新型OLTP数据库系统设计的关键技术及挑战
2014-09-06李战怀
任 堃, 李战怀
(西北工业大学 计算机学院, 西安 710129)
新型OLTP数据库系统设计的关键技术及挑战
任 堃, 李战怀
(西北工业大学 计算机学院, 西安 710129)
传统的数据库系统是根据20世纪70年代的硬件特点而设计. 随着“云计算”和“大数据”时代的到来,应用需求对数据库系统的事务吞吐量和可扩展性提出了更高的要求,同时内存、多核等新型计算机硬件技术的发展为数据库系统的发展提供了新的机遇,因此研究和设计新型数据库系统也变得越来越重要. 本文针对新型计算机硬件和应用需求的特点,研究和分析了新型OLTP数据库系统设计所涉及的关键技术,并探讨了存在的挑战性问题.
可扩展性; 计算机硬件; 事务处理; 确定性
0 引 言
现今的计算机硬件特点和20世纪70年代存在很大不同,在70年代,数据库系统通常在单核处理器下运行,内存容量非常有限,大多数数据库系统是以磁盘作为主要存储介质[1-2]. 随着计算机硬件的发展,目前单台服务器的内存容量已经达到TB级,而大多数数据库系统应用的大小仅有几百GB,因此很多数据库系统完全可以在内存中运行[3];同时计算机中的处理器核心越来越多,内存、多核等硬件技术的发展为数据库系统的发展提供了新的机遇. 相关研究[4-5]表明传统的数据库系统策略不能充分发挥内存和多核的硬件优势.
联机事务处理(On-Line Transaction Processing,OLTP)是数据库系统最重要的应用之一. 目前联机事务处理在金融、电信、互联网、游戏、交通、购物、医疗等关键领域起到非常重要的作用,也是学术界的研究热点. 随着“云计算”和“大数据”时代的到来,很多OLTP应用场景对数据库的事务吞吐量和可扩展性提出了更高的要求.
事务的ACID属性可以保证事务并发执行的正确性,是数据库系统中的一个重要概念. 通常情况下数据库系统允许多个事务并发执行. 当多个事务并发执行时,传统的策略是通过可串行化理论来保证ACID属性[6-8],尤其是隔离性属性. 相关研究表明在分布式数据库中保证事务的ACID属性更具有挑战[7-10],保证分布式事务的ACID属性限制了传统的分布式数据库系统的可扩展性[11,12]. 然而在“云计算”和“大数据”的背景下,数据库系统的可扩展性显得尤为重要.
为了数据的可靠性和提高系统的吞吐量,数据库系统通常采取多副本策略[13-16],如果保证副本间的强一致性,将增加事务的延迟和限制系统吞吐量. 有些系统采用最终一致性策略[17],此策略能够缓解强一致性所带来的限制和缺点,但却存在副本间不一致的情况,这在银行等很多场景下是不允许出现的.
本文针对新型计算机硬件和应用需求的特点,研究和分析了新型OLTP数据库系统设计所涉及的关键技术,同时也分析了分布式数据库设计中的关键问题,并探讨了存在的挑战性问题及今后重点研究方向.
1 传统的数据库系统设计框架及其问题
首先回顾一下传统的数据库系统的设计框架,其主要基于20世纪70年代的计算机硬件特点而设计,主要包括以下几个模块.
(1) 缓存池管理(Buffer Pool Manager)[18-21]:因为传统的数据库系统内存比较小而无法存储整个数据库系统,所以数据库系统用缓存池模块在内存中缓存一些磁盘块数据,并设计各种缓存算法来提高缓存命中率. 每个数据库查询操作首先查询所要操作的数据是否在缓存池中,如果命中就从缓存池中取出数据,否则就从磁盘中读取. 同时需要设计缓存池的缓存置换策略.
(2) 并发控制机制(Concurrency Control Mechanism):当一个线程执行的事务尝试访问的数据在磁盘中的时候,此线程处于等待磁盘读的阻塞状态. 为了提高系统CPU等资源的利用率,数据库系统使用并发控制方法来同时执行无冲突的多个事务[7-8],因此执行线程在等待某个事务磁盘操作的时候,可以执行别的不冲突的事务. 最常用的并发控制方法是基于锁的并发控制方法,例如System R[1,18]项目提出的两阶段加锁协议,此外还有乐观的并发控制方法和基于多版本的并发控制方法等[22-23].
(3) 恢复机制(Recovery Mechanism):为了保证事务的持久性,使数据库系统在出现软硬件等系统错误的时候仍然能够恢复,数据库系统使用恢复机制来维护正确的数据库状态. 大多数恢复机制都是基于事务日志的实现,需要记录元组修改前和修改后的状态,这些日志最终都需要写入磁盘[24-27],在业界和学术界最经典和最广泛使用的的恢复机制是ARIES恢复机制.
为了测试传统数据库设计的几个模块的开销,S. Harizopoulos等[4]在开源数据库系统Shore[28]上,测试了数据库系统在执行事务的过程中各个模块所执行的CPU指令数量,从而计算出每个模块的开销. 测试集使用的是TPC-C[29]中的New Order事务,测试中使用的数据库的容量小于内存容量,因此整个数据库完全在内存中存储,从而模拟了传统的数据库系统架构运行在内存数据库的环境. 图1显示的是其测试结果,其中显示只有大约12%的CPU时间在实际处理事务,其他时间都花费在缓存池管理、并发控制和事务恢复模块上. Postgre、MySQL等数据库系统的测试结果与之类似. 这充分说明了传统的数据库系统设计方案难以直接迁移到内存数据库系统中,因此非常有必要重新设计数据库系统框架.
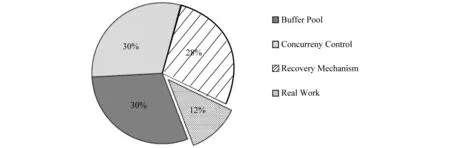
图1 数据库各个模块的开销
2 新硬件环境下的数据库系统设计的关键技术及挑战
针对传统数据库系统设计存在的问题,本文主要从以下几个方面来探讨新型OLTP数据库系统设计所要考虑的关键技术及其挑战.
2.1 针对内存的并发控制方法研究
计算机硬件的发展特点是内存容量越来越大以及价格越来越便宜,这引起了学术界和工业界对内存数据库系统的研究热潮. 现在有很多针对于内存数据库环境下的并发控制的研究. 例如Stavros Harizopoulos等[4]通过统计数据库模块的CPU执行指令数研究发现,在内存环境下,基于传统锁管理器的并发控制方法占用了大概21%的CPU时间,而实际的事务执行时间仅占12%左右,实验结果如图1所示;H-Store[30-31]和Hyper[32]系统提出,在内存数据库中不使用任何并发控制方法,在每个分区上由单个线程顺序执行事务的策略,这种策略避免了并发控制开销,但却限制了分布式事务的并发执行;Hekaton系统[33]指出了在内存环境下,传统的并发控制方法都不适用,并研究和提出了两种高效的基于多版本的并发控制方法,一种是悲观的,一种是乐观的,在这种并发控制策略中,事务不会出现阻塞的现象;I.Pandis等[34]重新设计了并发控制方法,通过划分分区,每个分区分配一个线程专门负责这个分区的所有锁操作,每个事务由其需要访问的分区的线程来协作进行锁操作;R. Johnson等[35]也发现传统的锁管理器的开销比较大,他们重新设计了锁管理器,通过减少锁操作的次数来减少锁开销;Ren Kun 等[36]研究指出:锁管理器的操作都是内存操作,对于以磁盘为存储介质的数据库系统来说,这些内存操作的开销很小,然而对于内存数据库来说,其操作开销显著增加,因此其研究了一种针对于内存数据库的轻量级锁机制技术VLL,实验结果表明此机制可以显著地减少锁开销.
总体来说,很多研究表明,最常用的基于锁的并发控制方法其锁开销相对于内存数据库比较大,而Heckton[33]、NuoDB[37]、SAP HANA[38-40]等使用的基于多版本的并发控制方法虽然可以避免锁开销,但却需要额外的内存来保存数据的多个版本,并且需要额外的操作来管理维护多个版本. 还有一些系统如Google的Spanner[41]、F1[42]等适用的是乐观的并发控制方法,没有以上提到的各种开销,但需要额外的验证步骤,可能会导致事务重启,尤其在冲突率比较高的场景下. 因此针对内存数据库的特点,非常有必要研究新型的并发控制方法,这也是未来的一个研究热点和挑战.
2.2 针对多核的并发控制方法研究
计算机硬件的另一个发展特点是CPU上的核越来越多. 因此近些年,针对于多核环境下的数据库系统研究得到了广泛关注. 本小节主要关注针对多核的并发控制方法研究. Hyungsoo Jung等[43]针对传统锁管理器的并发控制方法在多核环境下的可扩展性不佳的问题,提出了一种可扩展的锁管理器设计,通过使用同步原语操作,在MySQL源代码上进行修改,实验表明此策略显著提高了锁管理器的可扩展性. Takashi Horikawa[44]同样发现了传统的数据库设计在多核环境下的可扩展性问题,并重新设计了数据库的很多数据结构,主要提出和设计了Latch-Free的数据结构,实验结果表明此设计显著提高了数据库的并发性. Stephen Lyle Tu[45]和Hatem A. Mahmoud[46]等研究了新型硬件环境下的并发控制方法,提出了针对内存环境下高效的乐观的并发控制方法,同时此并发控制方法在多核环境下的可扩展性也非常好. Yu Xiangyao等[47]详细测试了传统的各种并发控制方法在多核环境下的性能,在Intel的仿真器上完成实验,仿真测试到1 024个CPU Core,其实验结果如图2,总结得出当前所有的并发控制方法在多核环境下的可扩展性比较差,大多数并发控制方法在大于8个Core的时候总吞吐量没有随着CPU Core的增加而增加. 因此非常有必要研究针对于多核环境下数据库系统设计策略,尤其是并发控制策略.

图2 各种并发控制方法在多核环境下的性能
2.3 内存数据库支持磁盘、NVM等存储介质的研究
内存技术虽然发展很快,但相比于磁盘,内存的容量还是有限,在很多场景下可能会出现数据库大小大于内存容量的情形. 在这种情况下,内存数据库系统还需要支持磁盘存储,使一部分数据存储在磁盘中. 微软的Per-Ake Larson等[48]研究了如果数据量超过内存大小,需要把一些“冷”数据转移到磁盘中,利用数据挖掘的算法分析“冷热”数据,从而设计出了高效的数据替换算法来置换“冷”数据至磁盘中,并把此算法应用到了Heckton数据库中. 在H-Store系统中,也进行了这方面的研究. 布朗大学的J DeBrabant等人研究了Anti-Caching策略[49],同样是把一些“冷”数据在磁盘中保存,和传统的缓存策略相反,H-Store系统中内存作为主存,磁盘作为辅助存储,和传统的缓存策略的另一个不同点是所有数据要么保存在内存中,要么保存在磁盘中,仅仅保存一份,从而减少了维护数据一致性的复杂度. 其基本思想是当遇到需要访问磁盘的事务的时候,延迟执行此事务而在后台进行读磁盘操作,当所需元组都在内存中的时候再执行此事务. Thomson等[50]针对确定性数据库系统提出了Prefetch策略来支持磁盘存储,基本思想和Anti-Caching比较类似,也是延迟执行需要访问磁盘的事务.
近年来,非易失内存(NVM)技术越来越成熟[51],NVM存储可以获得内存的读写性能,但同时也可以获得类似于SSD的数据持久性保存功能. 所以如果使用NVM作为数据库的存储介质,必将会使得数据库系统的很多模块设计发生变化,将会引出很多非常有研究价值的研究课题,例如如何组织数据库存储的层次关系、如何维护内存和NVM存储的缓存关系、如何设计基于NVM的并发控制方法等等. Brown、CMU、MIT和Intel合作的研究,在这方面进行了前沿研究[52],在Intel提供的NVM仿真器上进行实验(仿真NVM的读写延迟分别是内存的5倍和10倍),测试了数据库系统运行在NVM上的情况. 主要测试了两种数据库构架:① 主要存储和辅助存储都使用NVM;②主要存储使用内存,辅助存储采用NVM.
因此研究内存数据库系统支持磁盘存储以及NVM等新型存储器件,也是新型OLTP数据库系统的关键技术及挑战.
2.4 内存数据库系统的恢复机制研究
ARIES算法[7]被认为是数据库恢复的一个经典算法,别的很多数据库恢复机制都是和ARIES类似或基于ARIES修改的改进算法. 近些年,针对内存数据库系统的恢复机制得到了很多学者的研究. 康奈尔大学的Tuan Cao等[53]研究针对于内存数据库的频繁更新应用,提出了一种高效Checkpoint恢复算法以保证数据的持久性. Levy等[54]针对内存数据库研究了一种增量的恢复算法,通过独立的恢复数据库的页,因此可以并发的进行恢复. D.Lomet等[55]提出了逻辑日志的概念,通过应用逻辑日志而非物理日志来进行数据库的恢复. Malviya等[56]研究了针对内存数据库的轻量级的数据恢复机制command logging,也是应用了逻辑日志的概念. 其基本思想是在日志中仅仅保存事务本身,而不保存事务所涉及的元组更改前和更改后的状态,并和传统的ARIES-style的write-ahead logging并行对比. 实验结果表明这种恢复机制的开销更小,适合内存数据库系统. Calvin[50]研究了针对确定性数据库框架下的数据恢复机制,提出了一种高效的Checkpoint策略,即数据恢复不需要日志机制,仅仅需要在某个时刻的Checkpoint上进行重新执行事务操作即可.因此也非常有必要研究针对内存数据库系统的恢复机制.
3 新型分布式数据库系统设计的关键技术及挑战
由于待处理数据量的快速增长以及应用对事务高吞吐量的要求,单机数据库已经不能满足需求,分布式数据库是应对上述挑战的可行方式[57-58]. 本小节主要讨论分布式数据库系统设计中所涉及的关键技术及挑战,主要包括分布式事务处理策略和副本一致性策略.
3.1 CAP及PACELC定理介绍
在研究和设计系分布式数据库系统框架的时候主要参考CAP理论和PACELC理论,因此本小节主要介绍下CAP及PACELC理论.
首先介绍分布式系统中的一个重要的理论:CAP理论[59]. 很多分布式数据库系统的设计都是参考著名的CAP理论. 1998年,Eric Brewer教授提出了著名的CAP理论,后来Seth Gilbert和Nancy lynch两人证明了CAP理论的正确性. 简单地说,CAP(Consistency(一致性),Availability(可用性),Partition tolerance(分区容错性))理论表明:一个分布式系统不可能同时满足一致性,可用性和分区容错性这三个需求,最多只能同时满足其中的两个. 因此会出现AP(满足可用性和分区容错性,而不满足一致性),CA(满足一致性和可用性而不满足分区容错性)以及CP(满足一致性和分区容错性而不满足可用性)系统.
耶鲁大学学者Daniel Abadi教授对CAP理论做了补充,提出了PACELC理论[60],即如果考虑分区容错性,和CAP理论一样,必须在可用性和一致性之间进行权衡;如果不考虑分区容错性,必须在延迟(Latency)和一致性之间来权衡. PACELC理论主要是考虑到了如果不会出现分区错误的情况下,系统一直是可用的,所以系统的设计不需要考虑可用性,但这种情况下保持一致性又会增加事务请求延迟. 考虑到硬件和基础设施越来越好,分区容错会变得很少. 因此PACELC引出了一个重要的权衡,即必须在延迟和一致性之间来权衡,有些系统为了获得很强的一致性,但增加了事务请求的延迟,有些系统为了获得很小的系统延迟而牺牲了一致性.
3.2 分布式事务处理策略
分布式事务的处理策略最早在System R*[57]系统上实现,后面的商用或学术界的数据库系统基本都是参照或继承System R*的处理策略. 主要的处理策略包括:为了保证分布式事务的原子性,需要执行两阶段提交协议(2PC);为了保证隔离性,事务在执行两阶段提交协议期间必须保持加锁状态,即执行两阶段加锁协议(2PL).
相关研究表明[50,61],在执行两阶段提交协议期间加锁所带来的问题是:由于两阶段提交协议需要多次网络信息传输,因此执行两阶段提交协议的时间要比事务在本地的执行时间要长,而加锁时间的增长大幅增加了事务的冲突率,特别是对于一些热门的数据进行加锁,导致吞吐量的严重下降;同时也会增加分布式死锁的概率,检测和处理分布式死锁同样也会严重影响吞吐量. 虽然有一些并发控制协议不使用加锁协议,而使用乐观的并发控制协议或多版本控制协议(MVCC),但事务的冲突率增加依然会导致事务回滚的概率增大从而使吞吐量严重下降.
可扩展性(Scalabiliy)是指当数据库系统要处理更多的数据量和更高的事务吞吐量的时候,可以通过增加机器的线性扩展机制来达到要求. 近年来,大数据环境应用对事务吞吐量的要求越来越高,所以对系统可扩展性提出了更高的要求. 由于分布式系统中对于分布式事务ACID属性的支持比较困难,相关研究表明保持事务特别是分布式事务的ACID属性是限制分布式数据库可扩展性的主要原因[50,61].
分布式数据库系统的一个设计趋势是为了获得更好的线性可扩展性,减少或者不支持事务ACID属性. 一些系统包括Amazon的Dynamo[62]、MongoDB[63]、CouchDB[64]以及Cassandra系统[65]等不支持事务ACID属性; 另一些系统仅仅对事务ACID属性提供有限制的支持,例如仅支持单行或单分区的事务ACID属性,而不支持跨行或者跨分区的事务ACID实行,这些系统包括Google 的Bigtable[66]、Megastore[67]、微软的Azure[68]以及Oracle的NoSQL[69]等系统. 这些系统不支持事务ACID的最主要原因是为了获得很好的线性可扩展性. 减少对事务ACID属性的支持可以降低高可扩展性的分布式数据库的设计难度,然而却把保证事务ACID属性的任务留给了上层应用程序员,极大增加了代码的复杂度,同时延缓了应用开发的进度. 而且事务的ACID属性是数据库领域的一个重要概念,数据库几十年的发展也事实证明了保证事务的ACID属性的重要性.
另一些最新的系统例如H-Store、HyPer、VoltDB等新型内存数据库系统,支持强的事务ACID属性,采取的是在一个分区中单线程顺序执行事务的策略,对于大多数事务是单分区事务的场景下,可扩展性非常好,可以获得很高的吞吐量,然而在分布式事务比较多的场景下,吞吐量较低,因为当处理分布式事务的时候,限制了别的事务的并发执行. 因此这些系统只适用于上层应用容易分区的业务场景.
综上所述,在设计新型的分布式数据库系统的时候,需要研究如何在保证事务的ACID属性的同时可以获得很好的线性可扩展性.
3.3 分布式数据库系统副本一致性研究
大多数数据库系统选择采取多副本策略,即一份数据有多个副本,具体实现通常为在同一物理位置和不同的物理位置放置多个副本,这样的好处是:首先可以确保数据库系统的安全和容错性,例如某个物理位置的副本发生错误,可以从别的物理位置的副本进行拷贝恢复;其次多副本策略增加了数据库系统的性能和吞吐量,例如只读事务可以在任何一个副本上执行,实现了任务分流,提高了系统的吞吐量和性能. 然而如何保证副本间的一致性是一个研究热点.
由于很多分布式数据库系统的设计是参照CAP理论,最常见的一个权衡就是在允许分区容错性的基础上,在高可用性和多副本一致性之间进行权衡. 部分系统为了保证24/7的高可用性,甚至在出现网络或分区错误的情况下,依然要保证高可用性,然而却牺牲了多副本间的一致性,提供最终一致性(eventually consistency)或类似的弱一致性级别[70],即属于CAP理论的AP(满足分区容错性和可用性,而不满足一致性)系统. 这些系统包括Dynamo[62]、SimpleDB[71]、Cassandra[65]、Voldemort[72]、Riak[73]以及PNUTS[74]. 但是近些年,这个趋势有所改变,很多数据库系统的设计保证了副本间的强一致性,根据PACELC理论,强一致性策略增加了事务延迟,这些系统采取这种设计策略是因为网络传输等基础构架设施的不断改善减少了网络延迟(Latency),降低了网络错误的概率,因此即使为了获得副本间的强一致性而使得事务延迟增加,但事务延迟也在可接受的范围之内. 这些系统包括Google的Megastore[67]、F1(Spanner)[41,42]、IBM的Spinnaker系统[75]等,这些系统通过Paxos协议[76,77]来保证副本间的强一致性.
因此,在设计新型的分布式数据库系统的时候,需要研究如何保证副本间的一致性策略.
4 新型的确定性事务执行策略研究
事务执行策略是OLTP数据库系统中的一个重要研究方向. 近些年,随着内存数据库的普及以及事务执行特点的变化,确定性事务执行策略这种新型的事务执行策略得到了研究者的广泛关注.
4.1 基本原理及相关研究
Thomson等[50,78]提出了确定性事务执行策略的概念,是指在数据库系统开始执行事务之前,提前指定事务的执行顺序,并发执行事务的结果要等价于这个提前制定的事务执行顺序. 和传统的可串行化理论的区别是:可串行化理论要求事务并发执行后的状态等价于某一种(而不是事先确定的一种)事务串行执行后的状态,因此传统的事务执行策略是非确定的.
近年来,很多系统实现了确定性事务执行策略或接近于确定性的事务执行策略. Postgres-R[79]提出了一种复制协议来保证多个副本间的一致性,按照此复制协议,首先对事务进行排序,然后整个系统按照这个次序对事务进行加锁及执行,然而这种协议需要运行高开销的Group Communication协议来协调事务的执行,同时此协议在事务执行的过程中可能会出现事务回滚的现象,因此也不是严格的确定性事务执行策略. Ricardo Jimenez-Peris等[80]提出了一种基于中间件的确定性执行方案,此方案设计了一种确定性的多线程执行器,即各个副本对其上的每个线程进行相同的调度,可以获得多个副本间的强一致性,但是此种策略严格规定了线程在各个副本上的调度必须一致,极大限制了调度的灵活性. H-Store和VoltDB是按照处理器核心进行分区的内存数据库,各个事务在各个分区上顺序执行,而不采用并发控制方法,也是一种接近于确定性事务执行的策略,但不是严格的确定性事务执行策略,因为也可能会产生事务回滚. Garcia-Molina和Salem[81]提出在内存数据库环境下,没有磁盘I/O的瓶颈,大多数情况下不采用加锁等并发控制机制,而是事务完全的顺序执行可以获得最高的性能,但他们使用的仍然是传统的非确定性事务执行策略,因此也不是严格的确定性事务执行策略.
4.2 确定性事务执行策略的分析与评价
Ren Kun等[82]通过理论分析与实验验证对确定性事务执行策略进行了客观的分析与评价,总结其相对于传统的非确定性事务执行策略的优缺点. 研究结果表明确定性事务执行策略易获得数据库副本间的强一致性、可避免死锁和提交协议、具有更好的可扩展性和更高的吞吐量等优点;然而此策略所带来的缺点是丧失了事务执行的灵活性、限制了并发性以及增加了事务延迟等. 研究成果为数据库用户在不同应用场景下选择不同的事务执行策略提供了更多的参考. 表1是根据确定性事务执行策略的特点来归纳其优缺点.

表1 确定性事务执行策略的优缺点
5 总 结
针对新型应用需求和现代计算机硬件的发展特点,以及对分布式数据库系统可扩展性和一致性的新要求,有必要重新研究和设计新型OLTP数据库系统. 本文研究和分析了设计新型数据库系统所涉及的关键技术,重点研究了内存、多核、非易失内存等条件下数据库系统设计问题,以及分布式事务处理、多副本一致性等问题,最后介绍了确定性的事务执行策略.
[1] CHAMBERLIN D D, ASTRAHAN M M, BLASGEN M W, et al.A history and evaluation of System R[J]. CommunicationACM, 1981(24):632-646.
[2] GRAY J N, LORIE R A, PUTZOLU G R, et al. Modelling in data base management systems [J]. Chapter Granularity of locks and degrees of consistency in a shared data base,1976:365-393.
[3] STONEBRAKER M, MADDEN S, ABADI D J, S, et al. The end of an architectural era: (it’s time for a complete rewrite) [C]//VLDB, 2007:1150-1160,
[4] HARIZOPOULOS S, ABADI D J, MADDEN S, et al. OLTP through the looking glass, and what we found there [C]//SIGMOD,2008: 981-992.
[5] JUNG H, HAN H, FEKETE A D, et al. A scalable lock manager for multicores [C]//SIGMOD, 2013.
[6] BERNSTEIN P A, NEWCOMER E. Principles of Transaction Processing [M]. San Francisco: Morgan Kaufmann Publishers, 2009.
[7] BERNSTEIN P A, HADZILACOS V, GOODMAN N. Concurrency Control and Recovery in DatabaseSystems, chapter 7 [M]. Boston: Addison Wesley Publishing Company, 1987.
[8] GRAY J. Concurrency Control and Recovery in Database Systems [M].Berlin: Springer, 1978:393-481.
[9] BERNSTEIN P A, GOODMAN N. Concurrency control in distributed database systems [J]. ACM Computer.Survey, 1981,13(2):185-221.
[10] O’NEIL P E.The escrow transactional method [J]. ACM Trans Database Syst, 1986(11): 405-430.
[11] SHOUP R, PRITCHETT D. The ebay architecture [R]. SD Forum, November 2006.
[12] SOBEL J. Scaling Out (Facebook) [R]. http://on.fb.me/p7i7eK, April 2006.
[13] KING R P, HALIM N, GARCIA-MOLINA H, et al. Management of a remote backup copy for disaster recovery[J]. ACM Trans Database Syst, 1991, 16(2): 338-368.
[14] POLYZOIS C A, GARC′IA-MOLINA H. Evaluation of remote backup algorithms for transactionprocessing systems [J]. ACM Trans Database Syst, 1994, 19(3): 423-449.
[15] KRIKELLAS K, ELNIKETY S, VAGENA Z, et al. Strongly consistent replication for a bargain [C]//ICDE, 2010, 52-63.
[16] PLATTNER C, ALONSO G. Ganymed: scalable replication for transactional web applications [C]//Middleware, 2004: 155-174.
[17] VOGELS W. Eventually consistent [J]. Queue, 2008, 6: 14-19.
[18] ASTRAHAN M M, BLASGEN M W, CHAMBERLIN D D, et al. System r: relational approach to database management [J]. ACM Trans Database Syst, 1976, 1(2): 97-137.
[19] STONEBRAKER M, HELD G, WONG E, et al. The design and implementation of INGRES [J]. ACM Trans Database Syst, 1976, 1(3):189-222.
[20] COPELAND G, FRANKLIN M, WEIKUM G. Uniform object management [C]//EDBT, 1990(416): 253-268.
[21] GRAEFE G. The five-minute rule twenty years later, and how flash memory changes the rules [C]. DaMoN, 2007, 6:1-9.
[22] BERNSTEIN P A, GOODMAN N. Multiversion concurrency control - theory and algorithms [J]. ACM Trans. Database Syst, 1983, 8(4): 465-483.
[23] CHAN A, FOX S, LIN K, et al.The implementation of an integrated concurrency control and recovery scheme [C]//SIGMOD, 1982, 184-191.
[24] HELLAND P, SAMMER H, LYON J, et al. Group commit timers and high volume transaction systems [C]//Proceedings of the 2nd International Workshop on High Performance Transaction Systems. 1989, 301-329.
[25] HELLERSTEIN J M, STONEBRAKER M. Readings in Database Systems [M].San Francisco: Morgan Kaufmann Publisher, 1998: 238-243.
[26] MOHAN C, HADERLE D, LINDSAY B, et al. ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging [J]. ACM Trans. Database Syst, 1992, 17(1):94-162.
[27] O’NEIL P, CHENG E, GAWLICK D, et al. The log-structured merge-tree (LSM-tree) [J].Acta Inf, 1996, 33(4): 351-385.
[28] JOHNSON R, PANDIS I, HARDAVELLAS N, et al. Shore-mt:a scalable storage manager for the multicore era [C]//EDBT, 2009.
[29] The Transaction Processing Council. TPC-C Benchmark (Revision 5.9.0) [R].http://www.tpc.org/tpcc/spec/tpcc_current.pdf, June 2007.
[30] KALLMAN R, KIMURA H, NATKINS J, et al. H-Store: a high-performance, distributed main memory transaction processing system [C]//VLDB Endow. 2008, 1(2): 1496-1499.
[31] H-STORE [J/OL].http://hstore.cs.brown.edu.
[32] KEMPER A, NEUMANN T. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots [C]//ICDE, 2011, 195-206.
[33] DIACONU C, FREEDMAN C, ISMERT E, et al. Hekaton: Sql server’s memory-optimized oltp engine [C]//SIGMOD, 2013: 1243-1254.
[34] PANDIS I, JOHNSON R, HARDAVELLAS N. Data-oriented transaction execution [J]. PVLDB, 2010, 3(1): 928-939.
[35] JOHNSON R etc. Improving oltp scalability using speculative lock inheritance [C]//VLDB, 2009.
[36] REN K, THOMSON A, ABADI D J. Lightweight locking for main memory database systems [J]. PVLDB, 2013: 145-156.
[37] NUODB [J/OL].http://www.nuodb.com.
[38] FARBER F, CHA S K, PRIMSCH J, et al. SAP HANA database: data management for modern business applications [J]. SIGMOD Rec, 2012, 40(4): 45-51.
[39] LEE J, MUEHLE M, MAY N, et al. High-performance transaction processing in SAP HANA [J]. IEEE Data Eng Bull, 2013, 36(2): 28-33.
[40] SIKKA V, FARBER F, LEHNER W, et al. Efficient transaction processing in SAP HANA database: the end of a column store myth [C]//SIGMOD, 2012: 731-742.
[41] CORBETT J C, DEAN J, EPSTEIN M, et al. Spanner: Google’s globally-distributed database [C]//OSDI, 2012.
[42] SHUTE J, VINGRALEK R, SAMWEL B, et al. F1: A distributed sql database that scales [C]//VLDB, 2013.
[43] JUNG H, HAN H, FEKETE A D, et al. A scalable lock manager for multicores [C]. SIGMOD 2013.
[44] HORIKAWA T. Latch-free data structures for DBMS:design, implementation,and evaluation [C]//SIGMOD, 2013.
[45] STEPHEN T, ZHENG W T, KOHLER E, et al. Speedy transactions in multicore in-memory databases [C]//SOSP, 2013.
[46] MAHMOUD H A, ARORA V, NAWAB F, et al. MaaT: Effective and scalable coordination of distributed transactions in the cloud [J]. PVLDB, 2014, 7.
[47] YU X Y, BEZERRA G, STONEBRAKER M, et al. Concurrency control in the many-core era: scalability and limitations [R]. Blog:http://istc-bigdata.org/index.php/concurrency-control-in-the-many-core-era-scalability-and-limitations/.
[48] LEVANDOSKI J J, LARSON P A, STOICA R. Identifying hotand cold data in main-memory databases [C]//ICDE, 2013: 26-37.
[49] DEBRABANT J, PAVLO A, TU S, et al. Anti-Caching: A new approach to database management system architecture [J]. PVLDB, 2013, 6.
[50] THOMSON A, DIAMOND T, WENG S C, et al. Calvin: fast distributed transactions for partitioned database systems [C]//SIGMOD, 2012.
[51] ROBERTS D, CHANG J, RANGANATHAN P, et al. Is storage hierarchy dead? co-located compute-storage nvram-based architectures for data-centric workloads [R]. Technical Report HPL-2010-119, HP Labs, 2010.
[52] ARULRAJ J, DEBRABANT J, PAVLO A, et al. OLTP database systems for non-volatile memory [R]. Blog: http://istc-bigdata.org/index.php/oltp-database-systems-for-non-volatile-memory/.
[53] CAO T, VAZSALLES M, SOWELL B, et al. Fast checkpoint recovery algorithms for frequently consistent applications [C]//Proceedings of the 2011 international conference on Management of data. SIGMOD ’11, 2011: 265-276.
[54] LEVY E, SILBERSCHATZ A. Incremental recovery in main memory database systems [J]. IEEE Trans on Knowl and Data Eng, 1992, 4: 529-540.
[55] LOMET D, TZOUMAS K, ZWILLING M. Implementing performance competitive logical recovery [J]. Proc VLDB Endow , 2011, 4: 430-439.
[56] MALVIYA N, WEISBERG A, MADDEN S, et al. Rethinking main memory OLTP recovery [C]//Data Engineering (ICDE). 2014 IEEE 30th International Conference on, 2014: 604-615.
[57] DEWITT D, GRAY J. Parallel database systems: the future of high performance database systems [J].Commun ACM, 1992, 35(6): 85-98.
[58] MOHAN C, LINDSAY B, OBERMARCK R. Transaction management in the r*distributed databasemanagement system [J]. ACM Trans Database Syst, 1986, 11(4): 378-396.
[59] GILBERT S, LYNCH N A. Perspectives on the CAP theorem [J]. Computer, 2012, 45(2): 30-36.
[60] ABADI D J. Consistency tradeoffs in modern distributed database system design: CAP is only part of the story [J]. IEEE Computer, 2012, 45(2).
[61] Thomson A, DIAMEND T, WENG SH CH, REN K, et al. Fast distributed transactions and strongly consistent replication for OLTP database systems [J]. ACM Transactions on Database Systems (TODS),2013,39(4):1337-1371.
[62] DECANDIA G, HASTORUN D, JAMPANI M, et al. Dynamo: amazon’s highly available key-value store [J]. SIGOPS Oper Syst Rev, 2007(41): 205-220.
[63] MONGODB [J/OL].http://mongodb.org.
[64] ANDERSON J C, LEHNARDT J, SLATER N. CouchDB: the definitive guide [J]. CouchDB Homepage, 2010.
[65] LAKSHMAN A, MALIK P. Cassandra: a decentralized structured storage system [J]. SIGOPS Oper Syst Rev, 2010, 44(2): 35-40.
[66] CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: A distributed storage system for structured data [J]. ACM Trans Comput Syst, 2008, 26(4):1-26.
[67] BAKER J, BOND C, CORBETT J, et al. Megastore: Providing scalable, highly available storage for interactive services [C]//CIDR, 2011.
[68] CAMPBELL D, KAKIVAYA G, ELLIS N. Extreme scale with full sql language support in microsoftsql azure [C]//SIGMOD, 2010.
[69] SELTZER M. Oracle nosql database [R]. Oracle White Paper, 2011.
[70] DAVIDSON S B, GARCIA-MOLINA H, SKEEN D. Consistency in a partitioned network: a survey [J]. ACM Computing Surveys , 1985, 17(3): 341-370.
[71] Amazon simpledb [J/OL].http://aws.amazon.com/simpledb/.
[72] Project voldemort [J/OL]. http://project-voldemort.com/.
[73] Riak [J/OL].http://wiki.basho.com/riak.html.
[74] COOPER B F, RAMAKRISHNAN R, SRIVASTAVA U, et al. Pnuts: Yahoo!’s hosted data serving platform [C]//Proc VLDB Endow. 2008, 1(2): 1277-1288.
[75] RAO J, SHEKITA E J, TATA S. Using paxos to build a scalable, consistent, and highly available datastore [C]//VLDB, 2011.
[76] LAMPORT L.The part-time parliament [J]. ACM Trans on Comput Syst, 1998.
[77] LAMPORT L. Paxos made simple [J]. ACM SIGACT News, 2001.
[78] THOMSON A, ABADI D J. The case for determinism in database systems [J]. PVLDB, 2010, 3(1).
[79] KEMME B, ALONSO G. Don't be lazy, be consistent:Postgres-r, a new way to implement database replication [C]//VLDB, 2000.
[80] JIMENEZ-PERIS R, PATINO-MARTINEZ P, AREVALO S. Deterministic scheduling for transactional multithreaded replicas [C]//IEEE SRDS, 2000.
[81] GARCIA-MOLINA H, SALEM K. Main memory database systems: An overview [J]. IEEE Transactions on Knowledge and Data Engineering, 1992: 4(6).
[82] REN K, THOMSON A, ABADI D.An evaluation of the advantages and disadvantages of deterministic database systems [J].40th International Conference on Very Large Data (VLDB 2014), 2014, 7: 821-832.
(责任编辑 李 艺)
Key techniques and challenges of designing new OLTP database systems
REN Kun, LI Zhan-huai
(DepartmentofComputerScience,NorthwesternPolytechnicalUniversity,Xi’An710129,China)
Traditional database systems were designed based on the hardware environment in 1970s. However, with the era of “Cloud Computing” and “Big Data”, On-Line Transaction Processing requires database systems to provide more transaction throughput and better scalability. Meanwhile, the development of Computer hardware, in particular memory and multiple CPU Cores offer new opportunity for database systems evolution. Therefore, researching and designing new distributed database systems becomes more and more crucial. This paper researched on the key techniques and challenges of designing new OLTP Database systems.
scalability; computer hardware; transaction processing; determinism
1000-5641(2014)05-0031-12
2014-06
国家“973”计划课题(2012CB316203);国家自然科学基金重点项目(61033007)
任堃,男,博士研究生,研究方向为分布式数据库系统、事务处理. E-mail: renkun_nwpu@mail.nwpu.edu.cn.
李战怀,男,教授,博士生导师,研究方向为数据管理技术. E-mail: lizhh@nwpu.edu.cn.
TP311
A
10.3969/j.issn.1000-5641.2014.05.003
