基于Term-Query-URL异构信息网络的查询推荐*
2014-09-18刘钰峰李仁发
刘钰峰 ,李仁发
(1.湖南大学 信息科学与工程学院,湖南 长沙 410082; 2.湖南大学 嵌入式系统与网络实验室,湖南 长沙 410082)
当前,搜索引擎主要基于关键词匹配的方法进行检索,然而,用户输入的查询难以准确完整的表达用户的检索意图.因此,如何理解用户真正的信息需求成为信息检索系统重要的任务之一.当用户提交查询关键字时,搜索引擎推荐一系列与原始查询相关的查询供用户选择,这一技术称为查询推荐.由于它能帮助用户修正初始查询更好的表达查询需求而被众多的商业搜索引擎所采用.
日志信息中包含了用户的查询和点击行为,根据点击信息(click-through data)构造查询(Query)和URL之间的二部图是查询推荐中的主要模型之一[1-3].在此基础上,文献[1]采用随机游走模型分析查询词之间的平均首达时间(hitting time)进行查询推荐.文献[2]在Query-URL二部图的基础上整合了用户在查询过程中返回的Top N地址信息,从而优化稀疏查询的推荐性能.另一方面,通过分析用户在查询过程中的序列行为构造Query-Flow图也得到了广泛的研究,通常使用在同一个查询任务中Query和Query之间的文本关系、session特征以及时间相关等信息构造Query之间的转移概率,从而得到Query-Flow图[4].文献[5]采用了短随机游走(short random walk)对Query-Flow图进行分析,得出了在没有使用点击记录的情况下也可以获得较好的推荐效果.文献[6]对比分析了基于Query-URL二部图和基于Query-Flow图的查询推荐方法,认为基于Query-Flow图的查询推荐方法效果更好.基于日志信息的方法虽然得到了广泛的应用,但是存在着以下问题:一是用户提交给搜索引擎的查询满足长尾分布(long-tailed distributions),基于日志的查询推荐在处理高频查询取得了不错的效果,但是面对大量的稀疏查询,由于日志记录缺乏相应的信息进行训练,因此难以取得较好的效果[7].二是日志分析的本质是利用群体智慧进行协同推荐,但是无法分析查询中的语义信息.
基于以上原因,研究者考虑通过分析查询的语义概念进行查询推荐.例如:文献[7-8]等通过分析用户点击的摘要片段构造概率语言模型进行查询推荐.文献[9]使用维基百科来构造查询之间的语义关系.文献[10]使用大规模的链接文本作为语义分析的数据源.文献[11]把查询记录按照语义概念进行聚类,然后从聚类结果中选择用户浏览次数最多的Query作为类别的代表进行查询推荐.文献 [12]根据多种语义特征构造了基于主题的词汇转移矩阵进行查询推荐,取得了较好的效果.文献[13]提出了一种基于词项-查询图(term-query graph)的概率混合模型,该模型能够准确地发掘出用户的查询意图.基于语义的查询推荐的主要问题包括[14]:一是如何挑选合适的词汇进行查询推荐,仅仅按照与原始查询的相关性选择词汇可能会导致冗余性问题.二是如何将挑选的词汇自动构造成合适的查询.
由于基于日志分析和基于语义分析的方法各有优缺点,本文通过构造统一的模型同时分析日志信息及语义信息构造Term-Query-URL异构信息网络,采用基于查询的重启动随机游走进行查询推荐.相比现有的方法,本文具有以下优势:1)从全局的角度进行查询推荐,在一个统一的模型中同时使用日志信息和语义信息进行查询推荐.2)借助于点击日志进行协同推荐,在高频查询上能取得很好的效果,采用基于文档的方法训练词汇和查询词之间的语义关系,可以提高稀疏查询的推荐效果.3)基于日志的方法无法对没有在查询日志中出现过的查询进行推荐,在本文提出的方法中,只需构造合适的查询向量,无需修改推荐算法即可从历史查询中选择合适的查询进行查询推荐,同时避免了挑选词汇构造合适的查询的问题.在大规模商业搜索引擎查询日志上的实验表明本文方法优于现有的查询推荐方法.
1 基于Term-Query-URL异构信息网络的查询推荐标题
本节首先介绍如何根据文档摘要内容、查询序列行为以及点击信息构造Term-Query-URL异构信息网络,然后介绍使用重启动随机游走模型在该网络上进行查询推荐的方法.
1.1 Term-Query二部图模型
使用在查询上点击的文档摘要片段训练词汇和查询之间的二部图,该图示例请参见图1.基于Term-Query的二部图可以表示为三元组GTQ=(T,Q,ETQ),其中T表示为由词汇组成的非空顶点集,Q表示由查询构成的非空顶点集,ETQ为连接词汇和查询的边的集合,即E⊆T×Q,在词汇和词汇之间,查询和查询之间没有边.设w:T×Q→R+表示权重函数,w(i,j)表示词汇ti和查询qj之间关联的概率,如果两者之间没有关联则wTQ(i,j)=0.
可以采用伪反馈文档来训练得到wTQ(i,j),但是这就必须依赖于伪反馈文档的质量.通常认为,用户点击的上下文摘要片段和查询词之间存在着更为紧密的关系,因此本文采用查询词和点击的文档摘要片段之间的关系来得到wTQ(i,j).假设用户发出查询q时,点击的文档摘要的集合为sq,系统日志中总的摘要集合为S={s1,s2,…,sk},则令:
(1)
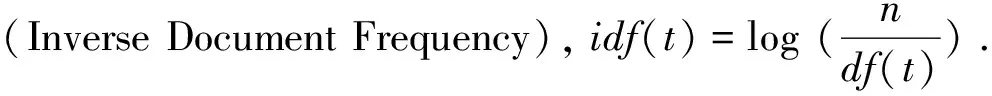
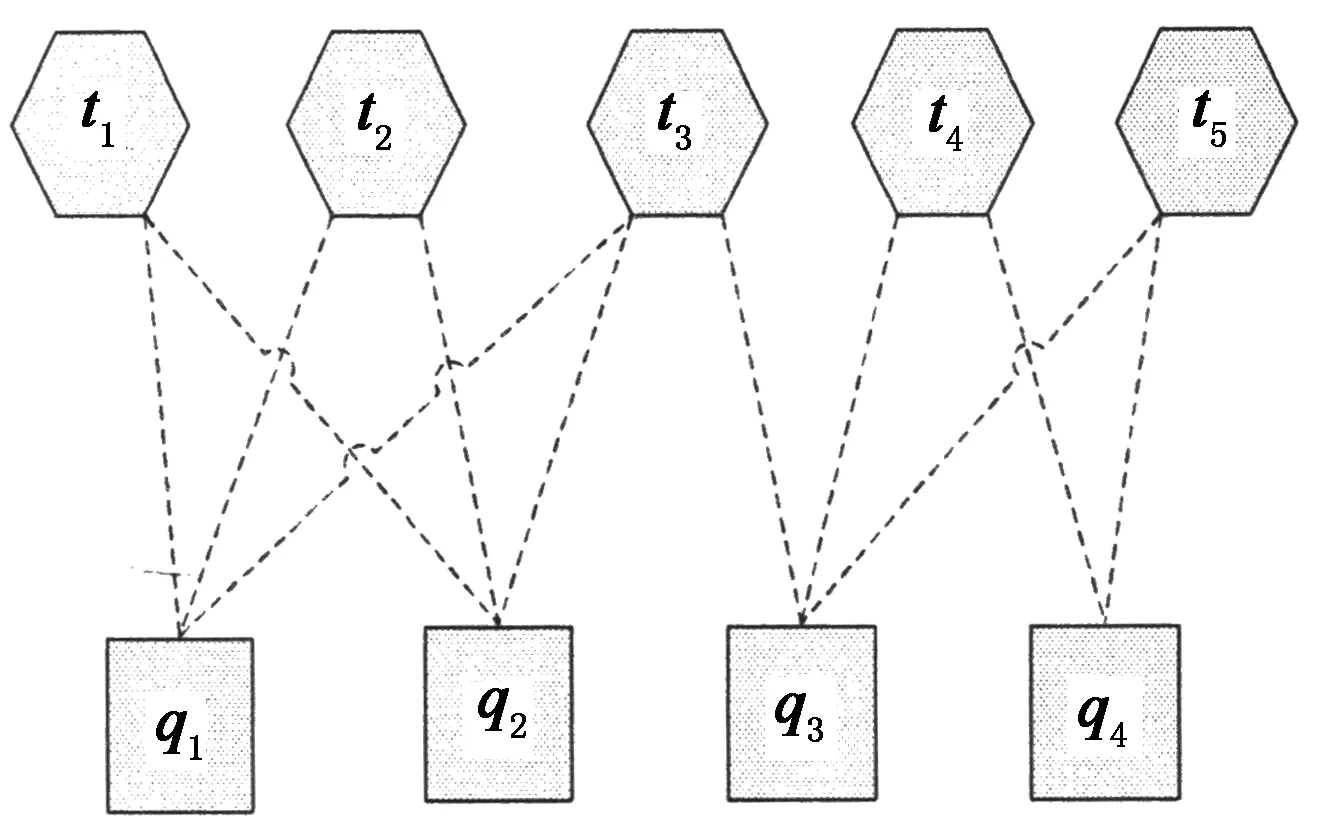
图1 Term-Query二部图
1.2 Query-Flow图模型
Query-Flow图是一种用来描述查询序列行为的有向图[4],它的基本思想是当查询qi和查询qj属于同一个查询任务时,它们之间应该存在一条有向边.Query-Flow图的示例请参见图2.Query-Flow图可以定义为GQQ=(Q,EQQ),其中Q表示由查询构成的非空顶点集,E为连接查询和查询的边的集合,EQQ⊆Q×Q.设wQQ:Q×Q→R+表示权重函数,wQQ(i,j)表示查询qi和查询qj之间关联的概率,如果两者之间没有关联则wQQ(i,j)=0.
(2)
psession(qj|qi)描述了从查询qi到查询qj的转移概率.在构造Query-Flow图时,通常使用会话(Session)的概念来判断两个查询是否属于同一个任务, 可以基于时间阈值或语义概率来判断同一个用户发出的连续的查询是否属于同一个Session[15].f(qi,qj)表示同一个查询任务中,查询qj跟随查询qi出现的次数,其中f(qi)=∑qk∈Qf(qi,qk)用于对w(i,j)进行规范化.可以观察到查询qi和查询qj之间的转移概率并不对称,因此Query-Flow图是一个有向图.如果按照文献[5]中的方法估计查询之间的转移概率,则可以构造无向的Query-Flow图.
1.3 Term-Query-URL异构信息网络模型

图3 Query-URL二部图
我们把以上讨论的三种关系统一到一个模型中进行分析,考虑包含Term,Query,URL3种不同节点的异构信息网络图GTQU={V,E},其中V=T∪Q∪U,E=ETQ∪EQQ∪EQU.以A来表示GTQ的邻接矩阵,使用B表示GQU的邻接矩阵,使用C表示GQQ的邻接矩阵,则GTQU的邻接矩阵如下所示:
(3)
为了在该图上使用随机游走模型,对W的列向量进行规范化:
(4)
式(3)中的α,β和γ为系数,α∈[0,1],β∈[0,1],γ∈[0,1]且α+β+γ=1.如果当前处在Q中的节点,α表示跳转到T中节点的概率,β表示跳转到U中节点的概率,γ表示使用Query-Flow图跳转到查询节点的概率.当α=γ=0,则本文模型退化为只使用Query-URL的点击模型,如果β=γ=0,则退化为只使用Term-Query模型的二部图,如果α=β=0则退化为只使用Query-Flow模型.
1.4 基于Term-Query-URL异构信息网络的查询推荐
当用户发出查询q,查询推荐的目标是在Q中寻找最为相似的查询进行推荐.我们使用重启动随机游走模型进行查询推荐,首先讨论当q∈Q的情况下的查询推荐.我们可以构造向量q:
q=[qt,qq,qu]T
(5)
如果q是GTQU中对应的第i个元素,令qi=1,其他对应的值都为0,很显然,此时qt和qu都是零向量.在给定了初始的查询向量的情况下,在GTQU上的重启动随机游走过程可以描述为:从GTQU上的节点q出发,它按照概率λ选择重新从节点q出发,或者按照概率1-λ选择访问q的邻居节点并开始新一轮的随机游走,不断地重复以上行为,直到在某一时刻停留在任意节点的概率保持稳定.该过程可以描述为:
p=(1-λ)Mp+λq
(6)
不断地迭代计算式(6),p将会达到一个稳定的状态,p中pq的值可以作为衡量与初始查询相关度的标准,排名靠前的查询节点用来作为q的查询推荐.
进一步分析本文中的模型,可以发现,q的邻居节点有3种:Term节点、URL节点以及Query节点.因此,在随机游走的过程中,它按照(1-λ)α的概率选择Term节点,按照(1-λ)β的概率选择URL节点,按照(1-λ)γ的概率选择Query节点,式(6)可以进一步转化为(7),从而减少计算过程中的计算量.
pt=(1-λ)αApq+λqt
pq=(1-λ)(αATpt+βBpu+γCpq)+λqq
pu=(1-λ)βBTpq+γqu
(7)
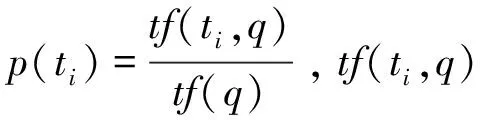
(8)

E步:
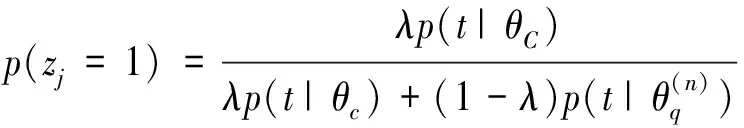
(9)
M步:
(10)
其中的zj为引入隐含变量:
(11)
综合以上描述,给出Term-Query-URL异构信息网络上的查询推荐算法如下.
算法1:基于Term-Query-URL异构信息网络的查询推荐算法.
输入:Term-Query-URL异构信息网络GTQU上的矩阵M及原始查询q.
输出:与原始查询q相关的查询推荐序列.
1)检查q是否在查询集合Q中出现,q∈Q则跳转至2,否则跳转至3.

3)根据式(8)计算q中词汇在qt中的权重,令qu和qq为零向量,由(5)式得到初始向量q,跳转至4).
4)根据式(7)迭代计算p至稳定状态.
5)取p中的pq排名靠前的查询作为推荐的查询序列输出.
步骤4中使用两个向量之间夹角的余弦小于给定的阈值作为判断迭代是否达到稳定状态的条件.在算法1中第4步是最为耗时的操作,其时间复杂度为O(n2).在实际应用中,GTQU图中的节点非常多,算法1难以直接用于数据规模较大的应用,但在GTQU图中大部分的节点与原始查询没有关系,因此,我们可以从原始查询节点出发,采用深度遍历的办法抽取GTQU的子网按照算法1进行迭代计算.
2 实验与分析
2.1 数据集
我们采用的原始数据集是来自搜狗搜索引擎2008年6月份网页查询日志数据集合,该数据中共包含51,537,393条日志记录,5,736,696个不同的查询,15,951,082个不同的URL.我们把日志记录中出现次数大于20次的查询称为频繁查询,共238,761个,平均每个频繁查询查询141.4次点击,小于20次的查询称为稀疏查询,共5,497,935个,平均每个稀疏查询点击3.2次.对于Session的定义,我们采用了简单的方法,使用时间阈值30 min作为判断两个查询是否属于同一个任务的判断标准[16],经处理后得到374,468个Session.
2.2 实验设计及结果分析
使用的topN的精度P@N和MAP(Mean Average Precision)作为评价指标,给定了一个查询q,系统给出j个推荐的查询.
(12)
(13)
其中K是查询测试集的总数,在我们的实验中K=200,N=5.在文献[2]中MAP被定义为所有查询的AvgP的平均值,其中:
(14)
RQ为推荐查询中与原始查询相关查询的总数.φ(j)是一个指示函数,如果推荐的第j个查询与原始查询相关,则取1,否则为0.
从频繁查询和稀疏查询中分别抽取了200个查询作为测试集,然后由人工进行判断产生的查询推荐是否相关.我们使用Query-URL二部图作为对比测试的基准模型(Baseline),此时对应的参数设置为α=0,β=1,γ=0,文献[1]在此基础上使用随机游走模型进行查询推荐.文献[2]在Query-URL图的基础上整合了系统返回的TopN地址信息,本文称为RW-Pseudo.当α=0,β=0,γ=1时,本文模型退化为Query-Flow图,正是文献[3-4]中使用的模型.文献[17]中给出了在没有日志信息的情况下从文档中抽取与原始查询相关的短语作为查询词进行推荐,本文称为Probabilistic方法,在本文中仅抽取包含查询词的句子进行训练.文献[13]使用概率混合模型来挖掘词项查询图中的查询意图,并使用个性化随机游走来预测单词在查询中的重要程序对查询进行推荐,该方法在实验中我们称为基于意图的方法.本章方法采用的参数设置为α=0.2,β=0.4,γ=0.4,由于GTQU图中大部分节点和原始查询无关,对推荐的性能影响不大,因此我们设置预定义的节点数为500,然后从原始查询节点出发采用深度遍历的办法抽取GTQU的子网,子网节点数大于500时深度遍历终止,然后使用在抽取的子网上按照算法1进行迭代计算.
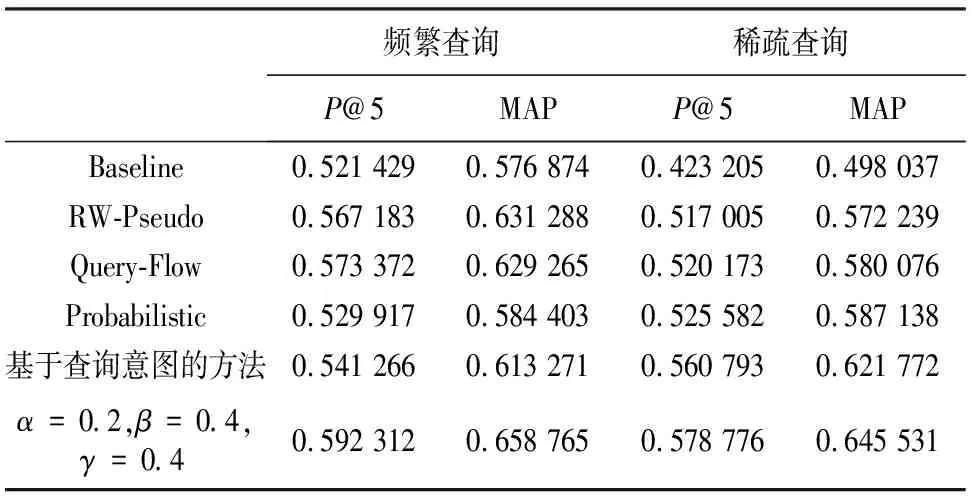
表1 6种算法在P@5和MAP上的性能比较
为了考察不同算法在不同P@N上的变化,我们分别使用Baseline、基于查询意图以及本文方法在P@1,P@3,P@5,P@5上对频繁查询和稀疏查询进行测试.图4为频繁查询上的测试结果,可以看到本文算法优于Baseline、基于查询意图的方法.图5为稀疏查询上的测试结果,可以看到只有基于查询意图的方法和本文方法性能大致一致,这是由于基于查询意图的方法通过概率模型来挖掘词项查询图,可以在不考虑其他查询的情况下提升查询推荐的性能,这与本文在稀疏查询上的方法有异曲同工之处.
本文采用的是重启动随机游走算法,式(6)中的参数λ表示重启动的概率.对于未在查询日志中出现过的查询,由于无法在Query中找到对应的节点,使用日志信息的方法无法进行处理[14].我们通过分析原始的查询记录,构造了在数据集中没有出现过的查询,其中部分推荐结果示例如表2所示.
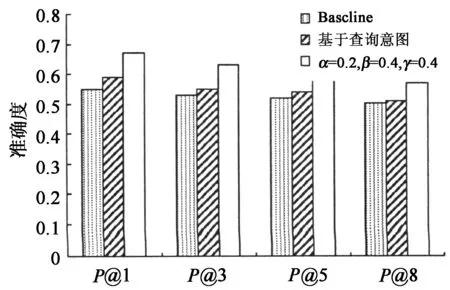
图4 不同算法在频繁查询上的P@N比较
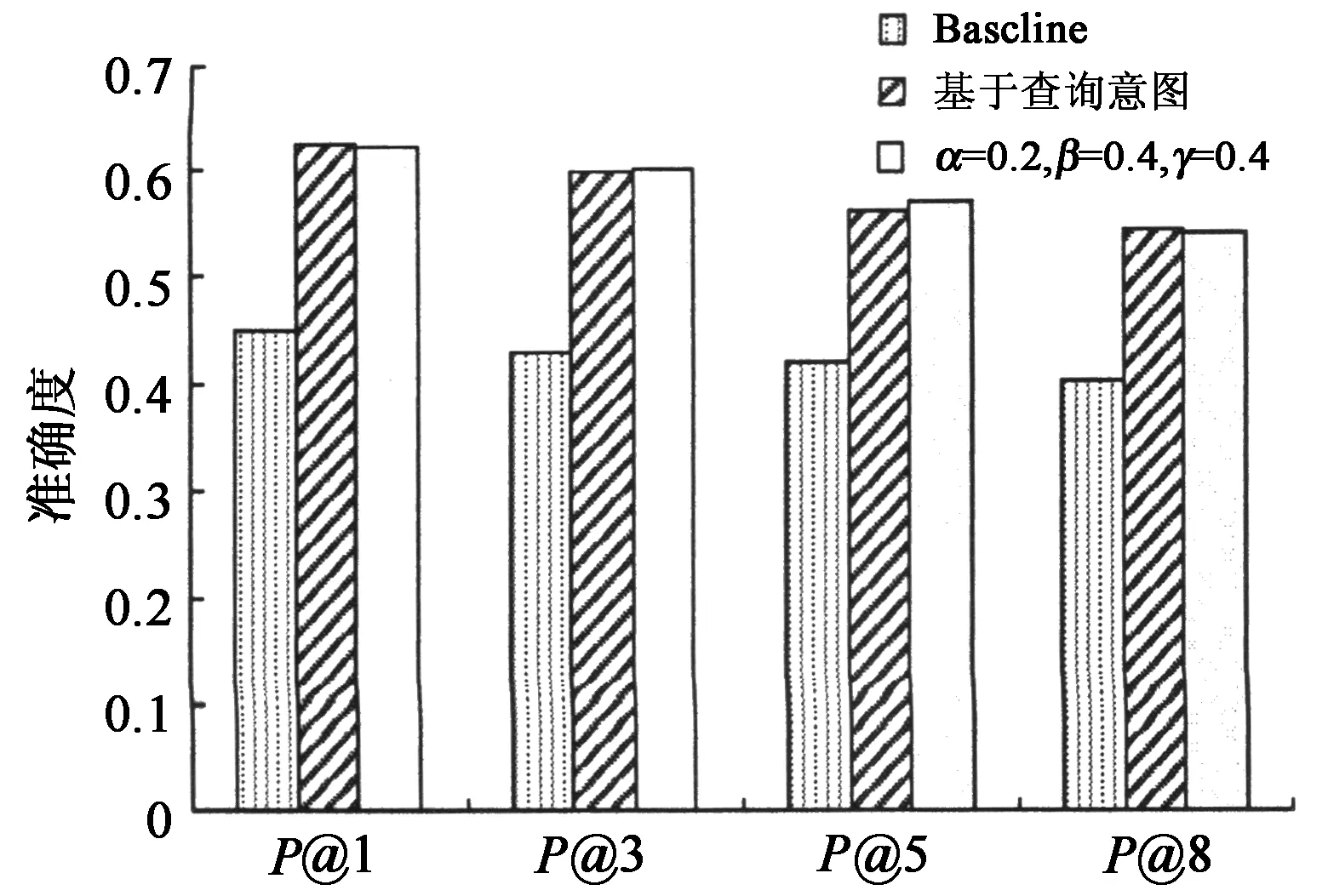
图5 不同算法在稀疏查询上的P@N比较
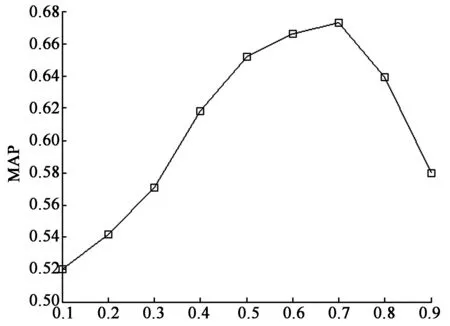
从表2中可见,本文算法在相关性上取得了较好的效果.由于本文的数据集采用的是2008年6月的数据,在推荐的查询中反映了当时的一些热点信息,例如汶川地震以及范尼离开曼联等.另一方面,由于算法关注的是推荐查询与原查询之间的相关性,但并没有考虑推荐查询之间的冗余性,导致推荐了一些重复的查询,例如:“为什么曼联不留范尼”和“曼联不留范尼”,该问题也是当前查询推荐算法共同面临的问题之一.Term-Query-URL异构信息网络上不同的重启动概率λ对MAP的影响.当λ趋近于0时,系统是从全局的范围选择最为重要的查询节点进行推荐,从而忽略了推荐查询和当前查询的相关性.而当λ趋近于1时,与原始查询路径最短的节点在推荐中就起到了关键性的重要,在局部查询节点与原始查询相关性不高的情况下,推荐性能就会急剧的下降.因此,λ的取值需要在全局和局部之间取得平衡,它的取值通常和图的结构及数据特点有一定的关系,由图6中可知在本文中λ=0.7时性能最优.

表2 查询推荐示例
λ
3 结束语
本文针对当前基于日志分析和基于语义分析进行查询推荐方法的不足展开研究,提出一种综合利用日志信息和语义信息的Term-Query-URL异构信息网络模型,使用该模型可以有效的提升检索系统在稀疏查询上的推荐性能.同时,针对没有在查询日志中出现过的查询,采用概率语言模型衡量词汇在原始查询中的重要程度,把原始查询转化为合适的词汇向量,从而提出了一种能直接使用本模型的进行查询推荐的方法.
当前的查询推荐系统通常只考虑推荐的查询与原始查询的相关性,往往忽略了查询推荐结果的冗余性[18].要进一步提升查询推荐系统的性能,需要回答以下关键问题:原始查询是否含义明确?如果原始查询含义模糊,那么与之相关的语义概念有几个?如何为每个不同的语义概念进行查询推荐?文献[19]在这些方面进行了初步的尝试,这也是我们下一步工作的重点.
[1]MEI Q,ZHOU D,CHURCH K.Query suggestion using hitting time[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management.ACM,2008: 469-478.
[2]SONG Y,HE L.Optimal rare query suggestion with implicit user feedback[C]//Proceedings of the 19th International Conference on World Wide Web.ACM,2010: 901-910.
[3]MA H,YANG H,KING I,etal.Learning latent semantic relations from clickthrough data for query suggestion[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management.ACM,2008: 709-718.
[4]BOLDI P,BONCHI F,CASTILLO C,etal.The query-flow graph: model and applications[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management.ACM,2008: 609-618.
[5]BOLDI P,BONCHI F,CASTILLO C,etal.From dango to japanese cakes: query reformulation models and patterns[C]//Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology-Volume 01.IEEE Computer Society,2009: 183-190.
[6]KATO M P,SAKAI T,TANAKA K.Query session data vs clickthrough data as query suggestion resources[J]//Advances in Information Retrieval:33rd European Conference on IR Resarch. ECIR 2011,2011:116-122.
[7]LAUCKNER C,HSIEH G.The presentation of health-related search results and its impact on negative emotional outcomes[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.ACM,2013:333-342.
[8]LIU Y,MIAO J,ZHANG M,etal.How do users describe their information need: query recommendation based on snippet click model[J].Expert Systems with Applications,2011,38(11): 13847-13856.
[9]XUE X,CROFT W B,SMITH D A.Modeling reformulation using passage analysis[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.ACM,2010: 1497-1500.
[10]CRASWELL N,BILLERBECK B,FETTERLY D,etal.Robust query rewriting using anchor data[C]//Proceedings of the Sixth ACM International Conference on Web Search and Data Mining.ACM,2013: 335-344.
[11]LIAO Z,JIANG D,CHEN E,etal.Mining concept sequences from large-scale search logs for context-aware query suggestion[J].ACM Transactions on Intelligent Systems and Technology (TIST),2011,3(1): 1-17.
[12]SONG Y,ZHOU D,HE L.Query suggestion by constructing term-transition graphs[C]//Proceedings of the Fifth ACM International Conference on Web Search and Data Mining.ACM,2012: 353-362.
[13]白露,郭嘉丰,曹雷,等.基于查询意图的长尾查询推荐[J].计算机学报,2013,36(3): 636-642.
BAI Lu,GUO Jia-feng,CAO Lei,etal.Long tail query recommendation based on query intent[J].Chinese Journal of Computers,2013,36(3): 636-642.(In Chinese)
[14]OZERTEM U,CHAPELLE O,DONMEZ P,etal.Learning to suggest: a machine learning framework for ranking query suggestions[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2012: 25-34.
[15]LUCCHESE C,ORLANDO S,PEREGO R,etal.Identifying task-based sessions in search engine query logs[C]//Proceedings of the Fourth ACM International Conference on Web Search and Data Mining.ACM,2011: 277-286.
[16]ZHAI C X.A note on the expectation-maximization (em) algorithm[C]//10th Int.2004: 403-410.
[17]BHATIA S,MAJUMDAR D,MITRA P.Query suggestions in the absence of query logs[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2011: 795-804.
[18]SONG Y,ZHOU D,HE L.Post-ranking query suggestion by diversifying search results[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2011: 815-824.
[19]李亚楠,王斌,李锦涛,等.给互联网建立索引: 基于词关系网络的智能查询推荐[J].软件学报,2011,22(8): 1771-1784.
LI Ya-nan,WANG Bin,LI Jin-tao,etal.Indexing the world wide web: intelligence query suggestion based on term relation network[J].Journal of Software,2011,22(8): 1771-1784.(In Chinese)
