基于支持向量机的物流量预测——以成都市为例
2014-11-17陈彦如
岳 辉,吴 波,单 翠,陈彦如
(1.中国中铁二院工程集团有限责任公司,四川 成都 610031;2.西南交通大学经济管理学院,四川 成都 610031)
0 引言
物流量预测作为物流系统规划的重要环节,其预测精度直接影响到物流系统的分析建模、规划布局等工作的科学性与有效性。因此,选取精度较高的预测方法,对提高物流规划质量和运行效率具有重要的意义。
传统的物流量预测方法,主要采用统计学预测方法、人工智能技术以及组合预测方法。武志惠等[1]采用Logistic模型确定区域物流业与区域经济增长之间的数量关系,利用边际分析和弹性分析计算出三大经济圈物流业的单位增长带来的区域经济的贡献。汤俊等[2]建立了基于最小二乘法的最优化模型(LaOR模型),该模型有效地降低了回归模型的期望风险,但模型的泛化能力差。管春燕等[3]以武汉市区域物流量预测为实例,采用逐步回归法建立模型,将影响程度大的变量依次纳入模型中,提高了模型的运算效率。随后Zhang G等[4]将人工神经网络(ANN)用于预测,但人工神经网络在解决复杂问题时容易陷入局部极小点。张晓磊[5]尝试引用可以处理非线性、高复杂系统的人工神经网络方法建立区域物流预测模型,但建模过程较为复杂。
支持向量机[6-7],简称SVM(Support Vector Ma⁃chine),是建立在统计学习理论上的机器学习方法,已经在实际应用中得到很大的发展。胡燕祝等[8]、Gao M[9]等考虑到SVM具有很强的迭代性能和非线性拟合功能的特点,将其用于物流需求预测。李春锦等[10]基于支持向量机模型预测方法,对我国石油需求预测进行了详细研究。Smola A J等[11]揭示了支持向量机预测方法强大的泛化性能。Car⁃bonneau R等[12]详细研究了自适应性的机器学习过程,并与传统预测方法,如趋势预测、移动平均等方法相比较,验证了支持向量机良好的预测性能。Lu Shan等[15]证明应用于支持向量机在非线性类问题和功能评价方面的适用性。杨雯斌[14]研究了在大规模数据情况下支持向量机的应用,再次证明了支持向量机泛化能力的强大。
综上所述,国内外学者对物流量预测进行了较多的分析研究,给出了具有重要参考价值的成果。不过部分研究方法存在着泛化能力弱、建模复杂、易陷入局部最优等局限。由于支持向量机理论具有强大的泛化能力,本文以成都市为背景,通过对该市的物流量预测实证分析,检验该方法的有效性。
1 支持向量机理论概述
在统计学理论中,学习机的风险有两类:经验风险和期望风险。经验风险一般指在模型建模时,对已有样本数据的拟合精度,而期望风险指模型的实际拟合精度。当样本容量很大且样本数据值无异常时,经验风险和期望值风险的差异较小,但当样本为小样本或者数据包含异常数据时,难以保证传统学习的泛化能力。而支持向量机基于结构化风险最小化的思想却很好地解决此类问题。支持向量机的模型如下:
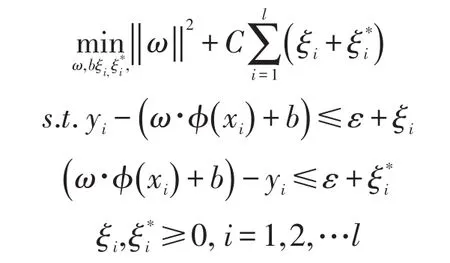
式中:目标函数用来控制泛化能力;约束条件用来减少经验风险;C为惩罚函数,用来控制样本误差和机器泛化能力之间的平衡。
为了避免维数灾难,支持向量机将原来空间维度非线性问题转化为高维度线性问题,而高维度空间涉及到原样本的之间内积运算,这种内积只要找到满足Mercer条件下的核函数K(xi,xj),就会对应空间某个内积,如图1所示。
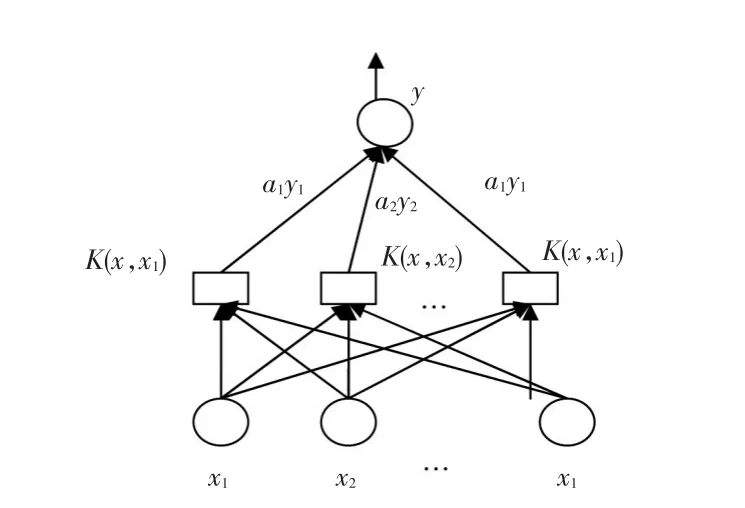
图1 核函数
2 基于支持向量机的物流量预测模型建立
根据支持向量回归机原理及物流量相关理论,本文建立了基于支持向量机的物流量预测模型,具体步骤如下。
2.1 确定物流量影响指标
首先需确定影响物流量的主要指标。为了保证物流量预测的准确性和科学性,通过相关性分析,本文选取的物流量影响指标有:第一产业产值(亿元)、第二产业产值(亿元)、第三产业产值(亿元)、社会消费品零售总额(亿元)、进出口贸易总额(亿美元)、城镇居民可支配收入(百元)、农村居民可支配收入(百元)以及货运量(千万吨)。
2.2 数据预处理
由于原始数据量纲不同,为了避免数据处理过程中由于数量级不同而影响预测结果,需要对原始数据进行统一的量纲处理。
2.3 构建模型
将已知样本分为训练样本与测试样本,对不同的训练样本进行反复训练,根据训练结果选择最佳的模型参数,然后构造支持向量机模型并求解最优化问题。
3 成都市物流量预测实证分析
本文采用的支持向量机软件为Libsvm—2.88。下面将以成都市为例,进行物流量预测。由于目前没有直接的物流作业量统计指标,如仓储量、配送量、流通加工量等统计值,并考虑到运输是物流中最重要的环节,且在一定程度上运输需求能反映物流需求,因此,本文选取货运量作为物流量指标进行预测。
3.1 数据指标收集
以成都市货运量为被解释变量,指标统计数据如表1所示(数据来源于成都市1996—2010年统计年鉴)。

表1 成都市物流需求预测指标原始数据表

表1 (续)
3.2 数据预处理
按照Libsvm—2.88软件输入格式的规范,将原始数据转化为表2所示的数据格式,同时建立训练数据样本和测试数据样本。

表2 规范数据格式
3.3 支持向量机参数选择
本文选择ε-SVM回归模型,核函数选择RBF。利用gridregression.py包对模型参数进行优化,获得的最佳参数分别为:C=64.0,g=0.125,p=0.5。
3.4 求解结果及数据分析
3.4.1 支持向量机回归模型求解
在DOS窗口中,输入svm-train-s 3-t 2-c 64.0-g 0.125-p 0.5 data.txt,从而获得data.txt.mod⁃el,利用训练的模型和测试的数据可以获得相应的输出值在out.txt中。
3.4.2 数据分析
由out.txt可以输出通过支持向量机预测得到的2008—2010年的货运量结果,表3~表5给出了不同试验组得到的结果及与2008—2010年实际货运量的对比。为了反映训练数据样本多寡对支持向量机预测结果的影响,分别选取2003—2007年、2002—2007年、…、1996—2007年作为训练样本中的第1组、第2组、…、第8组数据。
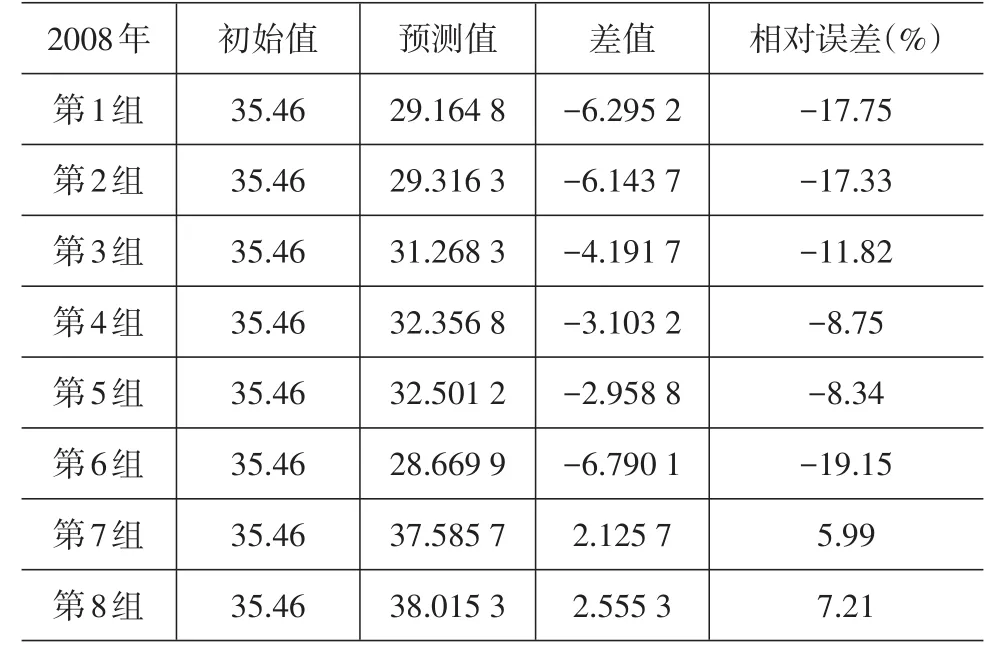
表3 向量机预测值和2008年实际值对比

表4 向量机预测值和2009年实际值对比
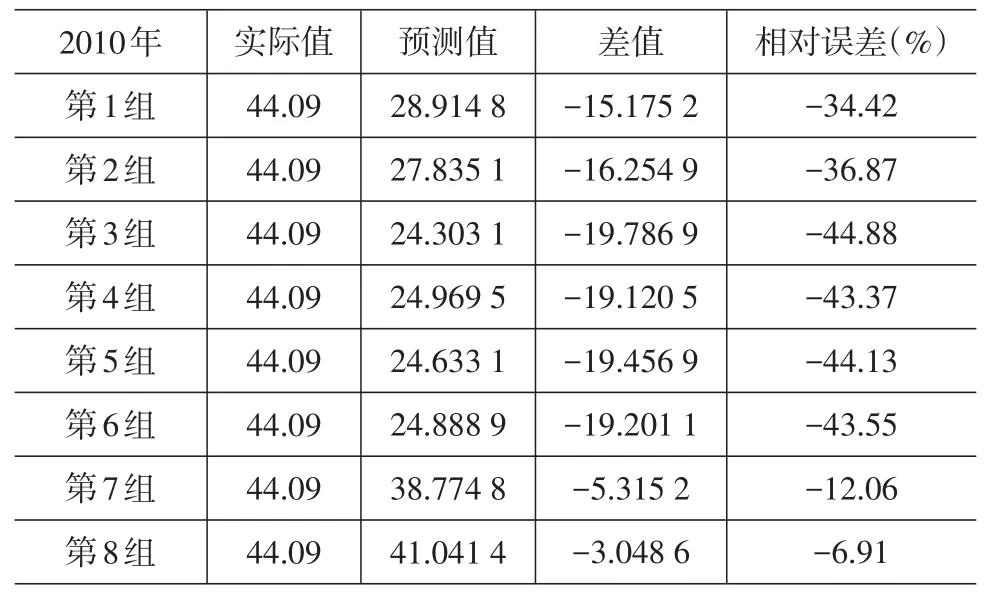
表5 向量机预测值和2010年实际值对比
从表3、表4、表5中可以看出,第1组的预测数据相对误差达到了近20%,但随着训练样本量的增加,整体的相对误差呈减少趋势,2008年、2009年分别在第7组及2010年在第8组的相对误差达到最小值:5.99%、3.82%、-6.91%,误差回落的速度较快。
为了验证支持向量机的预测效果,本文运用多元线性回归,采用同样的分组对2008—2010年之间货运量预测并与实际值进行对比,结果如表6~表8所示。
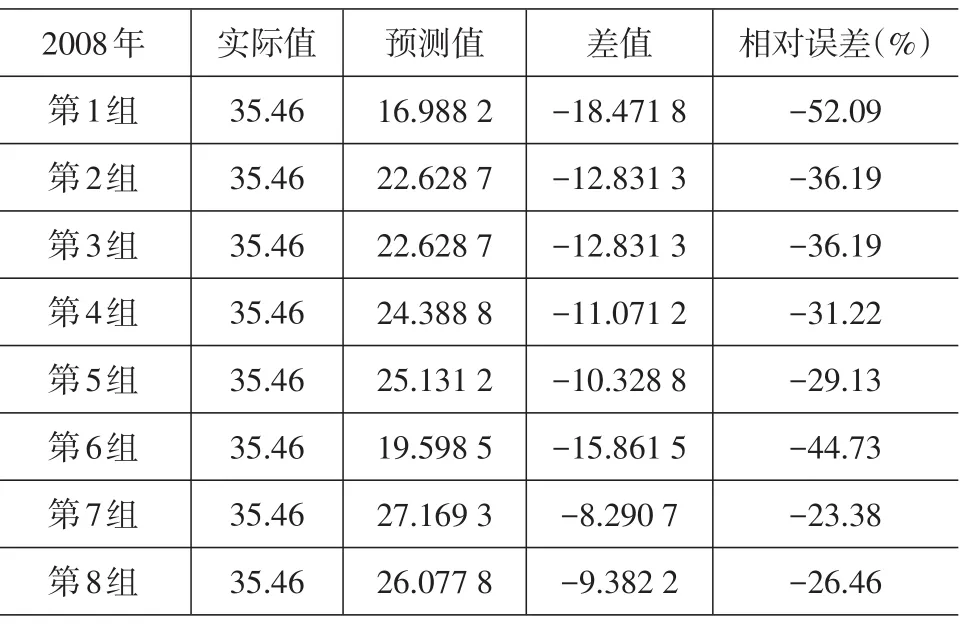
表6 回归预测值和2008年实际值对比
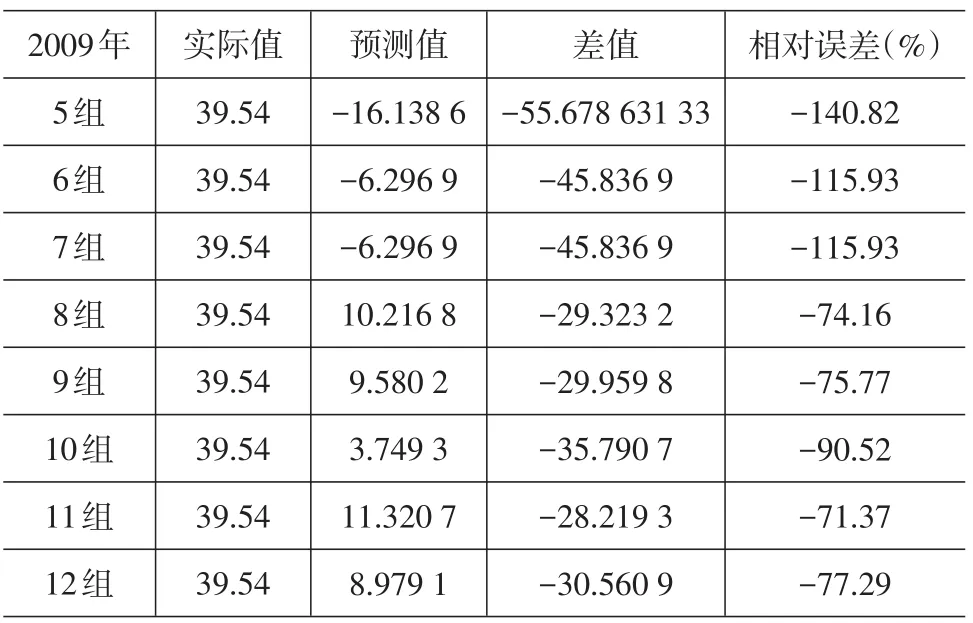
表7 回归预测值和2009年实际值对比
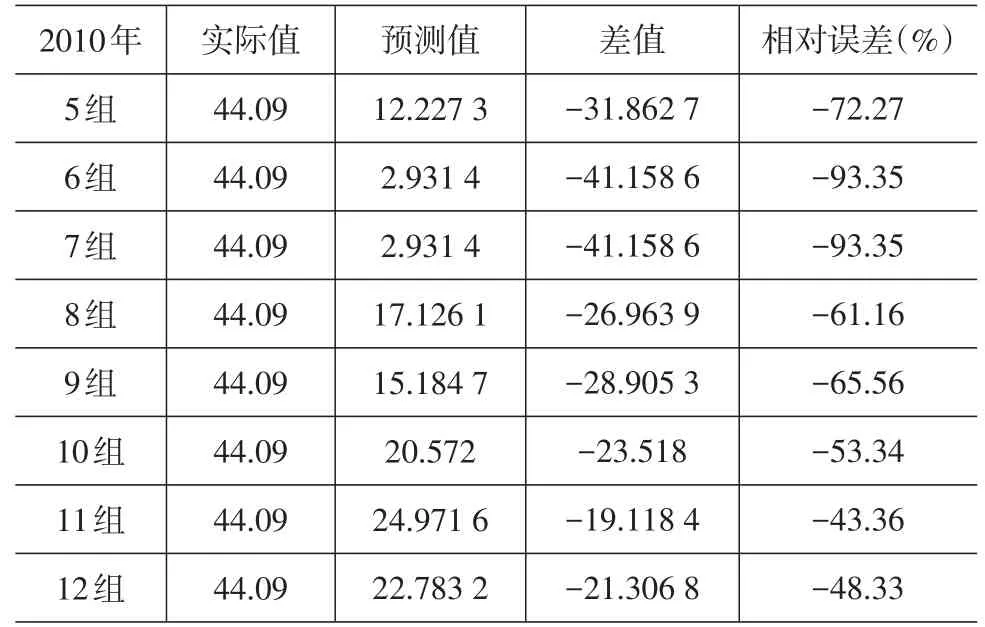
表8 回归预测值和2010年实际值对比
从表6~表8可以发现,通过多元线性回归得到预测值的相对误差总体偏大,虽然随着数据量的增加有明显的回落趋势,但最小的相对误差达-23.38%,最大竟达到-140.82%,与支持向量机的预测效果差距比较明显。
4 结语
本文考虑到支持向量机的预测优势,将其用于成都市物流量预测中。结果表明,随着训练样本数据的增加,预测值与实际值的相对误差呈减少趋势,误差回落的速度较快,最小误差为3.82%。此外选取多元线性回归模型对相同的样本进行预测,结果表明该模型预测值与实际值相对误差总体偏大,虽然随着数据量的增加有明显的回落趋势,但最小的相对误差达到-23.38%,最大达到-140.82%,与支持向量机的预测效果差距明显,证明了支持向量机用于物流量预测的有效性。
[1]武志惠,虞巧颖,申金升.三大经济圈的物流业对区域经济增长的实证分析[J].北京交通大学学报:社会科学版,2008,7(1):43-47.
[2]汤俊,肖建华.区域物流需求预测的LaOR方法[J].商业研究,2007,365(9):32-35.
[3]管春燕,苏建美.基于逐步回归分析的武汉区域物流量预测[J].企业导报,2012(16):133-135.
[4]Zhang G,Eddy Patuwo B,Y Hu M.Forecasting with artifi⁃cial neural networks:The state of the art[J].International journal of forecasting,1998,14(1):35-62.
[5]张晓磊.ANN分析在广西区域物流需求预测中的应用[J].物流工程与管理,2011,33(3):58-60.
[6]Cristianini N,Shawe-Taylor J.支持向量机导论[M].北京:电子工业出版社,2004.
[7]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-41.
[8]胡燕祝,吕宏义.基于支持向量回归机的物流需求预测模型研究[J].物流技术,2008,27(5):66-68.
[9]Gao M,Feng Q.Modeling and Forecasting of Urban Logis⁃tics Demand Based on Support Vector Machine[C]//Knowl⁃edge Discovery and Data Mining,2009.WKDD 2009.Sec⁃ond International Workshop on.IEEE,2009:793-796.
[10]李春锦,闫云聚.基于支持向量机的中国石油需求量预测研究[J].西安石油大学学报:自然科学版,2013,28(2):103-106.
[11]Smola A J,Schölkopf B.A tutorial on support vector re⁃gression[J].Statistics and computing,2004,14(3):199-222.
[12]Carbonneau R,Laframboise K,Vahidov R.Application of machine learning techniques for supply chain demand forecasting[J].European Journal of Operational Research,2008,184(3):1140-1154.
[13]Lu S,Han H,Dong J.Adaptability of SVR Time Series Analysis Used in Forecasting of Logistics Demand[C].In⁃ternational Conference on Transportation Engineering,2007:1298-1303.
[14]杨雯斌.支持向量机在大规模数据中的应用研究[D].上海:华东理工大学,2013.
