基于膨胀系数的正则表达式分组算法
2014-07-03王美阳唐学文杨正益
王美阳,唐学文,杨正益
(1.重庆大学计算机学院,重庆 400030;2.重庆大学信息与网络管理中心,重庆 400030;3.重庆大学软件学院,重庆 401331)
0 引言
随着网络技术的迅猛发展以及网络应用的复杂多样,深度包检测(Deep Packet Inspection,DPI)在防火墙、入侵检测系统、网络审计等网络安全领域的应用越来越广泛。正则表达式(Regular Expression,RE)[1-2]能够灵活高效地描述字符串,逐渐取代精确字符串匹配,成为深度包检测的重要手段之一,在开源入侵检测系统Snort、Bro以及众多网络安全产品中都得到广泛应用。
正则表达式匹配引擎的工作原理是将正则表达式转化为有限状态机(Finite State Machine,FSM),然后利用有限状态机对检测内容进行扫描。正则表达式匹配有2种实现方式,一种是确定性有限状态自动机(Deterministic Finite Automata,DFA),另一种是非确定性有限状态自动机(Non-deterministic Finite state Automata,NFA)。NFA的特点是存储空间高效,状态转移路径可以有多条,匹配的时间效率低下;DFA的特点是状态转移路径最多只有一条,匹配的时间效率高,但当规则数量增多时,DFA的状态数量呈指数增长,存储空间需求剧增,导致DFA难以实际使用。
针对正则表达式匹配时存在的状态空间爆炸问题,近些年来研究者提出了多种基于DFA的存储高效的正则表达式匹配算法,来降低DFA的存储空间需求。有些研究者提出的 D2FA[3]、CD2FA[4]、δFA[5]和XFA[6]等方法都是通过消除冗余的DFA状态转移,能够取得良好的压缩效果,但无法减少DFA的状态数。Yu等人[7]首次提出DFA分组算法(下文称之为Yu分组算法),但搜索策略存在可改进之处。Becchi等人[8]提出一种兼顾 DFA和NFA两者优点的混合自动机引擎。李鲲鹏等人[9]提出基于布鲁姆过滤器的正则表达式匹配算法,有效节约存储空间,提高匹配速度,但带来一定的误匹配率。徐乾等人[10]提出一种选择性分群算法来减少DFA状态数,但算法中的调整因子难以合理设置。王磊[11]、吴鸿伟[12]等人设计了基于多GPU的正则表达式匹配引擎,提高了匹配性能,但增加了硬件成本。还有研究者设计并改进基于FPGA[13-16]架构的正则表达式匹配技术,但FPGA时钟频率低于通用处理器,可伸缩性不佳。
本文在Yu算法的基础上,提出一种改进型正则表达式分组算法——IGA(Improved Grouping Algorithm)算法,采用更加合理的启发搜索策略,进一步减少DFA的状态数目,从而降低DFA所占存储空间。
1 Yu算法
Yu等人首先提出了正则表达式之间的相互作用这一概念,利用这一概念构造正则表达式集合的关系图,再对正则表达式进行分组。
定义1[7]对于正则表达式R1和R2,若#DFA,则R1与R2之间相互作用,其中#DFA(X)表示正则表达式X转换为DFA后的状态数,R1|R2表示正则表达式R1与R2合并之后的DFA状态数。
Yu算法的大致流程如下:
1)计算正则表达式集合中两两之间的相互作用关系,构造正则表达式集合的作用关系图G。
2)选择一条与其它正则表达式作用最小的正则表达式,加入到分组NG中。
3)选择一条与分组NG连接数最少的正则表达式R。
4)将R与NG合并转化为DFA,如果此DFA大小超过阈值,就跳转到步骤5),否则将R加入到NG中。
5)对G中所有的正则表达式是否检查完毕?若是则跳转到步骤3),否则NG分组完毕。
6)G中是否还有未分组的正则表达式?若是则跳转到步骤2),否则算法完毕。
2 改进型分组算法
本文在膨胀系数(Expansion Coefficient,EC)这一概念的基础上,提出改进型分组算法——IGA算法来改进Yu算法,更有效地降低DFA所占用的存储空间。
2.1 膨胀系数
在Yu算法中的定义1仅仅根据2条正则表达式合并之后与合并之前的状态数比较结果而得到相互作用关系,并没有描述2条正则表达式合并之后与合并之前的状态膨胀的剧烈程度,即没有充分利用正则表达式之间的关系所蕴含的信息。为充分利用正则表达式之间的相互作用关系信息来构造正则表达式集合的作用关系图,给出膨胀系数这一定义。
定义2 对于正则表达式R1、R2,膨胀系数计算公式如下:

当膨胀系数EC>1时,表示R1、R2相互作用。如果EC的值越大,说明2条正则表达式合并之后与合并之前相比,状态数膨胀越厉害,因此需要尽量将R1与R2隔离,尽量不要将它们分配到同一个DFA分组里,从而减少总状态数目。当膨胀系数EC<1时表示R1、R2不相互作用,可以将R1、R2放在同一个分组。当膨胀系数EC=1时表示R1、R2合并之后的状态数恰好等于合并之前的状态数,不过这种情况出现的可能性很小。
2.2 IGA 算法
在膨胀系数这一概念的基础上,本文设计改进型分组算法——IGA算法,伪代码如下:
算法输入:规模为n的正则表达式集合R
算法输出:集合 R的分组结果 R={g1,g2,g3,…,gk}


IGA算法中的SIZE_LIMIT为各个分组DFA状态数的阈值。第1行代码的作用是构建以膨胀系数为权值的关系图。第3~5行代码主要初始化新分组并选择最初的2条正则表达式。第7~21行代码的主要功能是选择使新分组膨胀系数最小的正则表达式,判断分组的状态数是否超过设置的阈值,并更新新分组与集合中其他正则表达式之间的膨胀系数。
为更直观地描述算法,假设有包含5条正则表达式的集合,计算正则表达式之间的膨胀系数,构造相互作用关系图,如图1所示。

图1 获得分组的双亲节点
选择膨胀系数最小的2个顶点(即表达式b和e)作为group 0的双亲,从图G中删除b、e两个顶点,这样就得到图2。

图2 获得分组的孩子节点
选择与group 0顶点相关联的顶点并且膨胀系数最小的顶点c,从图G中删除顶点c,增加到group 0中,不断重复此过程,直到group 0再添加任意一个膨胀系数最小的顶点会超过SIZE_LIMIT。如果group 0的状态数超过SIZE_LIMIT,则建立一个新的group 1,再向group 1中添加顶点。如此重复图1与图2所示的过程,直到所有顶点都分组完毕。
3 实验结果与分析
实验采用的硬件配置为Intel Dual-Core 2.5 GHz CPU,4 GB内存,操作系统为CentOS 6.2。正则表达式转换为DFA使用的是开源软件——由Becchi开发的Regex 1.4.1,并用 C++语言实现了 Yu算法与IGA算法。为了避免规则集上的不同实验效果的影响,在不同的公开规则集上比较IGA算法的分组结果与Yu算法的分组结果。规则集分别源自开源软件L7-filter、Snort和Bro的规则各100条。表1、表2和表3分别给出了上述3个规则集的实验结果。

表1 L7_filter分组状况对比
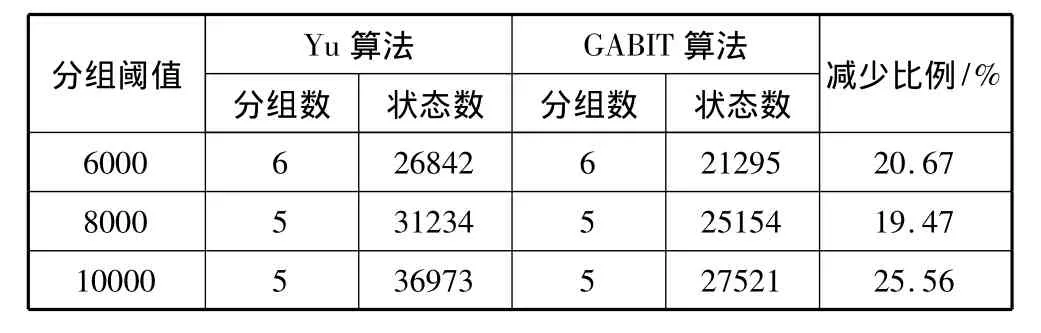
表2 Snort分组状况对比

表3 Bro分组状况对比
从表1、表2和表3的对比结果可以发现,在相同分组数的情况下,IGA算法比Yu算法的总状态数平均能够减少25%。DFA总状态数减少,能够减少存储DFA的内存空间,降低匹配算法的空间复杂度。
4 结束语
与Yu算法相比,IGA算法主要有以下改进:
1)IGA算法使用膨胀系数来计算表示正则表达式之间的关系,而Yu算法之间简单地依据正则表达式合并前后状态数是否增大来表示正则表达式之间的关系。
2)IGA算法将正则表达式加入新分组的选择标准是膨胀系数最小,而Yu算法的选择标准是边连接数最少。
3)IGA算法每次更新新分组与其他正则表达式之间的膨胀系数,而Yu算法不会更新正则表达式之间的连接数。
实验表明,与Yu算法相比,IGA算法在分组数目相同的情况下,总的DFA状态数平均减少25%以上,降低了匹配算法的空间复杂度。下一步工作是研究高速网络环境下如何利用网络流的局部性来实现DFA分组调度算法,从而提高正则表达式匹配引擎的吞吐量。
[1] 姚远,刘鹏,单征,等.面向存储的正则表达式匹配算法综述[J].计算机应用,2009,29(12):3171-3173.
[2] 邓凯元,姜磊.正则表达式匹配引擎性能分析[J].计算机与现代化,2011(7):105-107.
[3] Kumar S,Dharmapurikar S,Yu Fang,et al.Algorithms toaccelerate multiple regular expressions matching for deep packet inspection[C]//Proceedings of the 2006 ACM Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications.2006:339-350.
[4] Kumar S,Turner J,Williams J.Advanced algorithms for fast and scalable deep packet inspection[C]//Proceedings of the 2006 ACM/IEEE Symposium on Architecture for Networking and Communications Systems.2006:81-92.
[5] Ficara D,Giordano S,Procissi G,et al.An improved DFA for fast regular expression matching[J].Computer Communication Review,2008,38(5):29-40.
[6] Smith R,Estan C,Jha S.XFA:Faster signature matching with extended automata[C]//Proceedings of the 2008 IEEE Symposium on Security and Privacy.2008:187-201.
[7] Yu Fang,Chen Zhifeng,Diao Yanlei,et al.Fast andmemory-efficient regularexpression matchingfordeep packet inspection[C]//Proceedings of the 2006 ACM/IEEE Symposium on Architecture for Networking and Communications Systems.2006:93-102.
[8] Becchi M,Crowley P.A hybrid finite automaton for practical deep packet inspection[C]//Proceedings of the 2007 ACM Conference on Emerging Network Experiment and Technology.2007.
[9] 李鲲鹏,兰巨龙,李印海.基于Bloom filter的高效正则表达式匹配算法[J].计算机应用研究,2012,29(3):950-954.
[10] 徐乾,鄂跃鹏,葛敬国,等.深度包检测中一种高效的正则表达式压缩算法[J].软件学报,2009,20(8):2214-2226.
[11] 王磊,陈曙晖,苏金树,等.深度报文检测中基于GPU的正则表达式匹配引擎[J].计算机应用研究,2010,27(11):4324-4327.
[12] 吴鸿伟,郭东辉,庄进发,等.基于多GPU的正则表达式匹配技术[J].华中科技大学学报(自然科学版),2013,41(1):51-55.
[13] Mitra A,Najjar W,Bhuyan L.Compiling PCRE to FPGA for accelerating SNORT IDS[C]//Proceedings of the 2007 ACM/IEEE Symposium on Architecture for Networking and Communications Systems.2007:127-136.
[14] Lee J,Hwang S H,Park N.A high performance NIDS using FPGA-based regular expression matching[C]//Proceedings of the 2007 ACM Symposium on Applied Computing.2007:1187-1191.
[15] Dan Lo C,Tai Yi-Gang,Psarris K.Hardware implementation for network intrusion detection rules with regular expression support[C]//Proceedings of the 2008 ACM Symposium on Applied Computing.2008:1535-1539.
[16] 唐球,姜磊,谭建龙,等.FPGA实现的正则表达式匹配性能分析[J].小型微型计算机系统,2012,33(11):2405-2409.
