基于二次SVM的不均衡数据算法
2014-07-20张燕
张燕
(商洛学院 数学与计算机应用学院,陕西商洛726000)
基于二次SVM的不均衡数据算法
张燕
(商洛学院 数学与计算机应用学院,陕西商洛726000)
为减少不均衡数据对支持向量机分类性能的影响,提出一种基于二次支持向量机的欠取样分类算法,该算法依据样本的分类超平面贡献大小对多数类样本进行欠取样,并对少数类样本进行过取样,重构训练数据集。该算法能够删除样本中的噪声数据,用控制参数控制删除样本的规模,实验表明,该算法能够提高支持向量机在不均衡数据集下的分类性能。
支持向量机;不均衡数据;欠取样;分类超平面
支持向量机(Support Vector Machine,简称SVM)[1]是在统计学习理论基础上发展起来的一种新的机器学习方法,它基于结构风险最小化原则,在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势。传统SVM在均衡训练样本下有较好的分类性能,然而在样本数量不均衡的情况下SVM对多数类样本的过于拟合,而对少数类样本则是欠学习。均衡化方法可以分为两类:数据层面的方法和算法层面的方法。数据层面的方法主要是通过一定策略删除多数类的样本或者增加少数类的样本使数据集均衡化,进而提高分类器在不均衡数据集下的分类性能,常采用的方法有过采样[3-7]和欠采样[8-13]。算法层面的方法主要有代价敏感学习、核方法、集成方法如boosting等。
杨智明等[10]在核空间中对多数类样本进行谱聚类,然后依据聚类大小及聚类与少数类样本间的距离选择有代表性的样本;陶新民等[11]利用模糊样本修剪技术计算边界样本隶属度概率,还利用基于无监督学习方法的指导型欠采样技术减少欠采样时分类信息丢失的问题;吴磊等[12]、金鑫等[13]融合欠采样技术和过采样技术,避免过度欠采样导致分类信息丢失。以上欠采样方法中,都是为了减少样本修剪的过程中分类信息丢失,在一定程度上减少了信息的丢失,但仍会造成部分分类信息的丢失。然而在支持向量机中影响最终决策函数的是由支持向量所决定的分类超平面,而远离超平面的样本对决策函数影响较小,甚至没有影响;而过采样将增加训练集的规模,也会大大增加训练时间,基于以上分析,本文提出一种基于二次支持向量机(Double Support Vector Machine,DSVM)决策函数特点不均衡数据分类算法,该算法依据样本对构建分类超平面的贡献大小进行修剪,同时利用控制参数控制删除样本的比例,较好地实现不均衡数的均衡化处理,仿真实验表明该方法较好地解决了不均衡数据的分类,提高了分类准确率,特别是少数类样本的分类准确率。
1 支持向量机
1.1 SVM算法
训练SVM的过程实质就是求解最优分类超平面问题,即要保证正确分类的最小错误率,又要保证最大化分类间隔。给定一个样本集
T={(x1,y1),(x2,y2),…,(xl,yl)},xi∈Rn,yi∈{1,-1}。SVM的主要目的是构造一个分类超平面以分割两类不同的样本,使得分类间隔最大,同时错误率最小,可以通过求解(1)式二次优化问题,得到决策函数。
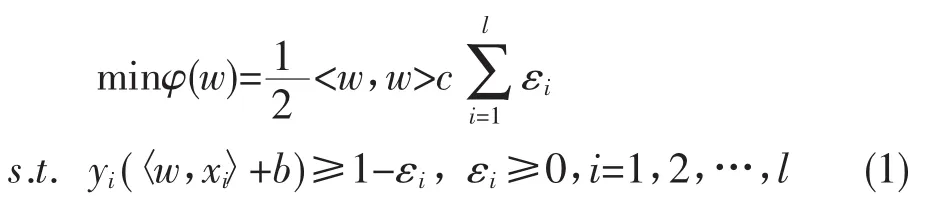
通过引入Lagrange算子可以得到问题(1)的对偶问题:

其中K(xi,yi)为核函数,K(xi,yi)=〈φ(xi),φ(xj)〉,是采用非线性映射φ:Rk|→F将训练样本从输入空间映射到某一特征空间,在该特征空间中样本是线性可分的。最后可以得到决策函数为:
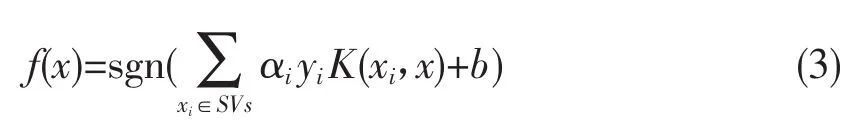
由决策函数可以看出,影响支持向量机最终分类性能的是支持向量,即αi≠0的样本,如图1所示,而那些远离分类超平面的样本对分类结果没有任何影响。
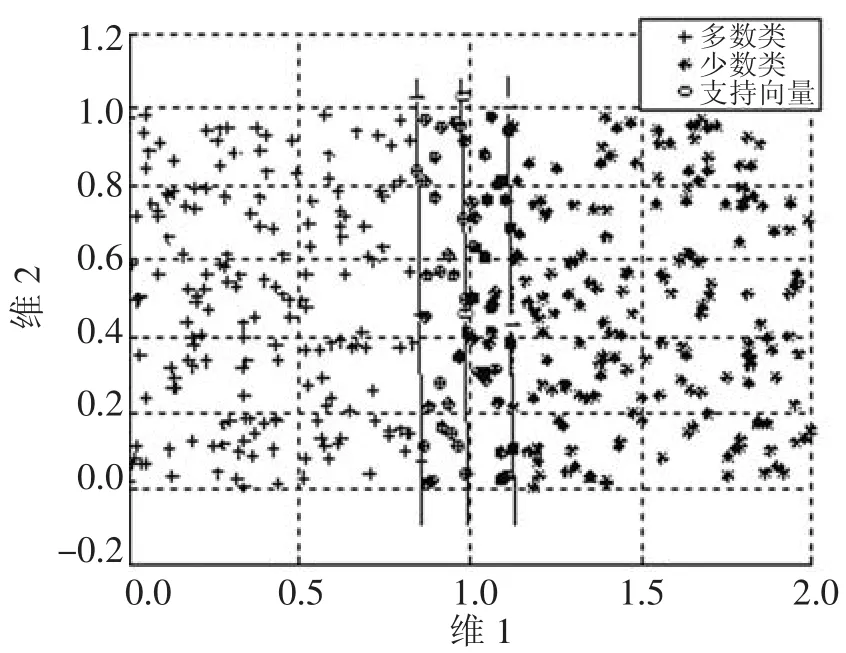
图1 样本比例100:100分类决策面
1.2 不均衡数据对SVM的影响
不均衡数据(Imbalanced Data,ID)指的是同一数据集中某些类的样本数量比其他类的样本数量多的多,其中样本数量多的类称为多数类,样本数量少的类称为少数类。通常如果目标类在数据集中所占比例非常小(通常远低于10%)就称为稀有类。所谓不均衡分类问题指的是对这些不平衡数据进行分类时,传统的分类方法倾向于对多数类有较高的识别率,对少数类的识别率却很低的问题。
为观察不均衡数据对分类决策面的影响,随机产生两类均匀分布的样本,第一类样本为U([0,1]×[0,1],第二类样本为U([0,1]×[1,2],第一类样本数为200,第二类样本数为20,经支持向量机训练最终的分类决策面如图2所示,其中线条为分类超平面。
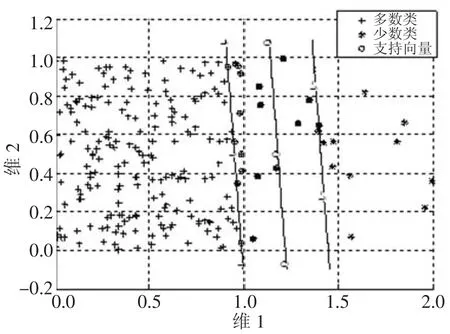
图2 样本比例是200:20的决策面
由图1和图2可以看出,样本不均衡的情况下,分类超平面向少数类样本侧移动。这是因为支持向量机在训练时认为两类样本错分造成的损失相同,即采用相同的惩罚因子。支持向量机为使分类间隔尽可能的大,同时保证分类错误率尽可能的小,因此分类超平面会向少数类样本方向偏移,最终导致对少数类样本分类错误率较高。对此,文献[14]提出对两个类采用不同的惩罚因子,为体现对少数类的重视,对少数类采用较大的惩罚因子,而对多数类采用较小的惩罚因子,但数据不均衡问题根本原因在于样本数量不均衡性,即提高少数类样本的分类准确率从样本的均衡化入手,使得分类超平面不会向少数类方向偏移。
1.3 点到超平面的距离
从图1可以看出,对分类结果有影响的是靠近分类边界的样本,而远离分类边界的样本对分类结果没什么影响,为了描述样本对最终的分类器的影响大小,定义点到分类超平面的距离。
定义1样本x到分类超平面的距离:

其中x0为样本x在超平面上的投影,w为超平面的法向量,||w||表示w的二阶范数,如图3所示。
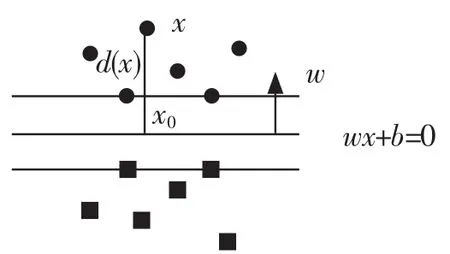
图3 点到超平面距离
对式(4)进行变形为:

由于x0是分类超平面上点,因此满足f(x0)= wx0+b=0,代入式(5)得

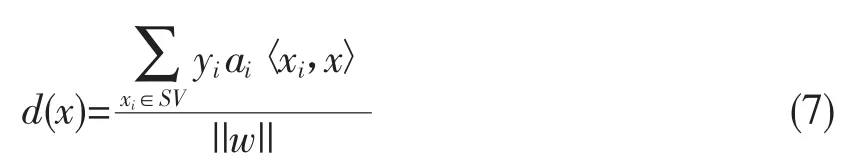
〈xi,x〉表示xi与x的内积。
对于线性不可分问题,样本x到分类超平面的距离为:
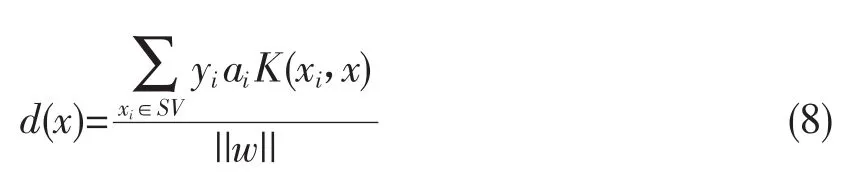
K(xi,x)是核函数,K(xi,yi)=〈φ(xi),φ(xj)〉。
样本x到分类超平面的距离d(x)的值可以是正也可以是负,d(x)为正数表示样本与类中心在分类超平面同侧,负数表示样本与类中心在分类超平面的相反侧,对于多数类样本若d(x)为负数则认为样本为噪声数据。
定义2类到分类超平面的距离D(ci)为类ci到分类超平面距离:

对于多数类,ni为属于类ci,且d(x)≥0的样本数;对于少数类ni为属于类ci的全部样本数量。
2 DSVM欠取样算法
在多数类样本中存在大量的重复信息或对分类无帮助的信息(如远离分类超平面的样本),这些冗余信息导致训练样本的不均衡性,进而导致分离器最终的分类性能。因此一种常用的方法就是通过一定的策略删除这些冗余信息,即欠采样方法,如DROP、CNN、聚类等算法,但这些方法在删除冗余信息的同时也会删除一些边界样本,本文提出基于样本到分类超平面距离的欠取样算法,算法过程描述如下:
Step 1针对训练数据集T用支持向量机进行训练,得到分类超平面f(x),法向量w,支持向量集合SV及每个支持向量对应系数ai;
Step 2依据式(7)或者式(8)(线性可分问题用式(7),线性不可分问题用式(8)计算样本到分类超平面的距离d(xj);
Step 3根据式(9)计算类到分类超平面的距离D(ci);
Step 4对于多数类样本,依据给定的控制参数a值删除d(x)>a*D(ci)的样本点,得到新的训练集T′;
Step 5对T′进行训练,如果分类效果达到理想状态,则得到最终的分类超平面和决策函数;否则,重新设定控制参数a,返回setp 4。
Step 6对新的少数类样本有插值法,增加样本;
控制参数a用来控制删除多数类样本的比例,其值依据少数类样本数量与多数类样本数量比值来确定,即,其中ni少数类样本数量,nj为多数类样本数量,k为常数。
3 实验及数据分析
3.1 实验数据选择
为简化过程本文实验数据采用人工生成方式,为观察不均衡数据对分类决策面的影响,随机产生两类均匀分布的不均衡样本,第一类样本为U([0,1]×[0,1]数量是200,第二类样本为U([0,1]×[1,2]数量是20。测试集同样采用均衡分布的人工数据第一类样本为U([0,1]×[0,1],第二类样本为U([0,1]×[1,2],两类样本各50个样本。
3.2 实验结果与分析
由于上面数据集是随机生成的,具有一定的偶然性,因此实验采用10次测试其结果。表1给出了10次实验不同的控制参数的实验结果,其中核函数采用多项式核函数,表1中数字为测试的准确率。
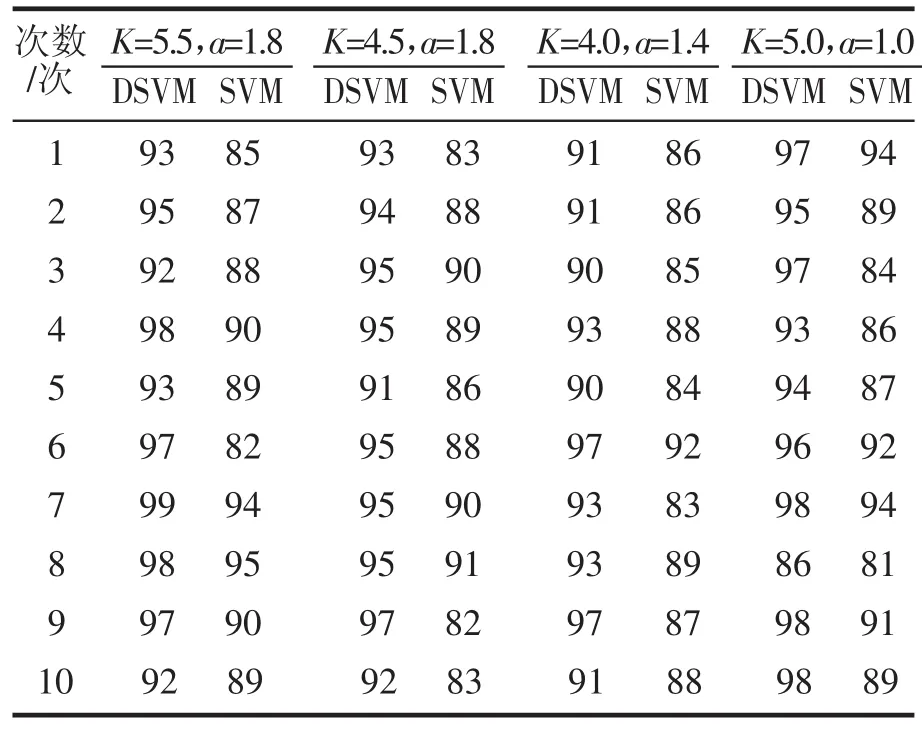
表1 DSVM与SVM的实验结果对比
从表1可以看到,随着K值的减小,多数类样本的数量也减少,在极限情况下(K=0时),问题转化为一类问题,导致多类样本信息丢失,分类准确率反而会下降,如表1中,K=3时,10次中就有两次准确率反而下降。图5是图4中相同数据经处理后的分类超平面分布的图,可以看到分类超平面向多数类倾斜。
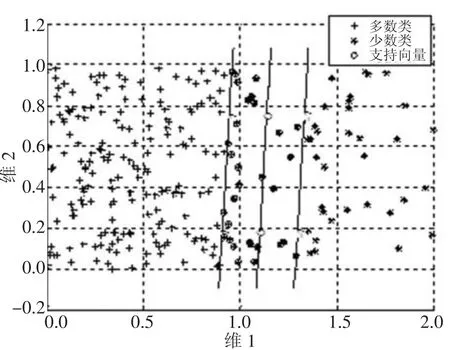
图4 原始分类图
4 结论
针对实际应用中训练样本不均衡的问题,本文根据支持向量机的特点,删除距离分类边界比较远的样本,同时对少数类样本利用SMOTE进行过取样,从一定程度上减少训练数据的不均衡程度,提高了分类准确率。但没有能从根本上解决不均衡数据集因为分类超平面的偏移而导致分类准确率低的问题,因此如何提取边界样本中有用信息,使得分类超平面向多数类方向偏移将是下阶段的主要工作。
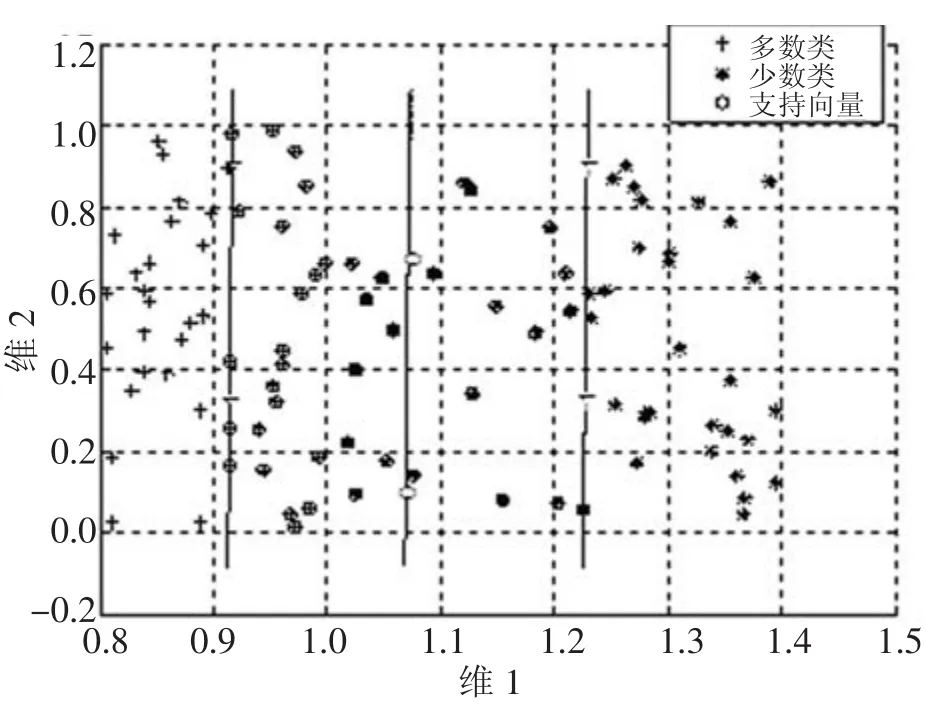
图5 DSVM下的分类图
[1]Vapnik V.The nature of statistical learning theory[M]. NewYokr:Springer-verlag,1995.
[2]Wang B X,Japkowicz N.Boosting support vector machines for imbalanced datasets[J].Lecture Notes in Computer Science,2008,4994:38-47.
[3]李雄飞,李 军,董元方,等.一种新的不平衡数据学习算法PCBoost[J].计算机学报,2012,35(2):202-209.
[4]李 鹏,王晓龙,刘远超.一种基于混合策略的失衡数据集分类方法[J].电子学报,2007,35(11):2161-2165.
[5]曾志强,吴 群,廖备水.一种基于核SMOTE的非平衡数据集分类方法[J].电子学报,2009,37(11):2489-2495.
[6]He H,Garcia E A.Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009,21(9):1263-1284.
[7]Chen B,Ma L,Hu J.An improved multi-label classification method based on SVMwith delicate decision boundary[J].International Journal of Innovative Computing,Information and Control,2010,6(4):1605-1614.
[8]楼晓俊,孙雨轩,刘海涛.聚类边界过采样不平衡数据分类方法[J].浙江大学学报:工学版,2013,47(6):944-950.
[9]陶新民,张冬梅,郝思媛,等.基于谱聚类欠取样的不均衡数据SVM算法[J].控制与决策,2012,27(12):1761-1768,1775.
[10]杨智明,彭 宇,彭喜元.基于支持向量机的不平衡数据集分类方法研究[J].仪器仪表学报,2009,30(5): 1094-1099.
[11]陶新民,童智靖,刘 玉.基于ODR和BSMOTE结合的不均衡数据SVM分类算法[J].控制与决策,2011,26 (10):1535-1541.
[12]吴 磊,房 斌,刁丽萍,等.融合过抽样和欠抽样的不平衡数据重抽样方法[J].计算机工程与应用,2013,49 (21):173-176,185.
[13]金 鑫,李玉鉴.不平衡支持向量机的惩罚因子选择方法[J].计算机工程与应用,2011,47(33):129-133.
(责任编辑:李堆淑)
An Algorithm for Imbalanced Dataset Based on Double SVM
ZHANG Yan
(College of Mathematics and Computer Application,Shangluo University,Shangluo 726000,Shaanxi)
In order to reduce the effect of imbalanced datacet on SVMclassification performance,a newunder-sampling algorithm based on the twice support vector machine is proposed for imbalanced data classification.For samples of majority class,this algorithm deletes the samples far from the classification hyperplane.And for samples of minority class,this algorithm use over-sampling algorithm to add newsamples.The method may resolve the problem of imbalanced dataset and improve the classification performance of SVM.Experiment results with artificial dataset showthe algorithm is effective for imbalanced dataset,especially for the minority class samples.
Support Vector Machine;imbalanced dataset;under-sampling;classification hyperplane
TP181
:A
:1674-0033(2014)04-0038-04
10.13440/j.slxy.1674-0033.2014.04.009
2014-03-21
商洛学院科研基金项目(13SKY024);商洛学院教育教学改革研究项目(10JYJX02011)
张 燕,女,陕西丹凤人,硕士,助教
