一种基于k-均值聚类的异常检测技术
2014-10-15白宁
白 宁
(山西警官高等专科学校计算机科学与技术系,山西 太原 030021)
0 引言
随着网络技术的发展,以及人们管理和知识水平的提高,对于客观世界事物的描述更加全面,现实世界中需要存储和处理的数据量也越来越大,但如何从这些海量复杂数据中提取异常但对于用户重要的信息,依然是一个亟待解决的问题。数据挖掘[1]就是从大规模的、不完整的、有噪声的、模糊的、随机的复杂数据集中提取隐含的、潜在有用的信息或知识。异常检测是数据挖掘领域的一个重要研究方向,其主要用来检测数据集中偏离正常分布模式的异常数据。目前常采用的异常检测技术包括监督的、半监督的和无监督的异常检测方法。
基于监督的异常检测技术通过给出带标签的正常数据集和异常数据集来构成整个训练集,常用的基于监督的异常检测技术包括:基于概率统计的方法[2]、基于数据挖掘的方法[3]、基于神经网络[4]的方法等。基于半监督的异常检测技术只给出部分有标记的正常数据构成训练集,而没有异常数据的标记。在半监督异常检测过程中,通过正常数据的标记来挖掘异常数据信息。李和平等[5]通过自动选择正常行为模式建立正常模型,提出一种基于半监督学习的异常检测方法,具有较高的可靠性;Hu等人[6]提出一个自组织层次神经网络模型,并通过轨迹分布模式来检测局部可能的异常现象;Zhang等人[7]通过正常数据集对正常模型进行建模,然后不断迭代使用贝叶斯自适应的隐马尔可夫模型判断异常。
尽管基于监督学习的异常检测方法虽然能够通过建立准确的正常模型来进行异常检测,但是需要对数据进行手工标记来获取足够的训练样本,成本较大,因此人们提出了基于无监督的异常检测方法。基于无监督学习的异常检测方法从无标签样本集中提取有用的信息,该方法具有代价小、适用范围广、适时性好、可独立于数据工作等优点。
聚类作为一种典型的无监督数据挖掘方法,目前已在异常检测领域得到成功应用。常见的聚类模型包括:划分聚类、层次聚类、密度聚类、网格聚类、概率聚类和谱聚类等。Yasami等人[8]提出了基于决策树算法的无监督异常检测算法,该方法分别从聚类算法和ID3决策树算法中提取异常分数,结合起来生成最终的异常评分值进行异常检测;Park等人[9]通过建立用户连续活动的数据流,采用基于数据流分析的聚类算法对用户的正常行为建模来实现异常检测;李娜等人[10]结合信息熵理论提出了一种基于层次聚类的无监督异常检测算法;周亚建等人[11]提出了基于CURE聚类算法的无监督异常检测方法以迅速、准确地检测出入侵行为。
由于实际问题中用户行为的多样性和不可预知性,以及人工标注的代价较大,传统异常检测方法通过提前设定正常模式的方式进行学习变得异常困难。针对这个问题,本文提出一种基于k-均值聚类的自动异常检测方法(OD_KC方法)。该方法通过对无标签的样本集进行k-均值聚类,通过调整不同的聚类个数,衡量聚类结果的抱团性和分离性,以获得最佳的聚类结果,同时自动地得到那些被划分为很小规模的类的样本作为异常模式样本。基于k-均值的异常检测方法具有很强的自主性和自适应性,特别地,当样本分布模式发生变化时,算法的检测结果也能随之而自动更新,因此具有较好的异常检测能力。
1 传统k-均值聚类方法
在众多聚类方法中,k-均值聚类是一种最为经典使用最为广泛的划分聚类方法[12-13]。k-均值聚类方法以各类样本的质量中心代表该类进行迭代,从而通过不断地动态调整各类中心进行聚类。
设聚类样本集为X= {xi,i=1,…,n }且 xi∈Rd,k为初始聚类个数参数。传统k-均值聚类方法首先从n个样本中随机选择k个样本作为初始聚类中心,然后根据其他样本与已得到的聚类中心的相似度分别分配到最相似的类中心所属类中。2个样本xi与xj的相似度定义如下:

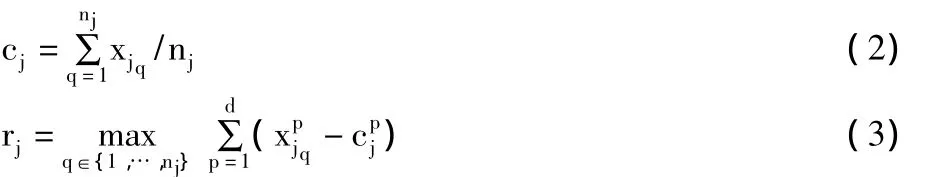
本文结合k-均值聚类方法能够根据样本相似度进行自适应聚类的特性,提出一种基于k-均值聚类的自动异常检测方法。通过对样本集进行多次不同k值的k-均值聚类,通过构造测度函数衡量聚类结果的抱团性和分离性,以获得最佳的聚类结果,同时自动得到那些被划分为很小规模类的样本作为异常模式样本。
2 基于k-均值聚类的异常检测方法
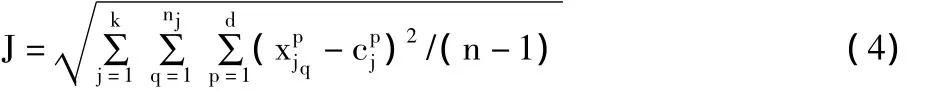
其中,d为样本维度,ni为聚类结果中第i个类的类内样本个数,k为聚类参数。然后逐次改变聚类参数k值,观测评测指标J的变化,从而自动地得到较为合理的聚类结果,以发现数据中的异常模式。
基于k-均值聚类的异常检测算法具体过程如下:
算法1 基于k-均值聚类的异常检测算法
Step2 对样本集X进行k-均值聚类,得到初始聚类结果,具体过程如下:
Step2.1 从样本集X中随机选择k(t)个样本构造初始聚类中心集
Step2.2 根据式(1)计算样本集中每个样本xi(i=1,…,n)与所有不同类心之间的相似度S,并分别将每个xi归为与其最相似的类中心所属的类;
Step2.4 观测更新前后的聚类中心集合C(t)是否一致,若不一致,则返回Step2.2继续执行,直到更新前后的聚类中心一致为止;若一致,则得到本论聚类的聚类结果X→。
Step5 算法结束,输出异常模式样本。
3 实验结果及分析
为验证本文提出的基于k-均值聚类的异常检测方法的有效性,本文在4个标准数据集上进行实验。实验在1台PC机(2Ghz CPU,4G内存)上进行,实验平台是Matlab 2008。实验采用的标准数据集[14]见表1。
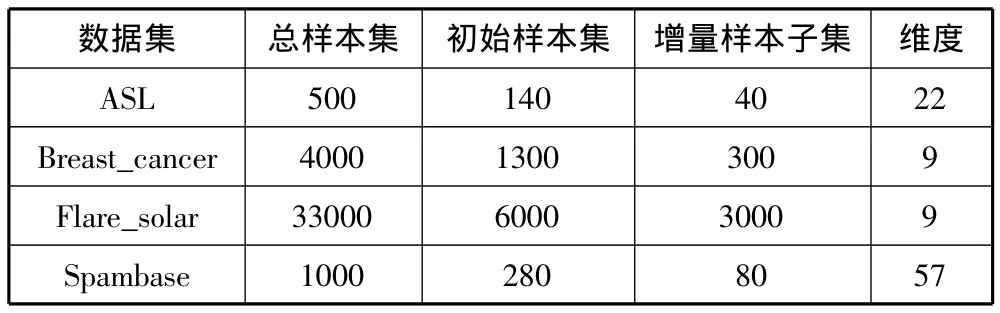
表1 实验数据集
表2列出了基于k-均值聚类的异常检测方法所得到的检测结果。实验中,4个数据集上的初始聚类参数k值分别根据样本规模的大小依次取20,50,200和 25。实验中的聚类结束参数 ε取 1.5。

表2 OD_KC算法的异常检测结果
综上可看出,本文提出的基于k-均值聚类的异常检测方法具有很强的自主性和自适应性,特别地,当样本分布模式复杂时,也能得到较为优秀的检测结果,因此具有较好的异常检测能力。
4 结束语
针对传统异常检测方法需要提前设定正常模式的缺陷,本文提出一种基于k-均值聚类的自适应异常检测方法。该方法通过对无标签的样本集进行k-均值聚类,通过调整不同的聚类个数,通过构造测度函数,以衡量聚类结果的抱团性和分离性,从而获得最佳的聚类结果,同时自动得到那些被划分为很小规模的类的样本作为异常模式样本。在今后工作中,笔者将进一步结合并行计算方法探讨基于k-均值聚类方法在大规模异常检测问题中的应用。
[1]苗夺谦,王国胤,刘清,等.粒计算:过去、现在与展望[M].北京:科学出版社,2007.
[2]Staniford S,Hoagland J,McAlerney J.Practical automated detection of stealthy portscans[J].Journal of Computer Security,2002,10(2):105-136.
[3]Bridges S,Vaughn R.Fuzzy data mining and genetic algorithms applied to intrusion detection[C]//Proceedings 23rd National Information Systems Security Conference.Baltimore,2000:13-31.
[4]Sung A,Mukkamala S.Identify important features for intrusion detection using support vector machines and neural networks[C]//IEEE Proceedings of the 2003 Symposium on Application and the Internet.2003:209-216.
[5]李和平,胡占义,吴毅红.基于半监督学习的行为建模与异常检测[J].软件学报,2007,18(3):527-537.
[6]Hu W M,Xie D,Tan T N.A hierarchical self-organizing approach for learning the patterns of motion trajectories[J].IEEE Transactions on Neural Networks,2004,15(1):135-144.
[7]Zhang D,Gatica-Perez D,Bengio S,et al.Semi-supervised adapted HMMs for unusual event detection[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2005:611-618.
[8]Yasami Y,Mozaffari S P.A novel unsupervised classification approach for network anomaly detection by k-means clustering and ID3 decision tree learning method[J].ACM Journal of Supercomputing,2010,53(11):231-245.
[9]Park N H,Oh S H,Lee W S.Anomaly intrusion detection by clustering transactional audit streams in a host computer[J].Information Sciences,2010,180(12):2375-2389.
[10]李娜,钟诚.基于划分和凝聚层次聚类的无监督异常检测[J].计算机工程,2008,34(2):120-123.
[11]周亚建,徐晨,李继国.基于改进CURE聚类算法的无监督异常检测方法[J].通信学报,2010,31(7):19-23,32.
[12]Elkan C.Using the triangle inequality to accelerate kmeans[C]//Proceedings of the Twentieth International Conference on Machine Learning.2003:147-153.
[13]曹文平.一种有效k-均值聚类中心的选取方法[J].计算机与现代化,2008(3):95-97.
[14]UCIrvine.UCI Machine Learning Repository[DB/OL].http://archive.ics.uci.edu/ml/,2013-08-13.
