面向海量新闻数据的HDFS节能存储策略
2015-01-01钟将,杨雷
钟 将,杨 雷
(重庆大学计算机学院,重庆400044)
1 概述
随着云计算技术的不断完善和普及,在继追求性能、容量、容错、安全性等指标之后,绿色节能逐渐成为该行业内的新标准。文献[1]指出2008年路由器、交换机、服务器、冷却设备等互联网设备总共消耗8 680亿度电,占全球总耗电量的5.3%。本文针对新闻媒体机构中急需高效管理的海量文本、图片、音频和视频新闻数据,对传统HDFS文件存储策略进行优化以实现节能降耗,同时平衡节点负载。
当前学术界主要围绕Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)节能管理展开研究[2]。一些学者通过对计算负载分类学习或者实时迁移存储数据等手段[3-5]减少服务器运行时的能耗;还有一些学者主要研究如何减少对整个数据中心基础设施的冷却成本[6-7]。现有研究成果虽然节能明显,但与传统HDFS一样,采用基于机架感知[8]的数据块存储策略使得数据块在集群中的分布具有随机性,该策略一方面会导致整个集群的数据分布出现不均衡的情况,特别是有新节点加入时,新节点和原有节点上的分布不均,新增节点需要经历较长时间甚至人工操作,才能与现有节点实现数据均衡分布,这样在分配MapReduce任务时,新节点可能分配不到可执行的任务,浪费新增节点的计算和存储能力[9-10]。另一方面,不同文件间的访问规律存在巨大差异,如果使HDFS集群中所有数据节点都处于活跃状态,势必造成能耗的增加,导致大量电能被浪费[11]。
在实际应用中,新闻类数据的访问具备一定访问规律,可在传统HDFS基础上进行针对性优化,以改善HDFS存取效能。本文研究维基新闻网站访问日志,分析新闻数据访问的分布规律,提出针对海量新闻数据的高效存储策略。该策略通过数据节点分区、具有最大活动剩余空间的节点优先匹配、文件迁移和节点待机等机制对整个HDFS实施节能降耗,同时使得集群中各节点的数据分布保持均衡,提高整个系统的计算效能。
2 Hadoop分布式文件系统
HDFS[12]是Google文件系统(Google File System,GFS)进行开发,采用主/从(Master/Slave)架构,包含一个名字节点(NameNode)和多个数据节点(DataNode)。名字节点是管理节点,用于管理数据节点和客户端对文件的访问。如图1所示,HDFS存储的文件被分成若干个64 MB大小的块(Chunk),而DataNode用于存储这些数据块。DataNode分布在多个机架(Rack)中,DataNode间通过机架网络进行通信。每个DataNode定期向NameNode发送心跳信息,以此报告该节点的状态信息和存储的数据块信息。

图1 HDFS框架
如图2所示,HDFS副本机制基于机架感知。每个数据块会有多个副本,其默认值为3,对3个副本的存放策略为:第1份放在本地节点上;第2份放在另外一个Rack的某一节点上;第3份放在与第2份相同Rack的另一节点上。虽然HDFS对于Rack的确定是有选择的,但对于节点的确定却具有一定随机性,导致数据在集群中分布不均。

图2 HDFS副本机制
3 HDFS节能存储策略
通过对HDFS文件存储机制的改进,采取数据节点分区策略、具有最大活动剩余空间的节点优先匹配策略、文件迁移策略和节点待机等策略以达到节能省电和数据分布均衡的目的。
3.1 数据节点分区策略
如图3所示,该策略是将所有DataNode逻辑上分为HotRackZone和ColdRackZone 2个区域。HotRackZone中的DataNode处于全天活跃状态,称为HotDataNode,性能最佳,但能耗高;ColdRackZone中的DataNode默认处于待机状态,称为ColdDataNode,虽然读文件响应时间可能会受到影响,但能耗较低。当新创建文件时,文件所有副本都放入HotRackZone的节点中,以保证良好的读取性能。采取分区策略的目的是使HotRackZone中的节点保证文件访问响应低时延和可靠性,同时使ColdRackZone中的节点尽量待机以降低能耗。

图3 数据节点分区策略
3.2 具有最大活动剩余空间的节点优先匹配策略
对ColdRackZone中的节点而言,有数据块需要写入时,优先匹配剩余空间最大且处于活动状态的DataNode。而对HotRackZone中的节点,则只需优先匹配剩余空间最大的节点。
选择剩余空间最大的节点,一方面能使新数据块快速分布到负载较轻的节点中,使集群中的数据尽量分布均衡,从而自动调节负载;另一方面使创建时间相近的文件尽量分散到不同节点中,以便将来被访问时不至于一直访问同一节点而导致该节点无法进入待机状态。同时,优先选择处于活动状态的节点,则可以减少已待机节点被唤醒的可能,达到更好的节能效果,其流程如图4所示。

图4 具有最大活动剩余空间的节点优先匹配流程
当ColdRackZone中优先匹配剩余空间最大的节点时,考虑以下2种方案。方案1:直接选择剩余空间最大的节点,不考虑数据分布均衡的问题。该方案会使ColdRackZone中有较多数据分布不均衡的节点出现,访问文件时需要唤醒节点的次数较多,影响数据访问效率,但优点是集群的耗电量低,有较好的节能效果。方案2:所选择的节点空间使用率不大于ColdRackZone中所有节点平均使用率。这相当于在写入数据时有选择性地进行平衡数据分布,可以使得ColdRackZone中过载或负载的节点非常少,实现数据分布的自均衡,提高集群的服务效率,但缺点是耗电量会有所增加。
该策略需要在NameNode上增加HotNodeList和ColdNodeList 2张表来保存节点的主要信息,一旦节点有数据操作时,需要实时更新表中数据。节点的剩余空间、所处状态等信息可直接从节点的心跳信息中获得。HotNodeList用于维护HotRackZone中所有节点存储空间使用情况、节点所处状态、节点最后一次访问时间等信息,并按可用空间大小降序排列,以便有新数据块需要写入时,能快速匹配到最合适的节点。类似地,ColdNodeList用于维护ColdRackZone中所有节点的信息。
3.3 文件迁移策略
本文选择新闻网站作为研究对象是因为新闻网站较其他网站(比如,搜索引擎、交友网站等)更具时效性,所以其访问的规律性更强,便于进行针对性的优化。通过对维基英文新闻网站的访问日志数据的分析,统计了1 000条新闻数据从创建开始之后10d内的叠加访问量。如图5所示,文件自创建起的3d内访问量较大,其访问量几乎占10d内访问总量的60%;7 d内的访问量占10 d内访问总量的88%;而10 d之后文件通常很少再被访问。

图5 10d内的新闻叠加访问量
从以上访问规律可以看出,文件自创建之后每天的访问量呈递减趋势,需要将HotDataNode中驻留时间超过驻留时间阈值Texsisted和前一日访问量小于日最低访问量阈值Taccessed的文件迁移到ColdDataNode中。因为随着文件驻留时间增加,文件被访问的次数逐渐降低,这些访问量较低的文件会大量占据HotDataNode存储空间,将这些文件移动到ColdDataNode中,能有效利用HotDataNode的存储空间。同时,由于ColdDataNode默认是处于待机状态,即如果没有写入或读取任务时,则使节点待机,可以较大幅度地降低能耗。其中,Texsisted是根据图5访问规律曲线中阶段性下降幅度较大的2个时间点确定的;Taccessed是根据经验确定的,如实验中认为日最低访问量小于5次的文件就属于“冷门”文件。文件迁移流程如图6所示。
由于对文件进行迁移会影响整个系统的效率和性能,因此如果在访问的非高峰时段来实施,则会最大限度降低策略对性能的影响。通过对访问日志的统计发现,每天02:00-04:00为网站访问量的低峰期,文件迁移策略可以在此时间段内进行。
3.4 节点待机策略
该策略只在ColdRackZone中进行,其目的是为了使ColdRackZone中的节点在没有读写任务时被置为待机状态,降低ColdRackZone的总能耗。上文已指出在ColdNodeList表中记录了节点最后一次被访问的时间,同时设定了一个节点待机时间阈值Tidle,在每个小时末遍历表中所有节点,如果节点最后一次访问时间与当前时间之差大于节点待机时间阈值Tidle,则将该节点置为待机状态。ColdDataNode待机流程如图7所示。

图7 ColdDataNode待机流程
3.5 ColdDataNode被唤醒的情况
因为有数据的写入和读取,所以ColdDataNode会在以下2种情况时会被唤醒:
(1)HotDataNode中满足一定条件的文件迁移到处于待机状态的ColdDataNode时。该情况是可控的,在每天非高峰时段进行。
(2)已经移动到ColdDataNode中的文件再次被访问时。如果再次被访问的文件位于已经由其他任务唤醒的节点上,则文件可以直接被访问,响应时延不会增加;如果文件位于待机状态的节点上,则需要唤醒该节点,就会增加响应时延。该情况的发生是随机、不可预测的。
4 实验结果与分析
实验模拟一个拥有120个数据节点的HDFS集群,数据节点功耗[3]如表1所示。

表1 数据节点功耗
实验所用数据集来自于维基英文新闻网站一个月的访问日志。实验前对数据集进行预处理,假设新闻中包含图片、视频等多媒体资料,因此对日志中的文件大小进行放大2 000倍操作,最终访问记录中包含28.3×104个文件,总数据量为66 TB。实验各项参数设置如表2所示。

表2 实验参数设置
4.1 集群耗电量分析
采用下式计算集群耗电量:

其中,Pn表示第n个节点的功率(假设节点在表1所示的额定功率下工作);Tn表示第n个节点的总工作时间。传统HDFS集群和HotRackZone节点的月耗电量的计算简单,不再赘述。ColdRackZone中的节点能耗,分为节点处于活跃状态和节点处于待机状态两部分进行计算。

图8为增加了节能策略的HDFS与传统HDFS月耗电量对比。图8(a)采用3.2节中的方案1在驻留时间阈值Texsisted=3时的集群耗电量,可以看出节能HDFS的月耗电量不足传统HDFS的70%。图8(b)为采用3.2节中方案2在驻留时间阈值Texsisted=7时的集群耗电量,该方案的耗电量较方案1有所增加,但仍比传统HDFS省电20%以上。无论采用哪个方案,随着驻留时间阈值Texsisted的增大,其节能效果也更好。这是因为随着Texsisted的增大,移动到ColdDataNode中的文件被访问的次数会更低,节点待机概率和时间都会增大。
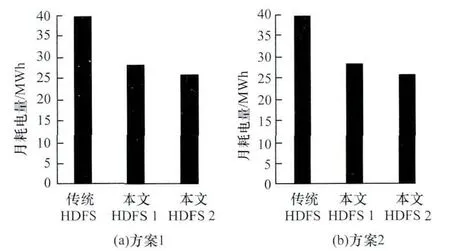
图8 月耗电量比较
图9和图10为当驻留时间阈值Texsisted=7,分别采用3.2节中的方案1和方案2时,ColdRackZone中全部节点的每天活动情况。采用方案1时,随着时间的推移,待机过的节点数量始终大于总数的50%,而采用方案2时,待机过的节点数量约占总数的25%。集群整体节能省电目标的实现正是依赖于这些没有任务而待机的节点,同时也解释了方案2比方案1耗电量更大的原因。

4.2 ColdRackZone中节点使用率分析
本文不对HotRackZone中节点的使用率情况进行分析,因为HotRackZone中的节点一直处于活跃状态,对文件读取或访问非常高效。并且当有数据需要写入时需优先匹配剩余空间最大的DataNode,因此,节点使用非常均衡,在此不做详细分析。
图11和图12表示当驻留时间阈值Texsisted=7,分别采用3.2节中方案1和方案2时,ColdRackZone节点的使用情况。

如图11所示,ColdRackZone中始终存在使用率已达上限和使用率为0的节点,初步表明该区域的数据分布不均衡。在10d~22d阶段,平均使用率曲线与最低使用率曲线相距较近,说明在此阶段多数节点使用率很低,只有少数节点使用率很高。在22d~31d阶段,平均使用率曲线与最大使用率曲线相距较近,说明此阶段大多数节点使用率都很高,同时仍然有使用率非常低甚至使用率为0的节点,进一步证明方案1存在使节点数据分布不均衡的情况发生。
如图12所示,ColdRackZone中所有节点的平均使用率曲线始终与最大使用率曲线几乎重叠,这表明采用方案2会使节点的数据分布更均衡。在10d~20d阶段,仍然存在数量极少的低使用率节点,这是因为采用HDFS机架选择机制,当数据量达不到足够量时,不会使每个节点都写入数据,也就是说存在空闲节点。当20d后,当移入的数据量越来越多时,最大使用率和最小使用率之差会逐渐减小,数据分布也会趋于平衡。
图13为当驻留时间阈值Texsisted=7时,每天需要迁移的文件数量和数据量。平均每天迁移约8×103个文件,共1.92TB的数据量。假设每个ColdDataNode拥有4个1TB的硬盘,平均每天有2TB的数据需要移入,按照带宽为80MB/s计算,该操作能在2h内完成,这与3.3节统计出每天02:00-04:00是访问低峰期的规律相契合,这也证明了文件迁移策略的可行性。

图13 迁移文件数量和数据量的变化情况
4.3 本文策略对读取文件响应时间的影响
假设不考虑传输时延因素,传统HDFS读取文件响应时间是系统处理时间,而本文节能存储策略由于要使部分节点待机,如果此时要读取的文件恰好位于待机节点上,则读取文件的响应时间还要加上唤醒节点所需的时间。
当驻留时间阈值Texsisted=7且采用3.2节中方案1时,如果文件驻留时间选择3d或者7d,那么在2 041 921次访问中只有734次访问需要唤醒冷节点,不到0.05%的文件访问会出现唤醒数据节点而造成响应时延增加。当驻留时间阈值Texsisted=7且采用3.2节中方案2时,文件访问会出现唤醒数据节点的次数下降为356次,占总访问次数的0.02%,说明方案2在读取响应时间上略优于方案1。综上所述,无论采用哪种方案,99.9%以上的文件访问均在热节点上,因此本文设计的节能策略对系统读文件响应时延的影响都较小。
本文节能策略对文件创建时的写操作没有影响,因为此时的写操作发生在HotRackZone节点中。而文件迁移时的写操作可能会出现需要唤醒节点的情况,但本文采取了优先匹配活动节点和迁移访问低峰期的节点降低这种负面影响,并且对于新闻数据,读取和访问效率更值得关注。
5 结束语
本文在传统HDFS文件存储的基础上加入节能策略,提出一种针对海量新闻数据存储的节能Hadoop分布式文件系统。通过仿真实验证明了该策略的可行性,对比分析了具有最大活动剩余空间的节点优先匹配策略中2种不同节点选择方案的优劣,但无论选择哪种方案系统都有较好的节能效果,并且节能策略对文件读取访问效率的影响较小。如果采用3.2节中方案2的节点选择机制,能在一定程度上解决集群中数据分布不均的问题,使得集群的存储管理更高效。但对访问日志进一步的观察发现,对于热度高的新闻和热度低的新闻,驻留时间阈值Texsisted和日最低访问量阈值Taccessed的取值是不同的,如果按照静态的固定值来计算,则会对节能效果产生一定的负面影响。因此,下一步将通过动态设置Texsisted和Taccessed,以取得更高的节能效率。另外,本文策略会使集群中出现负载或过载的节点,在今后工作中将进一步研究数据分布自均衡问题。
[1]Yun D,Lee J.Research in Green Network for Future Internet[J].Journal of KIISE,2010,28(1):41-51.
[2]刘晨光.面向 Hadoop存储系统的节能优化技术研究[D].武汉:华中科技大学,2012.
[3]Kaushik R T,Bhandarkar M,Nahrstedt K.Evaluation and Analysis of GreenHDFS:A Self-adaptive,Energy-conserving Variant of the Hadoop Distributed File System[C]//Proceedings of the 2nd International Conference on Cloud Computing Technology and Science.Washington D.C.,USA:IEEE Press,2010:274-287.
[4]Kaushik R T,Bhandarkar M.GreenHDFS:Towards an Energy-conserving, Storage-efficient, Hybrid Hadoop Compute Cluster[C]//Proceedings of USENIX Annual Technical Conference.Vancouver,Canada:USENIX Press,2010:109-112.
[5]廖 彬,于 炯,张 陶,等.基于分布式文件系统HDFS的节能算法[J].计算机学报,2013,36(5):1047-1064.
[6]Leverich J,Kozyrakis C.On the Energy(In)Efficiency of Hadoop Clusters[J].ACM SIGOPS Operating Systems Review,2010,44(1):61-65.
[7]Lang W,Patel J M.Energy Management for MapReduce Clusters[J].Proceedings of the VLDB Endowment,2010,3(1/2):129-139.
[8]蔡 斌.Hadoop 源 码 分 析 [EB/OL].[2014-04-17].http://caibinbupt.iteye.com/.
[9]Wirtz T,Ge R.Improving Mapreduce Energy Efficiency for Computation Intensive Workloads[C]//Proceedings of 2011International Green Computing Conference and Workshops.Washington D.C.,USA:IEEE Press,2011:1-8.
[10]Maheshwari N,Nanduri R,Varma V.Dynamic Energy Efficient Data Placement and Cluster Reconfiguration Algorithm for MapReduce Framework[J].Future Generation Computer Systems,2012,28(1):119-127.
[11]Kaushik R T,Abdelzaher T,Egashira R,et al.Predictive Data and Energy Management in Green HDFS[C]//Proceedings of 2011International Green Computing Conference and Workshops.Washington D.C.,USA:IEEE Press,2011:1-9.
[12]Apache.Apache Hadoop[EB/OL].[2014-04-17].http://hadoop.apache.org/.
[13]Wikipedia.Pagecount files for 2014[EB/OL].[2014-04-17].http://dumps.wikimedia.org/other/pagecounts-raw/2014/.
