基于开源技术的网络数据采集系统设计
2015-04-13中讯邮电咨询设计院有限公司北京100048
尧 炜(中讯邮电咨询设计院有限公司,北京100048)
0 前言
随着大数据时代的来临,企业数据所蕴藏的潜在价值越来越被重视。对电信运营商来说,海量的网络数据有着广泛的应用场景。针对用户,可用于用户体验分析、用户行为分析、精细化营销、辅助处理客户投诉等;针对网络,可精准地指导网络规划、网络建设及网络优化。要挖掘网络数据的价值,必须采集分布在各个设备上的数据并进行汇集,因此各大运营商均在着手建设集中的网络数据采集系统。
电信运营商内部IT 系统对于技术稳定性要求非常高,往往会优先考虑使用成熟的商业软件外加二次开发,并且由于建设起步较早,经过多年的发展各个系统已经比较成熟和稳定。因此,电信运营商对于全部采用开源技术的态度比较保守。
然而以Hadoop、Spark 为核心已经形成了广泛的开源技术生态圈,覆盖了数据采集、数据处理、数据挖掘、数据共享等各个环节。Hadoop、Spark 技术已成为大数据领域的标配。
鉴于开源技术在大数据技术领域已经占据了主导地位,同时使用开源技术也是去IOE的必然要求,本文将分析电信运营商网络数据采集的特点,并以积极拥抱开源技术的态度,借鉴互联网行业类似系统的设计经验,探讨网络数据采集系统的架构设计。
1 系统架构设计
1.1 网络数据采集特点分析
网络数据采集具有以下4个特点。
第一个特点是数据源种类多。从数据来源看,可分为网元、网管、OMC、网优以及分光后DPI解析等;从专业看,可分为移动网、固网交换、传输网、互联网、IP承载网、宽带接入、业务平台、动力环境等;从数据用途看,可分为性能数据、配置数据、告警数据、信令数据、用户面数据、投诉数据等。
第二个特点是数据消费者多。电信运营商内部的IT 系统经过多年的发展,形成了相对稳定的应用架构,各个系统之间分工比较明确,各个系统都有可能是网络数据的消费者,例如网管/监控类应用、运维工单类应用、资源管理类应用、客户支撑类应用、网络规划类应用、网络建设类应用、网络优化类应用,用户行为分析类应用。此外,由于运营商目前普遍没有完全实现IT系统的集中化,在IT系统由二级架构向一级架构转变的过程中,网络数据消费者既包括总部系统,也包括省分系统。
第三个特点是数据总量大。通常每天采集的网络数据总量将达到几百TB,随着4G终端的普及、用户流量使用习惯的改变,未来数据量仍将持续高速增长。
第四个特点是既有实时数据又有批量数据。严格来说,网络数据都是实时产生的,但是由于网络设备不同于IT系统,有很大一部分网络设备产生数据的方式是周期性地生成数据文件,因此只能通过批量发送文件的方式采集数据。典型的实时数据是告警类数据,典型的批量数据是经DPI解析后的信令数据。
1.2 设计目标
根据对网络数据采集特点的分析,结合应用系统对网络数据采集系统能力要求的预期,针对网络数据采集系统提出了以下设计目标。
a)支持关键网络指标实时计算、查询。
b)支持在一套框架下适配多种数据源。
c)支持多个数据消费者,且同时支持在线和离线处理。
d)支持实时采集和批量采集数据。
e)系统具备线性扩展能力。
1.3 系统架构
根据上述设计目标,本文提出的网络数据采集系统架构如图1所示,架构中采用了Flume、Kafka、Storm、Hadoop、Hive/Impala、Spark、MySQL 等一系列开源技术,架构说明如下。
a)Flume Agent运行在产生数据的服务器(即数据源)上,负责实时采集数据并发送给Kafka集群。通过配置不同的source,可以灵活地适配多种数据源采集数据,经过Channel 输出至sink,如果sink 配置为kafka则该sink 就是Kafka 中的Producer。如果本省系统有同样的数据需求,可通过设置多个sink来实现。
b)Kafka 集群是整个采集系统的中心,可以对采集到的数据进行缓冲,供多个Consumer消费。不同的Consumer 可以消费相同的数据(通过设置相同的Top⁃ic,不同的Consumer Group 实现),也可以消费不同的数据(通过设置不同的Topic 实现)。Consumer 可以在线处理,也可以离线处理。
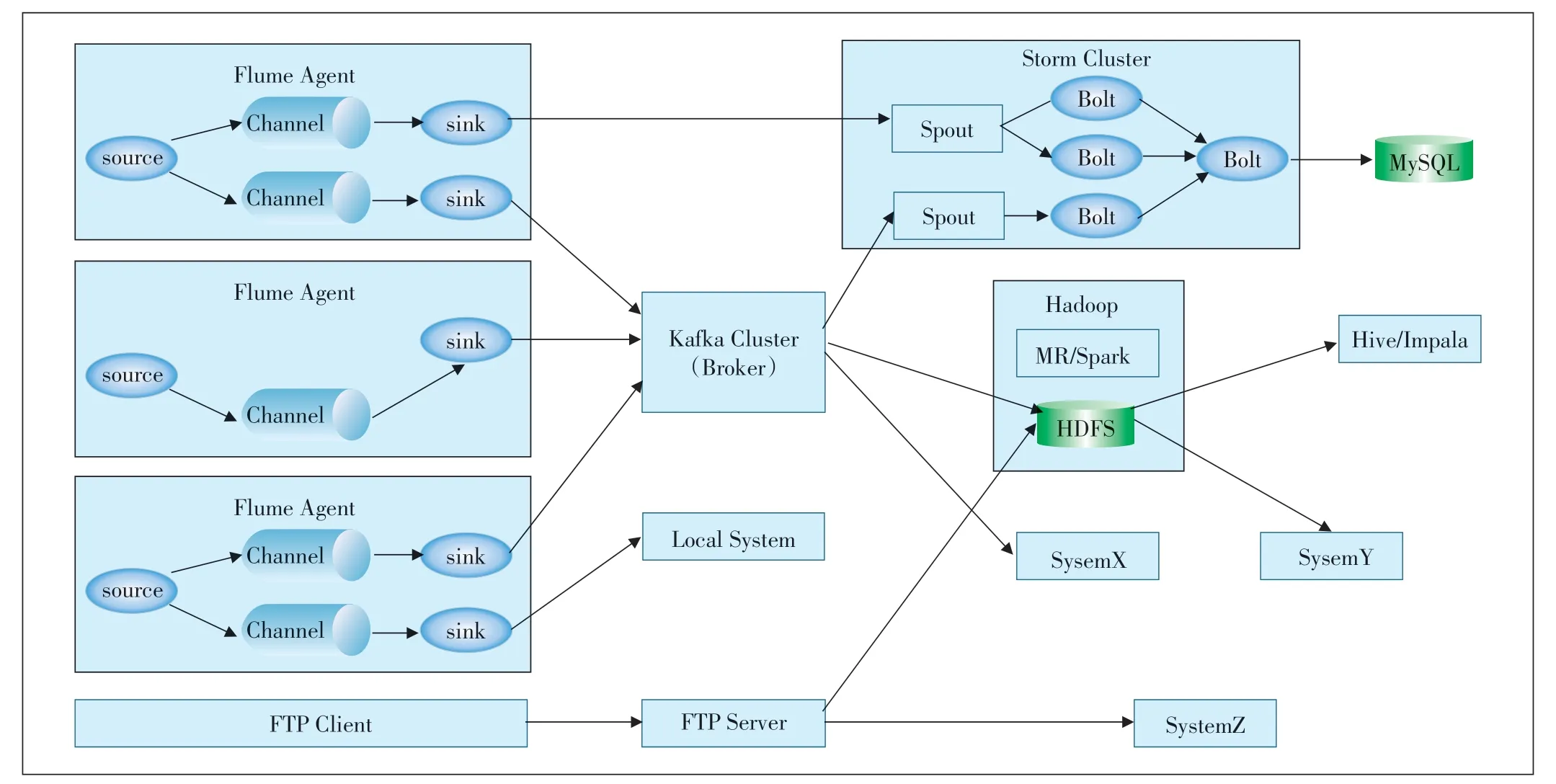
图1 网络数据采集系统架构
c)省分系统需要同时在线和离线处理网络数据,或者考虑到数据源不宜接入总部网络,可以考虑在省分搭建一个前置的Kafka集群,将总部Kafka集群和省分系统分别设置为前置Kafka 集群的消费者,并且分属不同的Consumer Group。
d)Storm 集群为Kafka 的Consumer,负责实时计算,例如计算关键网络指标,处理告警等。Storm 集群在实时处理数据时,还可以有其他的数据输入,例如接收外部事件、查询历史数据等,数据处理的结果写入关系型数据库,供应用查询。
e)Hadoop/Spark 集群同样是Kafka 的Consumer,负责批量数据处理,例如解码合成、格式转换,处理结果可以保存成Parquet格式,供数据分析使用。
f)Hive/Impala 面向分析人员提供ad-hoc 查询能力。
g)FTP 传输通道适用于无法实时产生数据,只能周期性地生成数据文件并且文件较大(即对吞吐量要求高)的数据源。如果存在数据源是关系型数据库的情况,也可以使用Sqoop 批量采集数据至HDFS。FTP传输通道带来的劣势是从数据产生到分析人员得出分析结果,通常需要花费几个小时或几天时间。
h)其他系统可以通过订阅Kafka 的Topic、从FTP下载或从HDFS读取等多种方式获得所需数据。
i)关于扩展性,Kafka 集群、Storm 集群、Hadoop 集群均具备线性扩展能力,FTP仅作为文件传输通道,通过为不同地域、不同数据合理分配FTP 服务器即可扩展。
1.4 技术成熟度
架构中所使用的均是目前开源社区中炙手可热的技术,其中MySQL、Hadoop、Hive、Impala等已被大家熟知,而Flume、Kafka、Storm 均是Apache 的顶级开源项目,被全世界范围内许多知名公司所采用。Kafka已被Linkedin、Yahoo、Twitter、Netflix、Uber、PayPal 等多家公司使用,在Apache Kafka 官方wiki上登记使用了Kafka的公司超过70 家。根据最新披露的数据,在Linkedin每天利用Kafka处理的消息超过1万亿条,在峰值时每秒钟会发布超过450 万条消息,每周处理的信息是1.34 PB,每条消息平均会被4个应用处理。Storm已被Yahoo、阿里巴巴、淘宝、支付宝、百度、爱奇艺等多家公司使用,在Apache Storm 官方网站上登记使用的公司超过80 家。Flume 最早由Cloudera 开源,目前已经更新至1.6.0版,广泛用于日志采集的场景。
这些开源技术发展已相对成熟,案例丰富、社区活跃、文档完备,电信运营商使用起来风险较小。
2 架构实施面临的挑战及应对策略
2.1 应对不熟悉开源技术的挑战
目前,电信运营商IT系统的建设从完全外包逐步转向自主研发,自有开发人员规模普遍较小,对开源技术不熟悉。为了跟上技术发展的潮流,需加快自主研发队伍的建设,通过引入对相关技术有丰富使用经验的人员来弥补不足。在项目实施过程中应坚持先小范围使用验证,再逐步推广的原则以降低风险。
2.2 应对数据源适配的挑战
从技术上看,Flume 支持的source 类型非常丰富,如Avro、Thrift、Exec、JMS、Syslog 等,如果默认不支持(例如Corba),可通过开发自定义的source来解决。对于一些不同于IT 系统的专业设备,无法直接运行Flume Agent,短期的解决办法是利用批量采集通道采集数据;长远来看提高专业设备的IT化程度才是彻底的解决办法。
2.3 应对海量网络数据对性能要求高的挑战
电信运营商每天采集的网络数据可能是几百TB,对于采集系统的性能是极大的挑战。上述架构中各个集群在一定规模内都具备线性扩展能力(集群规模上限需要实际使用中逐步验证),如果单集群无法达到性能要求,可以根据采集系统上承载的业务量、集群处理能力以及处理能力随集群大小变化曲线,合理地规划1 个或多个集群,集群划分的依据可以是地域、设备商、设备类型等。
2.4 应对开源软件安全功能支持不足的挑战
开源软件对于企业级安全功能的支持通常比较弱,比如Kafka 最新版本0.8.2.2 还没有任何安全功能(预计下个版本将会支持Kerberos 认证、ACL 鉴权、加密通信等),对此需做好以下几点。
a)由于采集系统及相关外围设备、系统均属于企业内部,通过管理手段增强安全性相对容易。
b)利用企业内已有的安全机制,包括网络、访问控制、审计等。
c)对于不允许直接访问的情形,可以通过代理提供REST API的方式来实现。
d)如果具备足够的研发能力,可以对开源软件的安全功能进行增强。
3 结束语
本文针对网络数据源种类多、数据消费者多、数据量大、实时与批量数据并存的特点,明确了网络数据采集系统的设计目标,据此采用Flume、Kafka、Storm、Ha⁃doop、Spark、MySQL 等一系列开源技术设计了系统架构,并针对架构实施可能面临的一些挑战提出了应对策略。
大数据推动了跨行业的业务竞争与合作,同样也推动了开源技术的发展。电信运营商在设计大数据系统架构时,应该以开放包容的心态勇敢地采用开源技术,多参与开源社区交流,借鉴全世界优秀公司的先进经验,充分利用自身丰富的数据资源创造更多价值。
[1] 施巍巍.电信运营商对大数据的应用[J].中国新通信,2015(3):27-28.
[2] 周龙,陈喜珠,彭江强.运营商IT支撑系统“去IOE”思路探讨[J].电信工程技术与标准化,2015(6):55-60.
[3] 雷蕾,李景文,宫大鹏,等.基于Hadoop的OSS域数据建模与采集方法研究[J].电信科学,2015,31(1):128-138.
[4] 人工智能.电信行业大数据应用实践和思考[EB/OL].[2015-09-28].http://labs.chinamobile.com.
[5] 王长武.移动互联网下的运营商大数据应用浅析[J].电子技术与软件工程,2014(13):45-45.
[6] 郭俊.Kafka背景及架构介绍[EB/OL].[2015-09-28].http://www.infoq.com/cn.
[7] 美团.基于Flume 的美团日志收集系统[EB/OL].[2015-09-28].http://tech.meituan.com.
[8] yanbohappy. Impala/Hive 现状分析与前景展望[EB/OL].[2015-09-28].http://yanbohappy.sinaapp.com.
[9] Apache Software Foundation. Sqoop User Guide[EB/OL].[2015-11-5].http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.htm l.
[10]Jun Rao.Apache Kafka Powered By[EB/OL].[2015-11-5].https://cwiki.apache.org/.
[11] Kartik Paramasivam. Linked In 是 如 何 优 化Kafka 的[EB/OL].[2015-11-5].http://www.infoq.com/cn/articles/linkedIn-improvingkafka.
[12] Apache Software Foundation. Companies Using Apache Storm[EB/OL]. [2015- 11- 5]. https://storm.apache.org/documentation/Pow⁃ered-By.htm l.
[13] Apache Software Foundation. Flume User Guide[EB/OL].[2015-11-5].http://flume.apache.org/FlumeUserGuide.htm l.
[14]朱拥华.CORBA 技术在构建电信综合网管系统中的应用[J].电信工程技术与标准化,2004(7):67-71.
[15] Apache Software Foundation,Apache Kafka Security[EB/OL].[2015-11-22]. https://cwiki.apache.org/confluence/display/KAFKA/Security
