基于GPU的交叉相关外推并行化算法
2014-10-14王介君
王 兴,王介君,孙 宁,汪 瑶
(南京信息工程大学大气科学学院,江苏 南京 210044)
0 引言
交叉相关算法是当今应用效果较好的外推方法之一,在大气科学、地质勘探、计算机图形图像处理、模式识别与跟踪等领域得到广泛研究与应用。在气象方面,交叉相关是短时临近预报的常用算法之一。它不仅可应用于气象雷达数据的跟踪外推,获得晴空边界层气流及降水回波强度的相关信息[1-2],还可应用于对卫星云图中云团移动的短时预测及数值预报等诸多方面[3-4]。
由于该算法的时间复杂度高、运算量大,在对高清图像的实时跟踪识别或气象精细化外推预报等方面,运算速度无法满足业务要求。以广东及周边地区的地闪定位资料外推为例,资料精度为0.001°,经纬网格数为14000×9000,算法的时间复杂度为 O(n3),在不做任何改进的情况下,外推一次的运算次数不少于1587万亿次,而Intel Core i7-3930K的计算能力约为186 GOPS,服务器用Intel Xeon E5-1620的计算能力也仅为115 GOPS,完成这样一次计算至少需要3小时20分钟。
鉴于此,许多学者结合行业应用特征对算法进行了改进和简化。朱永松等[5-6]给出了相似性度量的快速实现方法,通过对算法进行归并和近似计算,解决了目标跟踪的实时性要求。李卓[7]等通过对相关系数公式进行简化和迭代,减少重复运算,并通过设定参考图像与目标图像的相关系数阈值减少计算量,从而提高了运算速度。
尽管各种改进或简化后的算法在一定程度上提高了计算速度,但多是以牺牲计算的精度或准确性为代价,且对于如气象上外推预报方面的应用,动辄数十分钟甚至小时级的运算时长,根本不能满足实际业务要求。因此,有必要从承载计算的硬件层面进一步分析。
本文针对 AMD架构 GPU的特点[8],运用OpenCL技术对传统的串行交叉相关外推算法进行并行化改进,并从算法流程、主存与设备内存之间的数据传输,以及显存访问模式等几方面对算法进行优化。
1 交叉相关外推地闪落点的串行算法分析
地闪是云体对大地的放电现象,它的发生对电力、通讯、交通运输系统有着极其重要的影响。近年来,随着雷电定位系统网络的建设和大量资料的积累,人们对地闪的分布情况及跟踪预测不断取得新的理论方法和成果。但由于雷暴云的起电机制十分复杂,且具有瞬时电压极高、电流极大、电磁辐射极强等特点,因此,对于雷暴云相关物理过程的监测预测仍存在相当大的难度[9]。
交叉相关算法作为一种常用外推预测方法,在经历了较长时间的研究与应用并不断改进后,数学理论上已相对成熟[10]。该方法的总体思路是利用两组相邻时间的地闪监测数据,通过最大相关系数法进行匹配,寻求两组地闪数据之间的空间最优相关,从而得到△t时间内地闪落点区域的移动速度和移动方向,进而外推得到下一时刻地闪的分布特征。应用该算法的前提条件是,假设地闪落点分布的演变过程是线性的。主要过程分为如下几步:
(1)根据监测资料的地理范围,划分等间距的经纬网格,得到M×N的二维矩阵。将相邻两个时次离散的数据按其经纬度信息分别填充到初始闪电场和比对闪电场二维矩阵对应的单元网格中,对同一时刻同一地理位置发生多次闪电的情况做累加统计,从而得到初始闪电场数据矩阵A[m,n]和比对闪电场数据矩阵 B[m,n]。
(2)选取一个整数a,规定a的大小必须小于M和N,在初始矩阵A中以a为边长划定一个正方形区域,称作目标矩阵C[x,y],该区域左上角第一个单元 C[0,0]可在 A[0,0]至 A[M-a-1,N-a-1]之间逐格移动。a的取值视地闪监测的地理区域、范围、强对流天气形势、雷暴天气种类等业务场景的不同而有所区别。
(3)设定一个搜索范围L,对初始矩阵A中每一个选定的目标矩阵C[x,y],在比对矩阵B中以 B[x,y]为中心,向四周分别扩展L个单元作为比对矩阵B相对初始矩阵A中目标矩阵C的搜索匹配范围,然后自左向右、自上而下逐格移动并计算交叉相关系数R,公式为:

其中U、V分别表示目标矩阵C的长和宽,本算法中即为整数a;C为目标矩阵,其中每个单元记录了相应经纬度闪电频次的累加值;S表示比对矩阵B相对目标矩阵C的一个搜索矩阵;i和j表示目标矩阵或搜索矩阵的单元格坐标和分别表示搜索矩阵和目标矩阵所有单元值的平均值;x和y表示比对矩阵B在搜索范围内位置的坐标,其取值与搜索范围的大小相关,而搜索范围需根据外推时间间隔的长短以及雷暴强度等气象因素综合考虑,通常情况下,L为a的3~8倍。
(4)通过比较每一个目标矩阵C与其最优相关的比对搜索矩阵D的位置坐标,可得到△t时间内两者的位移矢量,从而建立最优匹配比对位置的位移矢量数据库。又由于时间间隔已知,进而可建立平面上的速度矢量数据库。
(5)通过对初始矩阵A中每个目标矩阵C进行上述计算,可得到初始矩阵A与比对矩阵B之间的线性关系。
由于经纬度和时间间隔已知,从而可建立时间间隔与速度、位移的线性关系,并推测下一时刻所对应的位置。
2 交叉相关算法的并行化设计
OpenCL(Open Computing Language)是一套为异构平台编写程序的框架,此异构平台可由CPU、GPU或其他类型的处理器共同构成[11]。本文选用的硬件平台为:Intel Core i7-3770 CPU,AMD Radeon HD 7970(DDR5 3072 MB)核心显卡,其显存位宽384 bits,显存带宽 268.8 G/s,峰值计算能力可达 4.1 TFLOPS。因此,算法并行化的设计及优化主要针对AMD Series GPU。
2.1 计算及控制流设计
图2说明了交叉相关算法SPMD(单程序多数据)的实现,SPMD执行同一段代码的多个实例,每个实例对数据的不同部分进行操作。在不考虑显存容量限制和Bank访问冲突等因素的情况下,理论上可将如图1中最外两层循环(约126万次)的操作归并为1次并发操作。

图1 交叉相关串行算法N-S流程图

图2 交叉相关并行算法N-S流程图
2.2 数据传输优化
要执行OpenCL计算内核,就需要分配设备内存空间并将Host(宿主机)相关内存数据复制到设备内存中。当前绝大多数显卡都是通过主板上PCI-E接口与主存进行双向数据传输,然而最新PCI-E×16 v3.0接口的双向数据传输理论带宽是32 GB/s,这与GPU访问设备内存的速度仍存在相当大的差距。所以,设计合理的数据传输策略是提升GPU计算吞吐量的重要环节。
针对本算法,宿主机代码充分使用Buffer对象,减少Host内存与设备内存的交互,提高设备内存自身的使用率。通过下列代码,将初始矩阵和比对矩阵中的数据批量传入设备内存。
int CT=iLongitude*iLatitude;
MO[0]=clCreateBuffer(cnt,CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR,sizeof(float)*CT,a,NULL);
MO[1]=clCreateBuffer(cnt,CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR,sizeof(float)*CT,b,NULL);
MO[2]=clCreateBuffer(cnt,CL_MEM_READ_WRITE,sizeof(float)*CT,NULL,NULL);
每次目标矩阵与搜索矩阵的交叉相关系数计算,都会产生中间结果,可以选择在设备内存上申请空间来存放这些数据,从而避免设备内存与主存的频繁数据交互。当kernel运算完成后,只要将计算结果输出到Host内存,代码如下所示。
因此,行动可以定义为有序对<输入状态,输出状态> 。在计算机科学中比较关注的是程序,下面只给出一个简单的扩充形式。输入状态,输出状态
clEnqueueReadBuffer(CQ,MO[2],CL_TRUE,0,sizeof(float)*CT,r,0,NULL,NULL);
MO是一个Buffer对象数组,其中包含3个对象,分别用于存储初始矩阵、比对矩阵和外推结果数据。CT定义了矩阵数组中元素的总数量。
2.3 内存访问的优化
kernel程序的执行效率很大程度上依赖于设备内存,影响性能的主要方面包括访存次数和访存模式。根据AMD GPU的硬件架构设计,基于Byte地址的总线要访问设备内存,访问地址必须和内存位宽对齐。由于HD 7970的内存位宽是384 bits,因此必须按48Bytes对齐来访问内存。如访问地址0x00002540,此时它会同时得到 0x00002540到0x0000256F的所有数据。如果本次访存只是为了取一个32 bits整数,那么其余44个字节的数据未能参与计算,因而高带宽的优良特性就白白浪费了。相反,如果多个线程访问连续48个字节以内的地址,则可以通过一次访存请求来完成,从而大幅提高带宽利用率。该技术称作 Coalescing[12]。
为了充分利用HD 7970超大的显存位宽,且由于HD 7970每个CU(Compute Unit)能够在一个周期内处理一个64线程的quarter-wavefront,因此,本算法设计时考虑将64个线程的内存访问合并到较少的内存请求命令中去。
由于GPU计算的并行要求,在对目标矩阵和搜索矩阵进行计算时,kernel程序会多线程分段处理数组。通常的做法是把数组分成多段,然后每个线程处理每段数组中连续的若干元素,kernel代码如下:

该数据读取的模式称为Sequencial Access,示意流程如图3所示。当Thread_0访问Data1[0]的元素时,Thread_1则访问 Data1[array_lenth/get_global_size(0)]的元素,同理,Thread_2则访问 Data1[2*(array_lenth/get_global_size(0))]的元素。很明显该方法破坏了数据访问局部性的原则,会造成读取性能的急剧降低。

图3 Sequencial Access流程图
由上述分析,可对数据读取模式作适当改进,kernel代码如下:

当Thread_0访问Data1[0]时,Thread_1访问Data1[1],Thread_2 访问 Data1[2],以此类推。如此kernel程序就能充分利用数据读取的局部性特点,从而极大地提升内存读取的速度。这样的数据读取模式称为Coalescing Access,示意流程如图4所示。

图4 Coalescing Access流程图
2.4 使用公共C函数库
OpenCL规范中定义了大量的内置函数,很多与公共C库提供的函数类似,其特点是支持矢量数据类型。但由于其对精度的要求,OpenCL内置数学函数的运算性能往往不如C原生函数。针对本算法需要的精度而言,使用公共C函数库math.h中的pow函数代替OpenCL中的pow可在一定程度上提升kernel程序的运行效率。
2.5 进一步优化
在CPU中,即便两个线程的行为高度不一致,其对性能的影响也是可接受的。而在并行算法中每个线程的行为需要尽量保持一致,如果分支或跳转过多,则会大幅降低GPU的运算效率。且在GPU中,线程之间的切换是轻量级的,可以把算法中的循环结构完全展开,一个线程就处理一个数据[13-14]。
3 实验结果与分析
3.1 实验数据说明
实验数据选取2013年3月广东省及其周边地区有强对流天气发生时的地闪落点监测资料。该资料包含地闪发生的时间、地理位置、电流强度等信息,其中地闪发生的时间精确到秒量级,地闪发生位置的经纬度精确到小数点后3位,即0.001°。自3月16日开始,南方大部地区经历了多次大范围强降水过程,期间多地还出现雷暴、短时大风、冰雹等强对流天气,给南方多地造成严重的经济损失。通过对3月26日地闪资料的统计分析,得出逐小时地闪发生频次,如图5所示。

图5 2013-03-26广东及其周边地区地闪频次统计
结合资料中经纬度信息可以看出,26日凌晨时分地闪主要分布在江西、湖南的南部及广西东北部,然后逐渐向东南方向移动,在6时地闪发生区域主要分布在广东省及广西东部地区,且单位小时内地闪频次达到最大2397次,随后逐步减弱,11时地闪主要分布于广东省东南沿海地区,14时后因雷暴中心离开内陆,因而监测到的地闪数量显著降低。
3.2 外推结果分析
选取当日5、6和7时监测资料作为实验数据,数据分析范围限定在经度从106°至120°,纬度从18°至27°,精度为0.001°。因此,所分析的矩阵为 14000 ×9000的网格,相邻网格间的距离约为100 m。为清楚显示,剔除地闪发生频次较低的网格后,5、6时的实况如图6所示,其中浅色点为5时,黑色点为6时。

图6 5时、6时地闪落点分布图
将5、6时的监测资料代入上述并行化交叉相关算法程序,分别作为初始矩阵和比对矩阵,经计算得到外推预测的7时地闪落点分布,结果如图7所示,其中浅色点为外推预测结果,黑色点为7时实况。同图6,为清楚显示剔除了地闪发生频次较低的网格。
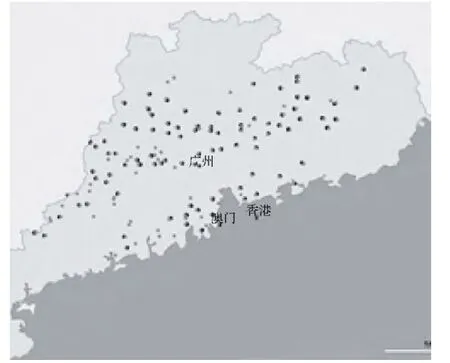
图7 7时外推预测和实况地闪落点分布比对图
从图7可以看出,7时地闪落点分布较图6中5、6时有向东南方向移动的趋势。由于7时监测到的地闪数量超过2000次,而受图片大小限制,图中对显示的落点进行了筛选,又因大部分外推预测的地闪落点与实况重合或部分重合,覆盖了部分实况落点,因此图7看似外推预测的点数多于实况。
3.3 并行算法性能分析
为了更加清楚地对比并行化算法的计算性能,将上述实验中监测资料精度分别减小为0.002°、0.005°和0.01°,即将所分析的矩阵分别缩小到 7000×4500、2800×1800和1400×900的网格。基于上述硬件环境的CPU串行算法程序和基于GPU的并行算法程序执行情况如表1所示。

表1 交叉相关算法程序串行与并行的执行时间对比
分析表1可知,在不考虑数据传输和内存访问等方面优化的情况下,基于GPU的并行算法程序计算效率提高了8至9倍。且随着网格精细度的提高,并行算法的性能提升效果越好。这是因为计算所耗费的时间除了GPU运算本身以外,还有设备内存与主存之间数据交互的时间,当输入数据量和PCI-E接口通信量较小时,整个程序的计算量也有限,GPU计算耗时所占比重较小,而数据交互时间的比重相对较大。随着计算量的逐步增加,GPU并行计算的性能优势越发体现,因而逐渐掩盖了设备内存与主存数据交互带来的时间损耗。
另一方面,通过对数据传输过程的优化,减少设备内存与主存的数据交互,在设备内存空间足够的情况下,尽可能使用其保存计算的中间结果。再运用Coalescing Access技术优化设备内存的访问方式,以及上文提及的其他辅助技术,将该并行算法的性能再提升近一倍,进而达到原串行算法执行效率的17倍。
4 结束语
本文利用GPU在并行计算方面的优势,对传统的串行交叉相关外推算法进行并行化改进,并针对AMD架构的GPU运用OpenCL技术对算法程序进行优化。实验表明,使用本文算法在AMD Radeon HD 7970硬件平台下,程序执行效率相较Intel Core i7-3770 CPU单核计算时提升了17倍。对于广东省及周边地区一小时地闪落点外推预测,在不损失原有监测精度的情况下,由原来计算一次历时6小时37分钟缩短到23分钟。实际业务应用中,如果投入更高性能的GPU设备,如AMD Radeon HD 7990,根据其技术性能参数,有望将计算时长再缩短一半。
关于地闪外推预测算法仍有改进的空间:雷暴作为强对流天气系统中重要的一部分,当今业务中对其的监测、预报还需借助天气雷达、卫星、探空等多种手段以及中尺度数值预报模式等进行综合分析。仅利用闪电定位资料进行外推预测,宏观上可以有效地预测雷暴移动的方向和速度。但微观上看,对于地闪落点、发生频数、生消趋势等方面,其预测结果与实际情况仍有明显差距。未来还可以结合多普勒气象雷达和数值预报等多种手段,对外推预测算法进行基于GPU的并行化改进和优化,以提高预测的准确率。
[1]陈明轩,王迎春,俞小鼎.交叉相关外推算法的改进及其在对流临近预报中的应用[J].应用气象学报,2007,18(5):690-701.
[2]陈雷,戴建华,陶岚.一种改进后的交叉相关法(COTREC)在降水临近预报中的应用[J].热带气象学报,2009,25(1):117-122.
[3]刘科峰,张韧,孙照渤.基于交叉相关法的卫星云图中云团移动的短时预测[J].中国图象图形学报,2006,11(4):586-591.
[4]胡胜,罗聪,黄晓梅,等.基于雷达外推和中尺度数值模式的定量降水预报的对比分析[J].气象,2012,38(3):274-280.
[5]朱永松,国澄明.基于相关系数的相关跟踪算法研究[J].中国图象图形学报,2004,9(8):963-967.
[6]朱永松,国澄明.基于相关系数的相关匹配算法的研究[J].信号处理,2003,19(6):531-534.
[7]李卓,邱慧娟.基于相关系数的快速图像匹配研究[J].北京理工大学学报,2007,27(11):998-1000.
[8]丁鹏,陈利学,龚捷,等.GPU通用计算研究[J].计算机与现代化,2010(1):12-15.
[9]焦雪,冯民学,钟颖颖.2006—2009年江苏省地闪特征分析及应用[J].气象科学,2011,31(2):205-210.
[10]顾媛,魏鸣.南京一次雷雨的闪电特征与多尺度资料分析[J].气象科学,2013,33(2):146-152.
[11]AMD上海研发中心.跨平台的多核与众核编程讲义——OpenCL的方式[Z].上海:AMD上海研发中心,2010:1-10.
[12]Aaftab Munshi,Benedict R Gaster,Timothy G Mattson,et al.OpenCL Programming Guide[M].Addison-Wesley Professional,2011:3-35.
[13]蔡镇河,张旭,栾江霞.CPU+GPU异构模式下并行计算效率研究[J].计算机与现代化,2012(5):185-188.
[14]朱兴锋.基于CUDA的高效IDEA加密算法设计与实现[J].计算机与现代化,2011(12):48-52.
