基于GRA与KPCA的LSSVM物流需求预测
2015-04-19耿立艳
耿立艳
(石家庄铁道大学 经济管理学院,石家庄 050043)
基于GRA与KPCA的LSSVM物流需求预测
耿立艳*
(石家庄铁道大学 经济管理学院,石家庄 050043)
为降低物流需求建模中最小二乘支持向量机(LSSVM)的结构复杂性、进一步提高LSSVM对物流需求的预测精度,提出一种基于灰色关联分析(GRA)与核主成分分析(KPCA)的LSSVM预测方法.首先利用GRA找出物流需求的主要影响因素;然后利用KPCA提取主要影响因素的非线性主成分,消除因素之间的多重相关性;最后,将提取出的非线性主成分作为LSSVM的输入变量,构建物流需求预测模型,并采用改进粒子群(IPSO)算法调整LSSVM参数.运用该方法对我国物流需求进行实例分析,结果表明,该方法有效减少了LSSVM输入变量个数,简化了LSSVM结构,并且在一定程度上提高了物流需求预测精度.
物流工程;预测方法;最小二乘支持向量机;物流需求;预测精度
1 引 言
物流需求预测在物流系统的规划与设计、物流产业发展政策的制定等方面具有重要意义.影响物流需求的因素很多,各因素的影响作用错综复杂,导致物流需求与各因素之间呈现复杂的非线性关系.目前,物流需求预测方法主要有传统预测方法、灰色预测方法和人工智能预测方法三类.传统预测方法和灰色预测方法由于自身的局限性,预测效果不佳.人工智能预测方法主要包括神经网络和支持向量机.神经网络(Neural Network,NN)能够很好地描述物流需求与其影响因素间的非线性关系.但NN所需数据样本较大,在物流数据较少时,无法保证预测精度.Vapnik[1]提出的支持向量机(Support Vector Machines,SVM)是一种基于统计学习理论的机器学习算法,可有效解决小样本、非线性等复杂系统问题.骆世广等[2]、胡燕祝等[3]将SVM应用于物流需求预测,发现SVM在有限样本数据下可获得较高的预测精度.但标准SVM算法需要求解二次规划方程,计算复杂性较大.Suykens等[4]提出的最小二乘支持向量机(Least Squares Support Vector Machines,LSSVM)通过等式约束将SVM求解的二次规划方程转换成一组线性方程,减少了算法的复杂性,更适合于物流需求这种复杂系统的预测研究[5,6].
影响物流需求的因素广泛而复杂,若LSSVM输入变量过多,将导致模型结构复杂,且不重要的因素还会降低物流需求的预测精度.耿立艳等[7]利用灰色关联分析(Grey Relational Analysis,GRA)从众多影响因素中选取主要影响因素,构建LSSVM物流需求预测模型.GRA虽然降低了模型的复杂性,但无法消除影响因素之间的多重相关性.梁毅刚等[8]将核主成分分析(Kernel Principal Component Analysis,KPCA)提取的非线性主成分作为LSSVM的输入变量预测物流需求,获得了较高的预测精度.
为进一步简化LSSVM结构、提高物流需求预测精度,提出一种GRA、KPCA、LSSVM相结合的预测方法,先采用GRA选择物流需求主要影响因素,再利用KPCA提取主要影响因素的非线性主成分,将其作为输入变量,建立LSSVM预测模型,最后利用Xu等[9]提出的改进粒子群(Improved Particle Swarm Optimization,IPSO)算 法优化LSSVM参数.通过对我国物流需求的实例研究检验新方法的有效性.
2 基本理论
2.1 灰色关联分析
GRA根据各因素序列几何形状的相似程度,判断各因素对系统发展的重要程度,具体分析步骤如下:

(2)在时刻 t'(t'=1,2,…,N),计算{Q0(t')}与{Qi(t')}的关联系数:
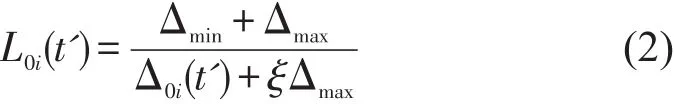
(3)计算{Q0(t')}与{Qi(t')}的关联度:

式中 r0i∈(0,1].再依据关联度由小到小排列出关联序.
2.2 核主成分分析
设样本集为X={xm∈Rq|m=1,2,…,N},通过非线性函数φ:Rq→F,将样本xm映射为高维特征空间(F空间)中的数据φ(xm).计算协方差矩阵:

式中 φ(xm),m=1,2,...,N具有零均值.定义核函数矩阵 K,Kmg=K(xm,xg)=φ(xm)∙φ(xg),m,g=1,2,…,N,将 F空间的内积运算转化为输入空间运算. K(xm,xg)为满足Mercer条件的核函数.若φ(xm)均值不为零,通过以下处理将K变换为中心化矩阵:

式中 AN为N阶矩阵;amg=1/N,m,g=1,2,…,N.

式中 λ=[λ1,λ2,...,λN]为的特征值;β=[β1,β2,...,βN]为对应的特征向量.由此得到CF的特征向量,则第r个非线性主成分为

由特征值的累积贡献率,选取前 p<N个非线性主成分.
2.3 LSSVM算法
给定训练样本集{zl,yl},l=1,2,…,n,其中,zl∈Rd为输入变量,yl∈R为输出变量,LSSVM优化问题为

式中 Φ()为一非线性映射函数,用于实现样本在高维特征空间中的线性拟合;ω为权向量;b为偏差量;γ为正则化参数;el∈R为误差变量.用Lagrange法求解以上优化问题,转化为以下线性问题:

式中 1=[1,1,…,1]T为n个1组成的向量;I为n阶单位矩阵;Hli=Φ(zl)TΦ(zi)=K(zl,zi),l,j=1,2,…,n;α=[α1,α2,…,αn]T为 Lagrange乘子向量;y=[y1, y2,…,yn]T;最后得到LSSVM模型为
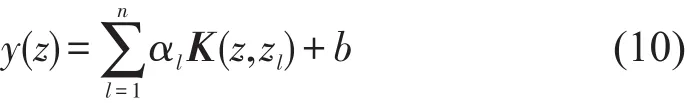
3 模型构建
GRA-KPCA-LSSVM预测模型将GRA、KPCA与LSSVM相结合,首先利用GRA从定量角度分析各因素对物流需求的影响程度,进而筛选物流需求的主要影响因素;然后通过KPCA提取主要影响因素的非线性主成分,消除各主要影响因素之间的多重相关性;再以非线性主成分作为LSSVM输入变量,建立预测模型.
LSSVM的预测精度取决于核函数的选取及参数的确定.若选择泛化能力较强的RBF核函数,则需要确定的参数为:正则化参数γ和核参数σ2.一般采用交叉验证法确定两参数,但交叉验证法是一种经验法,具有人为选择的随机性,难以得到最优参数.为此,本文利用IPSO算法搜索LSSVM最优参数,步骤如下:
步骤1设定IPSO算法参数:群体规模S,学习因子c1和c2,最大、最小惯性权重wmax和wmin,最大进化代数kmax.随机生成粒子的初始位置和初始速度.
步骤2定义适应度函数为LSSVM预测误差:

步骤3 根据式(11)计算各粒子适应度值,更新粒子个体最优位置和粒子群全局最优位置.惯性权重w按下式自动更新:

式中 k为当前进化代数.
步骤4 若所有粒子的进化代数满足预先设定值,计算结束,此时全局最优位置即为LSSVM最优参数;否则,k=k+1,转步骤3.
步骤5利用最优参数建立LSSVM模型并进行预测,再通过反归一化获得原始数据的预测值.
4 实例分析
4.1 指标的选取
物流需求的度量指标中,现有研究主要使用货运量[6]和社会物流总费用[7]两种,货运量从货运规模角度衡量物流需求,但整个物流活动中除了货物运输,还涉及其他多个紧密相关环节,货物运输量难以完全代表物流需求.而社会物流总费用从核算角度定义物流需求,指一定时期内社会经济各方面在物流活动中各项费用支出,该指标是体现物流需求的最综合指标,因此,本文选取社会物流总费用为物流需求量化指标.
关于物流需求影响因素目前还没形成统一观点.文献[3]将物流需求的影响因素概括为6项经济指标:经济总量指标、产业结构类指标、交通运输类指标、贸易类指标、邮电业务类指标、消费类指标.这些指标仅考虑了经济相关因素的影响,对其他相关因素未作考虑.文献[7]不仅考虑了经济影响因素,还将物流行业因素纳入物流需求影响因素.但以上研究均未考虑价格水平、人口数量和信息技术的影响,这三类因素对物流需求也会产生重要影响.不同市场的商品价格水平差异会促进物流需求增加;一个国家人口数量越大,消费需求越多,对物流的需求也增加;信息技术的发展可以提升物流的服务质量和需求范围,进而增加对物流的需求.
根据以上分析,考虑到指标数据可得性,初步选取17项指标作为物流需求的影响因素,并将这17项指标分为经济影响因素与非经济影响因素两大类,经济影响因素包括9项指标:国内生产总值GDP(P1),固定资产投资总额(P2),第一产业总产值(P3),第二产业总产值(P4),第三产业总产值(P5),货物进出口总额(P6),社会消费品零售总额(P7),居民消费水平(P8),商品零售价格指数(P9);非经济影响因素包括8项指标:邮电业务总量(P10),货运量(P11),货物周转量(P12),物流行业就业人员数(P13),民用载货汽车拥有量(P14),国家铁路货车拥有量(P15),民用货运船舶拥有量(P16),总人口数(P17).
选取1991~2011年相关数据为样本进行实例分析.其中,社会物流总费用根据国家发改委、国家统计局、中国物流与采购联合会相关资料,按当年价格计算;影响因素数据来源于《中国统计年鉴1992-2012》,经济影响因素中除商品零售价格指数按不变价格计算,其余指标均按当年价格计算.
4.2 物流需求影响因素的GRA与KPCA分析
设社会物流总费用(P0)为系统特征行为序列、17项指标Pi(i=1,2,…,17)为相关因素序列.根据式(1)对两类序列作均值化处理,取分辨系数ξ=0.4 ,根 据 式 (2)和 式 (3)计 算 P0与Pi(i=1,2,…,17)的关联度,并进行排序,结果如表1和表2所示.
由表1和表2可知,经济影响因素的关联度分布在0.851 7~0.986 0之间,非经济影响因素的关联度分布在0.778 0~0.913 1之间,表明经济因素对物流需求的影响程度大于非经济因素.经济影响因素中的P2和非经济影响因素中的P10,P11,P13,P16关联度没超过0.9,表明它们对物流需求的影响程度较小,应去掉这5项指标.因此,选择关联度大于0.9的12项指标作为物流需求的主要影响因素.进一步分析表明,非经济因素中P14,P15,P17对物流需求的关联度较高,文献[3]凭经验仅选取了经济类相关指标,而文献[7]尽管考虑了非经济类相关指标,但忽略了P14,P15,P17指标,这都将造成物流需求预测效果不佳.另外,经比较发现,本文指标的关联度与文献[7]中相同指标的关联度不同,但关联度的排序与文献[7]相同,这是由于关联度与分辨系数取值有关,而关联度的排序与分辨系数取值无关.因此,本文各相同指标对物流需求的重要程度排序与文献[7]相同.
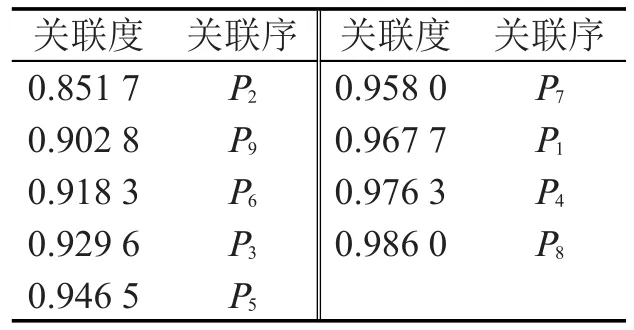
表1 物流需求与经济影响因素GRA结果Table 1 Results of GRA between logistics demand and economic factors

表2 物流需求与非经济影响因素GRA结果Table 2 Results of GRA between logistics demand and non-economic factors
KPCA分析时,选取RBF函数为核函数,分别计算12项指标的特征值、贡献率及累积贡献率,结果如表3所示.KPCA的降维效果明显,前2个非线性主成分包含了原12项指标95%的特征信息,可用于代替原12项指标.文献[8]基于累积贡献率大于85%,选取了前1个非线性主成分代替原始13项指标.根据KPCA理论,累积贡献率越大,包含原始数据的信息越多,相比于文献[8],本文在保留原始指标更多特征信息基础上获得了较好降维效果,能实现更好的替代作用.
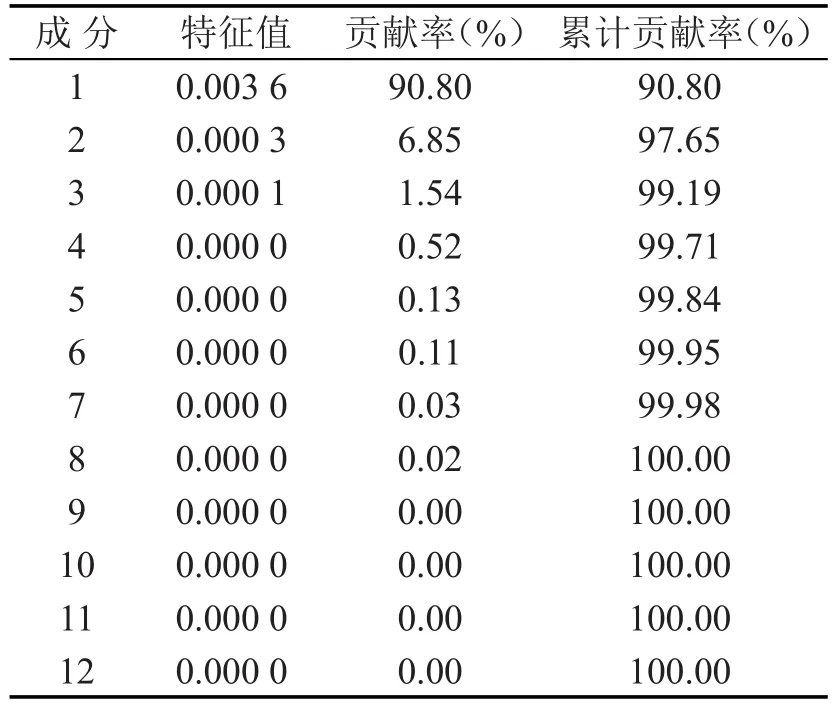
表3 物流需求主要影响因素KPCA结果Table 3 Results of KPCA to major factors of logistics demand
4.3 物流需求的LSSVM预测
根据KPCA结果,以前2个非线性主成分组成的向量为输入,以P0为输出构建LSSVM模型.将数据样本归一化到[0,1],并分为两组:1991~2005年的数据作为训练样本,2006~2011年的数据作为检验样本.设定IPSO算法自身参数:S=10;两个学习因子 c1=c2=2;wmax=0.9,wmin=0.1;kmax=30.为减少随机性产生的影响,用IPSO算法连续10次优化LSSVM,选择最优参数构建LSSVM模型并进行物流需求预测.
4.4 结果分析
将GRA-KPCA-LSSVM预测结果与GRALSSVM、KPCA-LSSVM、LSSVM模型相比较.其中,GRA-LSSVM以GRA选取的12项主要影响指标作为LSSVM输入变量;KPCA-LSSVM以17项指标提取的非线性主成分作为LSSVM输入变量;LSSVM以17项指标直接作为LSSVM输入变量.选取平均相对误差(Average Relative Error,ARE)、标准化均方误差(Normalized Mean Squared Error, NMSE)、标准化平均绝对误差(Normalized Mean Absolute Error,NMAE)评价模型的预测性能,以上指标值越小,预测性能越优.比较如表4和图1所示.

表4 不同输入变量预测结果比较Table 4 Comparison of forecasting results of different input variables
由表4结合图1可知,GRA-KPCA-LSSVM较其他三个模型更好地预测出物流需求变化趋势,其最大与最小相对误差、ARE、NMSE、NMAE分别小于其他三个模型的对应值,有力证明该方法在物流需求预测方面的有效性.表明由GRA结合KPCA选取LSSVM输入变量,不仅降低了输入变量维数、简化了模型结构,而且比单一GRA和单一KPCA更能提高LSSVM的物流需求预测精度.此外,GRA-KPCA-LSSVM模型2006-2007年的预测相对误差较小,仅分别为-0.20%和-0.66%, 2008-2011年预测相对误差明显增大,特别是2011年预测相对误差已达到6.90%,说明该模型更适合于物流需求的短期预测.
为验证IPSO算法的有效性,利用自适应惯性权重粒子群(Adaptive Inertia Weight PSO, AIWPSO)算法和随机惯性权重粒子群(Stochastic Inertia Weight PSO,SIWPSO)算法优化选择LSSVM参数,分别记为GRA-KPCA-LSSVM1和GRA-KPCA-LSSVM2,预测结果与本文比较如表5所示.
由表5可知,总体上IPSO算法优化的LSSVM比其他两算法具有更高的物流需求预测精度,表现在GRA-KPCA-LSSVM的ARE、NMSE、NMAE均小于其他两个模型的对应值;除2008年外,GRA-KPCA-LSSVM的相对误差小于其他两个模型的对应值.这主要是由于IPSO算法通过使惯性权重随进化过程快速变化,有效改善了粒子的收敛性和搜索精度,从而提高了LSSVM预测精度.而AIWPSO算法和SIWPSO算法进化过程中惯性权重变化较慢,对LSSVM参数优化能力弱于IPSO算法.
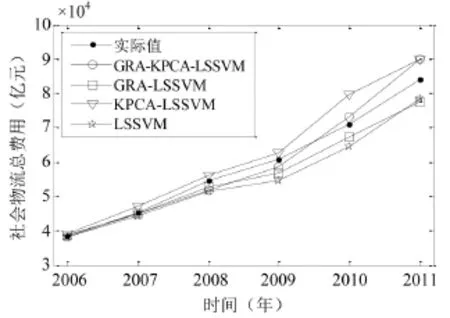
图1 不同模型预测结果比较Fig.1 Comparison of results of different models

表5 不同粒子群算法预测结果比较Table 5 Comparison of forecasting results of different PSO algorithms
5 研究结论
本文将GRA、KPCA与LSSVM相结合预测物流需求,先用GRA选取物流需求的主要影响因素,再通过KPCA消除主要影响因素之间的多重相关性,提取出的非线性主成分作为LSSVM输入变量,并采用IPSO算法优化调整LSSVM参数.对我国物流需求的实例分析表明,该方法降低了LSSVM模型结构复杂性,提高了物流需求的预测精度,适用于样本数据较少条件下的短期物流需求预测,具有一定推广应用价值.
[1]Vapnik V N.An overview of statistical learning theory[J].IEEE Transactions on Neural Networks,1999, l0(5):988-999.
[2]骆世广,叶赛,胡蓉.基于多输出支持向量机的物流量预测研究[J].华东交通大学学报,2010,27(5):67-71. [LUO S G,YE S,HU R.A research of forecasting the logistics amount based on multi-output support vector regression[J].Journal of East China Jiaotong University, 2010,27(5):67-71.]
[3]胡燕祝,吕宏义.基于支持向量回归机的物流需求预测模型研究[J].物流技术,2008,27(5):66-68.[HU Y Z,LU H Y.Study on logistics demand forecast model based on support vector regression[J].Logistics Technology,2008,27(5):66-68.]
[4]Suykens J T,Van G I.Least squares support vector machines[M].Singapore:Singapore Word Scientific, 2002:13-15.
[5]李泓泽,郭森,李春杰.果蝇优化最小二乘支持向量机混合预测模型——以我国物流需求量预测为例[J].经济数学,2012,29(3):103-106.[LI H Z,GUO S,LI C J.A hybrid forecasting model based on fruit fly optimization algorithm and least squares support vector machine:the case of logistics demand forecasting ofChina[J].Journal of Quantitative Economics,2012,29 (3):103-106.]
[6]耿立艳,赵鹏,张占福.基于二阶振荡微粒群最小二乘支持向量机的物流需求预测[J].计算机应用研究, 2012,29(7):2558-2560.[GENG L Y,ZHAO P,ZHANG Z F.Logistics demand forecasting based on LSSVM optimized by two-order oscillating PSO[J].Application Research of Computers,2012,29(7):2558-2560.]
[7]耿立艳,丁璐璐.基于灰关联分析的最小二乘支持向量机物流需求预测[J].物流技术,2013,32(10):130-132,135.[GENG L Y,DING L L.Forecast of logistics demand based on grey correlation analysis and least square SVM[J].Logistics Technology,2013,32(10): 130-132,135.]
[8]梁毅刚,耿立艳,张占福.基于核主成分-最小二乘支持向量机的区域物流需求预测[J].铁道运输与经济, 2012,34(11):63-67.[LIANG Y G,GENG L Y, ZHANG Z F.Forecast of regional logistic demand based on KPCA-LSSVM[J].Railway Transportation and Economy,2012,34(11):63-67.]
[9]Hongbo Xu,Guohua Chen.An intelligent fault identification method of rolling bearings based on LSSVM optimized by improved PSO[J].Mechanical Systems and Signal Processing,2013,35:167-175.
Forecast of Logistics Demand Using LSSVM Combining GRA with KPCA
GENG Li-yan
(School of Economics and Management,Shijiazhuang Tiedao University,Shijiazhuang 050043,China)
To reduce the complex structure of least squares support vector machine(LSSVM)in logistics demand modeling and improve the forecasting accuracy of LSSVM for logistics demand further,based on the grey relational analysis(GRA)and the kernel principal component analysis(KPCA),a LSSVM forecasting method is proposed.First,GRA is used to choose the main influential factors of logistics demand. Then,the KPCA is applied to extract the nonlinear principal components,which can eliminate the correlation in the main influential factors.Finally,the extracted nonlinear principal components are selected as the input variables of LSSVM to construct the logistics demand forecasting model.And the parameters of LSSVM are adjusted by the improved particle swarm optimization(IPSO).Using this method,China’s logistics demand is analyzed.The results indicate that the proposed method effectively reduces the number of the input variables in LSSVM and simplifies the structure of the LSSVM.The forecasting accuracy of logistics demand is improved to some degree.
logistics engineering;forecasting method;LSSVM;logistics demand;forecasting accuracy
1009-6744(2015)01-0137-06
:U268.6
:A
2014-10-11
:2014-12-09录用日期:2014-12-22
河北省高等学校青年拔尖人才计划项目(BJ2014097).
耿立艳(1979-),女,天津人,副教授,博士. *
:gengliyan_28117@163.com
