基于强化学习的汇流瓶颈区可变限速策略研究
2015-04-19李志斌汤斗南
段 荟,刘 攀,李志斌,汤斗南
(1.嘉兴学院,浙江,嘉兴 314211;2.东南大学,南京 210096;3.加州大学,伯克利 94720-1714)
基于强化学习的汇流瓶颈区可变限速策略研究
段 荟1,刘 攀*2,李志斌2,汤斗南3
(1.嘉兴学院,浙江,嘉兴 314211;2.东南大学,南京 210096;3.加州大学,伯克利 94720-1714)
为提高高速公路汇流瓶颈区的通行效率,本文结合强化学习无需建立模型,具有智能学习的特点,对瓶颈区的可变限速策略进行了优化,首次提出了基于Q学习算法的可变限速控制策略.策略以最大化系统总流出车辆数为目标,通过遍历交通流状态集合,尝试不同限速值序列进行自适应学习.以真实路段交通流数据搭建了元胞传输模型仿真平台,通过将其与无控制和基于反馈控制的可变限速策略进行对比,对Q学习策略的控制效果进行评价.通行时间的降低和交通参数的变化表明,强化学习控制策略在提高汇流瓶颈区通行效率和改善交通流运行状况方面具有优越性.
智能交通;可变限速;强化学习;高速公路汇流瓶颈区;Q学习算法
1 引 言
在高速公路系统中,匝道与主线连接路段是一个明显的交通瓶颈[1].可变限速(Variable Speed Limits,VSL),作为一种有效缓解交通拥堵、提高通行效率的技术手段,已被广泛应用于高速公路入口匝道处.其核心思想为通过调节瓶颈区上游主线交通需求,将拥堵期进入高速公路瓶颈区的车辆数控制在一定范围内,来提高瓶颈区通行效率.在过去的研究中,学者们提出了基于最优控制算法和反馈控制算法的可变限速控制策略[2-5].但由于复杂的程序计算,以及模型包含较多需要标定的参数,使其难以在工程中应用.强化学习(Reinforcement Learning,RL)作为一种高效的机器学习算法[6-8],由于具有无需建立环境模型,仅依据当前状态进行自适应学习的特点,已被应用于交通控制实践领域,并取得了较好的控制效果[9-11].因此本文首次尝试将强化学习算法与可变限速控制相结合,提出了基于Q学习算法的可变限速控制策略.
2 强化学习
2.1 强化学习原理
强化学习作为一种智能学习算法,在学习过程中,智能体(Agent)通过尝试不同的动作选择,并根据环境的反馈信号调整动作的评价值,来获得最优策略.在Agent与环境每一次交互过程中,接受环境状态s的输入,Agent选择行为动作a作为对环境状态的输出,使环境状态变迁到s’,同时Agent接受环境的奖惩信号r.Agent学习的目的是发现一系列的最优动作集.使环境获得最大的奖赏.强化学习具有下述特点:①无需事先对交通参数进行预测;②无需建立环境模型;③仅依据当前交通状态和行为动作进行自适应学习;④便于进行在线实施.
2.2 Q学习算法
强化学习中一个重要的里程碑就是由Watkins[12]提出的Q学习(QL)算法.它是一种与环境模型无关,通过遍历状态—动作序列的估计值Q(s,a)来学习最优动作的学习方法.由于其具有无需建立环境模型,并且在一定的条件下保证收敛的特点,使其成为强化学习中应用最为广泛的一种算法.Q学习基本算法为

式中 S代表状态集;A代表动作集;R代表每一状态动作对的即时回报.
Agent的目标为最大化无限折扣后的累计奖赏值为

式中 γ是折扣系数,定义了远期回报的重要度.
在Q学习中,Agent遍历一系列时间步,在每个时间步中,其学习过程如下:
(1)观察当前状态 St;
(2)选择并执行一个动作at;
(3)得到下一个状态St+1;
(4)收到一个立即强化信号Rt;
(5)按下式更新调整Q值:

(6)经过无限次迭代直到Q值收敛,学习结束.
3 基于Q学习的可变限速控制策略
可变限速的核心思想即通过人为降低瓶颈区上游路段的限速值制造一个人造瓶颈,降低上游路段输入瓶颈区的交通流量,使瓶颈区交通流保持在畅通状态,防止瓶颈区通行能力下降,从而提高整条路段的通行效率.可变限速路段主要由可变限速控制区和加速区两部分(如图1所示)组成.可变限速控制区作为可变限速的核心区域,通过设置该路段限速值,生成一个低流量、高密度的人造瓶颈区,使其流出的流量等于下游瓶颈区通行能力.可变限速区长度应确保车辆能从自由流速度稳定减速到限速值.同时由于从可变限速区流出的车辆速度值较低,为消除通行能力状态下车辆加速导致的通行能力下降,需要设置加速区,确保车辆到达瓶颈区前完成从可变限速区限速值速度加速到瓶颈区通行能力所需的自由流速度.因此,可变限速控制即通过避免瓶颈区车辆排队导致通行能力下降产生的额外延误,提高通行效率.该技术提高通行效率的效果取决于瓶颈起始位置由于挽回车辆排队导致的通行能力下降的幅度.

图1 汇流区可变限速控制系统结构图Fig.1 Structure of VSL controlled freeway merge area
本文的可变限速基本控制策略为:①依据历史交通流数据标定瓶颈通行能力下降幅度和下降时交通流阈值;②实时监测瓶颈位置交通流运行状态,判断是否达到通行能力下降阈值;③如无通行能力下降,则进入下一周期继续检测交通流状态;④如达到通行能力下降阈值,则启动位于上游位置的可变限速控制,限速值的选取即通过Q学习算法计算得到.
为了提高基于Q学习算法的可变限速控制策略(QL-VSL)的学习效果,对Q学习系统中的关键要素(状态、回报函数、动作选择策略)的选取进行了详细的设计.
(1)汇流瓶颈区交通状态集.
由于Q学习时间会随状态数的增加成指数增长,因此,应选取对交通流有重要影响的交通状态参数.本文选取了汇流瓶颈区主线下游交通流密度、主线上游交通流密度和入口匝道密度作为交通流状态参数.其示意图如图2所示.
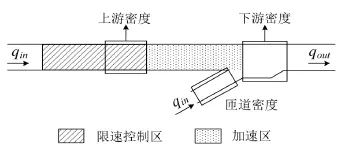
图2 Q学习策略汇流瓶颈区交通状态参数示意图Fig.2 Components of VSL controlled freeway segment
下游密度反映了瓶颈区的拥堵情况,是最为重要的QL-VSL状态参数.由于处于关键密度时瓶颈区流量最大,控制策略的目标即维持下游密度在关键密度附近.上游密度则反映了主线上游的交通需求及拥堵向上游传播的排队长度.为了更全面反映瓶颈区交通状态,同时选取了匝道密度作为交通流状态之一,它反映了匝道的交通需求状态及对主线交通的影响.
(2)目标函数.
基于Q学习算法的可变限速策略选取系统的总行程时间为目标函数,其定义为

式中 s(t)表示t时刻从系统流出的交通量,由拥堵的程度决定;d(t)表示t时刻系统的交通需求,d(t)独立于Agent的动作选择,在TTT中为常量.忽略d(t),减少系统总行程时间即为最大化系统的总流出车辆数.因此,回报函数应根据下游密度进行设置.
4 仿真设计
4.1 元胞传输模型仿真平台
元胞传输模型(Cell Transmission Model, CTM)是Daganzo于1994年首先提出的[13],模型通过将路段划分为具有相同性质等距的小段(元胞),并将时间细分成相等的时间间隔(元胞长度等于每一小段时间间隔车辆以自由流行驶的距离)来模拟车辆运行.在k时刻,系统的状态由此时每一个元胞i中的车辆数ni(k)所给定.模型通过不断更新元胞状态,反映不同交通流状态的时空变化规律及排队形成、消散、拥堵波的逆向传播等交通流动力学特性.如图3和图4所示,本文的元胞传输模型是在基本传输模型的基础上考虑了可变限速和通行能力下降进行优化得到的.
4.2 Q学习可变限速策略仿真
本文的Q学习可变限速策略是基于CTM仿真路段,通过状态与动作的交互作用学习得到的.仿真路段(如图5所示)为长10 km的四车道高速公路路段,并被划分为10个等距的小段,每个路段长1 km,其中孤立汇流瓶颈区位于路段8处.关于可变限速区及加速区的长度设置应能保证完成限速值与自由流速度的转换过渡原则,由于本文的限速值变化范围为[30,110]km/h,自由流速度为110 km/h,加速度取1 m/s2,因此两区间长度均选取1 km满足上述设置要求.为模拟汇流瓶颈区的交通运行状况,本文的参数标定选取了美国加利福利亚州I5高速公路路段(PM39.77-PM45.31)的真实交通流数据,并考虑了可变限速控制及通行能力下降因素.标定后的主要参数值如表1所示.
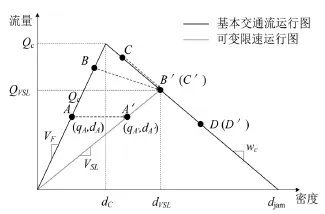
图3 基于可变限速控制的交通流运行图Fig.3 Fundamental diagram for mainline cells in the CTM
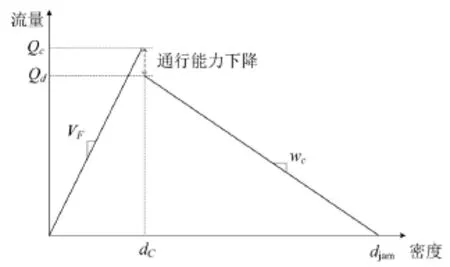
图4 基于通行能力下降的交通流运行图Fig.4 Fundamental diagram for the bottleneck cell with capacity drop in the CTM

图5 Q学习策略仿真路段Fig.5 Hypothetical motorway stretch

表1 基本交通参数的标定值Table 1 Traffic parameters for calibration in CTM
为保证学习效果,本文的状态划分较细.对于下游密度,共包含了50个取值.其中,在关键密度(16.3 veh/km/ln)附近,每隔0.5 veh/km/ln进行选取,在自由流低密度和拥堵高密度附近,分别每隔1 veh/km/ln和1.5 veh/km/ln进行选取.上游密度每隔1 veh/km/ln选取,共有30个取值.匝道密度每隔0.2 veh/km/ln选取,共有6个取值.进行组合,状态集中共包含50×30×6=9 000种状态.策略的动作为采取的限速值,限速值的取值从110 km/h到30 km/h,每隔10 km/h选取.为降低总行程时间,回报函数的奖惩值依据下游消散流率进行设置:在关键密度附近附加额外奖励值,在拥堵密度附近附加惩罚值,以使产生奖励值高的动作策略被选择的趋势增加,反之,趋势减弱.
仿真中,本文假设驾驶员对限速值遵从度为
100%.仿真周期时长为5 min,在每个控制周期时长内,交通需求为固定值以使学习转化为确定性马尔可夫问题.Q值根据下式进行更新:

折减系数γ取值为0.8.在每个控制周期内,智能体(Agent)根据系统状态(下游密度、上游密度、匝道密度)采取策略(限速值),之后智能体根据收到的奖励值(正负)不断更新Q值,直到所有Q值不再变化,即Q值达到收敛为止.此时,每种状态下最大Q值所对应的策略即为最优策略.
4.3 Q学习可变限速策略效果评价
为更好地对Q学习策略的控制效果进行评价,将基于Q学习算法的可变限速策略与基于反馈控制算法的可变限速策略进行了对比.反馈控制的核心思想为根据实际交通密度与流量,通过调节限速系数b(k)的值,使密度与流量维持在期望值附近.为使反馈控制呈现更好的控制效果,对模型中的参数进行反复调试,选取了使总行程最小的模型参数.其中,KI’=7,Kp’=30,KI=0.000 4.
图6和图7分别反映了仿真中稳定和波动两种交通需求下,无可变限速控制、基于反馈算法的可变限速控制与基于Q学习算法的可变限速控制下的密度、速度、流量、及限速值变化情况.

图6 稳定交通需求下可变限速策略对交通流的影响(情景1)Fig.6 Impacts of VSL control strategies on stable traffic operations(scenario 1)
仿真中稳定交通需求下,当不采取任何策略时,交通流量在第0.4 h达到通行能力(6 956 veh/h),随着到达流量继续增加,在第0.5 h后,拥堵开始形成.由于通行能力下降,最大交通流量为6 480 veh/h.瓶颈区密度达到37.5 veh/km/ln,速度降到40 km/h.拥堵持续了大约2.4 h,直到仿真结束时拥堵才完全消散.基于反馈控制的可变限速策略阻止了瓶颈区交通拥堵的发生(如图6(c)),瓶颈区交通流基本维持在自由流状态.基于Q学习的控制策略对瓶颈区交通运行产生了相似的控制效果,但是与反馈控制策略相比,控制效果更为稳定.在波动的交通需求下,两种算法控制效果与稳定需求下相似,同样Q学习的结果更为稳定.
基于Q学习算法与基于反馈算法的可变限速控制策略主要有两点差异:①在瓶颈区拥堵形成阶段,反馈控制首先采用较低的限速值以缓解产生的交通拥堵,然后逐渐提高限速值到最优限速值,维持流率在最大通行能力附近.Q学习则始终维持限速值在最优值附近波动.②当交通需求较大时,反馈控制的限速值随交通量波动变化较频繁,基于Q学习的限速值则随交通状态变化相对稳定.这两点差异产生的原因主要是由于Q学习算法具有防止拥堵产生的自适应前馈控制能力,而反馈控制则具有一定的滞后性,在通行能力发生下降后,开始进行限速的.同时,由于反馈控制的限速值是基于模型得到的,对参数的变化较为敏感而处于不断变化中.
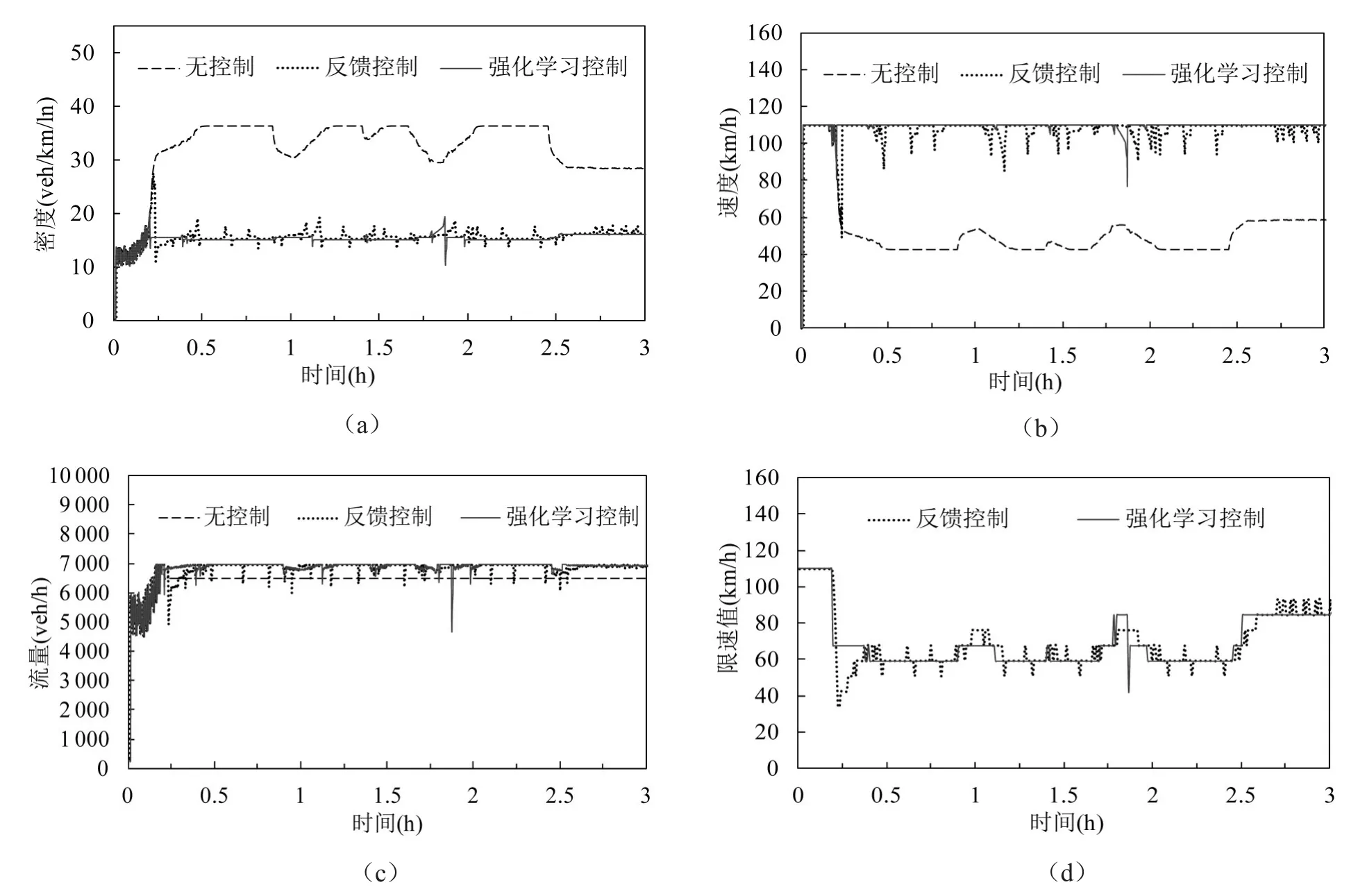
图7 波动交通需求下可变限速策略对交通流的影响(情景2)Fig.7 Impacts of VSL control strategies on noisy traffic operations(scenario 2)
控制策略对通行时间的影响如表2所示.稳定和波动交通流情况下,两种可变限速控制策略在减少总通行时间方面的控制效果显著.同样,Q学习策略对于降低通行时间具有更好的效果.
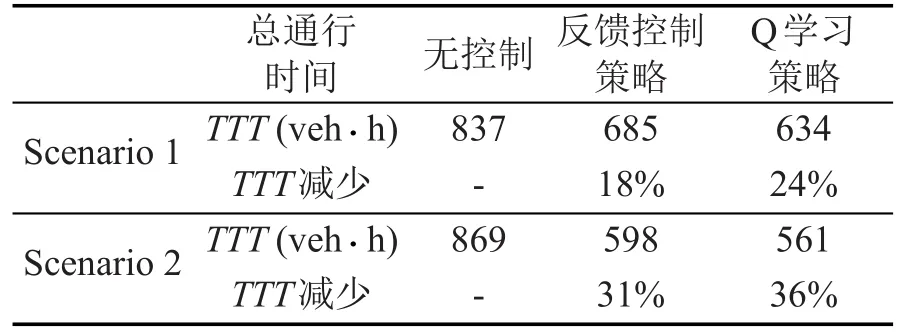
表2 可变限速策略对通行时间的影响Table 2 Effects of VSL control strategies on travel time
鉴于仿真得到的良好控制效果,下一步就是将基于Q学习的可变限速策略应用于工程实践,发挥可变限速控制与Q学习的潜力.系统的实现主要依赖于交通流检测器数据和可变情报板,系统根据每个周期时间间隔(如每5 min)的速度、占有率等状态数据进行限速值动作选择,根据输出的交通流量计算回报值,基于这些输入和输出,学习得到最优限速值,然后利用可变情报板将限速值发布给道路使用者.Q学习策略可以根据路段真实的交通情况进行在线学习,实时调整状态—动作对的Q值函数.通过这种在线学习方式,策略可以更好地适应例如驾驶员遵从度等不确定因素对学习效果带来的影响.
5 研究结论
结合强化学习和可变限速的特点,本文首次提出了基于Q学习算法的可变限速控制策略.在对策略中的关键要素进行了详细设计后,利用元胞传输模型仿真平台对策略的控制效果进行了效果评价.通行时间的降低和交通参数的变化表明,强化学习控制策略在提高汇流瓶颈区通行效率和改善交通流运行状况方面具有优越性.由于本文是在假设驾驶员对限速的遵从度为100%的基础上进行的,在今后的研究中,应注意考虑不同驾驶员对限速的实际遵从情况.并进一步探讨不同的参数选取及函数设置下,策略的学习控制效果.
[1]Cassidy M J,Rudjanakanoknad J.Increasing the capacity of an isolated merge by metering its onramp[J].Transportation Research Part B: Methodological,2005,39(10):896-913.
[2]Kang K P,Chang G L,Zou N.Optimal dynamic speedlimit control for highway work zone operations[J]. Transp.Res.Rec.,2004,1877:77-84.
[3]Hegyi A,Bart S D,Hellendoorn J P.Optimal coordination of variable speed limits to suppress shock waves[J].IEEE Trans.Intel.Transp.Syst.,2005,6(1): 102-112.
[4]Zhang J,Chang H,Ioannou P A.A simple roadway control system for freeway traffic[C].Minneapolis:Proc. American Control Conference,2006:4900–4905.
[5]Carlson R C,Papamichail I,Papageorgiou M.Local feedback-based mainstream traffic flow control on motorways using variable speed limits[C].Madeira Island,Portugal:13th International IEEE Annual Conference on Intelligent Transportation Systems,2010.
[6]Sutton R S,Barto A G.Reinforcement learning-an Introduction.[M].Cambridge,Massachusetts:MIT Press,1998.
[7]黄炳强.强化学习方法及其应用研究[D].上海交通大学,2007.[HUANG B Q.Research on the reinforcement learning method and application[D].Shanghai Jiaotong University,2007.]
[8]虞靖靓.基于Q学习的Agent智能决策的研究与实现[D].合肥工业大学,2005.[YU J L.The research and implementation of agent intelligent decision based on Q learning[D].HeFei University of Technology, 2005.]
[9]Rezaee K,Abdulhai B,Abdelgawad H.Self-learning adaptive ramp metering:analysis of design parameters on a test case in Toronto[C].Washington,D.C:92th Annual Meeting of TRB,2013.
[10]Veljanovska K,Bombol K M,Maher T.Reinforcement learning technique in multiple motorway access control strategy design[C].Intelligent Transport Systems(ITS) Preliminary Communication.Mar.19,2010.
[11]Abdulhai B,Pringle R,Karakoulas G J.Reinforcement learning for true adaptive traffic signal control[J]. ASCE Journal of Transportation Engineering.2003,129 (3):278-285.
[12]Watkins C,Dayan P.Q-learning.machine learning[J]. 1992,8(3-4):279-292.
[13]Daganzo C F.The cell transmission model-A dynamic representation of highway traffic consistent with the hydrodynamic theory[J].Transp.Res.B:Meth.,1994,28 (4):269-287.
Variable Speed Limit Control at Freeway Merge Bottlenecks Based on Reinforcement Learning 0
DUAN Hui1,LIU Pan2,LI Zhi-bin2,TANG Dou-nan3
(1.Jiaxing University,Jiaxing 314211,Zhejiang,China;2.Southeast University,Nanjing 210096,China; 3.University of California,Berkeley 94720-1714,USA)
To improve the efficiency of freeway merge bottleneck,this paper optimizes the bottleneck variable speed limit strategy.Considering the characteristics of reinforcement learning that it is modelingfree and intelligent learning,a QL-VSL control strategy that integrates the Q-learning(QL)algorithm in the VSL control is proposed for the first time.The goal of the strategy is to maximize the outflow vehicle,it is adaptive learning through traversing traffic flow states and taking different speed limits.The cell transmission model(CTM)calibrated with the real traffic data is used for the simulation.The effectiveness of the proposed QL-VSL control strategy is evaluated with no VSL control and the feedback VSL control in the simulation.The travel time reduction and traffic parameter changes show that the proposed QL-VSL control strategy outperforms in improving the traffic efficiency and traffic operations at freeway merge bottlenecks.
intelligent transportation;variable speed limit;reinforcement learning;freeway merge bottleneck;Q-learning
1009-6744(2015)01-0055-07
:U491
:A
2014-08-11
:2014-12-08录用日期:2014-12-19
国家自然科学基金资助项目(51322810).
段荟(1988-),女,辽宁丹东人,助教. *
:panliu@hotmail.com
