基于改进停机准则的SMO算法
2014-07-07韩顺成马小晴陈进东潘丰
韩顺成,马小晴,陈进东,潘丰
江南大学轻工过程先进控制教育部重点实验室,江苏无锡 214122
◎理论研究、研发设计◎
基于改进停机准则的SMO算法
韩顺成,马小晴,陈进东,潘丰
江南大学轻工过程先进控制教育部重点实验室,江苏无锡 214122
在序列最小优化(Sequential Minimal Optimization,SMO)算法训练过程中,采用标准的KKT(Karush-Kuhn-Tucker)条件作为停机准则会导致训练后期速度下降。由最优化理论可知,当对偶间隙为零时,凸二次优化问题同样可以取得全局最优解。因此本文将对偶间隙与标准KKT条件同时作为SMO算法的停机准则,从而提出了改进停机准则的SMO算法。在保证训练精度的情况下,提高了SMO算法的训练速度。通过对一维和二维函数的两个仿真实验,验证了改进SMO算法的有效性。
支持向量机回归;序列最小优化算法;对偶间隙;KKT条件;停机准则
1 引言
支持向量机(Support Vector Machine,SVM)由V.Vapnik等人提出,是一种以统计学理论、结构风险最小原则和Wolfe对偶化理论为基础的机器学习方法[1]。目前SVM已被广泛应用于模式识别、回归估计、概率密度估计等各个领域。SVM可分为支持向量分类(Support Vector Classification,SVC)和支持向量回归(Support Vector Regression,SVR)[2]。
常见的SVM算法有选块算法、分解算法、SMO算法等,其中Platt提出的SMO算法[3]是目前SVM处理大规模数据较为有效的训练方法。SMO算法起初主要用于模式分类问题,后来得到扩展并应用于回归问题,本文主要针对SMO算法在SVR训练中的问题展开。
在SVR训练过程中,SMO算法一般采用KKT条件作为停机准则[4]。经研究发现,采用KKT条件作为停机准则,SMO算法在训练刚开始时目标函数变化很快,但训练后期则变化缓慢,从而导致了训练的速度下降[5-6]。由最优化理论可知:在对偶间隙为零时,凸二次优化问题也将取得全局最优解。因此,本文从停机准则出发,将对偶间隙与标准KKT条件同时使用作为SMO算法的停机准则。在训练后期,当对偶间隙小于设定精度时,算法即可中止,从而减少后期的迭代次数,解决SVR训练后期训练速度下降的问题。
2 支持向量机回归和KKT停机准则
SVR可表示为对给定的训练集:T={(xi,yi),i=1,2,…,l},xi∈RN,和yi∈R,非线性映射Φ将数据xi映射到高维特征空间F,可构造非线性回归函数[7]:

通过求解优化函数(1),可以得到w和b。
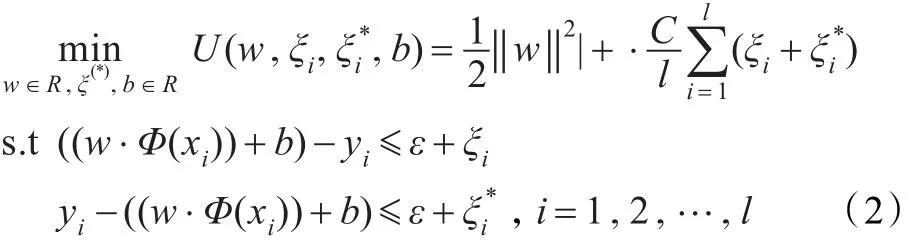
式中,C为惩罚系数;l为训练集T中样本个数;ε为不敏感系数;ξ、ξ*为松弛变量的上限与下限。为了便于求解上述优化函数,将式(2)转化为相应的对偶问题:
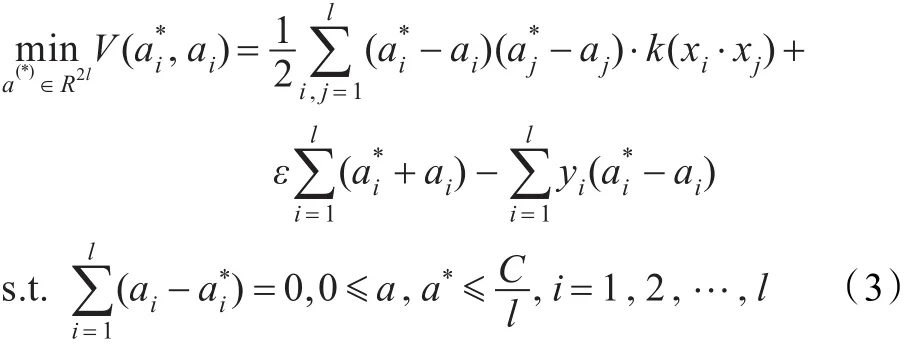
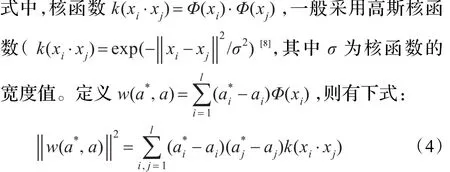
引入拉格朗日乘子,则对偶问题(3)的最优问题求解可转化为:
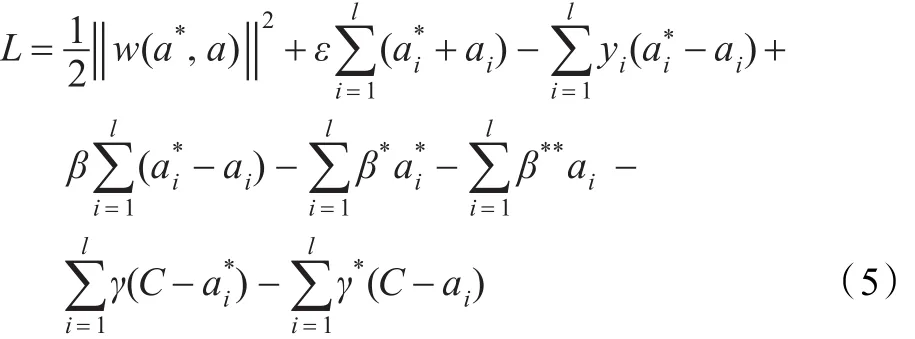
式中,β,β*,β**,γ和γ*为相应的拉格朗日乘子。式(5)可看做关于ai、的函数,分别对ai、依次求导,并令其为0,则相应的KKT条件可表示为:
KKT条件是判断优化函数取最优解的重要判定条件,也是算法终止的标志。SMO算法一般采用式(7)所示的KKT条件来判断算法是否结束。
3 算法设计与实现
3.1 对偶间隙
对偶间隙用来表述原问题与对偶问题的目标函数值的关系。对于原始问题和对偶问题分别有最优解的问题,可以通过强对偶定理来限定。
强对偶定理[7,9]:考虑连续可微的凸最优化问题
式中,f和ci都是连续可微的凸函数,若原始问题和对偶问题分别有可行解,则这两个可行解分别为原始问题和对偶问题的最优解的充要条件是它们相对应的原始问题和对偶问题的函数值相等。
由强对偶定理可知,对于原始问题:
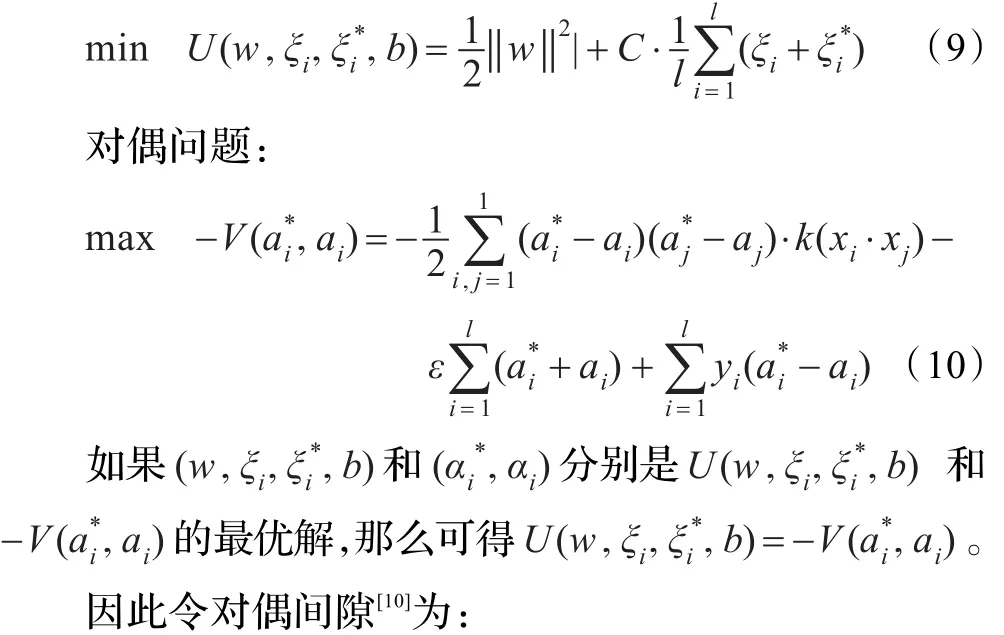
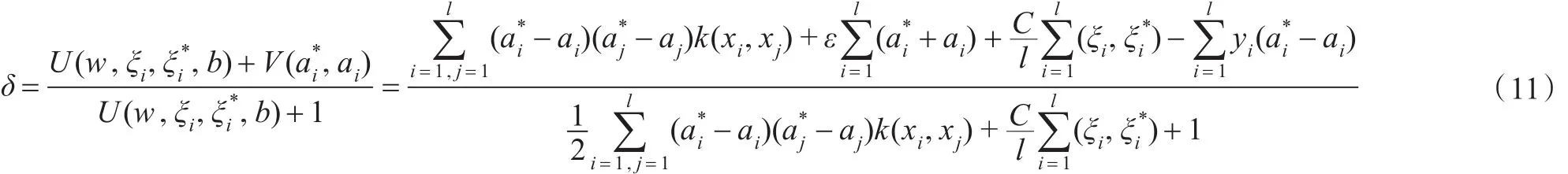
由此可以看出,当对偶间隙δ为零时,原始问题和对偶问题都取得最优解,所以对偶间隙可以作为一个有用的停机准则。在实际应用中,对偶间隙并不一定要为零时,SMO算法才终止,只需事先设定值μ,当δ小于μ时,算法即可中止。
3.2 SMO算法
SMO算法是分解算法[11]工作集个数等于2的特殊情形,即SMO算法把一个大的优化问题分解成一系列只含两个变量的优化问题。因此SMO算法主要包括两个初始训练点的选取、两个变量优化问题的解析求解。
首先,两个训练点的选取。SMO算法采用两层循环(外部、内部)的启发式策略选择训练点。
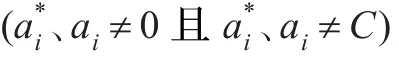
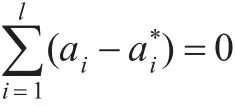
3.3 改进的SMO算法
由于样本的个数直接影响算法的训练速度,随着样本数目的增多,采用标准的KKT停机准则会导致迭代后期训练速度下降。停机准则标志SMO算法的终止,是影响训练时间的关键因素。由强对偶定理可知当对偶间隙为零时,凸二次优化问题也取得全局最优解,因此可以将对偶间隙作为一个检验算法中止的准则,但不能定性地直接将对偶间隙应用到停机准则中。
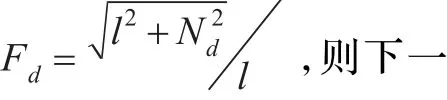
综上所述,基于改进停机准则的SMO算法的训练步骤:
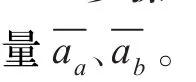
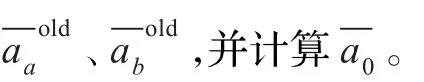
步骤4计算相应Fd,按照相应的Fd的值判断是否计算δ。
步骤5当所有样本均满足式(7)的KKT条件,或δ小于给定的精度,结束循环。
步骤6如果不满足KKT条件或δ大于给定的精度,则Nd←Nd+1,转向步骤2。
4 实验仿真
为了验证改进SMO算法的性能,分别选取一维和二维样本数据进行训练和测试。仿真计算机为Intel®Celeron®CPUE330,1 024 MB内存,仿真软件为MALABR2010a。
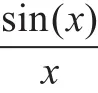

表1 算法检测结果

表2 一维MSMO与SMO的比较
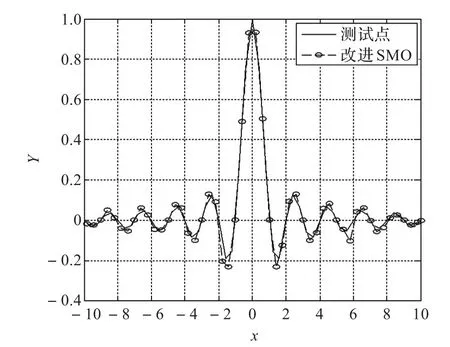
图1 MSMO对测试样本的逼近
训练精度表示在实验中采用真实目标函数与逼近值的均方偏差,由下式计算。
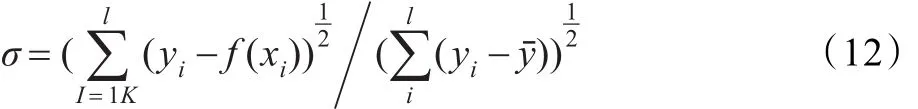
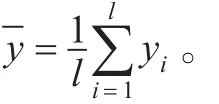
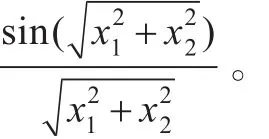
通过仿真结果可以看出,MSMO算法比SMO算法减少了迭代次数,提高了训练速度。且随着样本数目的增加,训练时间的缩短更为明显,一维和二维数据样本的情况相似,这主要是因为MSMO算法改进了停机条件,以对偶间隙来确定算法的终止条件,减小了优化迭代的次数,从而加快了算法训练速度。
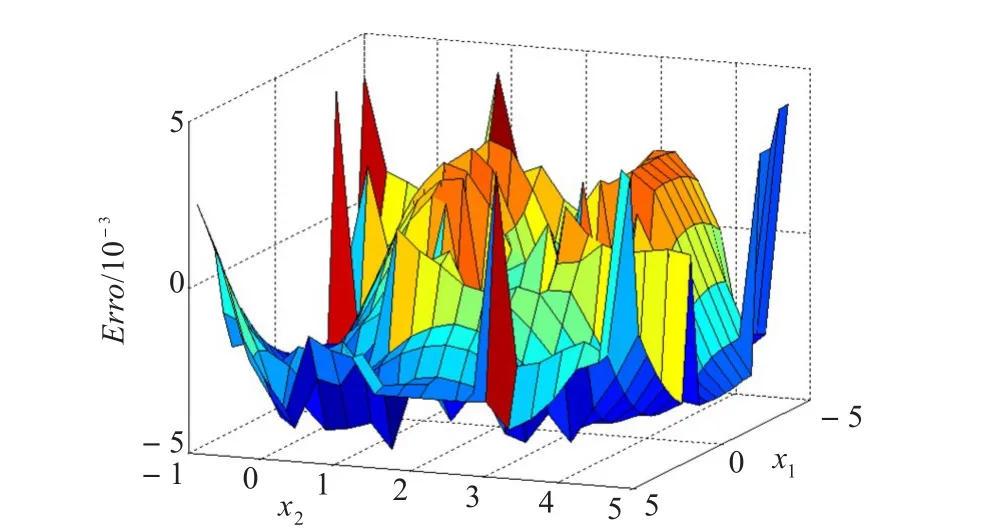
图2 MSMO对测试样本的逼近误差

表3 二维MSMO与SMO的比较
5 结论
SMO是目前SVM处理大规模数据较为有效的方法,但是采用KKT条件作为停机准则导致这种算法在迭代优化的后期训练速度减慢。针对这个问题,本文对SMO的停机准则进行了改进,提出了一种改进的SMO算法。仿真结果表明,这种改进的优化算法在保证预测精度的前提下,大大减少了迭代次数,提高了SVM训练的速度。对今后SVM处理大规模数据,提高算法运算收敛速度具有一定参考价值。
[1]Hearst M.Support Vector Machines[J].IEEE Transaction on Intelligent Systems,1998:13(4):18-28.
[2]Vapnik V N.Statistical learning theory[M].New York:Wiley,1998.
[3]Platt J C.Support Vector Machines[M]//Schölkopf B,Burges C,Smola A.Fast training of support vector machines using sequential minimal optimization.Advances in Kernel Methods.[S.l.]:M IT-Press,1998.
[4]Lin C J.A formal analysis of stopping criteria of decomposition methods for support vector machines[J].IEEE Transactions on Neural Networks,2002,13(5):1045-1052.
[5]Lin Yih-Lon,Jeng Jyh-Horng.Three-parameter sequential minimal optimization for support[J].Neurocomputing,2011,74:3467-3475.
[6]Lin Zuo,Zhang Yi.An improved working sets election for SMO-type decomposition method[J].Real World Applications 2010,17(11):3834-3841.
[7]邓乃扬,田英杰.数据挖掘中的新方法-支持向量机[M].北京:科学出版社,2004.
[8]Smola A J.Learning with Kernels[D].GMD,Birlinghoven,Germany,1998.
[9]Takahashi N,Guo J,Nishi T.Global Convergence of SMO algorithm for Support Vector Rgression[J].IEEE Trans on Neural Networks,2008,19(6):971-982.
[10]Burachik R S,Rubinov A M.On the absence of duality gap for lagrange-type function[J].Industrial Management and Optim,2005,24(1):33-38.
[11]Chen P-H,Fan R-E,Lin C-J.A study on SMO-type decomposition methods for support vector machines[J]. IEEE Trans on Neural Netw rok,2006,17(12):893-908.
[12]Flake G W,Law rence S.Efficient SVM regression training with SMO[J].Machine Learning,2002,46(7):271-290.
HAN Shuncheng,MA Xiaoqing,CHEN Jindong,PAN Feng
Key Laboratory of Advanced Process Control for Light Industry(Ministry of Education),Jiangnan University,Wuxi,Jiangsu 214122,China
In SMO training process,standard KKT stopping criteria w ill lead to training speed declining along with training progress.According to the optimum theory,if the dual gap is zero,convex quadratic optimization problem will also obtain global optimal solution.Therefore,an improved stopping criteria of SMO is proposed in this paper,it combines the duality gap and standard KKT condition as the stopping criteria.This algorithm can improve the training speed without training accuracy decrease.Two cases experimental simulating results corroborate the efficiency of this algorithm.
Support Vector Regression;Sequential Minimal Optimization(SMO);duality gap;Karush-Kuhn-Tucker (KKT);Stopping Criteria
A
TP301.6
10.3778/j.issn.1002-8331.1208-0471
HAN Shuncheng,MA Xiaoqing,CHEN Jindong,et al.Improved stopping criteria based SMO algorithm.Computer Engineering and Applications,2014,50(16):31-34.
国家高技术研究发展计划(863)(No.2009AA 05Z203);江苏高校优势学科建设工程资助项目。
韩顺成(1987—),男,硕士研究生,研究方向为工业过程的建模与优化控制;潘丰(1963—),男,教授,博导,研究领域为过程控制、建模等研究。E-mail:hanshuncheng@126.com
2012-09-04
2012-10-26
1002-8331(2014)16-0031-04
CNKI网络优先出版:2012-11-21,http://www.cnki.net/kcm s/detail/11.2127.TP.20121121.1103.042.htm l
