基于PLS /ANN-RP-HPLC的甲基苯甲醛同分异构体的同时测定
2014-10-26李彦威张照昱
张 汇,李彦威,张照昱
(太原理工大学 化学化工学院,太原 030024)
化学计量学是化学的一门分支学科,它运用数学、统计学及计算科学,设计和选择最佳实验方法,并通过解析化学测量数据,获得最大限度的化学信息[1]。近年来,化学计量学中的许多方法已被广泛应用于色谱分析中,如偏最小二乘法(Partial Least Squares,PLS)、人工神经网络(Artificial Neural Network,ANN)、信号处理、因子分析等,成功地解决了色谱峰型重叠、基线漂移等问题,并将其应用于药物识别、食品原料分类等领域[2-4]。本文将PLS和ANN分别与反相高效液相色谱法(RP-HPLC)相结合,建立了同时测定邻、间、对甲基苯甲醛同分异构体的预测模型,研究了同时测定三组分的适宜条件和适用范围,并将所建立的模型用于合成样品的分析,获得了良好的实验结果,为有机化合物同分异构体的测定提供了一种新的途径。
1 算法原理
1.1 偏最小二乘法[1]
PLS是一种基于因子分析的多变量校正方法,它同时对测量数据矩阵和浓度矩阵进行主成分分解,将所得主成分数代入偏最小二乘法,并通过迭代的方法,交换迭代变量,将两个独立的主成分分析过程联系起来,对测量矩阵进行校正,利用校正后的测量矩阵预测未知样品的含量。
PLS建立校正模型最困难的问题之一就是如何确立建模所使用的主成分数目。确定主成分数的方法,目前最常用的是交互验证的预测残差平方和S(prediction residual error sum of squares,PRESS)。其基本原理是将一组已知的标准混合溶液的响应矩阵A中的数据分成n个子集,把这n个子集中的一个作预测集,其余(n-1)个作校正集。这样将n个子集轮流作一次预测集样品,经n次校正-预测过程,就可用S来估计预测的误差。S按下式计算:

其中,ρij是第j个组分在i个样本子集中的真实质量浓度是预测的质量浓度值,m是主成分数,n为样品数。分别取主成分数m为1,2,…来构造校正模型,并计算各个m值时的S值。因此,根据S值的大小,可确定主成分数m的值。
1.2 人工神经网络[1,5]
ANN是一种模拟人脑功能的新型信息处理系统,具有一定的自适应、自组织、自学习及自动建模功能,对于处理非线性体系有其独到之处。目前比较成熟的三层BP神经网络模型,由输入层、输出层和隐含层组成,同层各节点互不连接,相邻层的节点通过权连接。输入层各点的输入信号经权重耦合到隐含层的各点,由传递函数f(x)转换后再耦合到输出层的各点。将输出信号与学习样本的目标数值进行比较,两者之间的误差利用“反传算法”沿原通道返回,通过修改各层节点的连接权重,使误差达到最小。其结构如图1所示。

图1 BP神经网络示意图
ANN可用于高维数据的拟合,即在样本点构成的高维空间,生成一个逼近其变化趋势(规律)的超曲面。如果它既能很好地拟合已知样本,又能很好地预测未知样本,即称所建的模型逼近了规律,是可靠的;若仅精确地逼近已知样本,但预测未知样本的能力变差,则产生了过拟合,模型不可靠。将已知样本分成训练集和预测集两部分,将训练集预测误差反传调节ANN权值,结合预测集预测误差和训练集误差,检测过拟合及优化模型。为此作出如下定义。
1)逼近误差:
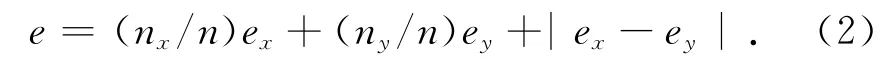
式中:e为逼近误差;ex为训练集预测平均相对误差;ey为预测集预测平均相对误差;nx为训练集样本数;ny为预测集样本数;n为已知样本数。
2)逼近度:

式中:D为逼近度;c为常数。通过调节c的大小,进而调节D的大小以便于作图。逼近度表示模型与规律的逼近程度,e越小,D越大,模拟越具有更好的预测能力。
2 材料与方法
2.1 仪器与试剂
日本岛津公司LC-10A型高效液相色谱仪;TU-1901型紫外可见分光光度计(北京普析通用有限公司)。实验所用甲醇为色谱纯(天津四友),邻甲基苯甲醛(o-tolualdehyde,质量分数98%)、间甲基苯甲醛(m-tolualdehyde,质量分数97%)和对甲基苯甲醛(t-tolualdehyde,质量分数98%)(A Johnson Matthey Company)均为分析纯;实验用水为二次蒸馏水,色谱用水为超纯水。所有试剂均经0.22μm的滤膜过滤并超声脱气后使用。
2.2 色谱条件
Shim-pack VP-ODS 色谱柱(150mm×4.6 mm,(4.6±0.3)μm)(日本岛津);流动相配比为V(甲醇)∶V(水)=40∶60;流速0.80mL/min;柱温40℃;检测波长250nm;进样量20μL。
2.3 供试液的配制
分别准确称取邻、间、对甲基苯甲醛0.0025g于25mL棕色容量瓶中,用纯甲醇定溶至刻度,即配制成100.00μg/mL邻、间、对甲基苯甲醛储备液。准确移取上述适量的邻、间、对甲基苯甲醛储备液于10mL棕色容量瓶中,用纯甲醇定容,配制成各自的单组分溶液或一系列三组分混合溶液,待测。
2.4 实验方法
在指定色谱条件下对供试液进行测定,将得到的单组分及混合组分的色谱数据输入用MATLAB7.0软件编写的PLS和ANN程序处理,分别计算混合溶液中各组分的含量。
3 结果与讨论
3.1 三种同分异构体混合测定的色谱图
配制o-T,m-T,p-T质量浓度比为1∶1∶1的混合标准溶液,在2.2所述的色谱条件下进行测定,结果如图2所示。
由图可知,此色谱条件下甲基苯甲醛三种同分异构体的色谱峰是难以完全分离的,且均有较大程度的重叠,不能采用常规色谱法进行定量分析。
3.2 邻、间、对甲基苯甲醛单组分的线性关系
按照实验方法,配制一系列浓度不同的邻、间、对甲基苯甲醛标准溶液,分别在指定色谱条件下进行测定,并进行线性回归。结果表明,三者质量浓度在1.0~20.0μg/mL范围内均呈现良好的线性关系,其回归方程分别为

图2 三种异构体混合物色谱图

因此,本实验中校正集的质量浓度选在该范围内。
3.3 预测模型的建立
3.3.1 校正集的建立
在初步试验的基础上,采用正交试验方法,选择三个L16(45)正交表作为校正集,质量浓度范围分为三个区间:3.00~6.00μg/mL,7.00~13.00μg/mL,14.00~20.00μg/mL,在指定色谱条件下进行分析测定。
3.3.2 PLS模型的建立
在PLS法中,主成分数的确定对预测结果的准确性起着至关重要的作用。本实验采用交互验证法建立模型,为了避免“过拟合”引入更多的噪声,通过F检验来确定当S达到最小时的主成分,即最佳主成分数[6]。如图3所示,当选择F检验的置信度为0.75时,得到邻、间、对甲基苯甲醛的最佳主成分数均为5。

图3 S随主成分数变化曲线
3.3.3 ANN模型的建立
根据已经建立的校正集可以确定,ANN模型的输入层节点数为16、输出层节点数为3,学习速率和动量常数等其它参数都采用软件Matlab7.0神经网络工具箱的默认值。下面主要讨论模型建立过程中最重要的三个参数如神经元、训练次数和目标误差的选择。
1)神经元的选择。
在试样数量和输入节点数确定的情况下,神经元个数的选择是建模的主要问题。若神经元过少,则网络中的权重不充分。此时的网络不能够较好地描述试样集的固有规律,即不能够得到好的预测数学模型。相反,若神经元过多,则会发生过拟合。过拟合时,对于预测集(未参加数学模型的构造)来说,则误差可能较大,这就是通常所说的数学模型的不稳定。本实验通过改变神经元个数,分别计算训练集(即校正集)和预测集的预测相对误差以及逼近度,取逼近度最大的点作为模型的神经元个数,如图4所示,本实验中模型的神经元个数选为14。
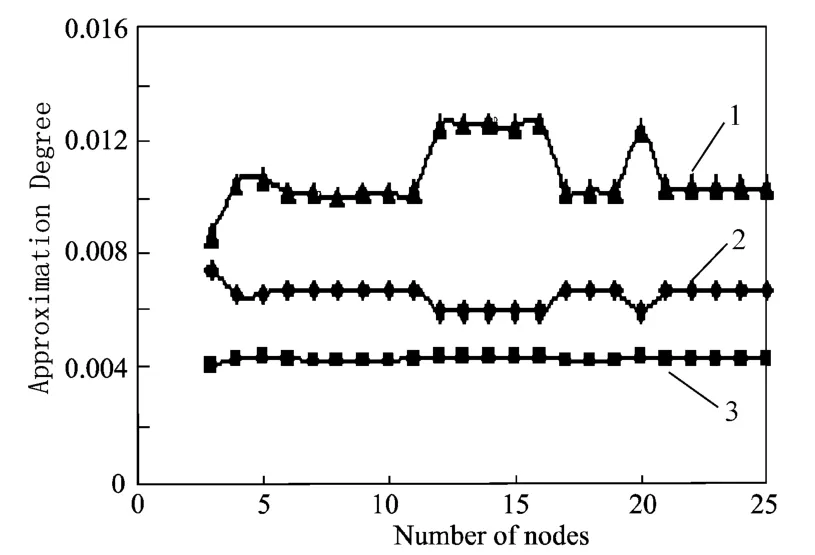
图4 逼近度随神经元数的变化曲线
2)训练次数的选择。
在建模过程中,训练次数的选择也是一个重要问题。训练次数过少,训练不彻底,误差无法趋近于目标误差;训练次数过大,将导致“过训练”,即所建立的模型去契合个别试样,这样的模型对于训练集(即校正集)来说误差较小,但对于“未知”试样(预测集)来说误差可能就很大。如图5所示,本文选择训练次数为450次。
3)目标误差的选择。
目标误差不但影响ANN模型的预测精度,而且对模型的泛化能力有严重的影响。本实验通过计算不同目标误差所对应模型的逼近度,从而优化模型的预测性能。以逼近度、训练集预测平均相对误差和预测集预测平均相对误差分别对目标误差作图,结果如图6所示。由图可知,目标误差为0.6时,逼近度最大,故选择模型的目标误差为0.6。

图5 逼近度随训练次数的变化曲线
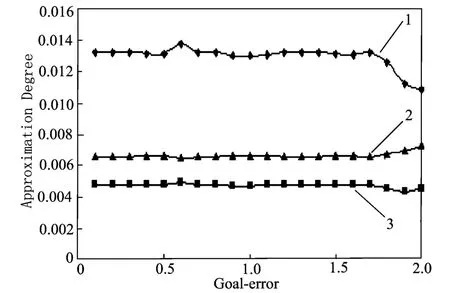
图6 逼近度随目标误差的变化曲线
3.3.4 模型预测性能的检验
为了检验所建立模型的预测能力,按照实验方法分别对所配制的八组模拟样品作测定。将测得的色谱数据分别输入建立的两个模型进行计算,以预测集各样品中三种甲基苯甲醛质量浓度的预测值对实际值作图并进行线性回归,方程式见表1。

表1 预测模型回归方程
由表1可看出,所建立的两种模型对甲基苯甲醛三种同分异构体的质量浓度均具有良好的同时预测性能,其模型的有关指标见表2。

表2 预测模型的有关指标
3.4 精密度试验
配制邻、间、对甲基苯甲醛质量浓度分别为18.00,20.00,19.00μg/mL的标准混合溶液,按照实验方法平行测定8次。结果显示PLS和ANN的相对标准偏差分别保持在0.84%~1.20%和0.11%~0.70%之间,表明这两种模型均具有良好的精密度。
3.5 加标回收率实验
分别取质量浓度为4.50,3.50,5.50μg/mL的邻、间、对甲基苯甲醛配制成样品溶液,同时加入不同含量的三种同分异构体化合物的标准溶液,采用两种模型进行加标回收率的测定,结果见表3。
由表3可知,本实验所建立的两种同时测定甲基苯甲醛三种同分异构体的预测模型回收率均在97.54%~116.77%之间,而相对偏差在±(1.69~15.4)%之间,表明该方法具有良好的准确度。

表3 加标回收率实验结果
4 结论
高效液相色谱法与化学计量学方法结合,可有效解析色谱重叠峰,解决有机化合物同分异构体同时测定的问题。本实验将其应用于邻、间、对甲基苯甲醛的同时测定,通过选择偏最小二乘法和人工神经网络法的建模参数,分别建立了两种较为完善的预测模型,获得了令人满意的结果。通过对两种模型的精密度和加标回收率实验的结果进行比较,发现人工神经网络法在处理多组分同时测定的问题方面更显示出优越性。
[1]许禄.化学计量学——一些重要方法的原理及应用[M].北京:科学出版社,2004:2-100.
[2]SârbuC,Nascu-Briciu R D,Kot-Wasik A,et al.Chromatographic lipophilicity determination using large volume injections of the solvents non-miscible with the mobile phase[J].Food Chemistry,2012,130:994-1002.
[3]Weldegergis B T,de Villiers A,Crouch A M.Chemometric investigation of the Volatile content of young South African wines[J].Food Chemistry,2011,128:1100-1109.
[4]Dumarey M,Put R,Van Gyseghem E,et al.Dissimilar or orthogonal reversed-phase chromatographic systems:A comparison of selection techniques[J].Anal Chim Acta,2008,609:223-234.
[5]刘平,梁逸曾,张林,等.人工神经网络用于化学数据解析的研究(Ⅰ)—逼近规律与过拟合[J].高等学校化学学报,1996,17(6):861-865.
[6]李彦威,方慧文,梁素霞,等.偏最小二乘紫外分光光度法同时测定丁烯二酸的顺反异构体[J].分析化学,2008,36(1):95-98.
