基于社会正则化的推荐算法研究
2014-10-15王雪婷黄文亮
王雪婷,黄文亮
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
随着近十年来Web 2.0技术的发展与普及,人们的日常生活越来越受到社会网络的影响。社会网络不仅仅是人们通常说的社会性网络服务,凡是能够连接人与人的媒介,都可以称为社会网络,其中以Facebook、Twitter、新浪微博、人人等为代表,吸引了众多人的眼球。根据尼尔森2010年的报告,用户在互联网上近22%的时间花费在社会网站和社交媒体上。虽然现在社会网络已成为互联网上最热门的应用,拥有庞大的流量和海量的数据,但是如何从中尽可能多地提取出对用户有意义的信息仍然是一个非常巨大的挑战。将推荐系统技术与社会网络相结合,利用推荐技术解决社会信息过载的问题成为科研工作者的研究热点[1]。本文正是在这样的研究背景下,通过利用社会网络信息对用户建模来产生推荐。
1 相关工作
1.1 问题描述
在社会标注系统中,如何向用户推荐项的问题,主要利用社会标注系统中的2类数据[2-3]:用户之间的朋友关系数据、用户对项的所打的标签数据。
用户之间的关系可以用矩阵表示,当矩阵中值为1时表示用户之间有朋友关系,如表1所示。用户对项的所打的标签数据可以用三元组<用户、项、标签>来表示,将该数据表示成三维张量的形式,本文将三维矩阵分别映射到二维平面上,得到<用户、项><用户、标签><项、标签>3个二维矩阵。这里用表2表示,其中横轴Um表示用户m、纵轴In表示项n、矩阵中的值Tmn表示用户m对项n所打标签的集合。
本文基于以上数据,针对推荐技术如何与社会网络应用结合的问题,分析社会网络中的用户、标签、项之间的关系,以及如何利用用户间及用户与项之间的关系进行社会化推荐。在表3中,给出了本文需要使用的缩写和概念。

表1 用户-朋友矩阵

表2 用户-项-标签矩阵

表3 概念和描述
1.2 用户标记数据预处理
传统协同过滤推荐系统的标签数据集存在如下缺陷:二值评分矩阵不能提供足够的有效信息。如表1所示,用户仅对喜欢的项做标记(标为1),不能很好地表示用户的喜恶。文献[4]提出了一种利用标签数据平滑评分矩阵的方法,利用标签数据平滑评分矩阵中的0-1值是更具有表达力的实数值。
文献[4]给出了2个参数来平滑数据:置信度(saving confidence)和似然度(saving likelihood)。似然度用来估计用户标记项的概率,置信度反映了这种似然的可靠程度。最终用户u标记项i的概率pu,i表示为置信度 cu,i和似然度 lu,i的乘积,如公式(1):

则用户对项的似然度如公式(2):
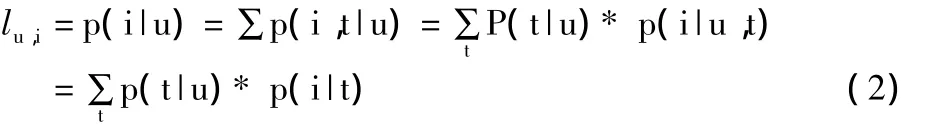
其中,p(i|t)表示用户使用标签t时,项为i的概率。

利用公式(3)可计算出用户-项的概率矩阵,即利用该矩阵进行项的推荐。本文将该过程作为对标记矩阵的预处理,用于社会正则化模型。
1.3 用户相似度计算
大多数基于标签的推荐系统都是统计用户-标签共同出现的次数来表示用户对该标签的权重。但是,这种不考虑用户对项所打标签数目的方法是不公平的。本文提出一种标签加权方法,如公式(4):
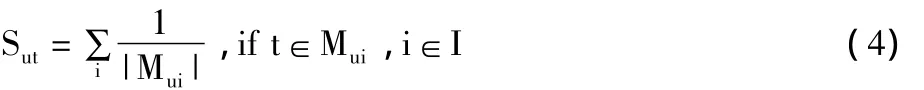
其中,Sut表示用户u中标签t的权重,Mui表示用户u对项i所打标签集合,|Mui|表示用户u对项i所打标签数。对于该加权方法的形式化描述为:对于目标用户u,需要计算其对标签t的权重。
综上给出结合平滑后的用户-标记矩阵和经过加权后的用户-标签矩阵来计算用户间相似度的方法。计算公式如下:

其中,vss(x,y)用来计算向量x、y之间的相似度或相关性,本文使用余弦距离作为向量间相似度的度量方法[5]。vss(Ri',Rj')表示平滑后的用户标记向量之间的余弦距离,vss(Si',Sj')表示加权后的用户标签向量余弦距离。
1.4 用户-项关联度计算
传统协同过滤算法中,利用评分矩阵可以很方便地计算用户之间、项之间的相似度,而对用户和项之间的相关性往往无法评估。本文提出一种用户和项关联度的计算策略:将用户、项同时映射到标签空间,在标签空间中利用公式(6)来计算它们之间的关联度:

其中,Su为利用上文中所述进行标签加权后的用户-标签矩阵中用户u的标签向量。这里对项-标签矩阵Ti也进行标签权值的计算,具体如公式(7):

其中,Tit表示项i中标签t的权重,Mui表示用户u对项i所打标签集合,|Mui|表示用户u对项i所打标签数。对于该加权方法的形式化描述为:对于目标项i,需要计算其对标签t的权重。
2 基于社会正则化的推荐模型
文献[6]提出了一种融合朋友关系的社会正则化模型,该模型利用朋友关系来约束矩阵分解中用户特征向量。本文基于该思路,提出在社会标注框架下的社会正则化模型,该模型不仅考虑用户间的朋友关系,并且将用户和项的关系融入模型中以提高推荐的精确度。
2.1 基于平均的社会正则化
在现实世界中,当无法决定该看什么电影或该去什么地方的游玩时,人们常常寻求朋友的意见。有时会咨询很多朋友,然后综合朋友们的建议来做决定。通常人们倾向于与自己有相同爱好或品味的朋友,以及在需要咨询的问题上较有权威的朋友。
基于以上观点,本文采用如下矩阵分解模型[7-10]:
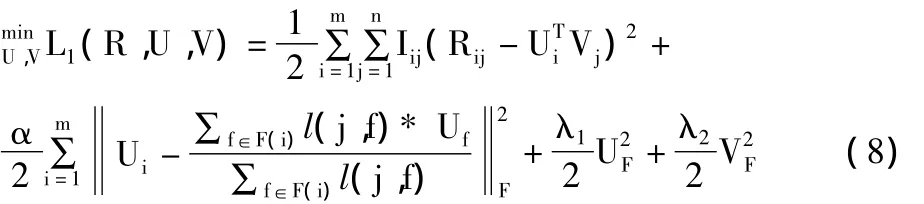
其中,Rij表示训练集中用户i对项j有评分;Ui表示用户i的特征向量,Vj表示项j的特征向量;‖.表示Frobenius norm,α为模型参数,值大于0;F(i)表示用户i的朋友列表。
上述目标函数中引入了社会正则化项为:

其中,l(j,f)表示项j与用户f的关联度,该关联函数可以让正则化项对于不同项区别对待用户的朋友。
这种正则化方法的潜在假设为:每个用户的爱好接近他所有朋友爱好的平均。但在现实生活中,这种情况往往是不成立的。因此,本文在上述模型的基础上加上用户间的相似度来区别对待用户的朋友,目标函数以及式中的社会正则化项可以改为以下公式:

其中,S(i,f)表示用户i与用户f的相似度,该相似函数可以让正则化项区别地对待用户的朋友。
2.2 基于个体的社会正则化
在上文中提出的社会正则化矩阵分解模型中,用户的爱好被限定为接近他所有朋友爱好的均值。但是,如果某个用户的朋友的爱好分布很分散,那么就会出现信息丢失以导致模型不准确。于是,本节提出一种基于个体的社会正则化方法,代替上文中所述的批量式正则化方法,采用增量式的正则化方法。正则化项公式如下:
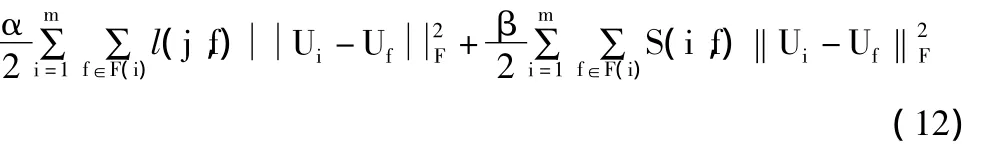
其中,α >0,β >0,l(j,f)表示项 j与用户 f的关联度,S(i,f)表示用户i与用户f的相似度。于是,基于个体的社会正则化矩阵分解的目标函数如下式:

本文将社会正则化目标函数的优化算法命名为OPT_SR算法,该算法中需要优化的目标函数如公式(10)和公式(13)所示。利用梯度下降法[11-13]寻找用户和项的特征向量,R、α、β、L、S|U|×|U|、l|U|×|V|作为输入数据,U|U|×ku,V|V|×kv作为输出数据。其中:
(1)R为通过公式(1)平滑后的用户-项矩阵;
(2)L为需要优化的目标函数,如公式(10)和公式(13);
(3)α、β为正则化参数,如公式(10)和公式(13);
(4)S|U|×|U|为通过公式(5)计算出的用户相似度;
(5)l|U|×|V|为通过公式(6)计算出的用户、项的关联度;
(6)U|U|×ku、V|V|×kv为算法需要学习的用户、项特征空间向量。其中,|U|为用户数,|V|为项数,ku、kv分别为用户、项的特征维度。
3 实验结果及分析
本文所使用的数据集来自于社会标签网站Delicious系统,该数据集包含社会网络信息、书签(项)信息、标签信息。社会网络信息包含1867个用户之间的15328条的连接关系,数据稀疏度为0.4398%。用户标记信息包含64305条标签名、69225条项信息、1867个用户信息、437593条标记信息(<用户、项、标签>为一条标记信息)。
在实验评价中,本文采用精度(precision)、召回率(recall)等评价指标来衡量上文所述模型的推荐质量的优劣。对于用户u,令Ru为给定用户u的长度为N的推荐列表,该表包含用户会打标签的项。令Tu为用户实际上打过标签的项集,则准确率、召回率分别表示如下:
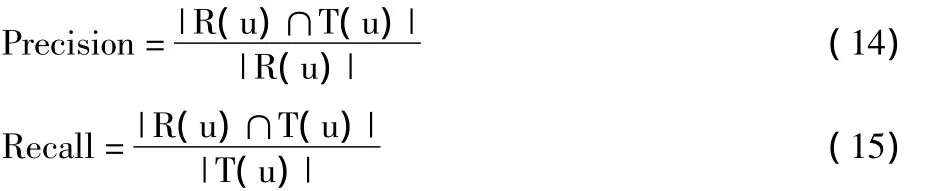
在实验评价中,笔者采用 P-1、P-3、P-5、R-5这几种评价指标,分别定义为:向用户推荐1个项时系统的准确率值、向用户推荐3个项时系统的准确率值、向用户推荐5个项时系统的准确率值、向用户推荐5个项时系统的召回率值。
本文选择进行以下3组实验:
(1)最热门推荐算法。该算法流程为:统计每个用户最常用的标签;对于每个标签,统计具有这些标签最热门的项;对于目标用户,首先找到他最常用的标签,然后找到具有这些标签的最热门项推荐给用户。这里“热门”利用上文所述的用户-标签权重算法和项-标签权重算法来计算。
(2)传统的协同过滤推荐算法[14],本文使用基于用户相似度的协同过滤推荐算法。这里用户间的相似度计算方法利用上文中所述的基于用户-项和用户-标签相似度计算的加权方法。当用户间的相似度高时,表示他们拥有更多相同的爱好。
(3)基于社会正则化的推荐算法,即本文提出的2种算法:基于平均的正则化以及基于个人的正则化。如上文所述:首先将用户-项矩阵进行数据预处理,并利用用户-项-标签之间的三元关系计算出用户和项的关联度及用户间的相似度。然后将以上数据融入到社会正则化模型中,计算出用户和项的特征空间向量。最后,利用用户和项在特征空间中的低维表示进行内积计算出用户对项的感兴趣程度进行推荐。
利用 Pop、UCF、SR-avg-k、SR-p-k 分别表示上述的方法:最热门推荐算法、传统协同过滤推荐算法、基于平均的正则化算法、基于个人的正则化算法。其中SR-avg-k、SR-p-k中的k值表示用户、项的特征空间维度值。
上述4种算法的评价指标的情况如表4所示。
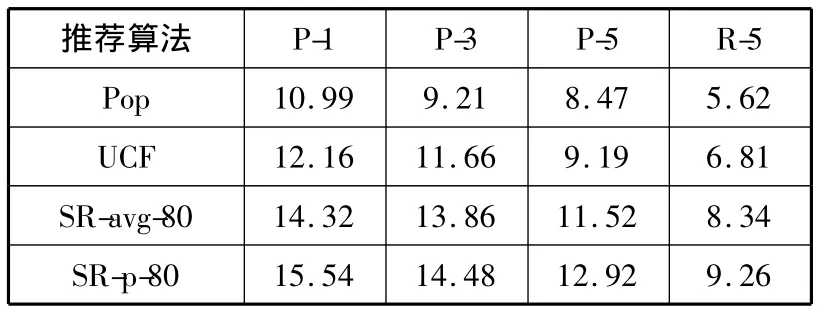
表4 4种推荐算法精度对比
表4显示的是4种推荐算法的P-1、P-3、P-5、R-5指标的值,可以很直观地看出本文所提出的社会正则化算法在各项指标上取得较好的结果,改进后的推荐算法的精度高于传统推荐算法的精度。
基于社会网络的推荐系统主要解决的问题是社会信息的过载,通过推荐算法的精确度证明了本文提出的基于社会正则化的社会化推荐模型可用来解决社会信息冗余问题。
4 结束语
本文主要介绍利用社会网络中的朋友关系等社会化信息进行推荐的社会正则化方法,首先利用标签信息平滑数据,然后利用用户-项矩阵及用户-标签矩阵进行用户相似度计算,最后本文提出一种基于社会正则化的推荐算法,建立相应的模型,然后将用户之间的相似度信息及用户与项之间的关联度信息融入到传统的矩阵分解模型中。实验结果表明,该算法有效地提高了推荐算法的准确率,使得社会化推荐系统较之传统的推荐系统具有更好的推荐效果。
[1]Resnick P,Iacovou N,Suchak M,et al.GroupLens:An open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work.1994:175-186.
[2]Tso-SutterK H L,Marinho L B,Schmidt-Thieme L.Tagaware recommender systems by fusion of collaborative filtering algorithms[C]//Proceedings of the ACM Symposium on Applied Computing.2008:1995-1999.
[3]Marinho L B,Schmidt-Thieme L.Collaborative tag recommendations[C]//Data Analysis,Machine Learning and Applications.Springer Berlin Heidelberg,2008:533-540.
[4]Peng J,Zeng D.Topic-based Web page recommendation using tags[C]//IEEE International Conference on Intelligence and Security Informatics(ISI’09).2009:269-271.
[5]Kenney J F,Keeping E S.Mathematics of Statistics,Part 2[M].Van Nostrand,1947.
[6]Ma H,Zhou D,Liu C,et al.Recommender systems with social regularization[C]//Proceedings of the Fourth ACM International Conference on Web Search and Data Mining.2011:287-296.
[7]Nguyen J,Zhu M.Content-boosted matrix factorization techniques for recommender systems[J].Statistical Analysis and Data Mining,2013,6:286-301.
[8]Koren Y.Collaborative filtering with temporal dynamics[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2009:447-456.
[9]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[10]Rennie J D M,Srebro N.Fast maximum margin matrix factorization for collaborative prediction[C]//Proceedings of the 22nd International Conference on Machine Learning.2005:713-719.
[11]阿佛里耳(M·Avriel).非线性规划:分析与方法[M].李元熹,等译.上海:上海科学技术出版社,1979.
[12]Jan A Snyman.Practical Mathematical Optimization:An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms[M].Springer-Verlag New York Inc.,2005.
[13]刘颖超,张纪元.梯度下降法[J].南京理工大学学报:自然科学版,1993(2):12-16,22.
[14]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
