一种不确定信息进行推理的人工智能评价系统
2014-11-28杨荣领YANGRongling林辉LINHui安生阳ANShengyang梁万英LIANGWanying黄景胜HUANGJingsheng
杨荣领YANG Rong-ling;林辉LIN Hui;安生阳AN Sheng-yang;梁万英LIANG Wan-ying;黄景胜HUANG Jing-sheng
(华南理工大学广州学院,广州 510800)
(Guangzhou College of South China University of Technology,Guangzhou 510800,China)
0 引言
如今社会上的评价系统还存在一些不确定的因数影响评价质量,有些人认为评价系统不公平,为了能更公平地解决这些问题,该项目起到重要的作用。就举个例子:大学的教师评价系统,就督导而言,他就有权威性,但是他不会每个教师的都去听,这点就会让老师觉得有点不公平。得出的结果让很多老师无法接受,教师评价系统除了这个因素外,还有些因素是该系的学生很多,算出来的评价很高,得出的结论也不准确。
为了能更全面更科学更公正地评价这些不确定的信息,将不确定的因数进行推理和分析,得出一个准确的结论,这是我们所需要的。
1 人工智能评价系统所存在的问题
项目主要研究的内容是:首先该项目的评价系统模型需要评价的样本点x1,x2,x3,…,设A 是同学的评分,占a%;B 是老师的评分,占b%;C 是督导的评分,占c%。C 具有权威性,但是同时它具有不确定性,不一定每个教师都去听课。A,B 都能得到所需的数据,C 能对该系统的评价质量有较准确的评价,误差较小。本模型在此基础上,通过统计分析,以图寻找一种较好的较公正的质量评价方法。
2 解决思路
我们想通过对于没有督导(C)评价的教师进行调整A,B 的比重来让系统进一步实现公平。
研究方法一:对具有权威数据C 项的样本进行质量排序,设A、B 项数据服从正态分布,以A,B 项数据对所有样本进行质量排序,计算该排序结果与仅仅C 项排序结果的误差方差D,通过调整A,B 项数据的比重使得方差D最小,得到样本点的较好的质量评价结果。
该模型中的样本点的质量数据信息不全是完善的,有部分样本点只有A,B 项数据,有部分样本点有A,B,C 项数据,如何利用不完善的信息对样本点进行质量排序。
解决方案:对具有权威数据C 项样本点进行质量排序,设A,B 项数据误差服从正太分布,以A,B 项数据对所有样本点进行质量排序,计算该排序结果与只有C 项排序结果的误差方差D 最小,这样得到样本点的较好的质量评价结果。
设某模型的样本点为x1,x2,x3…,A,B,C 是获取样本点质量评估的数据,A 占a,B 占b,C 占c。a+b+c=1;把含有C 的样本归为一类Q,设αi,βi,γi分别为第i 个样本在A,B,C 上的平均分数。Yi为xi在A,B,C 的总评分,Yi=αi*a+βi*b+γi*c,根据总评分来质量排序J,在Q 中A,B 服从正态分布,A 占e,B 占d,令e+d=1;Zi为xi在A,B 的总评分,Zi=αi*e+βi*d;根据总评分来质量排序K,m 为含C样本总数,方差通过调整A,B 的比重,使D 尽可能地小,让排序J 和排序K 接近。
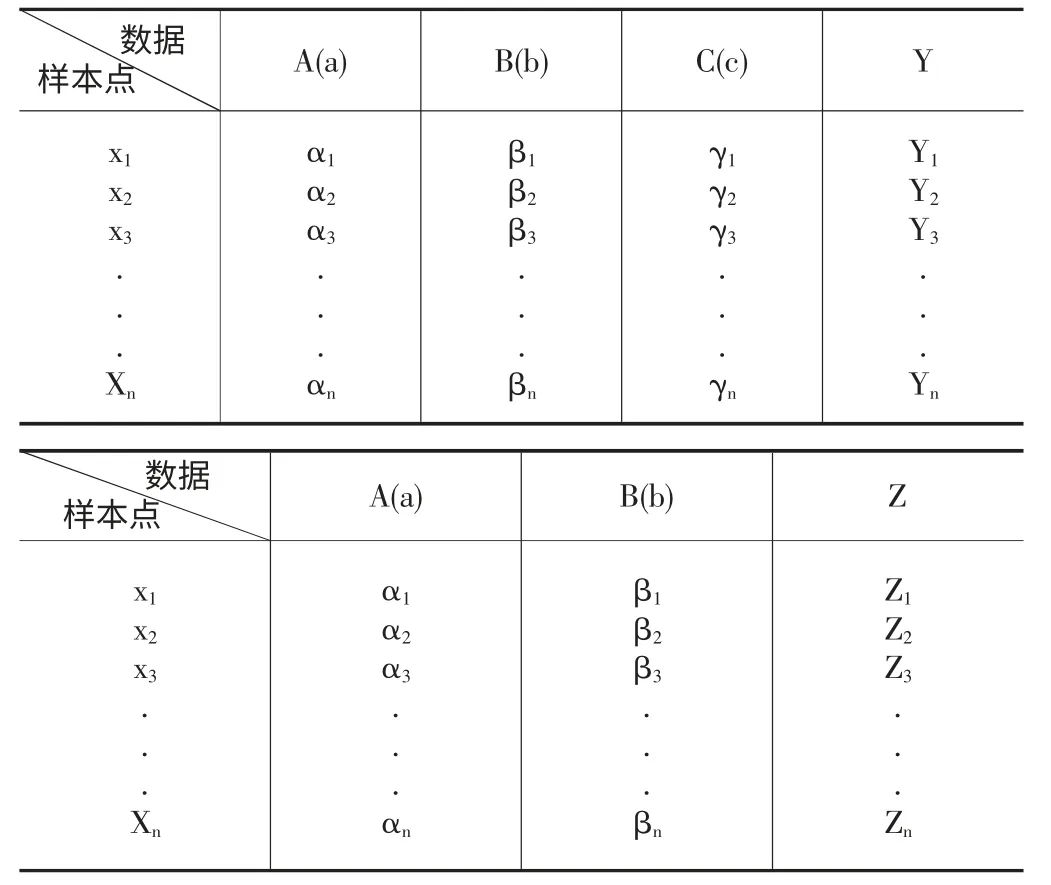
表1
初步得出的结论:在方差D 在允许范围内,AB 组合等价与ABC 组合的不确定,挺高评价的公平性。
该研究方法存在一个问题,对于没有督导(C)评价的样本点没有进行分析。所以对于没有C 评价的样本点不公平。该方案不可行。
研究方法二:主要目标都是抓住具有权威性C 的样本进行排序。先选择含有权威性C 的样本点出来排序,得到序列J;想通过权威性的排序体现评价系统的公平性。将没有权威性C 的样本分出来再进行排序,得出序列K,讲序列J 的总评分插入到序列K 中,调整没有权威C 的样本点的比重,让它接近公平。
不完善的数据和完善的数据样本点都能用上了。利用这些样本点如何通过调整比例得到公平的效果。
解决方案:对含有权威性C 的样本点进行筛选,对这些样本点进行一轮排序,得到序列J。J 的序列是不变的。另外筛选出没有权威性C 的样本点,得到序列K。将序列J 的每项样本点按顺序插入序列K 中,调整K 序列中A,B的比重得到新的序列N,能得到一条公平性较好的评价。
设该模型样本点为x1,x2,x3…,A,B,C 是获取样本点质量评估的数据,A 占a,B 占b,C 占c。a+b+c=1;设αi,βi,γi分别为第i 个样本在A,B,C 上的平均分数;把含有权威性C 的样本点先筛选出来,进行排序,得到序列J,其中Ji=αi*a+βi*b+γi*c;再将没有权威性C 的样本点整合成一个序列K,不需要急于排序。Ki=ai*γ+bi*(1-γ)因为调整A,B会使原序列Ki的序列改变,通过A,B 比重可以找到一条或者多条序列和我们所需的序列N。对于有多条序列我们同样的要用方差来解决问题。
结论:由于缺少序列M 做比较确定序列N 的合理性公平性,至于序列M 是一条公平合理的排序序列(即参考序列)。该研究方法不可行。结论不成立。
经过以上两种研究方法,发现几点问题:
①要实现公平,就要对有权威性和没权威性的样本都用来进行数据测试。
②还要有一条规范的评价标准,方便作为对照模板,与待确认的序列进行比较,达到公平的目的。
③数据的使用,选择数据具有随机性,否者会让人觉得数据不可靠。
④通过调整比例得出的序列不一定只有一条,若我们要找一条比较适合公平的序列还要用到方差来求解,让方差更接近0,波动小,就选择该序列。
⑤一个公平的智能评价系统,是针对于有权威性来仅需排序,对于没有权威性的数据我们要正常使用,使用自定义的比例让评价得到一定的公平,然后对权威数据进行分析、对比。
以上面几点问题为讨论的中心内容,得到第3 种研究方法:
同样的我们还是要以权威数据C 项样本进行质量筛选进行排序,不同的是,用了类似高中的控制变量法来解决问题。控制A,B 的权威样本(即含权威性C)数据不变,通过去掉C 项的评分,在调整A,B 的权威样本评分比重。让他们的排序和之前的排序一致,就可得出较公平的结论。其实比重可以用另外一种方式求解,这样求解不太精确。我们的研究项目就是不确定信息来较好地去评价。
该研究方法能较公平地评价教师的成绩。最终目的是将没有权威性C 的样本用一个比例去计算得到较公平的结果。毕竟权威性对教师较准确,但是具有不确定性,会让教师觉得不公平,为了解决这个问题,我们定义一个样本集Z=xi(i=1,2,3……)。对于一位教师(即xi)评分的获取由A,B,C 构成。A 项是同学对教师的评分,B 项是老师的教师的评分,C 项是督导(即具有权威性)对教师的评分。A,B,C 分别占总体的a%,b%,c%;αi,βi,γi分别是xi中的A,B,C 所对应的平均成绩。对于第i 位教师的成绩有权威性评价的样本Yi=αi*a+βi*b+γi*c;对于没权威性的评价样本先保留到序列的最后,对Yi进行排序得到一个有权威性的序列J,由于序列J 是有权威性的,所以就算怎么改变A,B 的比重也不能改变序列J 的排序。对于有权威性的样本xi,只除去权威性的成绩,保留A,B 原有的成绩,将除去权威性的样本归为一类Q,Q 的A,B 比重重新规划,设A占p,B 占1-p;对于每个除去权威性样本xi 的平均成绩Wi=αi*p+βi*(1-p);将算出来的结果进行排序,得到序列K,通过调整比例让序列K 的排序和序列J 的排序一致。可得到公平的比例去等效于有权威性的样本。
为了能深入地理解:例如有5 个样本x1,x2,x3,x4,x5,其中A 项占50%,B 项占20%,C 项占30%。这是有权威性C 的公平评分比重。x1,x2,x4是有权威性C 评价的样本,而x3和x5则没有权威性评价。要让他们能起到对比的作用。换一种想法,对于督导评价老师的成绩那些样本,去掉督导评价得到的不就是没有权威性的评价那些样本。所以将x1,x2,x4这些有权威性的数据找出来归为一类Q,通过计算每个样品的成绩Y1=α1*0.5+β1*0.2+γ1*0.3;Y2=α2*0.5+β2*0.2+γ2*0.3;Y4=α4*0.5+β4*0.2+γ4*0.3;对Q 类的样本Y1,Y2,Y4进行排序,得到一个从大到小的序列J,假设序列为Y2,Y4,Y1。然后将Q 类的权威性C 评分去掉归为P 类,剩下的就是X1,X2,X4样本的A,B 项的平均成绩,设A 项占比例的p,B项占1-p(0 表2 以下是我们探讨的解决思路: 方式一:就是上面提到的p 算法,即通过调整p 的值改变总成绩Zi的序列,让该排序和有权威性C 的样本排序基本一致,可以算出的p 在允许范围内,p 是在一个区间的,解决p 的具体值,就要用方差来计算两个序列的方差,尽可能地使方差接近于零(运用极限思想解决)。算出的p,这样就可以将没有督导评分的样本用p 和1-p 来计算只有A,B 的评分的样本,得到的数据可以较公平地去评价教师。 方式二:为了更能体现对于样本集中本来就没有督导评价的样本实现公平。这是中期答辩发现的问题。为了解决这个问题,我们可以使用第二层比较的方式去处理。先回顾下前面的重要信息,我们是将含有权威性C 的样本归为Q 类,在Q 类的基础上扩展一开始就没督导评价的样本,即在Q 类中添加不含有权威性的Y3和Y5这两个样本。用假设法,我们先假设p 是个合理公平的比例;P 类是有除去权威性和没有权威性的样本集,可以算出每个样本所对应的总成绩Zi=αi*p+βi*(1-p),进行排序得到新序列K1,K1序列为:Z4,Z5,Z1,Z3,Z2。以K1作为公平标准的评价序列,再将p 回代到Q 类中的没有权威性C 的样本计算他们的总成绩,有权威性C 的样本还是按照原来的比重来计算每个样本的总成绩。对Q 类样本的总成绩进行排序,得到新的序列J1,改变合理比例p 的值,如果p 改变了,序列K1和序列J1的序列都有可能发生变化,最终目的是让序列J1和K1的样本的排序达到一致的效果。那么该p 值就是我们所要找的合理比例。可以用p 来计算那些没有被督导评到的样本,公平性大大地提高了,符合不确定信息进行推理的人工智能评价系统。 笔者觉得方式二更能体现公平,因为这方式能考虑到各种情况的因素,对于有权威性的样本和没有权威性的样本都能有一个模板进行对比。 结论:通过方式二,求得的p 可在没有权威性的样本进行使用并计算得出的结果是具有公平性的,即有权威的样本按原先给的比例计算和没有权威的样本用p 的值计算的公平性评价是等效的。 在该项目中的创新点就是,对于不确定的信息,要解决这类问题,还是要找到一条较明确的评分标准。用排序的思想去解决不确定的信息,让不确定的信息在某种程度上看是确定的,即让人觉得该系统能达到公平。 最重要的创新点是假设法和两重对比,让有权威和没权威的样本都能达到统一的公平的评价标准。假设一个评价标准:对于有权威的样本按给定的评价标准比重作为评价标准,然后让没有权威的样本假设有个评价标准比重p,能让没有权威的样本变得和有权威的样本使用的是同一套正确的评价标准。两重对比体现在第一对于有权威的样本和去掉权威的样本进行第一次对比,得到一个比重p的比例,假设p 是标准评价比例,那么对扩展的Q 类(即包含没有权威的)样本中没有权威的样本代入p 进行计算得到一个新的序列既有权威也有非权威的样本排序J1,P类样本中被除去的权威性的和本来就没有权威性的样本进行排序得到K1,假设K1是用标准评价比重p 来计算的,那么就以K1作为模板进行对比J1的序列是否一致。从而达到两重对比,更具有说服力。 在研究该项目过程中,发现很多的问题,为了解决问题需要小组的讨论,每当讨论出解决思路的时候,会有其他成员的思想不能达成一致,需要进一步的交流。我们每遇到困难,并没有先想放弃,而是想有没有好的解决方案,如果一开始就放弃,可想而知,下次遇到困难就会放弃,有点像破窗原理。 项目的研究成果:通过一系列的讨论和分析得出p 的算法。让不确定信息进行推理的人工智能评价系统能更好地去解决公平性这个智能的问题。通过这次项目,让我们提高自己的分析和解决能力。的确做一个项目要花费挺多的时间和心思在上面,为进入社会打下一定的基础。 [1]李德毅,杜鸧.不确定性人工智能[M].国防工业出版社,2005. [2]温武,钟沃坚.离散数学及应用[M].华南理工大学出版社,2010. [3]同济大学应用数学系.概率统计简明教程[M].高等教育出版社,2003,7:83-85. [4]郭平.基于多层次综合评价系统的教学质量评价系统[C].现代计算机,2006(237):3. [5]江丽丽.基于数据挖掘技术的教学内容双向评价系统的设计与实现[D].江苏:中国矿业大学,2010. [6]邰蕾蕾.青年科技人才绩效评价系统的设计与实现[C].运筹与管理,2013,22(6):12.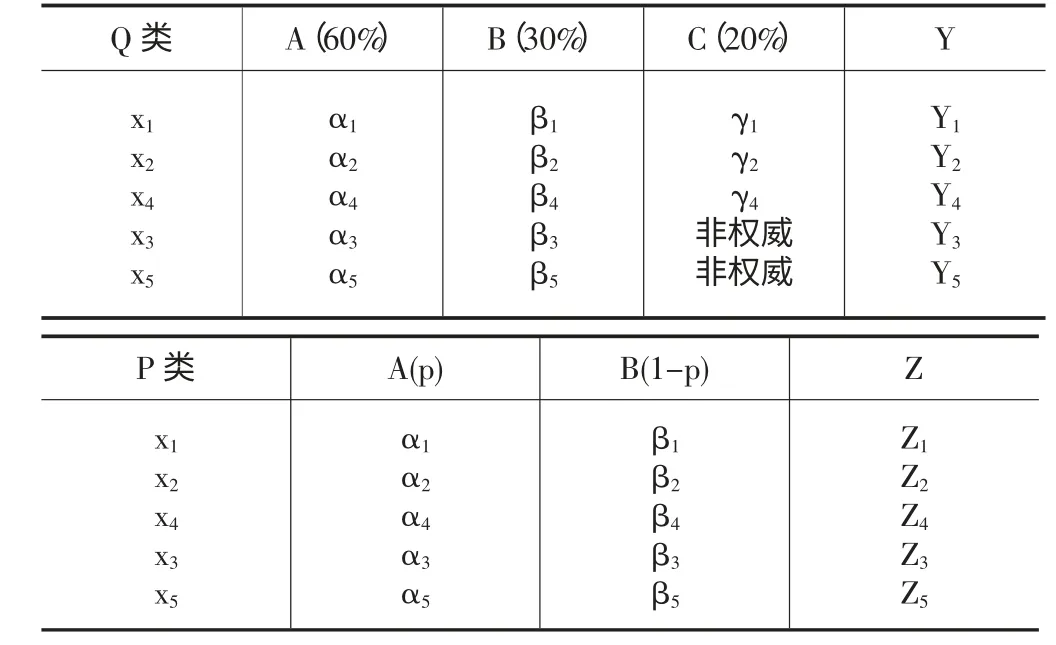
3 得出结论
4 研究成果
