一种非对称多核SDR的任务调度和分配算法
2014-09-29史少波
徐 力,史少波
(1.宁波工程学院电子与信息工程学院,浙江 宁波 315016;2.北京科技大学计算机与通信工程学院,北京 100083)
1 概述
近年来,无线通信领域不断发展,各种通信标准层出不穷,标准的实现也变得越来越复杂。为了缩短产品上市时间,通信设备制造商还要求设备开发必须早于标准的完全确立。此外,人们还希望无线设备能支持多种不同的标准,软件无线电(Software-defined Radio, SDR)越来越受到关注。SDR采用处理器或可编程逻辑器件,通过软件更新灵活地实现各种无线通信标准。而高性能计算的需要使得多核处理器成为软件无线电平台的重要组成部分[1]。由于SDR常常用于功耗要求比较苛刻的通信设备,现在还常采用非对称多核处理来器搭建SDR[2]。
一种有效的任务调度和分配算法是多核处理器获取高性能的关键因素。而很多算法假设多核处理器基于对称体系结构,并忽略任务之间的通信时间[3]。此外,相关研究还提出了一些非对称多核处理器的任务调度和分配算法[4-5]。但这些算法面向所有应用,没有针对软件无线电的特点进行优化。本文针对非对称多核处理器和软件无线电的特点,提出基于任务固定流水和任务拆分的调度和分配算法。算法主要通过 2个步骤来实现:(1)将任务通信时间和任务固定流水引入到整数线性规划(Integer Linear Programming, ILP)方法中,然后对任务调度和分配进行建模;(2)通过任务拆分进一步优化任务调度和分配,减少流水线中处理器核最长空闲待时间,提高软件无线电平台的吞吐量和处理能力。
2 问题定义
2.1 非对称多核软件无线电平台
在软件无线电平台中,处理器主要负责通信系统中的基带数字信号处理。如图1(a)所示,基带数字信号处理根据处理目的不同可以分为3个部分:数字前端,调制解调、编解码[6]。基带数字信号处理主要包括:在接收端,把无线电前端模数转换后的数据帧解调为比特流数据发送给MAC层;在发送端,把MAC层需要发送的比特流数据调制成物理层数据帧并通过无线前端转发出去。
从当前流行的无线通信标准(如WLAN、WiMAX等)中可以看到,基带数字信号处理都是数据流占主导的过程,并具有同步数据流特征[7]。从基带数字信号处理任务模型的描述可以看到,任务模型中任务之间实际是一种线性关系,也就是说后一个任务必须在前一个任务完成之后,才可以获得输入数据开始执行。那么,基带数字信号处理的任务模型可以用图1(b)表示,其中有向连线表示任务之间的数据依赖关系,连线上的数字表示任务之间的数据传输量。由于任务之间的线性关系,因此整个任务图中只有1个入度为0的起始任务和1个出度为0的终止任务,其余任务都只有1个入度和1个出度。

图1 无线通信系统的基带处理过程
多核处理器根据体系结构的不同可以分为对称多核处理器和非对称多核处理器[3]。对称多核处理器和非对称多核处理器的主要区别在于不同处理器核的性能和处理器核之间的通信。对称多核处理器中每个处理器核的体系结构相同,同时处理器核之间可以对等通信,所以,对称多核处理器上处理器核之间一般采用总线互联结构,如图2(a)所示。而非对称多核处理器中每个处理器核具有不同的处理能力,或者处理器核之间采用非对等通信。非对称多核处理器一般采用 mesh互联结构或者 ring互联结构[8-9],如图2(b)、图2(c)所示。非对称多核处理器相比对称多核处理器来说有 2个优点:(1)非对称多核处理器采用不同处理能力和功耗的处理器核,可以达到较好的处理器性能功耗比;(2)非对称处理器一般采用mesh互联结构和 ring互联结构,而这些互联结构的转发单元硬件结构和仲裁机制相对简单,易于集成大量的处理器核来提升多核处理器的并行计算能力[4]。但这2种互联方式对于处理器核之间通信有一定的约束。以图2(b)的ring互联结构为例,假设处理器核P1向P3传输数据,那么这些数据需要通过P2上的转发单元转发才能最终发送到P3。若2个处理器核之间相隔较多的处理器核就会产生很大的跨核通信代价。所以,在本文的任务调度和分配算法中,相邻的2个任务必须分配到同一个处理器核上或者分别分配到相邻2个处理器核上,避免跨核通信产生的时间代价。
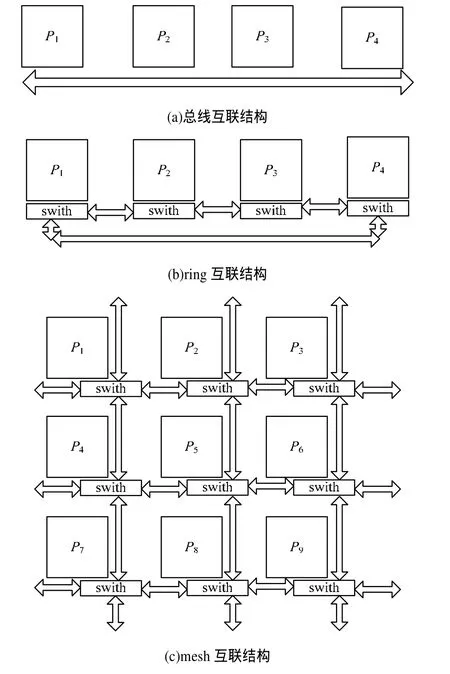
图2 不同核间互联结构
2.2 固定流水
如图3所示,这里把相继2个迭代之间的时间间隔定义为LT、1次迭代的时间定义为TP。LT和TP分别代表软件无线电平台的实时性和吞吐量指标。文献[10]提出一种基于ILP方法的任务调度和分配算法,由于没有采用任务并行流水,导致第i+1次迭代必须等到第i次迭代完成后才能开始执行,如图3(a)所示。对于软件无线电的任务模型而言,采用该算法会导致LT、TP较长,系统吞吐量较低。文献[7]把任务并行流水带入ILP方法中,如图3(b)所示。根据文献[11]得到的任务调度和分配,其每次迭代后LT和TP并不相同,是动态改变的。如果整个处理中待处理数据个数确定,则该算法具有较好的调度结果。然而,软件无线电中待处理数据个数并不确定,将文献[11]的算法应用于软件无线电中可能会增加硬件任务调度器,来实时调整任务调度和分配[12]。此外,该算法主要面向对称多核处理器的任务调度和分配,并不适应于非对称多核处理器。为了不增加硬件负担,同时又能通过任务并行流水来提高非对称多核软件无线电平台的实时性和吞吐量,本文提出固定流水的方法。如图3(c)所示,固定流水保证每次迭代中LT和TP不变。固定流水对1次迭代进行任务调度和分配,就能得到整个迭代过程的任务调度和分配,算法时间复杂度大大降低。同时根据2.1节所述,算法采用固定流水时,还必须保证相邻的任务分配在同一个处理器核上或者分别分配到相邻2个处理器核上,来避免跨核通信代价。
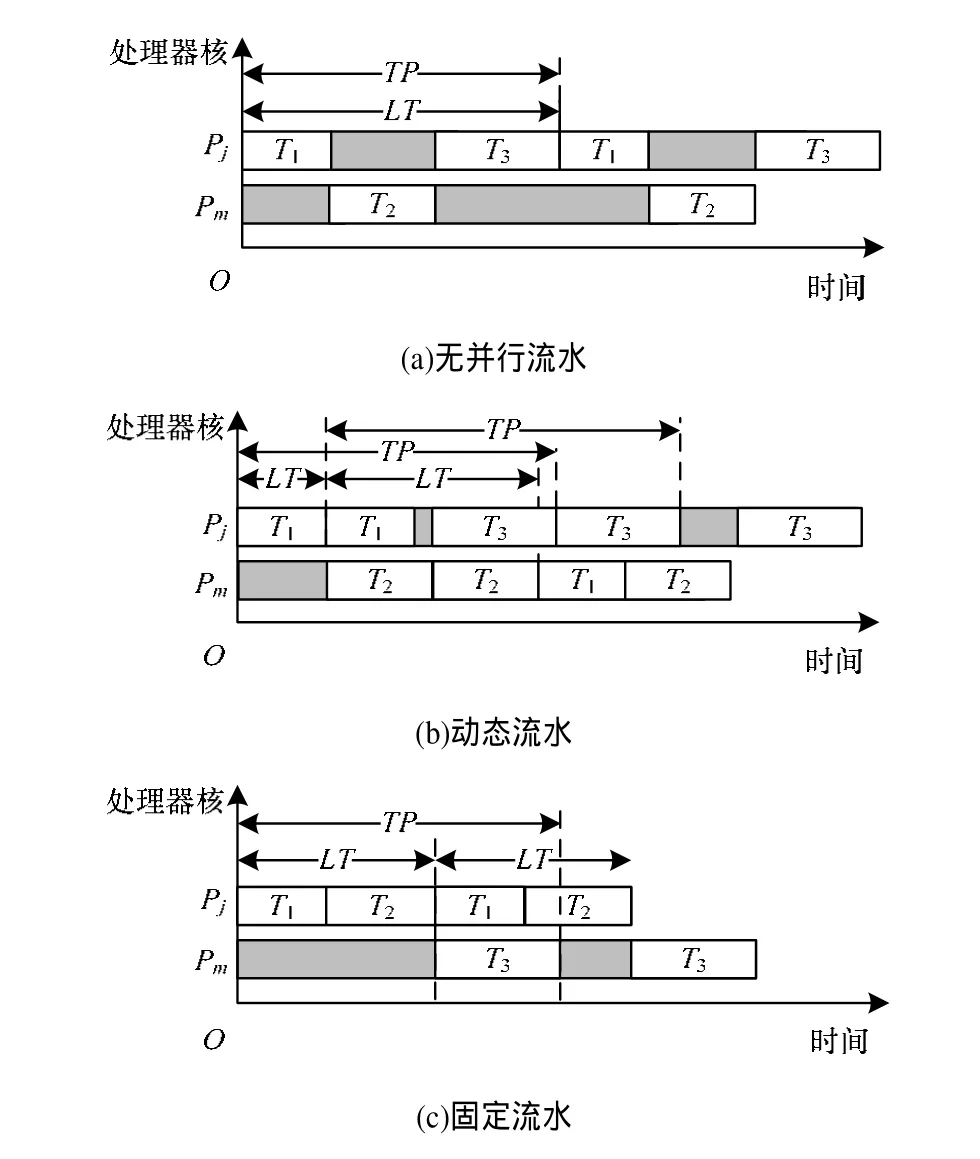
图3 多核处理器上任务的执行
2.3 通信时间
任务之间数据传输产生的通信时间主要包括任务在处理器核内的通信时间和任务在处理器核之间的通信时间。如图4所示,假设任务T1、T2分配到处理器核P1上,T3分配到处理器核P2上。那么,由于任务分配的不同,因此T1和T2在P1内数据传输产生通信时间tc1,T2和T3在P1和P2之间数据传输产生通信时间tb1。

图4 处理器核的执行过程
在图 4中,OET表示处理器核的整体执行时间,并由1个迭代中任务执行时间、任务在处理器核内的通信时间总和以及任务在处理器核之间的通信时间构成。任务在非对称多核处理器中的通信时间有 3个主要特点:(1)任务之间的数据传输量对通信时间有重要影响;(2)非对称多核处理器中每个处理器核的存储器结构有可能不同,就会导致每个处理器核内单位数据传输产生的通信时间不同;(3)从现有用于软件无线电平台的多核处理器可以看到,处理器核之间一般通过总线或者共享存储器进行互联,所以,假设任务在处理器核之间单位数据传输产生的通信时间是一个定值。
3 任务调度和分配算法
3.1 任务及多核处理器体系结构的定义
在此引入文献[13]ILP方法中的batch概念。基于batch的ILP方法首先把多个任务分配到一个batch中,然后再将batch调度到处理器核上,以此完成任务调度和分配。同时假设每个任务同一时刻只能在1个处理器核上执行,每个处理器核能执行所有的任务。此外,定义任务个数为n,处理器核数目为m,现在汇总ILP中一系列的定义。
任务集定义为:

其中,T1、Tn分别是起始任务和终止任务;其他任务Ti{1 <i<n}只和前后2个任务Ti-1、Ti+1有互联通信关系。
同样地,把非对称多核处理器中的处理器核集合定义为:

batch集合定义为:
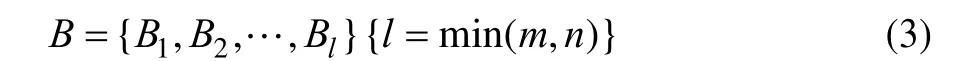
每个任务在各个处理器核上的执行时间定义为:
1.新民主主义革命时期与党的群众史观。以毛泽东为核心的中共第一代中央领导集体在领导中国人民进行新民主主义革命的伟大实践中,把马克思主义群众史观同中国革命的具体实践相结合,提出了“全心全意为人民服务”“一切从人民的利益出发”“向人民负责”等一系列群众思想,并在实践中通过对中国道路的有益探索,最终创立了符合中国实际的群众观点和以此为基础的群众路线。毛泽东则成为中国共产党群众史观的首创人和践行者。
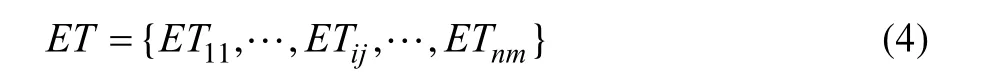
其中,ETij表示第i个任务在第 j个处理器核上的执行时间。
任务之间的数据传输量定义为:

其中,Di{1≤i<n}表示Ti和Ti+1之间的数据传输量;Dn表示终止任务和共享存储器之间的数据传输量。
每个处理器核内单位数据传输产生的通信时间定义为:

任务在处理器核之间单位数据传输产生的通信时间定义为:MPC。
1次迭代中每个处理器核的整体执行时间定义为:

3.2 ILP方程
ILP方程中的变量为:

任务调度和分配的目标是保证系统实时性和吞吐量,目标函数由下面公式所示。
ILP方程的目标函数为:

其中,k1、k2的值可由用户自己设定,表示软件无线电平台实时性和吞吐量之间的权衡。
ILP方程的约束条件具体如下:
(1)每个任务必须分配到 1个 batch上且只能分配到1个batch上:

(2)每个batch必须分配到1个处理器核上且只能分配到1个处理器核上:

(3)由于固定流水的需要,因此相邻任务分配在同一个处理器核上或者分别分配到相邻 2个处理器核上。那么,分配到batch上的任务必须是单个任务或者是1组顺序的任务:

(4)同样由于固定流水的原因,因此相邻2个batch必须分配到相邻2个处理器核上:

(5)单个处理器核内任务之间的通信时间为:
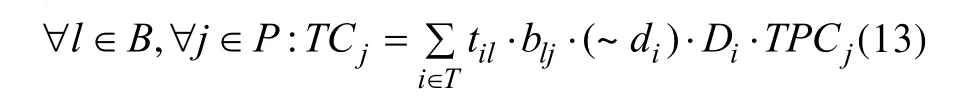
(6)任务在处理器核之间的通信时间可以表示为:

(7)每个处理器核的整体执行时间可以表示为:

(8)LT取决于整体执行时间最长的处理器核:

(9)TP取决于已分配任务的处理器核数目和分配到终止任务的处理器核:
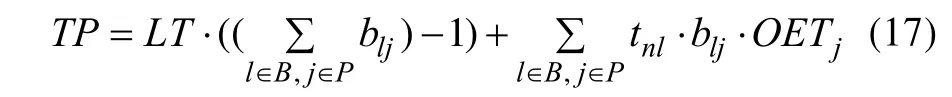
3.3 任务拆分
对软件无线电任务模型求解ILP方程,可以得到任务调度和分配的初步结果。初步结果中每个处理器核的整体执行时间并不相同,而LT取决于整体执行时间最长的处理器核,使得任务调度和分配后出现一些处理器核长时间空闲等待的状况。如图5(a)所示,经过初步任务调度和分配,P2在每次迭代时需要等待一段时间才能继续执行,这样就不能实现系统的高吞吐量和多核处理器的高性能计算能力。本文根据软件无线电的特点,通过任务拆分优化任务调度和分配,进一步提高系统的吞吐量,实现处理器的高性能计算能力。如图 5(b)所示,将T2拆分为2个任务并分别分配到P1和P2中,来优化图5(a)的任务调度和分配。

图5 任务拆分示例
任务拆分主要针对2种任务类型:一种是任务带有内部自循环体,可以把循环体拆分后再分配,具体如下:原始任务为:

4 实例分析
4.1 目标软件无线电平台和测试实例
目标 SDR所用的非对称多核处理器如图 6所示,2个处理器核P1和P2通过ring互联结构相互连接,所有处理器核都运行在400 MHz工作频率下。每个处理器核内部拥有一定数目的寄存器组和私有存储器。各个处理器核的私有存储器体系结构一样,所以,式(6)中TPC为定值。处理器核之间采用共享存储器进行数据传输,同时通过控制总线进行任务调度。P1和P2由于内部计算单元数目不同,拥有不同的计算能力。非对称多核处理器中TPC为1个周期,MPC为2周期。
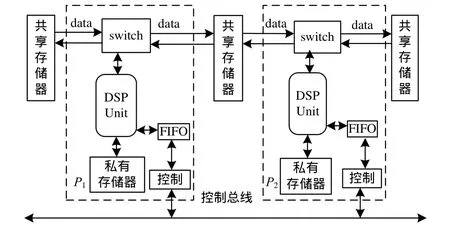
图6 多核处理器体系结构
测试实例为IEEE 802.11a接收端频偏处理,其任务图如图 7所示,包括小数倍频偏估计、小数倍频偏补偿、64点快速傅里叶变换(Fast Fourier Transformation, FFT)和整数倍频偏估计4个任务。任务之间的数据传输量以及任务在P1、P2上的执行时间如表1所示,其中,通信量的单位为1个32 bit数据;执行时间的单位是1个周期。

图7 IEEE 802.11a频偏估计处理的任务图

表1 任务之间的数据传输量以及任务在处理器核上执行时间
4.2 算法测试
本文将ILP方程中目标函数中的参数K1、K2都设为1,并对10000组数据进行频偏估计处理得到多核处理器中处理器核的平均利用率。
通过Matlab工具对ILP方程进行求解可以得到任务调度和分配的第1步结果。其中,T1、T2分配到P1上执行,而T3、T4分配到P2上执行,调度后每个处理器核的OET如表2中第2列所示。可以看到,第1步任务调度和分配后LT为7108周期、TP为12823周期,处理器核最长空闲等待时间为1393周期,而多核处理器中处理器核平均利用率约为90.20%。在第2步中,对T3进行拆分和再分配,实现任务调度和分配的进一步优化。T3为64点FFT,这里采用6阶基2蝶形运算实现。根据T3的算法实现特点把它拆分成前后3阶基2蝶形运算,并将前3阶基2蝶形运算分配到P1,后3阶基2蝶形运算分配到P2。经第2步再分配后,每个处理器核的OET如表2中第3列所示。其中,LT变成6486周期、TP为12057周期,处理器核最长空闲等待时间为915周期,处理器核平均利用率约为92.94%。

表2 算法每一步的任务调度和分配结果 周期
4.3 验证和分析
测试结果表明,本文提出的ILP方程可以有效地用以非对称异构SDR任务调度和分配的建模。而经过第2步的优化,系统吞吐量和处理器核平均利用率分别提高了5.97%和 3.03%,处理器核最长空闲等待时间减少了34.31%,具有较好的优化效果。相对于文献[10]本文引入固定流水和任务拆分,优化了任务调度和分配后系统的吞吐量和处理器核利用率。而与文献[11]相比,不需要增加硬件任务调度器,实现任务调度和分配,减少了系统的硬件负担,提高了任务调度的灵活性和可适应性。
5 结束语
本文提出一种非对称多核软件无线电平台的任务调度和分配算法。算法根据软件无线电和非对称多核处理器的特点,在考虑任务之间通信时间和任务并行流水的前提下,通过ILP方法对任务调度和分配进行建模,并采用任务拆分优化建模结果。在目标软件无线电平台上实现IEEE 802.11a频偏估计处理的任务调度和分配。实验结果表明,该算法能提高软件无线电平台吞吐量、处理器核平均利用率,并减少处理器核的最长空闲等待时间。下一步工作将研究如何细化任务模型,改进并行流水方式,使算法更具普适性和高效性。
[1]阎 毅.软件无线电与认知无线电概论[M].北京: 电子工业出版社, 2012.
[2]Blake G, Deslinski R G, Mudge T.A Survey of Multicore Processors: A Review of Their Common Attributes[J].IEEE Signal Processing Magazine, 2009, 26(6): 26-37.
[3]Wu A S, Yu Han, Jin Shiyuan, et al.An Incremental Genetic Algorithm Approach to Multiprocessor Scheduling[J].IEEE Transactions on Parallel and Distributed Systems, 2004, 15(9):824-834.
[4]Topcuoglu H, Hariri S, Wu Minyou.Performance-effective and Low-complexity Task Scheduling for Heterogeneous Computing[J].IEEE Transactions on Parallel and Distributed Systems, 2002, 13(3): 260-274.
[5]Radulescu A,.Fast and Effective Task Scheduling in Heterogeneous Systems[C]//Proceedings of the 9th Heterogeneous Computing Workshop.Cancun, Mexico: [s.n.], 2000.
[6]施汝杰, 高佩君, 田佳音, 等.ZigBee网络节点基带处理器的设计与实现[J].计算机工程, 2008, 34(17): 219-221.
[7]Lee E, Messerschmitt D.Static Scheduling of Synchronous Data Flow Programs for Digital Signal Processing[J].IEEE Transactions on Computers, 1987, 32(1): 24-35.
[8]Tran A, Truong D, Baas B.A Reconfigurable Sourcesynchronous On-chip Network for GALS Many-core Platforms[J].IEEE Transactions on Computer-aided Design of Integrated Circuits and Systems, 2010, 29(6): 897-910.
[9]Bell S, Edwards B, Amann J, et al.TILE64-processor: A 64-core SoC with Mesh Interconnect[C]//Proceedings of IEEE International Solid-state Circuits Conference.San Francisco,USA: [s.n.], 2008.
[10]Bender A.Design of an Optimal Loosely Coupled Heterogeneous Multiprocessor System[C]//Proceedings of European Design and Test Conference.Paris, France: [s.n.], 1996.
[11]Yi Ying, Han Wei, Zhao Xin.An ILP Formulation for Task Mapping and Scheduling on Multi-core Architectures[C]//Proceedings of Design, Automation & Test in Europe Conference & Exhibition.Nice, France: [s.n.], 2009.
[12]Limberg T, Winter M, Bimberg M, et al.A Heterogeneous MPSoC with Hardware Supported Dynamic Task Scheduling for Software Defined Radio[C]//Proceedings of the Design Automation Conference.San Francisco, USA: [s.n.], 2009.
[13]Ostler C, Chatha K.An ILP Formulation for System-level Application Mapping on Network Processor Architectures[C]//Proceedings of Design, Automation & Test in Europe Conference & Exhibition.Nice, France: [s.n.], 2007.
