片上网络非适应性路由算法研究
2015-05-31李天阳潘能智屈凌翔
李天阳,潘能智,屈凌翔
(中国电子科技集团公司第58研究所,江苏 无锡 214035)
1 引言
近十年来,由于摩尔定律的发展遇到了工艺和生产成本的限制[1],许多片上系统(SoC)为了在单芯片上集成更高的运算能力,同时也为了缩短芯片的面市时间(TTM,Timing To Market),通过集成IP的方法来构建多处理器芯片[2]。当前集成多核芯片的主要方法是通过总线互联,这在小规模如双核、四核、八核等芯片上具有结构简单且能达到单周期存取数据的要求[1]。但是,总线结构由于其总线带宽的限制,可扩展性不高,且当数据流量过高时,也会产生平均通信效率低下的问题。因此,近年来人们提出了一种类似计算机网络的方法将处理器进行互联的硬件结构,并称之为片上网络(NoC,Network on Chip),使多核处理器系统的通信效率、吞吐量和可扩展性有了本质的飞跃。片上网络结构处理器目前已经广泛用于超级计算机和分布式计算等领域。NoC互联结构或可成为下一代超大规模集成电路的主流[3]。
片上网络体系结构包括网络拓扑、协议设计、路由算法、流量控制、仲裁、服务质量(QoS)和差错管理等方面。其中路由算法和流量控制是判断某个NoC网络好坏的两个关键因素[4]。
路由算法负责在网络拓扑结构中从源节点到目的节点进行路径选择。在一个NoC网络中,路由算法的选择非常严格。一个好的路由算法在网络信道中可以起到平衡负载的作用,即使是在像随机序列通信这样的非标准通信模式下,信道负载越平衡,网络的吞吐量就越理想。但是当前的路由器并没有进行很好的负载平衡。通常,节点之间的通信取决于某条预先设定的路径。在这种路由算法下,非标的通信模式会在次优的吞吐量下发生巨大的负载失衡。选择这些路由的原因在于大多数路由器都是以最短路径作为设计目标[5]。一个好的路由算法也应该保持路径长度尽可能地短,并且减少经过的节点数以减少数据的总体延时。通常,路由最小化(通常选择最短路径)在平衡负载和吞吐量上会相互冲突[6]。
本文总结了常见的路由算法,介绍了无关性路由算法并对其进行分析比较,其中主要分析了非适应性的路由算法,因为其具有结构简单、容易实现和能预防死锁的优点,因此被大多数片上网络系统所使用。
2 路由方法分类
按照如何选择从源节点x到目的节点y可能的路径集Rxy的方式来分类不同的路由算法。使用路由关系R和选择函数ρ来代替路由算法。R返回一组路径(或信道),ρ在这些路径(或信道)之间进行选择。分割算法,和信道依赖以及死锁都与R相关,而适应性与ρ相关。
定义R为以下3种方式[8]:
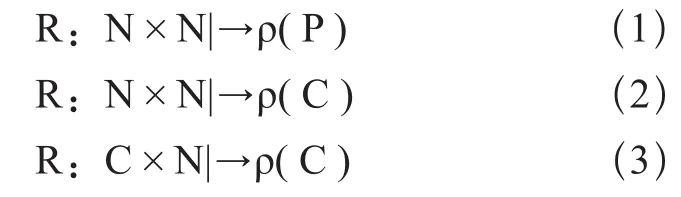
其中ρ(X)指定了幂集,或X的所有子集。这种记法表明,路由关系可能会返回多条路径(或信道),且由选择函数选择这些结果中的一个。
当路由关系的输出是所有路径,如式(1)所示,路由算法又表示为一次路由(all-at-once routing)。当数据包从节点x到节点y进入网络时,路由关系为:U=R(x,y)。由于U有可能是路由的集合,因此只选择其中一个赋值给数据包。U不必包含所有可能的路由集合R’xy,甚至不必包含所有的最小路由集合Rxy。在确定性路由算法的情况下,只返回一个结果(|U|=1)。一旦路由被指定,就被保存在数据包中。一次路由可以最小化每个包计算路由关系的时间,但这需要在数据包内增加额外的路由开销。
另一种方案是增长路由[7],其路由关系返回一组可能的信道。与一次路由不同,增长路由并不是一次性返回全部路径,而是每到一个中继节点才计算一次,如式(2)所示。例如,路由关系的输入为数据包的当前节点ω和目的节点y。通过计算得到一组信道:D=R(ω,y),其中D的每个元素都是一条源于ω的输出信道或ωOCD⊆。选择函数用来从D来的数据包选择下一条信道,并且这种增长的过程一直重复到数据包到达其目的节点为止。
第三种关系(式(3))也是类似的增长方法,唯一的区别是函数的输入是历史数据包使用的信道和其目的节点,即使用历史信道c的信息而不是节点本身,由于信道c已经提供了足够的历史信息来去除信道间的依赖和耦合,这可以避免死锁[11]的发生。
3 确定性路由算法[8]
确定性路由算法是最简单的路由算法,它在x和y之间即便可能存在多条路径(|Rxy|〉1)的情况下也只选择固定的一条路径,故而称为确定性路由算法。
确定性路由算法忽略了当前拓扑结构路径的多样化,在负载平衡的优化上表现很差。每个确定性路由算法都存在一种通信模式可以产生巨大的负载失衡。但是,这类算法有着非常简单且容易实现的优点,而且不会产生路由死锁。确定性路由算法在项目中曾被广泛使用,即使在现在也能在很多片上网络项目中使用确定性路由算法。尤其是对于不规则的网络拓扑而言,设计一个好的随机化或适应性路由在不规则网络拓扑下非常困难。最流行的确定性路由算法是目标标记路由和维度排序路由算法。
3.1 目标标记路由
在一个k路n级(k-ary n-fly,即有n级路由,每级路由有k个输出通路)的蝶式网络拓扑[23]结构中,目标地址表示为n位k进制的数。地址的每一位都用来依次选择每级路由的输出通路,就像是转发的路由表一样。图1表示了2路3级的蝶式拓扑下目标标记路由算法[9]的寻路过程。
从节点3到节点5,从左到右传输目标地址转换成二进制,5=1012=下,上,下。算法没有用到源节点的信息,因为无论从哪个节点出发,用101的模式都能到达节点5。因此,目标标记的路由方法只依赖于目标的地址,与起始地址无关。
3.2 维度排序路由
维度排序路由又叫e立方路由[10],是目标标记路由算法在a路b维网络(tori和meshes)[11]的模拟。和目标标记算法类似,目标地址表示为k进制数的每一位都用来指示路由寻址。不同点是每一位不是用来选择输出通路,而是用来选择在指定立方体下的路由节点。与蝶式拓扑网络不同,立体网络可能在处理每一位数字时需要多次跳转才能到下个数字。以多维(torus[12])拓扑网络为例,其每个维度都可以顺时针或者逆时针遍历,因此e立方路由的第一步就是计算每个维度最短的(或者其他优先的)方向。为了找到优先的方向,先要计算每一位源和目标数字i相关的地址Δi:

这可以用来计算优先的方向:

其中T表示函数是环形(tori)网络的。一旦优先方向向量被计算出来后,数据包就被转发到下一层,直到其到达目的节点。
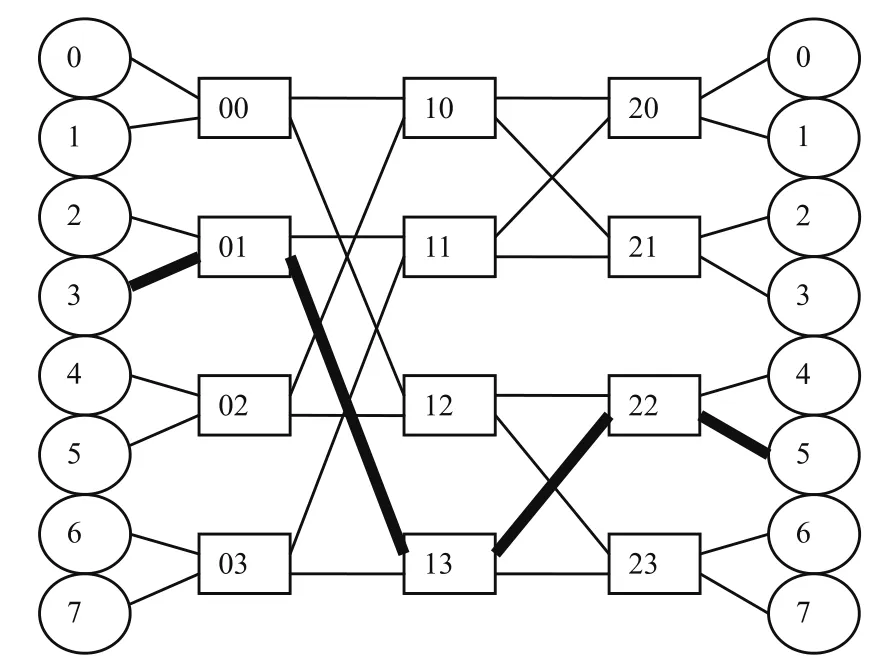
图1 从节点3到节点5的路由过程
一般而言维度排序路由的负载平衡性质很差,但是仍然被广泛用于高路多维(mesh和torus)的网络结构[18]。首先维度排序路由很容易实现,而且允许路由以维度进行切分或跨维度分割。其次,这种算法通过预防在不同维度间回环,从而避免死锁的问题。不过,在一个维度内还是有可能造成死锁。
4 无关性路由算法[13]
无关性路由(oblivious routing),是指在传输数据包的时候不考虑网络当前状态的路由算法。这种算法非常容易实现和分析,加入网络状态信息可以提高路由性能,但同时也加入了相当大的复杂性,如果不小心处理,反而会导致性能下降。无关性路由算法主要有随机化路由算法、最小无关路由算法和负载平衡路由算法等。
4.1 Valiant随机化路由算法
Valiant随机化路由算法[14]是一种部分随机的算法。当数据包从s传输到d时,首先从s传输到一个随机选择的终端节点x,然后从x传输到d。这两步中可以使用任意的路由算法,此算法在标准通信中可得到最好的平衡负载效果。不考虑初始的通信模式,Valiant算法的每一步都是标准随机通信。因此Valiant算法避免了网络中不均衡网络流量和热点(hot spot)[24]的产生。
Valiant算法具有最好与最坏的性能边界。以k路n级的网络为例,在n的每个维度中,随机的两步中的每一步的平均距离都是k/4,总的跳数为nk/2。因此每次链接平均的负载为γ=k/4。吞吐量为4b/k,在实践中几乎是最优的。在旋风通信(tornado traffic)[19]的情况下,每个数据包必须经过H=n(k/2-1)次跳转。信道负载在任何路由算法下至少为:
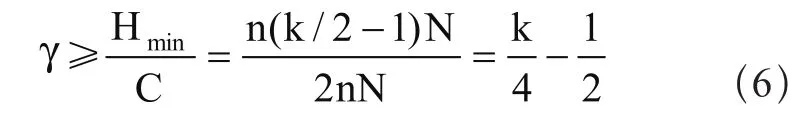
当k增加的时候,Valiant算法引起的信道平衡接近理想情况,因此Valiant算法是渐进最优的。在最坏通信的情况下(如tornado 旋风通信[19]),Valiant算法有良好的性能,这是以牺牲本地性为代价的[15],因为在两步中加入了随机化和额外的工作量。在某些模式中,如邻近通信(nearest neighbor traffic),每个数据包一般只要求中继一次,使用Valiant算法却仍需两步,将跳转数从H=1提高到了nk/2,且降低了吞吐量。
4.2 最小无关路由算法
最小无关(minimal oblivious)路由算法[16]尝试通过将路由限制为最小(最短路径),以在不丢失本地性的情况下来达到随机化路由算法的负载平衡。非最小无关路由算法可能选择任何R’xy中的路径来将数据包从x传输到y,而最小无关路径严格选择路径Rxy。对于层次拓扑而言,最小无关路由算法工作得非常好,在保证本地性的同时也有良好的负载平衡性。
对比而言,在旋风通信的顺时针下所有最小化算法都给出了至少γ=k/2-1的信道负载,在逆时针则是0。由于这样的负载不平衡性,吞吐量最多只能达到因此没有一种最小无关路由算法能达到Valiant算法最差情况下吞吐量的一半。
4.3 负载平衡无关路由算法
完全随机化路由(Valiant)算法和最小无关路由算法中有时需要取一个折中的方法,即负载平衡无关路由算法[17],其在torus中通过随机选择象限(quadrant)来进行输入。通过距离来给象限的选择赋权,能精确地平衡旋风通信的负载。在每个维度i下,以的概率选择较短的方向D’i=Di,以Δi/k的概率选择较长的方向D’i=-Di。一旦选择了方向向量D’,就可以像最小无关路由一样输入到选择的象限中。在象限中随机选择一个中间节点,并路由经过该节点,然后再传输到目的地。对于路由的每一步来说,维度顺序都是随机选择的。
5 非适应性路由算法比较
非适应性路由算法在进行路由选择时不关心当前路由网络的实际流通状态,因此其结构简单,易于在单芯片中实现。在实际中可能通过对已有路由拓扑结构加载已经开发的标准测试通信向量,并对其加载向量后整个网络的通信归一化波特率加以分析,可以得到非适应性路由算法之间的一个比较。常用的测试通信模式有“邻近通信模式”、“单一通信模式”、“位互补通信模式”、“转置通信模式”[18]、“旋风通信模式”[19]与“最大负载通信模式”[20]。表1通过对一个8路2维立方[21]节点路由拓扑结构的模拟,比较了维度路由、随机路由、最小无关路由、与负载平衡无关4种路由算法。因目标标记路由主要针对蝶形拓扑结构,在这里不适合与其他非适应性路由算法进行对比。各种算法测试结果如表1所示[22]。
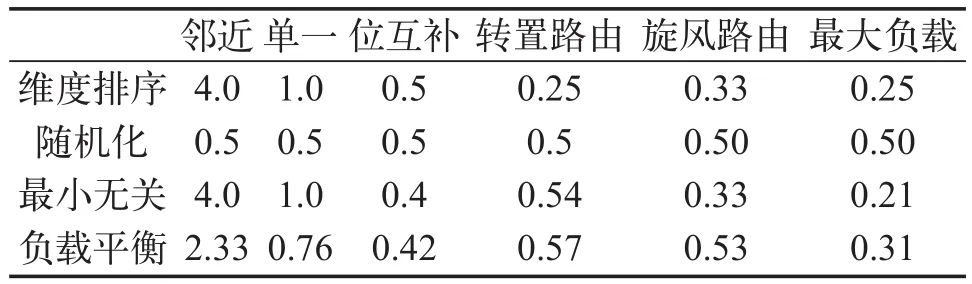
表1 使用不同负载模式对一个8路2维立方路由拓扑进行测试得到的网络归一化吞吐量
从表1的值可以看出,在不同的负载方式下各个路由算法所表现出来的吞吐量有着较大的差异。因此不存在一个绝对优良的算法可以在每种通信模式下都表现出较大的吞吐量。例如在邻近通信模式情况下,负载平衡无关路由算法的表现胜过Valiant算法(这是因为其更频繁地通过较短路径传输),但是其表现却不如最小无关路由算法(这是因为有一部分数据传输不是通过最小象限的)。虽然负载平衡无关路由在旋风通信下表现优异,但其最坏情况下的吞吐量却远低于Valiant算法。
6 小结
本文主要介绍了几种非适应性的路由算法。由于适应性路由算法在实践中往往太过复杂,芯片实施的代价(实现、面积、功耗等因素)很大,对性能的提升效果也不明显,因此大多数片上网络架构都使用非适应性路由算法[22]。Valiant随机化路由算法完全平衡了任何通信模式下的负载,然而这样的平衡性却是以破坏本地性为代价。最小无关路由算法则相反,其保持了本地性,提高了在所有模式平均状态下的网络吞吐量。但是在多维(torus)网络中,任何最小无关路由算法最多只能提供最坏通信情况下的Valiant算法的一半吞吐量。负载平衡无关路由算法提供了上述两种算法的一种折中,既考虑了负载平衡也考虑了本地性,但其最坏情况下的吞吐量却远低于Valiant算法。因此在选择非适应路由算法时,需要着重考虑目标NoC芯片的应用场景的通信模式,依照目标应用场景模式才可以选出适合于具体工程要求的路由算法。
[1] Semiconductors Industry Association. International technology road map for semiconductors,World semiconductors[C]. World Semiconductor Council, 1999.
[2] 马关胜,冯刚. SoC设计与IP核重用技术[M]. 北京:国防工业出版社,2006.
[3] W J Dally, C L Seitz. The Torus Routing Chip[M].Technical Report 5208: TR: 86, Computer Science Dept,California Inst. Of Technology, 1986. 1-19.
[4] Axel Jantsch, Hannu Tenhunen. Networks on Chip[M].Kluwer Academic Publishers, 2003. 87-88.
[5] J Hu, R Marculescu. Exploiting the routing flexibility for energy/performance aware mapping of regular NoC architectures[M]. In Proc. DATE, March 2003.
[6] S Murali, G De Micheli. SUNMAP: A tool for automatic topology selection and generation for NoCs[M]. In Proc. DAC, June 2004.
[7] K Srinivasan, KS Chatha, G Konjevod. Linear programming based techniques for synthesis of Network-on-Chip architectures[M]. In Proc. ICCD,Oct 2004.
[8] Ni L M, McKinley P K. A survey of wormhole routing techniques in direct networks[J]. IEEE Tran.-on -Computers, 1993, 23 (2): 62-76.
[9] Kariniemi H, Nurmi J. Arbitration and routing schemes for onchippacket networks[C]. Interconnect-Centric Design for AdvancedSoC and NoC,2005. 253-282.
[10] R E Kessler, J L Schwarzmeier. Cray T3D: a new dimension for Cray Research[C]. In Proc. Of the IEEE Computer society International Conference (COMPCON),Feb. 1993. 11176-182.
[11] Charles L Setiz. Deadlock free message routing in multiprocessor interconnection networks[J]. IEEE Transactions on Computers, 1987, 36(5): 546-553.
[12] Steven L Scott, Greg Thorson. Optimized routing in the Cray T3D[M]. In proc. Of the First International Parallel Computer Routing and Communication Workshop,Seattle, May 1994. 281-294.
[13] Jose Duato. A necessary and sufficient condition for deadlock-free routing in cut-through and store-and-forward networks[J]. IEEE Transactions on Parallel and Distributed Systems, 1996, 7(6): 841-854.
[14] D H Lawrie. Access and alignment of data in an array processor[J].IEEE Transactions on Computers,1975, 24:1145-1155.
[15] Harold S Stone. Parallel processing with the perfect shuffle[J]. IEEE Transactions on Computers,1971, 20(2):153-161.
[16] Allan Borodin, John E Hopcroft. Routing, merging,and sorting on parallel models of computation[J]. Journal of Computer and System Sciences, 1985, 30: 130-145.
[17] L G Valiant, G J Brebner. Universal schemes for parallel communication[M]. In Proc. Of the ACM Symposium of the Theory of Computing, Milwaukee, Minn, 1981. 263-277.
[18] Ted Nesson, S Lennart Johnsson. ROMM routing on mesh and torus networks[M]. In Proc. of the Symposimu on Parallel Algorithms and Architectures, Santa Barbara, CA, 1995. 275-287.
[19] Arjun Singh, William J Dally, Brian Towles, Amit K Gupta. Locality-preserving randomized oblivious routing on torus networks[M]. In Proc. Of the Symposium on Parallel Algorithms and Architectures, Winnipeg, Manitoba,Canada, Aug. 2002. 9-19.
[20] Brian Towles, William J Dally. Worst-case traffic for oblivious routing functions[M]. In Proc. Of the Symposium on Parallel Algorithms and Architecture, Winnipeg,Manitoba, Canada, Aug. 2002. 1-8.
[21] H Sullivan, T R Bashkow. A large scale, homogeneous,fully distributed parallel machine[M]. In proc Of the International Symposium on Computer Architecture, March 1977. 105-124.[22] W J Dally, B Towles. Principles and Practices of Interconnection Networks[M]. Morgan Kaufmann publishers, 2004. 182.
[23] Charles E Leiserson, Zahi S Abuhamdeh, David C Douglas, Carl R Feynman, Mahesh N Ganmukhi, Jeffrey V Hill, W Daniel Hillis, Bradley C Kuszmaul, Margaret A St Pierre, David S Wells, Monica C Wong-chan, Shaw-Wen Yang, Robert Zak. The network architecture of the Connection Machine CM-5[J]. Journal of Parallel and Distributed Computing, 1996, 33(2): 145-158.
[24] Ni L M, McKinley P K. A survey of wormhole routing techniques in direct networks[J]. IEEE Tran.-on -Computers, 1993, 23 (2): 62-76.
