基于局部呼叫数据建模的相对相似用户分布式查询
2014-10-14张泽西
张泽西,汪 芸
(1.东南大学计算机科学与工程学院,江苏 南京 211189;2.东南大学计算机网络与信息集成教育部重点实验室,江苏 南京 211189)
0 引言
在智能城市的远景规划下,手机网络正在逐渐成长为一个巨大的无处不在的感知平台。这得益于手机在全世界范围内尤其是人口稠密的城市地区极高的持有率,由于与人类活动紧密的连通性,使得越来越多的大规模应用和研究通过手机网络提供的数据对人类群体和个体的属性进行分析,比如理解用户行为[1-2]、城市不同地区的活动类型[3]、预测用户位置[4]等。其研究手段往往是通过对记录在基站网络上的用户呼叫详细记录(Call Detail Records,CDRs)数据集进行分析和数据挖掘。相似用户查询作为一种数据分析的基本方法,返回与被查询的兴趣用户最相似的K个用户,可应用于用户分群、异常检测、基于用户的推荐、观察特定用户群体行为特征等方向。大多数针对CDR的分析和查询假设数据为中心存储,即数据中心需要定期收集CDR数据进行集中存储,再在这些历史数据上进行查询。然而,CDR数据在手机网络中为分布式产生和存储,用户的每一次手机接入电信网的操作(接打电话、收发短信),都会在连接的基站(Cell)上产生一条CDR记录用于记账系统进行计费服务。因此一个用户在一段时间内的所有通信数据可能分布地存储于多个不同的基站上。即使在一天之中,一个用户在不同时间产生的CDR记录也可能存储于不同的基站上(比如工作地点附近的基站和居住地点附近的基站),相比于全部收集到中心之后的全局用户数据,这些分布在各个基站上的CDR数据仅记录这个用户的局部呼叫数据。
本文所要解决的问题就是如何在这样的环境下,充分利用分布存储的用户局部呼叫数据,进行分布式的相似用户查询。本文的目标是以较低的通信代价,高效地找出与被查询兴趣用户相似的一批用户。传统的相似性用户查询技术依赖于集中存储的用户数据,数据收集会导致高昂的通信代价。而纯粹的在各个分布的基站上进行相似用户查询又受限于用户的局部数据,导致查询结果不够准确。为了解决这一问题,本文提出一种基于局部数据的相对相似用户分布式查询方法(RSU-DQ)。整个查询过程由3个阶段组成:(1)数据中心仅收集被查询的兴趣用户的全部局部数据,建立兴趣用户模型;(2)将兴趣用户模型发送至相关基站,各个基站上独立运行相似性查询算法得到候选用户和对应的相似度;(3)数据中心汇聚各基站的候选用户和对应的相似度,排序并返回查询结果。
本文结合真实手机网络CDR记录的产生和存储特性,定义基于局部呼叫数据的相似用户分布式查询问题;分析用户局部呼叫数据与全局用户数据的关系,提出并实现一种低通信代价的高效相对相似用户分布式查询方法(RSU-DQ),以真实数据完成RSUDQ的评估,验证其低时间代价、低通信代价和高准确率的特性。
1 相关研究
在分布式搜索领域有很多研究工作,本文重点关注分布式模式匹配和分布式时空相似性搜索两类工作。分布式模式匹配主要研究如何在分布式存储系统或分布式数据库中快速定位查找“类似”对象,通常以子序列匹配的形式阐述。文献[5]通过对时间序列数据的索引完成一个快速的子序列匹配;文献[6]用部分关键字匹配技术结合特定的P2P网络层次结构进行高效率的字符串匹配;文献[7]用多维度二叉树来提前降低匹配过程计算代价;文献[8]提出了一种基于排序的分布式数据管理的匹配算法,其基本思路是利用降维的方法,把高维的矩阵降为低维(一维)的序列之后应用经典的匹配算法。文献[9]在电信数据的环境下提出不完整数据集的概念数据作为数据源,其匹配算法的核心在于采用带权重的布隆过滤器作为容器,将待匹配的模式集合的全组合映射进布隆过滤器之后,再将该布隆过滤器传输到各节点上进行精确匹配。
分布式时空相似性的搜索主要处理时空数据(Spatio-temporal Data)。文献[10]针对物体的移动轨迹(Trajectory)提出了基于最长公共子序列(LCSS)距离度量的分布式时空相似搜索;文献[11]利用GPS日志,计算出用户的位置信息并按时间顺序将用户轨迹定义为兴趣地点的序列,在此基础上计算其编辑距离;文献[12]针对一个游客信息交流系统设计了一套基于时空近邻性的推荐系统,游客在对地点打分和评价后通过Ad-hoc网络和机会信息共享将本地存储的信息与同地点的游客进行交换。
上述研究都或多或少依赖于分布式节点拓扑结构,即存在中继节点或分布节点之间可以相互通信。而本文所考虑的基站网络环境中,各基站只与数据中心进行通信;用户的呼叫数据在时间上并不具有连续性,各基站的范围过大,并且各基站仅包含用户的局部数据,现有的轨迹聚类方法并不适用于全局相似用户的查询。
2 系统模型
2.1 CDR 数据集
当用户使用手机连入基站网络时,会在其接入的基站上留下一条呼叫详细记录。包括主叫号码、被叫号码、呼叫起始时间、呼叫终止时间、呼叫时长(以秒为单位)、呼叫类型、连接的基站号等信息。其中基站信息常被用来计算用户粗略的地理位置,在隐私保护和可获得性方面优于GPS信息(很多手机用户常常关闭GPS定位功能而CDR数据优于运营商计费需要一定会产生)。
本文使用的CDR数据集由安徽省某城市电信运营商提供,记录了38万用户一个月的通话详细记录。用户主叫和被叫号码等隐私相关信息已被加密。原始的CDR数据集具有以下特点:
(1)分布式。CDR数据产生并存储的各个基站上,通常以较长的周期(一个月)上传回数据中心或者直接抛弃。因此一个人在观察周期内的通信记录常常分布地存储于多个不同基站。
(2)不断进化。在手机网络中,每当用户打一次电话就会产生一条新的CDR记录,即其数据集是不断在增加和变化的。因此定期汇聚基站数据的数据中心往往只能处理历史数据。
(3)大规模。由于用户数量巨大,CDR数据的量往往很庞大,有些市中心的基站一天之内产生的数据量就超过了2G,因此搜索过程中必须要考虑数据传输代价。
2.2 用户模型
不同的应用和研究目的可能导致对相似用户的定义有所不同,然而对于关注用户位置信息的应用[3,11,13]和以用户移动性(Mobility)为主要目的研究[1-2,4]来说,用户在不同时间段的位置信息是至关重要的数据。本文关注的是在同样的时间段出现在相同基站附近的用户,因此需要从CDR中提取呼叫时间和基站号建立用户模型。然而,通过对数据的初步观察(见3.2节),本文发现有很多基站在观察时间内含有非常少量的用户呼叫数据,表明这些地区可能并不是用户在日常生活中经常出现或者访问的地区。为了将这些地区与用户经常出现的地区进行区分,在用户建模过程中还需要从用户的CDR中引入额外的属性以建立用户在不同地区的活跃度。
通过对众多基于CDR的研究的调查,可以发现最常用于建立用户模型的属性包括观测时间间隔内的呼叫次数(Number of Calls,NoC)、呼叫时长(Duration of Calls,DoC)、呼叫人数(Persons of Called,PoC)等。因此本文使用这3个基本属性,结合呼叫行为发生的时间和记录的基站信息(隐含呼叫行为发生时的位置信息),建立用户在特定时间和地区的活跃度模型。
定义1 在时间间隔t,基站Cp上用户Ui包含属性集合={,,…,},f 表示属性的个数。则该用户在此时此基站的活跃度为:

其中 ωd为属性的权重。用户 Ui在观察周期 T 内在基站Cp上的用户局部模型由各时间间隔活跃度组成,=,…,,…,},可以根据相似性用户查询的应用类型对选用属性的个数f和每个属性的权重ωd进行调节。本文选用时间间隔内的呼叫次数和呼叫时长的均值作为其活跃度,即f=2。用户在不同基站上的局部模型组成用户的全局模型gUMi={,,…,},mi为存有用户 Ui的CDR记录的基站个数。按此定义建立的用户模型实际上隐式地表达着用户在不同地区的周期性活跃度。
2.3 相似性定义
用户间相似性一般通过用户模型间的相关系数或距离来表达。本文定义的相对相似性是指用户全局模型的相似度,计算用户间的全局相似度依赖于各基站上用户间的局部模型相似度。用户Ui和用户Uj全局相似度为:

其中 Simp(,)表示用户 Ui和用户 Uj在基站Cp的局部相似度,φp为该基站在兴趣用户全局模型中的权重。注意到全局相似度是一种非对称性相似度[14],gSim(Ui,Uj)不一定等于 gSim(Uj,Ui),即如果用户Uj是兴趣用户Ui的全局相似用户,则表明Uj在Ui的所有局部模型所在的基站上都与Ui相似,反之则不一定成立。本文称这种全局相似度为相对相似度(Relative Similarity,RS),gSim(Ui,Uj)称为用户Uj相对于兴趣用户Ui的全局相似度。
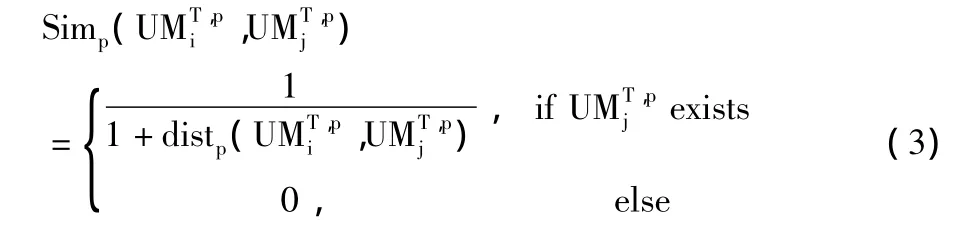
若用户Uj在基站Cp没有局部模型,则其与兴趣用户在该基站的局部相似度为零;若存在则视和为2个时间序列,计算其欧式距离并使用公式(3)转化为局部相似度。对于其他的距离测度或相似性测度将在将来的工作中予以探讨。
3 相对相似用户分布式查询问题
在给出基于局部数据的分布式相似用户查询问题(Relative Similar User Distributed Query problem,RSU-DQ problem)的正式定义之前,首先考虑一个应用情景:运营商希望使用某种基于相似用户(使用2.3节中的相对相似用户定义)的协同过滤算法为某一个(一群)兴趣用户做地点推荐。这就需要在分布式的基站网络中运行相似用户查询来找到与目标兴趣用户,即在分布式基站网络中,哪些手机用户是全局模型相对于目标兴趣用户的全局模型最相似的用户?
由于用户的每一次呼叫都会产生一条新的CDR,导致用户全局模型随着时间流逝在不断进化。因此对于运营商和诸多应用来说,更为近期的用户模型往往比历史数据建立的模型具有更多的商机,因此对于查询的快速响应就显得颇为重要。
3.1 问题定义
本文考虑的环境是分布式基站网络,共有M+1个节点:一个节点是数据中心C0,其他M个节点是基站节点C1,C2,…,CM。所有的基站加起来掌握着一个n个用户的集合USet={U1,U2,…,Un},每个Ui都包含一组T内的用户全局模型gUMi={,,…,},其中 1≤mi≤M。每个用户模型都表示该用户Ui在对应的基站Cp上的一系列活跃度序列。若用户Ui在基站Cp有记录(即有局部模型),称用户 Ui存在于基站 Cp。
输入一个兴趣用户Ui和参数K,基于局部数据的分布式相似用户查询(Top-K Query)要能够找出一组用户集合包含所有的用户中相对于兴趣用户的全局模型最相似的K个用户。该查询由数据中心C0发出,最后的响应也由C0作出。用户Uj相对于用户Ui全局相似当且仅当他们在每一个Ui存在的基站上都相似。相似度的具体计算方法如2.3节所述,将局部模型视为定长的浮点数组成的向量,用于计算局部模型之间的欧氏距离。
3.2 分析和观察
直觉上,有两种思路可以用来完成在分布式基站网络上的相似性用户查询,集中式的查询和分布式查询。
(1)集中式查询:将所有基站上的全部CDR数据传输至数据中心,在集中存储的数据集上运行集中式查询算法,计算所有用户模型与兴趣用户模型的相对相似度,排序后取得最相似的K个用户作为结果返回。这种方式显然不够高效,由于基站数量很大并且海量用户的CDR数据总量规模庞大,传输全部基站数据到数据中心带来巨大的通信代价,导致集中式的查询可行性不高。
(2)分布式查询:每一个基站在自己本身含有的局部数据上独立地执行相似性查询算法,数据中心收集各基站的查询结果,找出相对于兴趣用户全局模型最相似的K个用户作为结果返回。这种方式的好处在不需要提前将基站上存储的CDR数据传输到数据中心,极大地降低了数据通信代价,并且契合于本文所关注的相对相似性定义,即与兴趣用户相对相似的用户需要在兴趣用户所在的各个基站上具有相似性。然而,由于每个基站只拥有用户的局部数据,因此收集的各基站独立查询得到的结果可能导致准确度不高,“相似”的用户可能会被漏报。
无论是哪种方式,数据中心都依赖于来自分布式基站的通信消息来获取查询结果。从以上的分析中可以看出,将全部用户的CDR数据包含进通信消息的集中式查询效率很低,而在通信消息中仅包含局部查询结果的分布式查询则有可能准确度不高。因此本文提出优化的分布式查询方法,本质上需要在降低通信代价的同时保证传输的信息中包含足够构建用户全局相似性的信息,即通信消息要“少而精”。

图1 随机8个用户的各基站活跃度柱状图
对CDR数据集进行分析后观察到用户在少数基站上的活跃度主导了其总活跃度这个现象。图1展示了从所有用户中随机选取的8个用户在其各自所在的基站上的活跃度(观察周期为一周)。X轴为用户在观察周期内存在过的基站号,Y轴为用户在各基站上的总活跃度。从图1中可以发现用户在各个基站上的活跃度并不平均,在少数基站上的活跃度占据了其总活跃度的很大比重。为了进一步研究这一现象是否普遍存在于所有的用户数据中,本文对真实数据统计了每个用户最活跃的前3个基站和最活跃的前25%的基站上的活跃度在该用户总活跃度中所占的比例,并依此绘制了其互补累计积分分布图(Complementary Cumulative Distribution Function,CCDF)(图2),X轴为用户在最活跃的几个基站上的活跃度之和占该用户总活跃度的比重,Y轴为互补累计分布函数中的百分比。从图2中可以观察到,将近60%的用户在其最活跃的前3个基站上的活跃度超过了其总活跃度的80%;将近78%的用户在其最活跃的前25%个基站上的活跃度超过其总活跃度的80%。这一现象在现实生活中并不难理解,用户在某些地区(工作地点、家庭住址等)停留的时间越长,在其附近基站上留下的记录就越多,导致在这些基站上的活跃度明显高于其他基站。

图2 用户最活跃的前3个基站和前25%个基站上的活跃度占总活跃度比例的互补累计积分分布(CCDF)图
本文所提出的分布式查询方法充分利用这一特性,对兴趣用户的全局模型进行主要基站分析(Prime Cell Analysis,PCA):选择那些在用户总活跃度中占主要成分(活跃度之和占用户总活跃度的比重大于阈值θ)的基站运行局部的相对相似度计算,从而降低通信代价。同时为了体现各基站在用户Ui全局模型中的不同重要程度,本文引入基站权重φp,定义如下:

4 相对相似用户分布式查询方法
相对相似用户分布式查询方法(Relative Similar User Distributed Query,RSU-DQ)主要由4个阶段组成(见图3)。数据中心接收到要查询的兴趣用户的用户ID后:(1)向各基站收集该用户的CDR数据并建立用户全局模型;(2)对该用户全局模型运行PCA算法并计算每个基站的权重;(3)由选择出来的基站执行本地查询算法计算局部相似度;(4)各基站独自计算出来的结果传输回数据中心(传递消息以<用户ID,局部相似度>的形式),由数据中心汇聚后确定最相似的K个用户。阶段2和阶段4均发生在数据中心,阶段1和阶段3则需要分布式基站的参与。
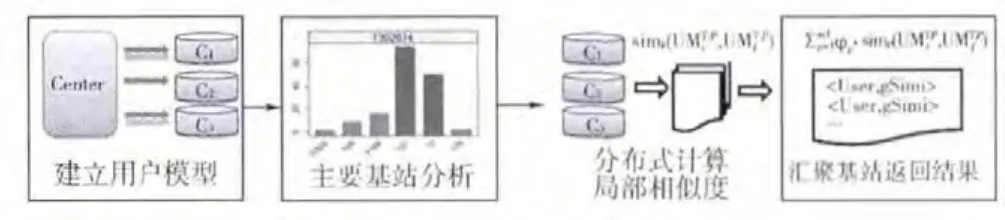
图3 相对相似性用户分布式查询方法概览
阶段1 兴趣用户建模。
对兴趣用户的建模发生在数据中心。数据中心接收到待查询的兴趣用户ID后,将ID号和建模参数(观察时间T、时间间隔Δt、建模属性集合A和各属性权重等)发送给所有基站,由存在兴趣用户CDR记录的基站进行响应,按照公式(1)独立完成相应局部模型的建立后传输回数据中心。
阶段2 主要基站分析。
数据中心收集了兴趣用户的全部局部模型之后建立用户的全局模型,并对其进行主要基站分析:按公式⑷计算各基站的权重,并以用户在各基站上的活跃度排序;选择最活跃的m个基站使得用户在这m个基站上的活跃度之和超过该用户总活跃度的阈值θ。视这m个基站为主要基站(Prime Cells,PC),由PC执行接下里的局部相似度计算。举例说明,假设兴趣用户Ui存在于3个基站{C1,C2,C3},在每个基站上的活跃度占总活跃度比重分别为{12%,70%,18%}。若θ=80%则PCA选择{C2,C3}作为主要基站;若 θ=90%,则 PCA 选择{C2,C3,C1}全部3个基站作为主要基站。
阶段3 计算局部相似度。
局部相似度的计算是分布式的,由各PC独立完成:首先遍历基站上所有的用户局部模型,按照公式(3)计算其与兴趣用户在该基站上的局部模型的局部相似度;计算完成后得到一张表,包含该基站上所有用户的用户ID及对应的相对于兴趣用户的局部相似度,将整张表传输回数据中心。
从计算过程可以看出,局部相似度计算过程的时间代价和传输代价取决于该基站上所存储的用户数量,存在于该基站的用户越多,时间代价和传输代价越大。
阶段4 汇聚基站返回结果。
在接收到主要基站的计算结果之后,数据中心对所有结果进行汇聚:对于所有局部计算结果中的每一个用户ID,按公式(2)计算其相对于兴趣用户的全局相似度;按全局相似度降序排列所有用户;取前K个用户(即相对与兴趣用户最相似的K个用户)作为查询结果作出响应。
5 实验评估
本节用真实的CDR数据集对提出的相对相似用户分布式查询方法进行评估。首先对实验进行描述,包括数据集、实验环境和比较方法;其次在准确度、时间代价和通信代价方面对本文所提出的分布式查询方法进行评估。
5.1 实验描述
(1)数据描述:实验的数据集大小为5.67 GB。从CDR数据(详细描述见2.1节)中可以提取出呼叫发起时间、基站ID和必要的用户属性用以完成用户模型的建立(见2.2节)。评估实验中使用的数据集是安徽省某城市电信运营商提供的2012年2月的全部CDR数据集,覆盖了38万用户和6万个基站。
(2)实验环境描述:一台配备三代酷睿i5处理器(主频2.5 GHz)和8 GB主存的笔记本电脑。实验使用一个独立的线程作为一个主要基站进行独立的局部相似度计算。
(3)比较方法:以集中式查询(见3.2节)作为基线方法,在准确度、时间代价和通信代价方面与本文提出的分布式查询做比较。为了进一步观察PCA阶段阈值θ对结果的影响,实验还对比了θ=80%和θ=90%的时候RUS-DQ方法的准确度和效率。
5.2 准确度和效率评估
本文从3个方面对准确度和效率进行评估:精度(Precision)、时间代价(Time Cost)和通信代价(Communication Cost)。对于准确度的衡量本文使用精度的概念,即正判率/(正判率+误判率);时间代价则为被评估的查询方法运行一次查询所用的时间;通信代价为各基站和数据中心之间所传输的通信消息的数量。
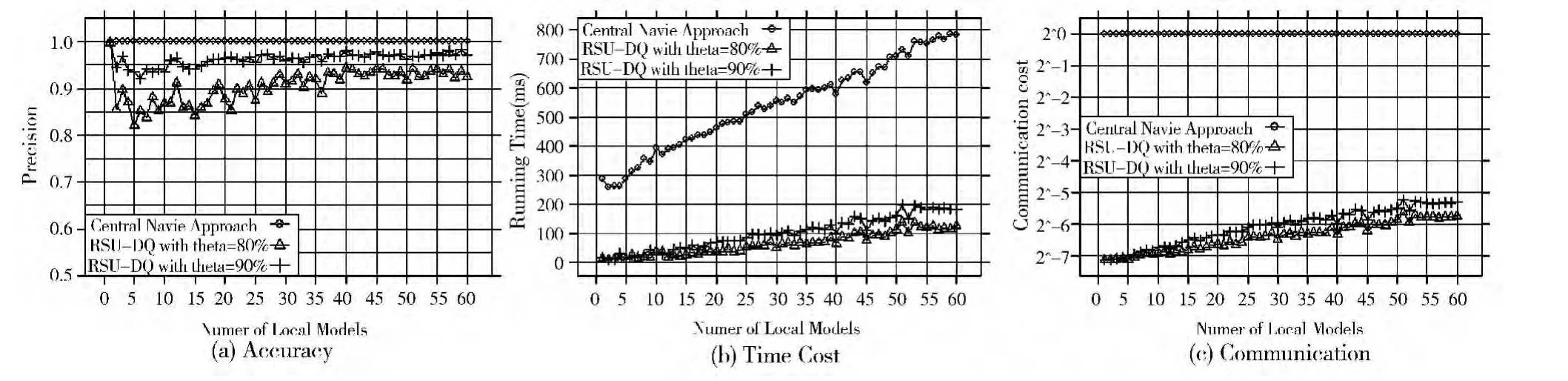
图4 准确度和效率评估
在图4中,X轴为兴趣用户Ui局部模型的个数mi。对于每一个mi(从1到60),随机选择20个局部模型个数为mi用户作为兴趣用户进行查询,取均值作为平均的准确度、时间代价和通信代价。从图4(a)中可以看出,集中式查询具有最高的准确度,因为集中式查询将所有基站上的全部数据都传输回数据中心后再进行查询算法,拥有全局用户模型。本文提出的分布式查询方法在主要基站阈值θ=80%的时候精度保持在90%左右(均值为91.6%),当θ=90%时RSU-DQ方法能够保持96%左右的准确度。准确度的提升并不难以理解,较高的阈值意味着有更多的基站被视为主要基站执行局部相似度的计算,尤其在兴趣用户的局部模型比较少的时候(少于20个),调高主基站阈值对于准确度的提升效果更加显著,然而随着更多的基站参与计算,RSU-DQ方法的总时间代价和通信代价也随之增加。图4(b)的Y轴为平均查询时间,可以观察到RSU-DQ方法明显优于集中式查询,随着兴趣用户局部模型的增加,查询时间的增长也相对平缓,当主基站阈值较高时,查询时间稍有增长但依然远远低于集中式查询。图4(c)的Y轴为通信代价(以占集中式的查询的通信代价的比例的形式),可以看出RSU-DQ方法比集中式查询的通信代价要小得多,原因在于RSU-DQ只要求与少数的主要基站进行大量数据的传输,而集中式查询需要提前将所有基站上的CDR数据搜集起来之后再进行查询。可以看出,当兴趣用户的局部模型比较少的时候,较高的主基站阈值θ引起的时间代价和通信代价的增加并不明显。
通过上述实验评估和分析可以看出,RSU-DQ方法能够达到高准确率、低时间代价和低通信代价的目标;随着兴趣用户局部模型的增加,稳定的准确度和平缓增加的时间通信代价也保证了RSU-DQ的扩展性;设置一个较高的主基站阈值θ可以进一步提高RSU-DQ的准确率。
6 结束语
本文结合对真实手机网络中的呼叫详细记录的分析,提出了基于局部呼叫数据的相似用户分布式查询问题。为了解决这一问题,本文分析了用户局部呼叫数据与全局用户数据的关系,根据分析结果,提出并实现了一种基于用户局部数据的相对相似用户分布式查询方法RSU-DQ。通过用真实数据做的一系列实验,本文展示了RSU-DQ的高准确度、低时间代价和低通信代价的特点。
在今后的工作中,将继续研究更多的应用场景,比如考虑批量查询、其他的相似度定义以及相似度定义和各基站权重之间的关系等。
[1]Candia J,Gonzalez M C,Wang P,et al.Uncovering individual and collective human dynamics from mobile phone records[J].Journal of Physics A:Mathematical and Theoretical,2008,41(22):Article 224015.
[2]Gonzalez M C,Hidalgo C A,Barabasi A L.Understanding individual human mobility patterns[J].Nature,2008,453(7196):779-782.
[3]Phithakkitnukoon S,Horanont T,Di Lorenzo G,et al.Activity-aware map:Identifying human daily activity pattern using mobile phone data[C]//Proceedings of the 2010 International Workshop on Human Behavior Understanding.Istanbul,Turkey,2010:14-25.
[4]Ficek M,Kencl L.Inter-call mobility model:A spatiotemporal refinement of call data records using a Gaussian mixture model[C]//Proceedings of the 31st Annual IEEE International Conference on Computer Communications.Orlando,USA,2012:469-477.
[5]Faloutsos C,Ranganathan M,Manolopoulos Y.Fast subsequence matching in time-series databases[C]//Proceedings of the 1994 ACM SIGMOD International Conference on Management of Data.Minneapolis,USA,1994:419-429.
[6]Ahmed R,Boutaba R.Distributed pattern matching:A key to flexible and efficient P2P search[J].IEEE Journal on Selected Areas in Communications,2007,25(1):73-83.
[7]Van Hook D J,Rak S J,Calvin J O.Approaches to RTI implementation of HLA data distribution management services[C]//Proceedings of the 15th Workshop on Standards for the Interoperability of Distributed Simulations.Orlando,USA,1996:535-544.
[8]Raczy C,Tan G,Yu J.A sort-based DDM matching algorithm for HLA[J].ACM Transactions on Modeling and Computer Simulation(TOMACS),2005,15(1):14-38.
[9]Liu S,Kang L,Chen L,et al.Distributed incomplete pattern matching via a novel weighted Bloom filter[C]//Proceedings of the 2012 IEEE 32nd International Conference on Distributed Computing Systems.Macau,China,2012:122-131.
[10]Zeinalipour-Yazti D,Lin S,Gunopulos D.Distributed spatio-temporal similarity search[C]//Proceedings of the 15th ACM International Conference on Information and Knowledge Management.Arlington,USA,2006:14-23.
[11]Li Q,Zheng Y,Xie X,et al.Mining user similarity based on location history[C]//Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems.Irvine,USA,2008:Article No.34.
[12]De Spindler A,Norrie M C,Grossniklaus M,et al.Spatiotemporal proximity as a basis for collaborative filtering in mobile environments[C]//Proceedings of the Workshop on Ubiquitous Mobile Information and Collaboration Systems(UMICS 2006).2006.
[13]Isaacman S,Becker R,Caceres R,et al.Identifying important places in people’s lives from cellular network data[C]//Proceedings of the 9th International Conference on Pervasive Computing.San Francisco,USA,2011:133-151.
[14]Heck T.A comparison of different user-similarity measures as basis for research and scientific cooperation[C]//Proceedings of the 2011 International Conference on Information Science and Social Media.2011.
