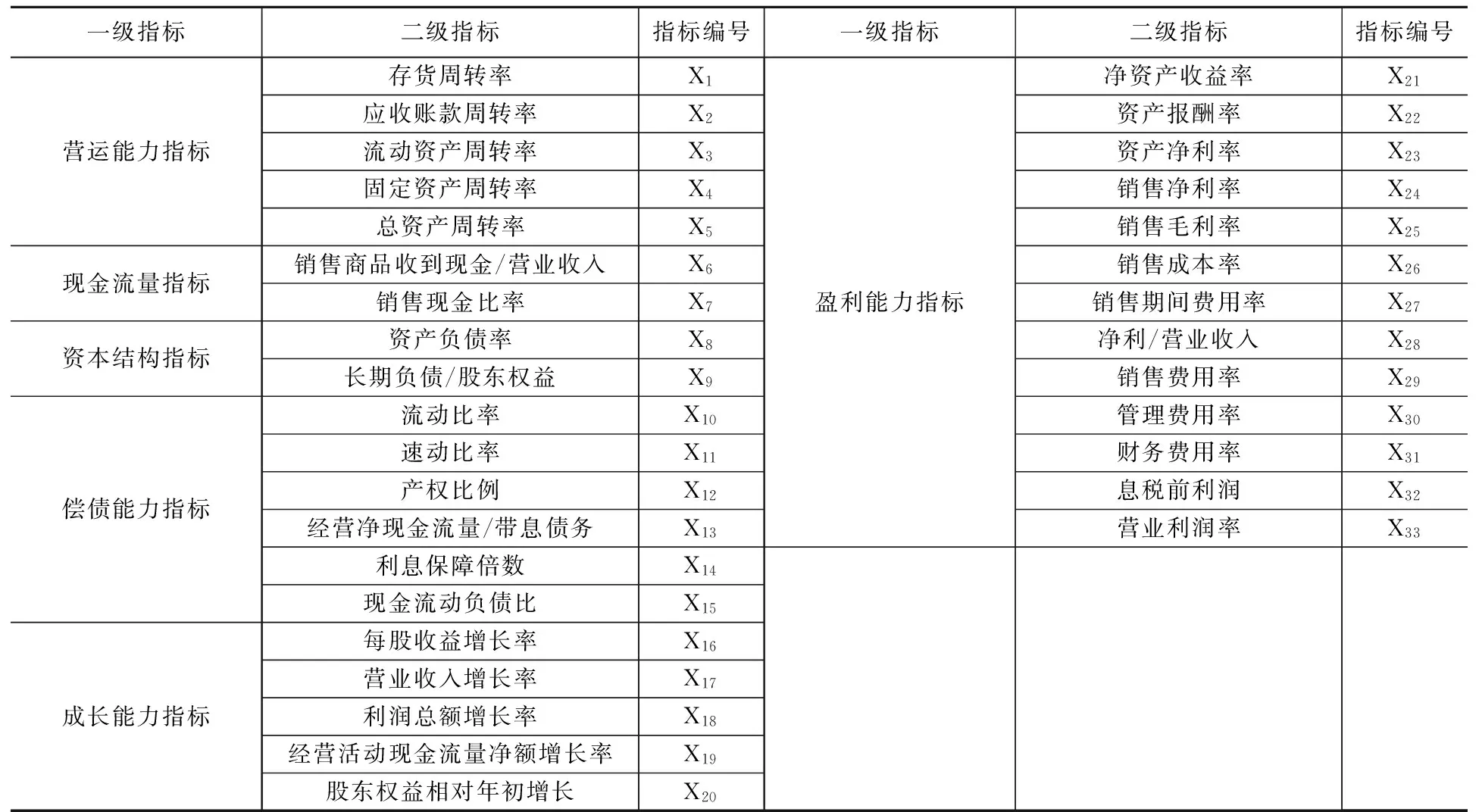
表1 选择财务指标
2.3 数据标准化
聚类分析及建树的要求需要对各个原始数据进行标准化处理。本文选择0-1标准化方法,算法描述如下:
对于一个正向指标Xi,假定当它取值大于或者等于α时为最佳,此时,把它所有取值等于或者大于α的值标准化后取值为1;同理,假定当Xi的取值小于或者等于β时为最差,标准化后取值为0;取值为区间(β,α)的数据δ,标准化之后为:
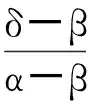
(5)
将选取的85家上市公司的33个财务指标运用上述方法进行标准化。
2.4 指标约简
由于财务指标之间会有较强的相关性,同时考虑到各个指标对公司财务状况影响程度不同,本文基于聚类和粗糙集中指标重要度来对指标约简,建立决策树的指标体系。
(1)首先从指标的共线性角度出发,使用系统聚类方法对33个财务指标进行聚类。本文综合考虑指标之间相关性和指标经济含义,把33个原始指标分为9类,分别为:
Y1={X2,X4,X19},Y2={X10,X11},Y3={X14,X16,X17,X18,X25},Y4={X1,X3,X5,X13,X15},Y5={X27,X30},Y6={X6},Y7={X7,X9,X29,X31},Y8={X8,X12},Y9={X20,X21,X22,X23,X24,X26,X28,X32,X33}
结合指标的经济意义来看,{X2,X4,X19}反映的主要是营运能力;{X10,X11}是对偿债能力说明性强的指标。显然,将{X2,X4,X10,X11,X19}划分为两类是合理的。{X7,X9,X29,X31}主要是反映销售收入结构的指标,而{X8,X12}反映的是企业资本结构,从二者的计算过程来看,将它们聚在一起,并与其他指标分开比较合理。
(2)其次考虑每个指标对决策变量的重要性,利用粗糙集中重要度理论对指标聚类结果中属于同一类的财务指标进行约简。得到最终的财务预警指标体系。一般来说,不同的条件属性对决策属性有不同的重要性。为了确定每个条件属性对于决策属性的重要性,粗糙集中常用的一种方法是将该属性从决策表中删除,然后考察没有这个属性的情况下决策表分类的变化情况。
定义3 重要度:给定一个决策表DT=(U,C∪D,V,f),∀β⊆C,∀β∈c,以及∀α∈C-B,定义:
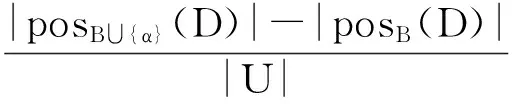
(6)
为条件属性α对条件属性集B相对于决策属性D的重要度;其中,U表示一个论域,C为条件属性,D为决策属性,V表属性集的值域, f为一个信息函数,表任意一个对象的属性在V上的取值。
以第一步中每一类聚类结果中的指标为条件属性,确定每个指标对决策属性的重要程度。在每一类指标中挑选重要度最大的指标作为最终指标,构建最终指标体系。

表2 指标重要度
由此得到约简后的指标,构建出最终指标,如表3。
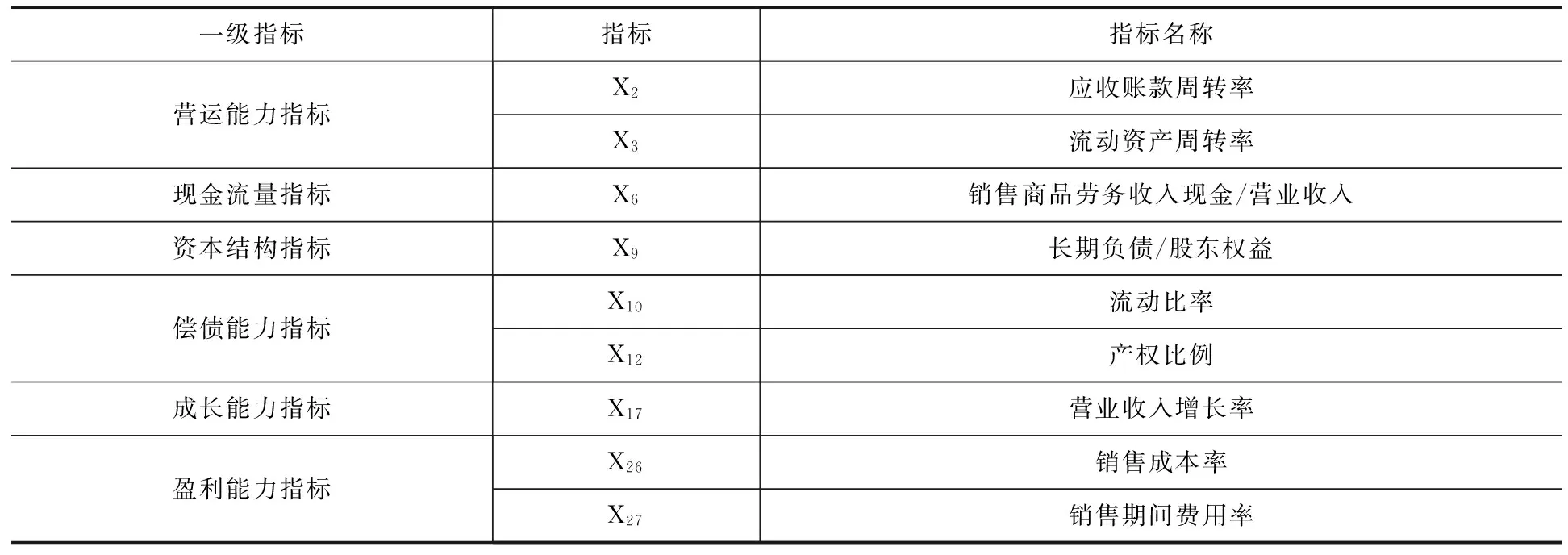
表3 最终财务指标
从33个财务指标中最终筛选出9个指标,它们从6个方面描述企业的财务状况,并且指标之间无明显的共线性。
2.5 聚类分析
为了确定每家单位所属的财务状况等级,我们需要对这些单位进行分类。文章运用系统聚类的方法,把所选的国内制造业上市公司分为5类。根据各指标值的表现情况,第一类为财务状况健康的公司,第二类为财务状况良好的公司,第三类为财务状况一般的公司,第四类为财务状况预警的公司,第五类为财务状况危机的公司。
利用处理过后的数据,然后通过系统聚类把85家企业分为5类,为方便起见,我们对85家公司进行了编号。聚类结果如下:
A={9,30,37,43,49,52,53,55,56,57,60,65,69,73,78,81,84};
B={4,5,7,13,15,21,24,26,27,31,32,33,36,38,39,40,45,47,48,63,66,68,71,74,82,83};
C={3,8,10,11,14,17,29,32,34,46,58,59,62,72};
D={2,12,16,23,25,28,35,42,61,67,70,75,76,77,80,85};
E={1,6,18,19,20,41,44,50,51,54,64,79}。
以上聚类结果把85家企业分为5类,并根据每类公司各指标值的表现情况,A、B、C、D、E分别表示财务状况健康、良好、一般、预警和危机。从聚类结果来看,大多数ST公司被聚到了第五类,聚类效果较好。
同时,为了满足建树的需要,我们需对数据进行离散化处理。数据离散化把连续型数据转化为离散型数据,对标准化后的数据,把每个条件属性按照取值划分为5个等价类,分别为:[0,0.1)表示财务状况差,用数字“1”表示;[0.1,0.3)表示财务状况较差,用数字“2”表示;[0.3,0.6)表示财务状况中等,用数字“3”表示;[0.6,0.8)表示财务状况较好,用数字“4”表示;[0.8,1]表示财务状况好,用数字“5”表示。由此,每个条件属性都有5个等价类。
2.6 生成决策树
分类误差可以反映决策树分类精确度,综合考虑分类精度与防止决策树过度拟合问题,本文设定分类误差β=0.2。
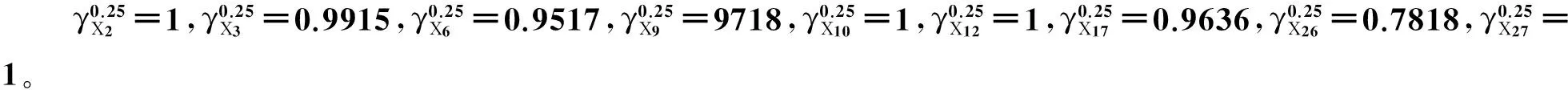
若子表中属于某一类别实例个数占表中总实例个数比例大于等于0.8或者表中没有可选的属性,则以该子表中占多数的实例类别标识该节点,并作为叶子结点;否则,将子表中的条件属性去掉已选划分的条件属性R3,重复上述步骤。
3 实证结果
首先,销售成本率作为树的根结点,把训练集分成了五类,其中销售成本率在区间[0,0.1)之间的公司有10家,而这10家中有9家是属于财务状况危机的公司,9/10=0.9,大于1-β=0.8。因此,销售成本率在区间[0,0.1)之间的等价类财务状况为危机。据此,我们可以认为训练集以外的公司销售成本率在区间[0,0.1)的财务状况为危机。而且,得出的决策树把大部分被ST的公司分到财务危机的一类,总体分类准确率比较高。
树中“1”表示区间[0,0.1),“2”表示区间[0.1,0.3),“3”表示区间[0.3,0.6),“4”表示区间[0.6,0.8),“5”表示区间[0.8,1]。
决策树结果如图2。
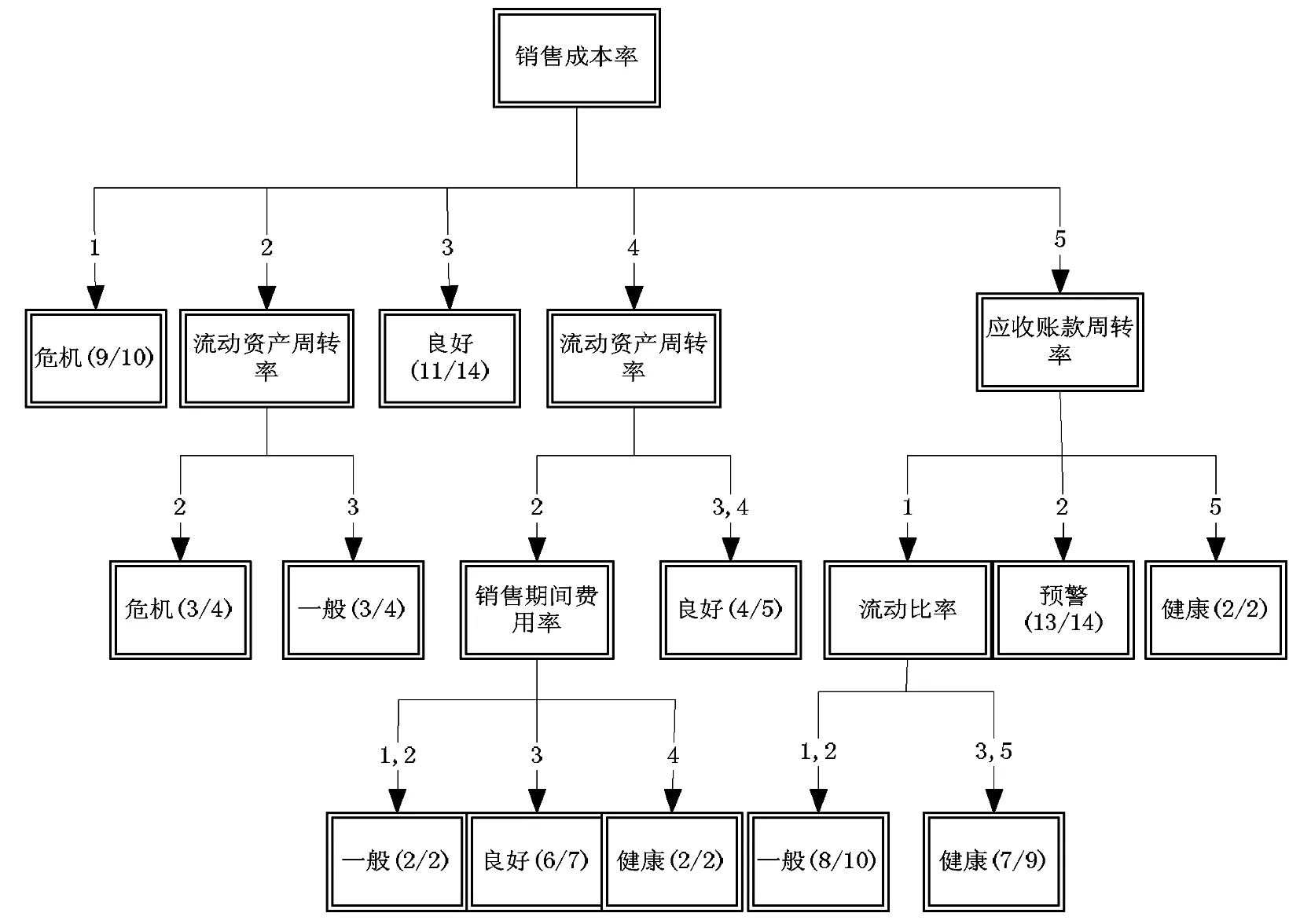
图2 财务预警的决策树结果
根据决策树形成规则如表4。

表4 决策规则
根据历史数据寻找公司财务数据的规律,建立一棵决策树,生成一系列规则,根据这些规则可以预测训练集以外的公司财务状况。
同时,我们得到利用变精度加权平均粗糙度决策数模型的财务预警分类精度,如表5所示。同时,运用CHAID决策树算法,对相同样本进行了财务预警的分析,其分类精度结果见表5。可以看到,基于变精度加权平均粗糙度决策树的财务预警结果精度更高。
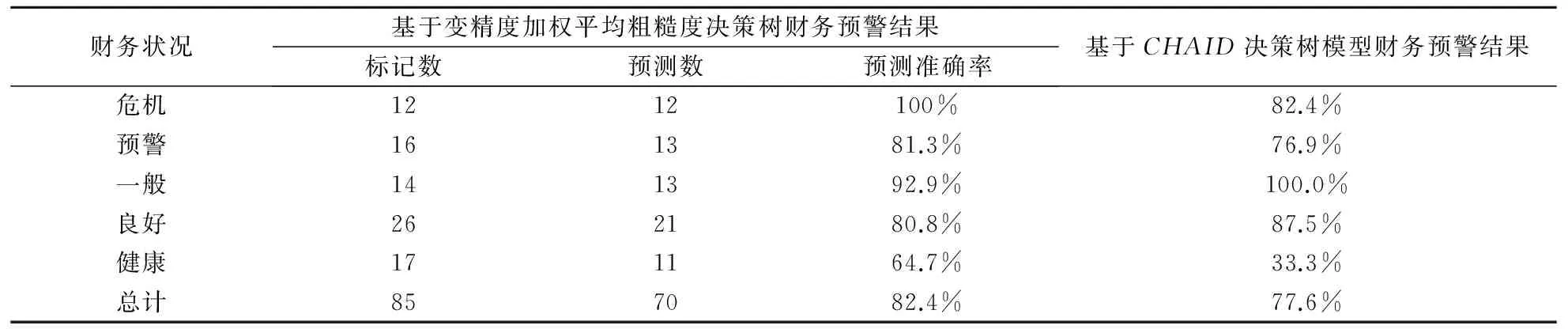
表5 模型分类精度表
4 结论
为了对公司财务状况进行更加精确的预警,本文把公司财务状况分为5个等级,与以往两个等级的财务预警相比,分类更具渐进性,更加合理。同时本文利用粗糙集中重要度理论对所选33个指标进行了约简,最终得到可以代表公司财务状况的9个财务指标,这9个财务指标从6个方面描述公司的财务状况,并且消除了指标之间的相关性。数据离散过程,不是平均地划分为5个区间,而是偏向于正态分布的趋势,符合数据分布的一般规律。
将变精度加权平均粗糙度作为构造决策树的测试属性选择的标准,通过实证研究,我们得到一棵决策树,并根据这棵决策树形成12条规则。这些规则对发生财务危机的企业预警精度为100%,构造出的决策树把10家ST公司全部分到财务状况危机的一类;对公司财务状况一般的企业预警精度为92.9%,总体预测精度达82.4%。可见此模型对公司财务状况预警有较好的效果,尤其是对将要发生财务危机的企业。与运用CHAID决策树算法的财务预警模型相比,基于变精度加权平均粗糙度决策树的财务预警结果更加准确。
根据决策树提取的一系列规则以及决策树模型,可以构建一个财务危机预警系统。由于引入了变精度加权平均粗糙度,生成的决策树有效弱化了少数实例对决策树造成的不良影响,虽然决策中存在一定的误差,但决策树总体分类是比较好的,最终生成的决策树也比较符合实际,分类精度也比较高,且有效地处理了噪声数据。
[1] Yang Z J, You W, Ji G L. Using partial least squares and support vector machines for bankruptcy prediction[J]. Expert Systems with Applications, 2011, 38: 8336- 8342.
[2] Bao X Z, Tao Q Y. Dynamic financial distress prediction based on rough set theory and EWMA model[J]. International Journal of Applied Mathematics and Statistics, 2013, 48(18): 339-346
[3] Jae K B. Predicting financial distress of the south korean manufacturing industries[J]. Expert Systems with Applications, 2012, 39 (10): 9159-9165.
[4] Sun J, Jia M Y, Li H. Adaboost ensemble for financial distress prediction: an empirical comparison with data from Chinese listed companies[J]. Expert Systems with Applications, 2011, 38(8): 9305-9312.
[5] Frydman H, Altman E I, Kao D. Introducing recursive partitioning for financial classification: the case of financial distress[J]. Journal of Finance, 1985, 40(1): 269-291.
[6] 姚靠华,蒋艳辉.基于决策树的财务预警[J].系统工程,2005,23(10):102-106.
[7] 陈晓红,易松青.基于CHAID方法的中小企业上市公司财务预警研究[J].经济管理研究,2007,3: 50-54.
[8] Lee S. Using data envelopment analysis and decision trees for efficiency analysis and recommendation of B2C controls[J]. Decision Support Systems, 2010, (49): 486- 497.
[9] 赵卫东,李旗号.粗集在决策树优化中的应用[J].系统工程学报,2001,16(4):289-295.
[10] 蒋芸,李战怀,张强等.一种基于粗糙集构造决策树的新方法[J].计算机应用,2004,24(8):21-23.
[11] 高静,徐章艳等.一种新的基于粗糙集模型的决策树算法[J].计算机工程,2008,34,(3):9-11.
[12] 鲍新中,杨宜.基于聚类-粗糙集-神经网络的企业财务危机预警[J].系统管理学报,2013,22(03):358-365
[13] Iftikhar U S, Toshinori M. Application of rough set and decision tree for characterization of premonitory factors of low seismic activity[J]. Expert Systems with Applications, 2009, 36: 102-110.
[14] Chen M Y. Predicting corporate financial distress based on integration of decision tree classification and logistic regression[J]. Expert Systems with Applications, 2011, (38): 11261-11272.
Financial Early-warning Based on Variable Precision WeightedAverage Roughness Decision Tree
BAO Xin-zhong, FU Hong-yu
(Management School, Beijing Union University, Beijing 100101, China)
Traditional researches usually divide the samples into ST and non-ST for the financial status. We use clustering methods to divide sample companies into 5 categories, namely, healthy, good, general, warning and crisis. This five-level classification may be more reasonable and practical than the traditional two-level classification. Meanwhile, 33 financial indicators are reduced into 9 ones based on the indicator correlations and the significance. The reduced indicaor system and the five-level financial status are used to construct the decision tree, which makes the process more reasonable. Then, we regard variable precision-weighted average roughness as the method of selecting branch properties, and each time select minimum of them as branch properties. Thus generated decision tree can avoid the detailed classification of a small amount of special categories data and improve the ability of anti-noise. This method is less complex and can effectively improve the classification results. The empirical study proves to have good results by using it in the early-warning of financial distress.
clustering analysis; decision tree; rough sets; financial early-warning
2013- 09-30
国家社会科学基金项目(14BGL034);北京市社科基金重点项目(15JGA003)
鲍新中(1968-),男,江苏宜兴人,教授,博士,主要研究方向为财务数据挖掘。
F275
A
1007-3221(2015)03- 0189- 08
