融合协同训练和两层主动学习策略的SVM分类方法
2014-09-01谢科
谢 科
(阿坝师范高等专科学校计算机科学系,中国 汶川 623002)
融合协同训练和两层主动学习策略的SVM分类方法
谢 科*
(阿坝师范高等专科学校计算机科学系,中国 汶川 623002)
针对当前主动学习策略直接用于SVM分类器时存在的泛化能力不强的问题,结合协同训练思想,提出了两层主动学习策略(TLAC),并用于SVM深层挖掘未标记样本数据的分布知识.实验表明,该TLAC策略能够合理的指定TSVM算法中的正样本数,在典型指标测试中都表现出了一定的优越性.
协同训练;主动学习;贝叶斯网络;支持向量机
在传统的学习机技术中,学习器的学习主要针对带有标记的样本数据,而且通过模拟建立的模型主要用于对有标记的样本数据集进行数据的预测和推断,并在分类问题中标记出样本数据的类别.由于目前数据收集技术的快速发展和逐步提高,在收集数据时对未标记样本数据的收集十分容易,而在获取大量有标记的样本数据时比较困难,这是因为在获取有标记样本数据时需要耗费大量的人力、财力、物力等资源.而利用少量有标记样本数据训练出的学习器往往泛化能力并不强.那么如何在有标记样本数据较少的情况下,通过利用大量的不带标记样本数据来改善学习器的性能已经成为目前机器学习研究的热点之一.
1 研究现状
文献[1]首次将主动学习策略用于支持向量机(Support Vector Machine,SVM)算法中,文中利用主动学习策略选取SVM分类器最有可能预测的样本,根据这些样本尽可能地简约SVM分类器超平面所在的版本空间,从而得到最有可能近似正确划分所有样本的超平面.实验分析也指出对直推支持向量机(Transducive Support Vector Machine, TSVM)采用文中所提的主动查询策略在某些情况下不如随机查询效果好.文献[2]利用主动学习策略并结合高斯随机场和谐波函数对学习器进行半监督形式的学习,该策略首先通过样本数据训练建立一个图,图中建立的每个节点都代表一个(有标记或未标记)样本数据,然后通过求解对应的函数最优值,进一步获取未标记样本数据的最优标记.该文在最后的实验分析中指出如果利用结构风险最小化准则去主动查询训练SVM,所得到的精度甚至不如直接在SVM上随机查询所得的训练精度.文献[3]提出的基于SVM的主动学习方法,采用版本空间和边缘方法选取样本的标记,其主要思想是反复选择离分类超平面最近的未标记样本标注直至达到设定阈值停止.文献[4]则对文中提出的方法进行改进,提出了一种基于不确定选样和确定选择相结合的主动学习方法,并应用于浅层语义分析的任务.
基于上述文献分析,目前基于SVM的学习存在下面两个问题:(1)对于错误样本标记敏感,如果初始的SVM分类超平面位置不好,需要很长时间才能移动到合理的位置,甚至受错误标记影响较大时,分类超平面会一直停留在不合理的位置:(2)基于SVM的主动学习在查询的中后期,查询的点大部分位于SVM分类超平面附近,使得算法的泛化能力不强.
2 两层主动学习策略
2.1 直推支持向量机设计
文献[5] 提出了直推支持向量机算法,在TSVM算法对样本数据进行训练的过程中,该训练过程通过不断地修改超平面并实时对该超平面两侧的某些未标记实例进行标记处理,通过不断训练获取一个数据相对稀疏的区域并把这些标记实例划分为超平面.
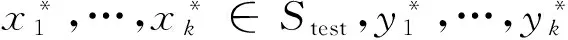
(1)
使用TSVM算法训练获取的学习器比只使用标记样本数据训练获取到的学习器,在性能上有显著的提高.但TSVM算法的主要缺陷是该算法执行之前需要指定待训练数据的未标记样本数据中的正标签样本数N.如果标记样本较少或者样本标记严重不平衡,就会导致学习器性能的迅速下降.为此,文献[6~7]分别就此问题对TSVM算法做了改进.但是这些改进算法还是基于一些假设进行的,没有从根本上利用未标记样本的潜在分布.TSVM算法流程可以分为SVM训练和TSVM迭代过程.如果将主动学习策略应用于TSVM上,也将出现错误样本标记敏感和泛化能力不强的问题.
2.2 主动贝叶斯网络分类器的构建
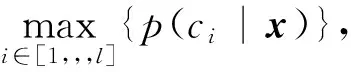
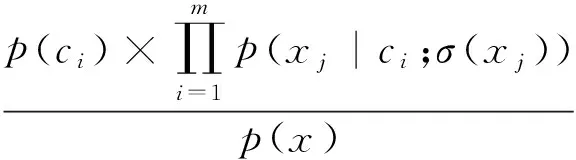
(2)
这里σ(xj)表示结点Nj除类别结点C之外的所有父结点,xj表示实例x第j个特征的取值.根据文献[9],类概率采用无信息先验均匀分布计算,类后验概率p(xj|ci;σ(xj))用共轭分布计算.
贝叶斯网络学习包括结构学习和参数学习,其学习的目标是找到和样本数据集合D匹配度最好的贝叶斯网络结构,参数学习的目标是给定网络拓扑结构S和训练样本集D,利用先验知识,确定贝叶斯网络模型各结点处的条件概率密度,记为:p(θ|D,S)[10].
在本文中假定结构已知,主要讨论参数学习的情况.
2.3 主动学习策略设计
主动学习方法是选择最有利于分类器性能的样本来训练分类器,它不但能够通过选择高质量的样本来训练分类器,并且大大地减少了用于训练的样本数量[11].给定网络拓扑结构S和先验分布p(θ),根据某主动学习策略从未标记样本集中选择一实例xi,标记并加入标记样本集中.更新分布p(θ)为p′(θ),然后再寻找下一实例.令参数向量θ=(θ1,θ2,…,θr)服从分布Dirichlet(α1,a2,…,ar),ar表示观测数据之前的先验知识或专家经验.如果查询一实例xi,则p′(θ)服从分布Dirichlet(α1,…,ai+1,…,ar).
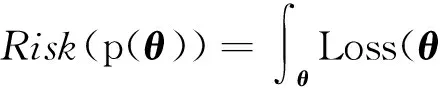
HR(θ‖θ′)=∑i∑jHR(Pθ(xi|σj)‖Pθ′(xi|σj))Pθ(σj),
(3)
(4)
其中θ为条件概率分布Pθ(xi|σj)的参数集,σj为Xi的父节点集. 在此假定参数是独立的,我们利用共轭分布来计算后验概率.由参数独立性可知,p(θ)=∏i∏jp(θXi|σ(j)).令参数向量θ=(θ1,θ2,…,θr)服从Dirichlet分布,如果样本的属性值出现nk次,根据共轭分布的定义,它的后验分布也服从分布Dirichlet(α1+n1,…,ar+nr),其中(α1,α2,…,αr)为超参数.由此可得下式:
(5)
从未标记样本中查询时,每次选取期望后验风险值最大的样本实例,将之标记并加入已标记样本中.以此不断迭代直至达到设定的条件时停止.
下面给出基于两层分类器的主动学习算法(TLAC):
输入:标记样本集L,未标记样本集U,空集P;输出:TSVM的分类值.
步骤:
1) 用贝叶斯网络分类器训练标记样本集L(最少包括正负例各一);
2) 计算未标记样本集U中的每个样本的期望后验风险值,选取值最大的一个样本;
3) 用当前的分类器标注该样本,并把它加入到L中,再从U中移走;
4) 将该样本放入P中,并获取它的样本标记;
5) 重新从步骤1开始执行,并反复这一循环,直到达到设定的停止准则或未标记样本用尽;
6) 计算P集中正样本的数目并记为N;
7) 将P集中样本当作未标记样本,和标记样本集L一起训练TSVM分类器,输出所有样本的分类值.
2.4 算法分析
本文提出的TLAC算法中先用了贝叶斯网络算法对未标记数据进行标记,然后把这些标记了的数据结合TSVM算法进行迭代训练,这个过程类似于co-training思想.两个不同偏置的分类器可能将同一个实例标记成不同的标记值.
定义1 令A表示贝叶斯算法,B表示支持向量机算法,C为训练样本的真实分类器(泛化错误为0).d(A,B)表示两个分类器之间的偏置差异,d(B,C)表示与真实分类器之间的偏置之差,即d(B,C)=Prx∈D[B(x)≠C(x)].
定义2 根据定义1,有d(A,B1),其中B1表示含有标记的样本,A表示利用未带标记的样本集训练而出的标签值.根据文献[13]关于协同分类算法性能的证明,对于给定的泛化错误ε1,下面的公式以不低于1-δ的概率成立:Pr[d(B1,C)≥ε]≤δ.
基于贝叶斯的主动学习策略能均匀地从未标记样本的分布中查询实例,可以避免SVM主动学习超平面移动的问题.算法中关于TSVM中正样本数N的估计是根据贝叶斯方法从未标记样本中训练所得,基本和分布的真实正样本数目相符.在定义1和定义2中从理论上揭示了贝叶斯网络分类器含有支持向量机分类器未知的信息,可以提高TSVM算法的性能.
3 仿真实验
TLAC算法是基于Joachims 的SVMLight 软件实现的,其中SVM参数中核函数选择RBF核函数.下面将用UCI标准数据集[14]对算法的性能进行测试,采用文献[15]中的方法对数据进行约简.由于UCI标准数据集所包含的数据集类别以及数据量较大,考虑到实验中各对比算法的特点,作者只选择部分数据集来验证文中算法,具体所选数据集如表1所示.
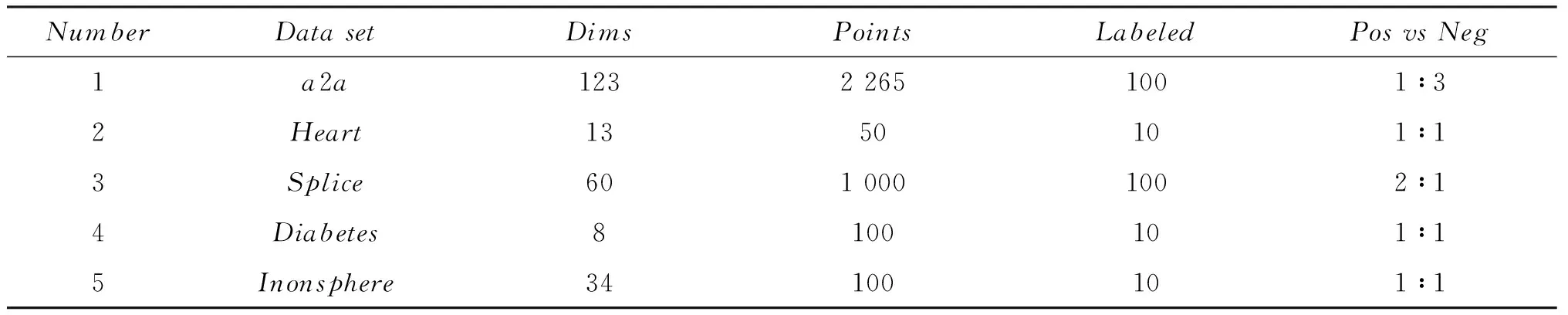
表1 所选UCI数据集
从表1可以看出,在实验中,从a2a和splice数据集中各选取了100个已标记样本,从Heart 、Diabetes和Inonsphere这3类数据集中分别选取了10个样本,其中正负样本数相等.由于在Dirichlet分布中超参数表示先验知识,因此,在实验中根据所选数据集的分布特点,令a2a和splice数据集的先验分布p(θ)服从Dir(50,50),而令其他3类数据集直接服从分布Dir(5,5).本实验采用3个指标来评价结果:Recall,Precision,Accuracy.假设数据集样本总数为N,令N=A+B+C+D.变量定义见表2所示.

表2 混淆矩阵
并定义如下:
Recall=A/(A+C)*100%,
Precision=A/(A+B)*100%,
Accuracy=(A+D)/N*100%.
具体实验结果如图1所示:
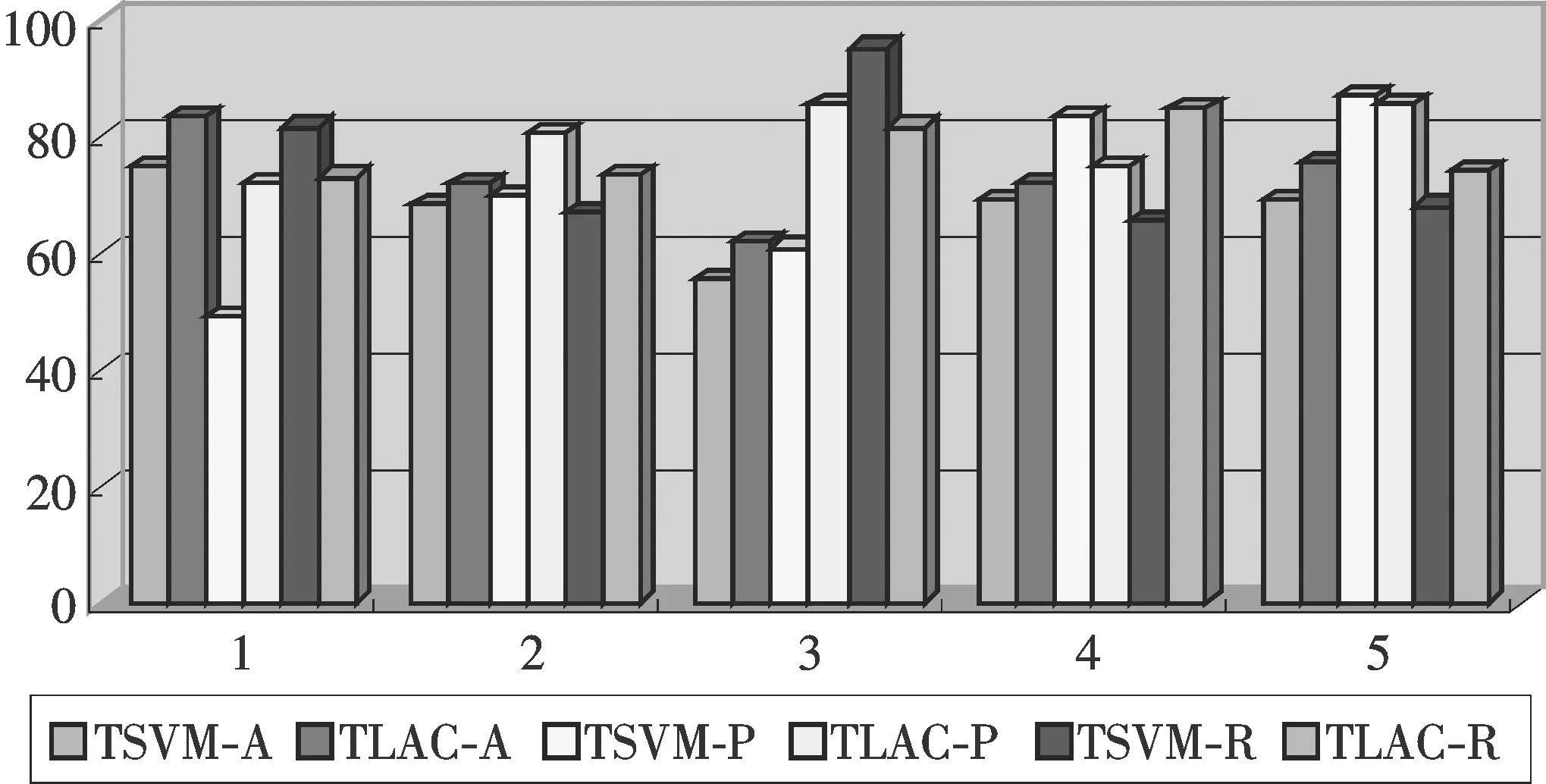
图1 UCI数据集测试结果Fig.1 Test results on UCI data sets
因为数据集中的标记样本是在数据集中随机选取的,如果初始分类超平面处在不合理的位置,利用TSVM训练得到的准确率也可能不太好.从图1可以看出,在处理1类和3类时,我们的算法准确率更高,这是因为TSVM在初始估计的正样本数和真实值之间相差较大.但是1类和3类的召回率有所下降,这是因为这两类维数较高,由于高维特征空间映射时可能导致样本相对位置改变,从而影响分类器的决策.4类的样本分布不均匀导致了精度有所下降.
4 结束语
针对当前TSVM算法存在的问题和主动学习策略用于SVM分类器的缺陷,本文提出了一种基于贝叶斯的主动学习选取样本策略用于TSVM算法中,在一定程度上解决了TSVM算法指定正样本的问题,同时也使主动学习策略能在全局分布上进行查询样本,进而使SVM分类器的超平面移动到合理的位置.由于贝叶斯分类器也有其固有的假设性缺陷,本文的后续工作是进一步改进主动学习策略,挖掘未标记数据的潜在分布知识,并用真实数据集加以测试.
[1] 袁 勋,吴秀清,洪日昌. 基于主动学习SVM分类器的视频分类[J]. 中国科学技术大学学报, 2009,39(5):473-478.
[2] 赵英刚,陈 奇,何钦铭.一种基于支持向量机的直推式学习算法[J].江南大学学报:自然科学版, 2006,26(8):441-444.
[3] 陈耀东,王 挺,陈火旺.半监督学习和主动学习相结合的浅层次语义分析[J].中文信息学报, 2008,22(2):70-75.
[3] CHEN Y D, WANG T, CHEN H W. Combining semi-supervised learning and active learning for shallow semantic parsing[J]. J Chin Infor Proc, 2008,22(2):70-75.
[4] 刘端阳,邱卫杰. 基于SVM期望间隔的多标签分类的主动学习[J].计算机科学, 2011,38(4): 230-233.
[5] 刘端阳,邱卫杰. 基于加权SVM主动学习的多标签分类[J].计算机工程, 2011,37(8):181-183.
[6] 赵卫中,马慧芳,李志清. 一种结合主动学习的半监督文档聚类算法[J]. 软件学报, 2012,23(6):1486-1499.
[7] 白龙飞, 王文剑, 郭虎升. 一种新的支持向量机主动学习策略[J]. 南京大学学报:自然科学版, 2012,48(2):182-189.
[8] 杨颖涛,王跃钢,邓卫强,等. 基于共轭先验分布的贝叶斯网络分类模型[J].控制与决策, 2012,27(9):1393-1397.
[9] 王中锋,王志海. 基于条件对数似然函数导数的贝叶斯网络分类器优化算法[J]. 计算机学报, 2012,35(2):364-374.
[10] 曾杰鹏, 廖 芹, 谷志元. 基于结构继承的贝叶斯网结构学习优化设计[J]. 计算机工程与设计, 2012,33(7):2782-2786.
[11] 张晓宇. 基于动态可行域划分的SVM主动学习[J].计算机科学, 2012,39(7):175-178.
[12] 吴伟宁,刘 扬,郭茂祖. 基于采样策略的主动学习算法研究进展[J]. 计算机研究与发展, 2012,19(6):1162-1173.
[13] 戴上平,姬盈利,王 华. 基于多群协同人工鱼群算法的分类规则提取算法[J]. 计算机应用研究, 2012,29(5):1666-1669.
[14] MERZ C, MURPHY P, AHA W. UCI Repository of machine learning databases[D].Irvine: Department of Information and Computer Science, University of California, 1997.
[15] 谢 科. 基于可分辨矩阵的属性集依赖度计算方法[J]. 湖南师范大学自然科学学报, 2012,35(6):13-16.
(编辑 沈小玲)
重要启事
·优先数字出版· “优先数字出版”是以纸质版期刊录用稿件为出版内容,先于纸质期刊出版日期出版的数字期刊出版方式.
为了缩短稿件的发表周期,提高作者学术成果的认可、传播和利用价值,我刊与中国学术期刊(光盘版)电子杂志社签订了优先数字出版协议,自2012年1月1日起在中国知网(CNKI)对本刊拟录用的学术论文实行单篇优先数字出版.凡被我刊录用的稿件一经优先数字出版,读者即可在中国知网(CNKI)全文数据库进行检索和下载,广大读者对我刊论文的查询、阅读、引用与传播也将更加便捷.
从2012年起,凡向本刊投稿的作者,如无特别申明,均被视为作者授权本刊编辑部在纸质期刊出版前,可以在中国学术期刊(光盘版)电子杂志社主办的“中国知网”(www.cnki.net)上优先数字出版;也被视为作者同意并授权我刊与其他电子杂志社签订的协议,并许可他们在全球范围内使用该文的信息网络传播权、数字化复制权、数字化汇编权、发行权及翻译权,并不再额外支付稿酬.
·电子稿件系统· 从2012年1月起,湖南师范大学期刊社所属的3个学报全部正式启用电子稿件系统.投稿网址分别为《湖南师范大学自然科学学报》:http://zkxb.hunnu.edu.cn;《湖南师范大学教育科学学报》:http://jkb.hunnu.edu.cn;《湖南师范大学社会科学学报》:http://skb.hunnu.edu.cn.
本刊编辑部
SVM Classification Method Combined Co-Training with TLAC Strategy
XIEKe*
(Department of Computer Science, Aba Teachers College, Wenchuan 623002, China)
To deal with the poor generalization problem when active learning strategy is directly using in SVM classifier, a two-level active learning strategy(TLAC) is proposed by using the idea of co-training, and applied in deep mining the distribution knowledge of unlabled samples. The experimental results show that TLAC strategy can determine the positive labeled sample numbers reasonably and demonstrate its superiority in typical indicator test.
co-training; active learning; Bayesian network; SVM
2012-11-26
四川省教育厅资助项目(122B168);阿坝师专校级重点科研资助项目(ASB13-15)
*
,E-mail12257776@qq.com
TP315
A
1000-2537(2014)01-0090-05
