基于神经网络的汉字质量量化评价模型
2014-10-15耿晓艳许维胜吴继伟
耿晓艳,许维胜,吴继伟
(同济大学电子与信息工程学院,上海 201804)
0 引言
传统的汉字字库制作采用人工手写的方法[1-2],即由造字专家按照统一的风格及笔形规范逐字书写,然后将字稿扫描到电脑,形成点阵字库,再进行数字化拟合,将点阵图形抽象成数字信息,最后进行人工修字,并按照需求,整合为不同格式的字库。这种方法工作量大,耗时久,成本高,且易受到人为因素的影响,因而现有的汉字字库制作技术已不能适应信息产业日益发展的需求。
近年来,一些关于个性字库的研究,如陈禹伶[3]将手写体样本字与标准字进行识别,然后对标准字进行图像变换,生成具有手写字特征的“我”体字库,但没有考虑字体的品质评价问题,故生成的字库与期望有较大的差距。ZHOU Bao-yao等[4]针对个性化手写体汉字提出样本字复用的方法,首先在标准印刷体汉字图像的基础上建立汉字部首组合模型,即采用水平、垂直和封闭式分类器对标准汉字进行分割,并根据视觉相似性对部首分类,然后采用该模型将输入的手写体样本字分割并生成其他汉字。潘志庚等[5]提出了一种使用Fourier级数描述汉字轮廓,通过对不同字形的风格进行复合,生成具有多种风格的字形的方法,但也未涉及字体的品质评价问题。
针对传统字库制作中需要人工干预构字结果这一弊端,本文依据造字专家对于汉字质量的评判方法,抽象汉字的相关美学属性特征,并依此建立神经网络模型。通过学习造字专家对个例汉字的评判结果,获取汉字品质的量化评判标准,从而实现对所有构字结果进行计算机自动美学评价,提升字库中汉字的质量。
1 提取属性
1.1 汉字书写规则
造字专家采用人工手写的方法造字,必然有一系列的关于字体品质的评价准则,按照这样的准则生成的汉字被认为是符合专业审美要求的。标准整字满足的基本书法规则有:
(1)满收虚放,即字体外围较满的汉字要内收,较虚的汉字要外放。另外,内白大的汉字应适当缩小,这样才能使字体的视觉大小一致。如图1所示,第一组的“口”、“田”、“围”3个字实际大小相同,但看起来“口”字较大,“围”字最小;第二组将“口”字和“田”字做了适当的缩小,看起来就更加协调了。
(2)黑白均匀,即汉字整体的黑白比例协调。
(3)重心稳定,上紧下松,左右平衡。因人有视错觉,即视觉中心比绝对中心要高一点,故为使字体的中心在视觉中心上,就要上部紧凑下部宽松,这样才符合视觉审美[6-7]。

图1 字体内白对视觉效果的影响
1.2 定义影响汉字质量的属性
用计算机对构字结果进行评价,需要将上述标准和要求量化,具体可以通过汉字的相关属性来表征。本文利用Matlab环境,采用图像处理的方法,提取可能影响字体质量的属性特征,并经实验测试,确定了以下对汉字品质有重要影响的属性[8-11]。
(1)外接矩形的宽(Width)和高(Height),反映汉字最基本的大小和比例。
(2)水平重心(W_X)和竖直重心(W_Y)。设c(i,j)表示汉字点阵,则重心的计算方法如下:
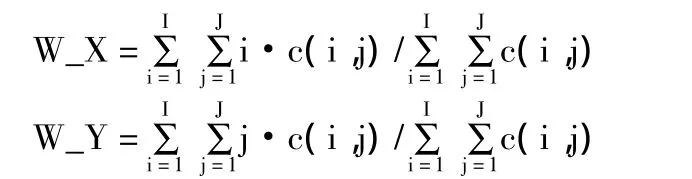
其中,I表示外接矩形的宽,J表示外接矩形的高。
(3)中心,即外接矩形的中心,包括水平中心(G_X)和竖直中心(G_Y)。
(4)黑像素占外接矩形的比例(WAR),计算公式如下:

(5)复杂度,定义为黑白像素的变化次数,包括水平复杂度(CompX)和竖直复杂度(CompY)。
(6)满虚度,设汉字点阵c(i,j)到外接矩形上、下、左、右 4 个方向的距离分别为 dT(i,j)、dB(i,j)、dL(i,j)和 dR(i,j),则整字的满虚度定义为:
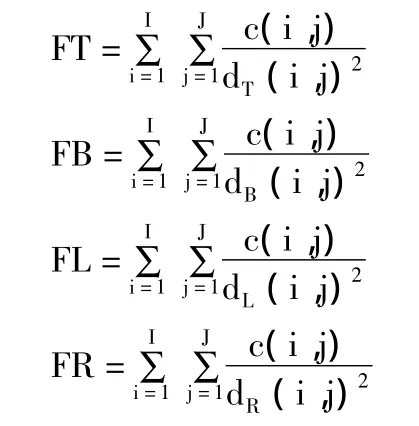
(7)为了更细致地表示汉字的黑白,将外接矩形等分为左上、右上、左下和右下4部分,分别计算每一部分的黑像素比例(WARLT、WARRT、WARLB和WARRB)。
(8)为充分反映汉字边界的满虚程度,计算外接矩形上、下、左、右各四分之一部分的黑像素比例(WARL、WARR、WART、WARB)。
(9)形态结构特征,取外接矩形的上三分之二部分、从上到下的中间三分之二部分和下三分之一部分,分别求出各自的左、右满虚度(ShapeT_L、ShapeT_R、ShapeTBM_L、ShapeTBM_R、ShapeB_L、ShapeB_R);同理,取外接矩形的左三分之二部分、从左到右的中间三分之二部分和右三分之一部分,分别求出各自的上、下满虚度(ShapeL_T、ShapeL_B、ShapeLRM_T、ShapeLRM_B、ShapeR_T、ShapeR_B)。
2 构建评价模型
2.1 确定评价模型的输入与输出
根据上文提出的书法规则,大小一致可以通过外接矩形的宽和高来衡量,满收虚放和内白大小决定了汉字的大小,反映到抽象的量,即复杂度、满虚度和形态结构特征决定了外接矩形的宽和高。整字的黑像素所占比例WAR可以体现汉字的黑白均匀,影响整字WAR的量有:外接矩形的宽和高、复杂度、黑像素总数、形态结构特征以及满虚度。为更精确地反映汉字的黑白均匀,将4等分外接矩形得到的WARLT、WARRT、WARLB和WARRB值作为表现黑白特点的量度,与整字的WAR类似,影响这4部分黑像素比例的因素有:外接矩形的宽和高、复杂度、整字的WAR、形态结构特征以及满虚度。重心稳定,上紧下松,左右平衡,可以用汉字的重心和中心来表征,经测试汉字的形态结构特征和满虚度可以较好地确定重心和中心。
基于以上分析,本文利用改进的三层BP神经网络分别构建4个评价模型:SelEvaluWHNet、SelEvalu-WARNet、SelEvaluQuaWARNet、SelEvaluPosNet,其各自的输入、输出如图2~图4所示。
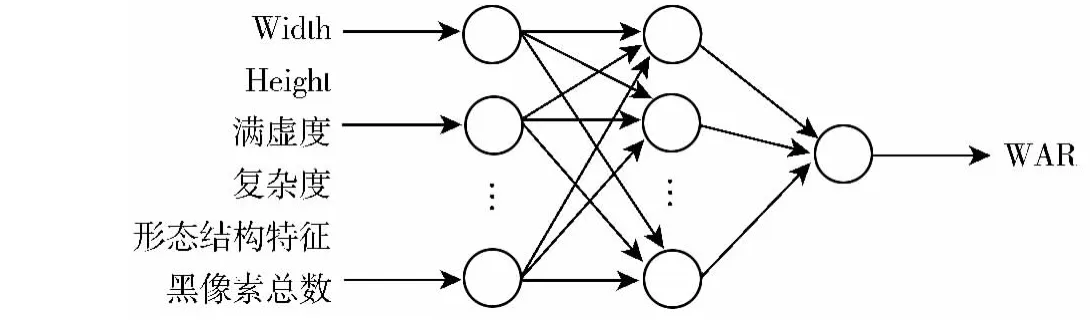
图3 SelEvaluWARNet评价黑白是否均匀
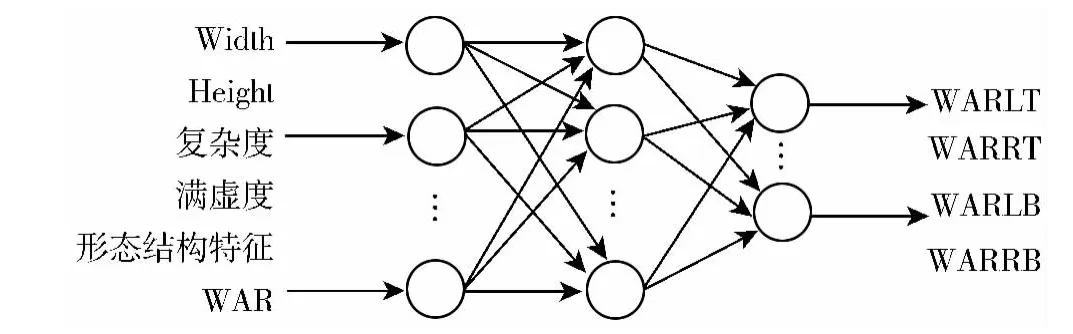
图4 SelEvaluQuaWARNet评价黑白是否均匀
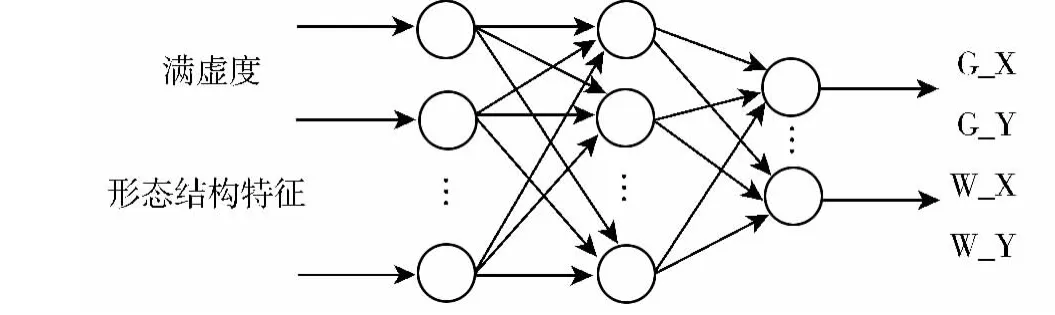
图5 SelEvaluPosNet评价重心是否稳定
2.2 建立评价模型的BP网络
评价模型的搭建过程中使用到Matlab的神经网络工具箱,该工具箱提供了许多有关神经网络设计、训练和仿真的函数,用户可根据需要调用相关函数[12]。下面介绍本文构造评价模型的BP网络所用的工具箱函数及具体的参数选择。
(1)利用 newff函数生成 BP网络进行初始化[13],其语法结构为:

其中,P、T分别表示输入、输出向量;Si表示第i层网络的神经元数目,N表示网络的总层数,设输入、输出神经元个数分别为 m、n,由于本文采用三层BP网络,则根据经验值取第一、第二隐层的神经元个数为:
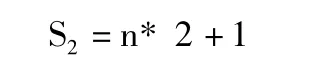
PF是性能函数,常用默认的均方误差mse;TFi表示第i层网络的传递函数;BTF表示训练函数;BLF表示学习函数。TF、BTF和BLF的选取分别如下:

这里,传递函数logsig为S型的对数函数,可将输入映射到区间(0,1)中;tansig为双曲正切S形传递函数,其返回值位于区间(-1,1)中;satlins为对称饱和线性传递函数。学习函数选取默认的梯度下降动量学习函数learngdm。
为克服标准BP算法存在的收敛速度慢、易形成局部极小等缺陷,本文使用改进的BP网络,即训练函数采用动量及自适应lrBP的梯度训练递减函数traingdx。增加动量项,即从前一次权值调整量中取出一部分叠加到本次权值调整量中,有助于使网络从误差局部极小中跳出;自适应改变学习率,可减小振荡趋势,提高网络的训练速度[13-14]。
(2)设置网络的训练参数。
收敛次数 net.trainParam.epochs=200000。
显示间隔 net.trainParam.show=100。
收敛误差 net.trainParam.goal=igoal,igoal根据表1对4个评价网络分别进行设置。

表1 评价网络的收敛误差
3 测试结果及分析
本文所提出的评价模型首先针对结构较为简单的上下、左右结构的汉字进行研究。影响评价结果的因素,除了评价模型本身,还与样本字的选择有很大关系,目前采用随机选取的方式获得样本字,以839个标准字作为样本进行训练,并用另外随机选取的271个标准字测试,根据测试结果分别统计各个属性的标准误差(标准误差定义为各测量值误差平方的平均值开平方),结果如表2所示。
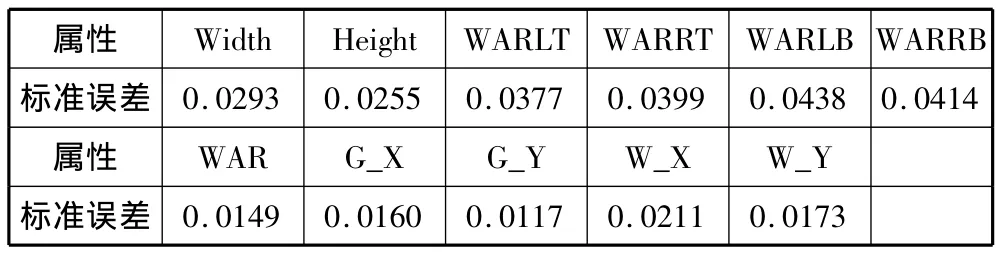
表2 测试结果中各属性的标准误差
由表2可以得出,各属性的标准误差都在4.5%以内,证明该评价方法具有可行性。然后,随机构字300个对各属性进行评价,经统计,外界矩形的宽Width误差大于5%的结果有9个,由于篇幅所限,现展示部分如图6所示,其中左图是待评价汉字,右图是对比样本字,余图同理。

图6 Width误差大于5%的待评价汉字与样本字的对比
外界矩形的高Height误差大于5%的结果有5个,展示部分如图7所示。

图7 Height误差大于5%的待评价汉字与样本字的对比
左上黑像素比例WARLT误差大于5%的结果有2个,如图8所示。

图8 WARLT误差大于5%的待评价汉字与样本字的对比
右上黑像素比例WARRT误差大于5%的结果有3个,包括图8中的“鬠”,另外2个结果如图9所示。

图9 WARRT误差大于5%的待评价汉字与样本字的对比
右下黑像素比例WARRB误差大于5%的结果有4个,包括图9中的“舮”和“驷”,另外2个结果如图10所示。

图10 WARRB误差大于5%的待评价汉字与样本字的对比
X方向中心G_X误差大于5%的结果有1个,即图8中的“阶”。
X方向重心W_X误差大于5%的结果有4个,包括图9中的“驷”和图10中的“酐”,另外2个结果如图11所示。

图11 造W_X误差大于5%的待评价汉字与样本字的对比
Y方向重心W_Y误差大于5%的结果有2个,如图12所示。

图12 W_Y误差大于5%的待评价汉字与样本字的对比
另外,整字的黑像素比例WAR、左下黑像素比例WARLB和Y方向中心G_Y的误差均小于5%。
4 结束语
通过上述研究,可以得出以下结论:
(1)通过分析标准汉字满足的基本书法规则,定义可能对汉字质量产生影响的属性特征,采用图像处理方法提取获得这些特征量,并经实验测试,确定了其中对汉字品质有重要影响的属性。
(2)采用改进的三层BP神经网络,建立起4个分别针对各项基本书法规则的评价模型。
(3)针对随机产生的待评价汉字,基于神经网络的汉字质量量化评价模型能够较准确地反映出汉字的品质,为字体调整提供参考。该评价模型应用于汉字字库的制作过程中,将减少对于构字结果的人工干预,提升工作效率,进而缩短制作周期,降低成本。
(4)对于样本字的选择,目前采用随机选取方式,虽然覆盖范围较大,但因为基本书法规则体现的是总体特征,若随机将特殊汉字作为样本字,学习精度就会受到很大影响,所以今后的工作将着重于样本字的选择方法,以进一步提高评价模型的精度。
[1]方正.如何制作电脑中文字库[J].印刷质量与标准化,1999(6):35-36.
[2]夏自由.字库知识浅谈[J].印刷技术,2006(13):64-66.
[3]陈禹伶.基于部件融合的“我”体字库的建立[D].绵阳:西南科技大学,2008.
[4]Zhou Bao-yao,Wang Wei-hong,Chen Zhang-hu.Easy generation of personal Chinese handwritten fonts[C]//Proceedings of the 2011 IEEE International Conference on Multimedia and Expo.2011:1-6.
[5]潘志庚,马小虎.基于Fourier级数描述器的多种汉字字形自动生成[J].软件学报,1996,7(6):331-338.
[6]张璇.字体与版式设计[M].北京:清华大学出版社,2009.
[7]樊建平.基于汉字结构码量化传统书法规则知识方法的实现[J].中文信息学报,1990,4(4):43-51.
[8]孙燮华.图像处理——原理与算法[M].北京:机械工业出版社,2010:195-211.
[9]龚声蓉,刘纯平,等.数字图像处理与分析[M].北京:清华大学出版社,2006:238-259.
[10]谭军,冯明帅,胡迎梅,等.基于笔画形态与结构的自动笔迹鉴定[J].广东公安科技,2010(1):11-15.
[11]Zhang Li-xin,Zhao Yan-nan,Yang Ze-hong,et al.Feature selection in recognition of handwritten Chinese characters[C]//Proceedings of the 2002 International Conference on Machine Learning and Cybernetics.2002:1158-1162.
[12]罗成汉.基于Matlab神经网络工具箱的BP网络实现[J].计算机仿真,2004,21(5):109-111.
[13]张德丰.MATLAB神经网络应用设计[M].北京:机械工业出版社,2009:92-119.
[14]韩力群.人工神经网络教程[M].北京:北京邮电学院出版社,2006:58-78.
