一种利用高斯函数的聚类算法
2014-07-13王祥斌邓伦治
王祥斌,杨 柳,邓伦治
(贵州师范大学数学与计算机科学学院,贵州贵阳550001)
0 引言
所谓聚类就是把一组个体按照相似性归纳成若干类别,即将数据集划分成若干个簇,使得同一个簇中的对象具有较高的邻近度(相似性),可以将簇中的数据对象作为一个整体来对待与使用,而簇与簇之间的对象邻近度(相似性)较低[1-4]。
许多聚类算法都在试图寻找一种很好的途径,来实现对大规模数据集进行聚类分析时获得理想的效果,但是都在一定的程度上存在着局限性。例如,经典的基于划分的k均值聚类算法(k-means)而言,需要事先给定出簇的数量,而且还只能发现超球状簇,这在很大程度上影响了此种聚类分析的准确性[5-6]。基于密度的聚类算法,因为其采用以数据集在某空间区域的稀疏程度来作为发现簇的依据,能够自动而非人为给定簇的数量,因此,能够发现任何形状的簇,越来越得到业界的关注。本文从传统的基于密度的带噪音的空间数据聚类算法(DBSCAN)入手,提出了一种改进的基于密度分布函数的聚类算法,继而给出相关算法的概念定义,重点是利用高斯函数来描述数据对象之间亲疏程度,最后,利用Iris数据集进行了相应的试验。试验结果证明:该算法能有效地提高聚类的效率。
1 传统的密度聚类—DBSCAN
传统的DBSCAN算法,其中心思想就是要在数据集中寻找被低密度区所分割出来的高密度局域,进而由所获得的高密度区的分布状况,就可以确定出结果中簇的数量。在此基础上,下文给出改进算法时需要用到的几个概念的定义[7-9]。
定义1 邻域:给定数据集D的一个任意对象p,p的邻域定义为以p点为圆心,以Eps为半径的圆内包含的所有点的集合,记为NEps(p),即其中,dist(p,q)表示D中两个对象p和q之间的距离。
定义2 密度:数据集D中某一对象p的邻域内所包含的点的数目称为该点p的密度,记为
定义3 核心点与非核心点:对于对象p∈D,给定一个密度阈值MinPts(MinPts∈Z)。如果有则称对象p为(Eps,MinPts)条件下的核心点,记为point_core;反之称为非核心点,记为non_point_core。
定义4 直接密度可达:给定(Eps,MinPts),如果对象p和q满足MinPts,则称对象p从对象q直接密度可达。
定义5 类:数据集D的非空集合C是一个类,当且仅当C满足如下条件:
(Ⅰ)对于数据集中的任意点p和q,若p∈C且q从p密度可达,则q∈C。
(Ⅱ)对于数据集中的任意点p和q,如果有p∈C和q∈C,则p和q是密度连接的。
在以上的叙述中,定义1~定义3确立了关于密度的概念。DBSCAN算法中以(Eps,MinPts)作为算法的参数确定一个密度阈值,把密度大于MinPts的对象视为核心点。在对数据集D进行一次扫描之后,确定出所有的核心点,所有密度可达的核心点即可以被合并成为簇,而边界点划归至最近的簇。不是核心点或者边界点的对象被视为噪声。值得注意的是,由于算法采用的是密度可达而不是中心距离的概念,所以DBSCAN所获得的簇可以是任意形状的。
DBSCAN算法也有着薄弱的方面,该算法对于密度区域反差较大的数据集的处理能力比较理想,但是对于密度区域反差不明显的数据集处理则不尽如人意。而面对密度区域反差不明显的数据集进行聚类的情况下,如何给定出合适的MinPts参数值比较困难。
2 改进的利用高斯函数的聚类(Gause-DBSCAN)
聚类分析算法按照对象在性质上的亲疏远近进行分类。为了使分类的结果比较合理,必须描述对象之间的亲疏远近的程度。这种亲疏远近的程度称之为邻近度(相似性)。通常地,描述对象之间的邻近度主要有距离和相似系数两个方面。目前,常用的对象邻近度度量的方法包括欧几里德距离、余弦相似性、Jaccard相似性、共享最近邻相似性(SNN)等[10-11]。
Gause-DBSCAN算法是在DBSCAN算法的基础上,对其进行改造。最大的特点是在算法中引入了密度分布函数的概念,并且采用了高斯函数来描述对象之间亲疏程度。
定义6 给定数据集D中的对象p和q,且q对p的影响函数记为:ρ(p,q)。该函数是由p和q之间的距离来决定的,这个距离的描述,采用了高斯函数。于是有

进一步地,给定k个数据对象D=(x1,x2,…,xk),可在数据对象p上定义出数据对象p的密度函数,即所有数据点的影响函数之和,记为Density(p),则有

其中,dist(p,i)是数据对象p和第i个近邻之间的欧氏距离。距离越小,意味着该对象的邻域越紧凑,密度自然也就越大。
算法思想:
步骤1:预处理数据集D。
步骤2:设定一个密度阈值MinPts和Eps,计算出每一个数据对象的密度,从而可以确定哪些对象是point_core,将这些数据对象存入队列point_core_queue。
步骤3:检查找出的所有point_core中是否存在相同的数据对象。若有的话,则只保留一个作为point_core。
步骤4:以队列point_core_queue中的point_core为种子位置,在Eps半径范围内,寻找其K最邻近结点(KNN),将找到的KNN加入至一个候选队列candidate_queue中。
步骤5:检查候选队列 candidate_queue。如果队列中出现某点 p,其密度函数满足条件Density(p)≥Density(point_core)×MinPts,则点p成为可能目标对象。
步骤6:若p不存在于point_core_queue队列中,则说明p与当前的point_core密切程度高,可以聚类;将该点p的KNN加入至队列candidate_queue,再次判断找到的新点密度函数满足条件Density(p)≥Density(point_core)×MinPts,直到无法扩展队列candidate_queue的成员为止。
步骤7:若p存在于point_core_queue队列中,则将p对应的点在point_core_queue做一个访问标记,使其不会再作为种子被访问到。同时将p归入当前找到的聚类中。
步骤8:当找到的点密度下降到核心点密度的密度阈值MinPts时,完成一轮搜索。反复执行步骤5~步骤7,直到候选队列candidate_queue为空结束。
步骤9:从队列point_core_queue中取出下一个point_core。反复执行步骤4~步骤8,直到队列point_core_queue为空结束,即该算法完成。
3 测试及评价
对算法Gause-DBSCAN的性能进行测试,并将测试结果与常见的聚类算法进行比较。算法测试是在一台普通PC机上进行的。该机器的配置为DualCore AMD Athlon 64 X2 5000+CPU,内存2 G、500 G硬盘,算法采用C#语言编程环境实现。测试数据集使用了Iris数据集(也称鸢尾花卉数据集)。Iris数据集是150个关于3种鸢尾花的生物统计数据[12-13]。试验结果如表1所示。

表1 Gause-DBSCAN聚类试验结果
两种算法的执行效果如图1和图2所示,两种算法的效率比较见图3。
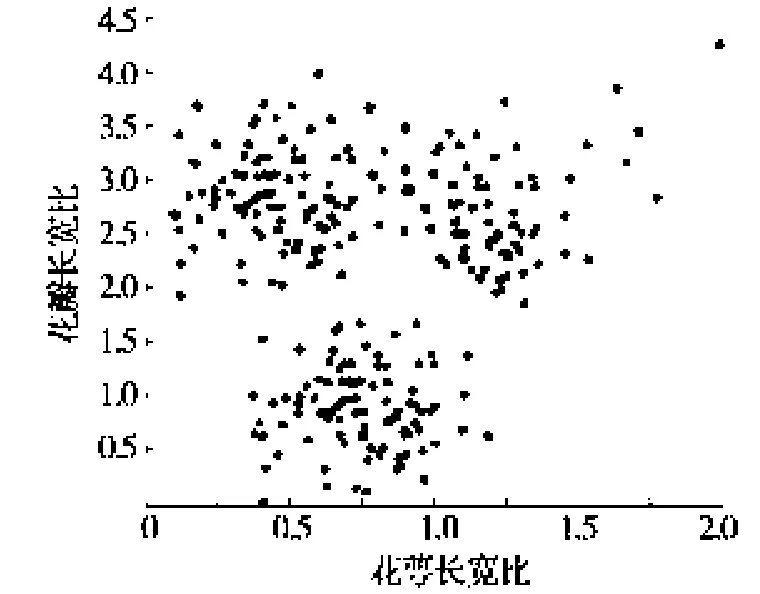
图1 DBSCAN试验结果

图2 Gause-DBSCAN试验结果
传统的DBSCAN算法对具有N个点的数据集,其算法的时间复杂度为O(N2);在建立空间索引的情况下,其复杂度为 O(NlogN)[5]。而改进后的 Gause-DBSCAN算法因为其邻域查询的时间复杂度远小于O(NlogN),因此算法总体的时间复杂度也小于O(NlogN)。以上的试验结果也表明:改进后的Gause-DBSCAN算法的执行效率要高于传统的DBSCAN算法。

图3 两种算法执行效率的试验结果
4 结束语
聚类是研究数据挖掘算法的重要方面之一。在研究传统的DBSCAN算法的基础上,本文提出了一种改进的同样基于密度的聚类算法Gause-DBSCAN。算法从最高密度的对象着手,考察周围对象的密度分布状况,为了提高准确性,引入了影响函数和密度函数的概念。并在此基础上进行了数据试验,试验结果表明本算法可以实现较好的聚类效果和效率。今后的工作是研究如何更加合理的设定(Eps,MinPts)这两个参数的值,并且研究如何进一步缩短算法的执行时间。
[1]Mac Q J.Some Methods for Classification and Analysis of Multivariate Observations[C]∥Proc of Fifth BerkeleySymposium on Math.Stat and Prob:University of California Press,1967:281-297.
[2]Christian M,Diem H.Clustering by Kernel Density[J].Computational Economics,2007,29(2):199-212.
[3]Nasibov E N,Ulutagay G.Robustness of Density-based Clustering Methods with Various Neighborhood Relations[J].Fuzzy Sets and Systems,2009,160(24):3601-3615.
[4]于永玲,李向,宗思生.考虑空间格局的谱聚类算法及其应用[J].河南科技大学学报:自然科学版,2013,34(5):101-104.
[5]Tan P N,Steinbach M.数据挖掘导论[M].范明,范宏建,译.北京:人民邮电出版社,2006.
[6]Bicici E,Yuret D.Locally Scaled Density Based Clustering[C]//The 8th International Conference on Adaptive and Natural Computing Algorithms.Berlin:Springer-Verlag,2007:739-748.
[7]Parsons L,Haque E,Liu H.Subspace Clustering for High Dimensional Data:A Review[J].Sigkdd Explorations,2004,6(1):90-105.
[8]赵杰,杨柳.聚类分析算法DBSCAN的改进与实现[J].微电子学与计算机,2009,26(11):189-192.
[9]许虎寅,王治和.一种改进的基于密度的聚类算法[J].微电子学与计算机,2012,29(2):44-46.
[10]Zhou S G,Zhou A Y,Jin W.Fdbscan:A Fast Dbscan Algorithm[J].Journal of Software,2000,11(6):735-744.
[11]Chen N,Chen A,Zhou L X.An Incremental Grid Density Based Clustering Algorithm[J].Journal of Software,2002,13(1):1-7.
[12]Iris Data Set(UCI)[DB/OL].[2012-09-10].http://www.datatang.com/data/551.
[13]张琳,陈燕,汲业,等.一种基于密度的K-means算法研究[J].计算机应用研究,2011,28(11):4071-4085.
