中文产品评论结构化引擎
2014-07-03刘红岩
杨 慧,刘红岩,何 军
(1.中国电子科技集团公司第十五研究所航空信息系统部,北京 100083;2.清华大学管理科学与工程系,北京 100084;3.中国人民大学信息学院,北京 100872)
0 引言
随着Internet的发展和普及,Web已经在很大程度上改变了消费者反馈观点的途径。如今,产品使用者可以通过商家的网站、网络论坛、BBS,以及Blog发表对于产品性能的看法。人们通常称这类数据为用户生成数据(user generated content或者user generated media)。这些网上评论为市场研究提供了充足且宝贵的信息资源。潜在消费者也可以此作为重要的参考依据。但由于网络信息分散、海量、非结构化的特点,给评论信息的收集、统计带来很大的困难。基于此产生了意见挖掘。
本文的工作是进行意见挖掘。研究对象是中文产品评论,研究目标是自动收集网络上关于用户指定产品的评论,对这些评论进行结构化,即按照产品特征组织评论,并判断对应特征的意见的感情色彩。
本文的贡献是对中文语种的非领域相关的评论结构化的第一次尝试,对于其所面临的问题给出解决方法。
1 产品结构化概述
产品特征结构化由Liu等人在文献[1]中提出,旨在发现用户对于产品某些细节的喜好,通常是句子级别的操作。例如对于句子“保湿效果持久”,这条评论关注的是产品的“保湿效果”这一细节,并发表了“持久”这一意见,通过上下文可了解到,“持久”在这里是褒义评论。将评论关注的细节定义为“特征”(feature),用户对于“特征”的评论,定义为“意见”(opinion)。相关的有些算法还会在此基础上对各个特征进行汇总,归纳出一个摘要。在Liu的论文发表之后,很多研究人员开始关注这个领域,其中文献[2-9]在该领域都进行了不同程度的探索。国内在该领域也有一些研究成果[10-14],主要集中在对某特定类别中文产品意见的挖掘研究。
产品评论结构化的相关研究主要着重于2个议题上:1)特征、意见抽取;2)意见极性判断。对于上面举的例子,找到用户关注的细节即产品特征“保湿效果”抽取的过程称为特征抽取,找到与特征“保湿效果”相关联的意见“持久”即是意见抽取,判断“持久”的感情色彩的过程,称为极性判断。
目前对消费者评论的特征抽取的方式有有监督(supervised)以及无监督(unsupervised)2 种方式[4]。无监督的方式属于无人工介入,不需要有人为的标注语料库作为训练集,因此有较好的通用性以及便利性,可以适用于每一种产品,不需花太多时间就能够套用到不同种类产品上,缺点是正确率可能较差。文献[2,4]中的特征抽取方法都属于无监督抽取方法。有监督的方法需要有人工标注的数据作为它的训练集,由于有一些卷标必须要人工标记,无法由程序完成,因此需要人为介入。不同种类的产品就必须要标注不同的训练集,因此会相当耗费时间,无法同时适用所有种类的产品。文献[1,6]提出用有监督方法抽取用户评论中的特征以及意见。
opinion是表达对于feature的意见,通常都是以形容词的方式呈现,但也有不少的opinion是以动词或是副词等其它形式呈现。除了必须抽取不同词性的opinion外,也必须判断opinion的极性方向性,以便将正面以及负面的评价区分。文献[2,4]中介绍了opinion的抽取方法。
opinion的极性判别在opinion处理上一直是相当重要的议题,文献[2-3,15-17]在这方面做了很多工作。判断极性可以让系统对于opinion进行分类,对分类整理后提供给用户,从而方便用户能够更快速地得到想要的信息,不用一条一条地查看。opinion极性判断的困难在于,虽然人类知道这个opinion是正面或是负面,但是人工列举出所有的极性opinion的工作量很大,机器由于不了解自然语言而无法自动完成。自动处理语义极性成为一个重要的研究课题。
2 中文产品评论结构化引擎体系结构
Review Search的系统结构如图1所示。系统根据用户输入的产品名称返回对网络上关于这一产品的评论的结构化结果。本文的工作主要集中在“产品结构化系统”中。处理的数据为网络中关于某一产品的网页集合,网页通过商业搜索引擎接口得到(如Google API)。网页经过去噪后,送到“评论识别”模块,用于识别出包含评论的网页。将识别出的评论,进行“特征、意见抽取”。经过特征、意见抽取,得到一个特征与意见相关联的结构FeatureList。接下来判断FeatureList的感情色彩,这一工作由“极性判断”模块通过极性聚类的方法完成。最后返回用户依据产品特征、意见、极性组织的结构化信息。在下面的章节中,将陆续介绍相应模块。

图1 引擎体系结构
3 中文产品评论结构化核心算法
3.1 问题描述
定义1 产品 P 的评论集 R=(r1,r2,...,rm):其中ri为集合中的一条评论,一般情况下评论以用户来区分,即每个用户发表的评论记为ri。
定义2 评论发表人Holder:即R中ri的发表人。
通常情况下意见可以是关于任何事物的,比如人、组织、事件、电影等。本文中的意见为关于某个商品的意见,因此用“product”来指代评论的对象实体。product可能会有一些组成部件(components),也可能有一些属性(attributes)。这样product就可以得到一个关于其组成部分和属性的层次结构。例如,产品product(汽车),包含组件 components(发动机,轮胎等),具有性质 attributes(百公里能耗,启动性等)。下面给出形式化定义。
定义3 Product:Product(缩写为P)是一个评论对象实体。其关联一个集合P:(C∪A),C为P的组成部分集合,A为P的属性集合。
定义4 特征feature:为了简化后续的讨论,用feature(缩写为 f)来代表组件与属性的集合,即feature=:component∪attribute。
定义5 显性特征(explicit feature)与隐性特征(implicit feature):如果f在评论R中出现了,就定义为显性特征,如果没有出现在R中就定义为隐性特征。
定义6 意见opinion:opinion(缩写为o)为评论R中关于特征f的意见。
定义7 极性polarity:极性即评论的感情色彩,通常分为褒义(正向,positive)和贬义(负向,negative)。
定义8 上下文相关意见context dependent opinion与上下文无关意见context independent opinion:上下文无关意见指意见opinion的极性固定,不受上下文的影响;上下文相关意见指意见opinion没有明确的极性,而受上下文的影响,这里主要是受与opinion相关联特征的影响。
3.2 特征意见抽取
在第1节中已经介绍了特征与意见的抽取大致可以分为有监督抽取和无监督抽取2种方法。其中有监督抽取方法需要大量的手工标注,而且由于不同类别产品的特征意见变化较大,所以这一方法仅限于领域相关的应用。无监督抽取方法虽然不受领域的限制,但抽取正确率与召回率都不及前者。
本文试图寻找一种方法,即通用方法,领域无关,而且也可以获得较高的正确率与召回率。
算法的核心思想是:利用语言中相对稳定的部分,通过迭代的方法发现特征与意见。算法思想来自对评论句式的分析,下面简单介绍一下对评论句式的统计结果。
3.2.1 评论特点分析
经统计发现,评论主要可以分为3种句式:
句式1 feature+opinion。
这种句式直接表达了用户对产品某种特征的意见,其中feature代表产品的特征,opinion代表相应意见。例句见表1。
这种句式里包含另一种重要句式,即feature并没有显性地提出,就是说只有opinion而没有相应的feature,但事实上这种句式中的opinion同时暗指了feature,所以这里认为该句式里的opinion既是implicit feature(隐性特征)也是opinion。例句见表1。
句式2 主张词+句式1。
这种句式由“主张词”来显性标识所在句子为评论。识别这类句式有助于提高召回率。例句见表1。
句式3 情感词+feature。
这种句式由“情感词”来显性标识这句是评论。识别这类句式有助于提高召回率。例句见表1。

表1 评论句式分类
本文标注了500条评论,3种句式在标注集中所占的比例如图2所示。从图2可以看出这3种句式的覆盖率还是比较高的。

图2 3种主要评论句式所占比例
根据对评论句式的统计,针对句式1提出抽取特征、意见的算法,并利用句式2与句式3提高算法的召回率。
在抽取顺序上,不同于以往算法的先确定特征再发现意见词,而是采取先抽取opinion,然后根据opinion抽取feature的方法。确定这全策略是由于中文评论中隐性特征较多,如果运用传统方法即先确定feature,然后抽取opinion的话,会损失掉隐性特征。
采用这一顺序的另一方面原因是,评论中不可避免会有噪音,噪音的来源可能是网页本身的广告、标签等;也可能是评论人发表的非评论部分。以实验数据来说,由于本文的数据是关于化妆品使用心得的,评论中可能会含有一些使用方法、购买地点等噪音。认为这些成分是噪音的原因无疑是这些成分中不含有用户的意见。通过先抽取意见的方法,同时忽略不含有意见的句子,这样自然就滤去了噪音。
3.2.2 发现意见词
核心思想:通过相对稳定且小规模的程度副词发现意见词。
通过统计观察发现,人们在发表评论时经常会使用程度副词来修饰opinion word(意见词)。意见词会因评论的对象不同、特征不同而变化,且数量巨大,随时间的变化也较大,而副词的数量较少,且相对稳定。罗振声教授主持的清华大学ZW大型语料库的词性统计表见表2。因此本文考虑是否可以通过副词来找到意见词。

表2 词性统计表
本文标注了500条评论,经统计发现:通过“adv+adj”模式,判断adj为意见词的正确率为92%。而意见词前面含有程度副词的情况达81%,这里由于一个意见词可能出现频率不止一次,只要在一次出现中前面伴随程度副词则按照出现的n次里都伴随副词进行统计。
具体方法:首先准备一个初始advWordList(程度副词词表),实验中所用的初始 advWordList是《知网》情感分析用词语集中的词汇[18]。在频繁集中,将符合“adv+adj”的模式抽出来,这里的adv代表adv-WordList中的词,adj表示该词的词性为形容词,也就是说要抽出程度副词后面的形容词作为opinion,并放入opinionList中。然后再找opinion前面的副词添加到advWordList中,这样反复迭代,直到opinionList与advWordList都不再增长为止。
3.2.3 发现特征
核心思想:意见词opinion前的名词短语为产品特征feature。
具体算法如下:
取opinion前的以名词为中心的一定长度窗口内的n-gram,加入featureList中。
将feature所在句子中形容词加入opinionList。
将新加入的opinion前面的以名词为中心的ngram加入featureList。反复迭代,直到opinionList与featureList不再增长。
为了提高算法的召回率,根据3.2.1节评论句式分类中的句式2、句式3,提出2条启发式规则:
规则1 如果句子中含有“主张词”,则将句中的形容词加入opinionList,以名词为中心的n-gram加入featureList中。
规则2 如果句子中含有“情感词”,则将句中的名词加入featureList。
对特征剪枝:统计featuren-gram的频率,如果 support(n - gram)≤minsup=ReviewCount× support,其中minsup为用户给定的一个阈值,则将该featuren-gram从featureList中删去。
最后合并同义feature:合并的方法即计算任意2个feature的相似度,相似度用于衡量2个特征为同义词的可能性,如果相似度大于阈值则视为同义词进行合并。合并同义特征主要考虑2方面:首先,如果2个feature含有共同的词语片段,则认为2个feature相似;另一方面,考虑同义词产生的原因,之所以会有同义现象是由于不同用户的语言习惯不同,对同一产品特征有不同的表达方式,但对于同一个用户来说,他在表达某一特征时用不同的说法的可能较小,也就是说,如果2个feature出现在同一个人发表的评论中,则这2个feature为同义词的概率较小。基于这2点,用如下公式计算2个特征featurei和featurej的相似性:

经过特征与意见抽取后,得到一个特征与意见相关联的结构,即特征列表(FeatureList),其中包含最终的特征。FeatureList中的每个feature链着一个意见集合(OpinionSet),意见集合包含了与其关联的特征的所有意见,其中每个单元包括意见词及其出现的子句号码列表。子句号码的标识将在下面的章节中介绍。
3.3 特征意见对偶极性判断
极性判断即是判断感情色彩,分为3类:正向(褒义)、负向(贬义)、未知。
以往在判断评论极性时,通常分为3个层次,即基于文章的、基于句子的、基于特征的。本文中判断粒度是子句(由任意标点符号分割),若该子句内含有某特征和意见,由于判断时同时考虑此子句内否定词的个数,因此可以看作是对(特征,意见,否定词个数)三元组极性的判断。通过这种方法将特征和意见相关联,判断上下文相关意见的极性。考虑否定词个数的原因是显而易见的,即如果有1个否定词,则对偶的极性翻转,如果有2个否定词则双重否定变肯定。
判断(特征,意见,否定词个数)三元组极性的方法是基于聚类的,希望将同一极性类别的特征、意见对聚在同一个类中,因此称该聚类为极性聚类(polarityClustering)。
算法总体描述:
polarityCluster借鉴了已有极性判断算法中的利用连词和种子词的方法,不同之处在于不是简单依赖句子中极性之间的并列关系(如果有转折连词的话,则为互斥关系),而是通过聚类的方法,考虑类中其他成员对判断极性的意见词的影响,从而缓解前述中存在的问题。
为了描述算法,将评论按照3种级别进行操作,分别是评论级别、同极性句级别、子句级别。
1)评论级别:每个用户的评论被认为一条评论。
2)同极性级别:将每条评论分成若干段,每个片段的极性认为是相同的。
3)子句级别:同极性句中的任意2个标点符号之间的句子被看为一个子句。
每个级别中句子统一编号。
算法过程如下:
1)首先将待处理评论以转折连词分开,各自成为一个“同极性句”。
被转折连词分开的2个同极性句极性相反,将彼此的这一级句子编码synonymSentence(同极性句子)加入其反义句集antonymSentenceSet中。将这些信息记录到FeatureList结构中,即根据每个特征所关联意见的子句,添加同极性句子和反义句(可为空)。统计每个子句中的否定词个数(privativeCount),添加到featureList结构中。这个结构有助于判断否定句式的极性。
将每个feature关联的opinion所在的同极性句集按照否定词个数分成2个集合。生成 polarityPair(polaritySentenceSet0,polaritySentenceSet1),polaritySentenceSeti为其中否定词个数为奇数(或偶数)的同极性句的集合,并且分别将polaritySentenceSet1与polaritySentenceSet0的反义句集合antonymSentenceSet加入到对方的集合中。
2)初始化相似度矩阵SimilarityMatix。
为了进行聚类,需要确定任意2个三元组间的相似度,即确定相似度矩阵SimilarityMatix的值。SimilarityMatix为 n×n矩阵,其中 n为三元组的个数。SimilarityMatrix[ i] [j]表示三元组 triplei、triplej之间的相似度。其初始值赋值如表3所示。
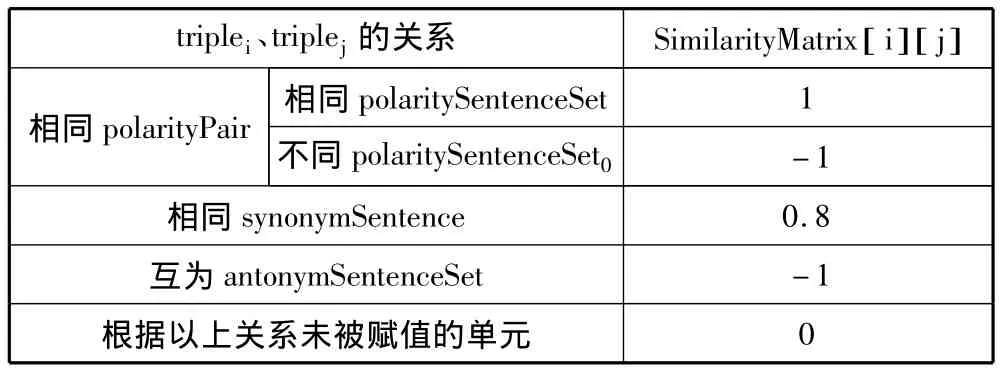
表3 SimilarityMatrix初始值
3)计算相似度矩阵的n次方(n-th Power)。
在上一步的相似度矩阵初始化中,对矩阵中有直接相连关系的单元进行了赋值,接下来通过矩阵连乘的方式获得间接相连关系的相似度值。相似度矩阵乘方的计算公式如下:

从上面的公式可以看出,1次矩阵乘方中计算了triplei、triplej通过一次间接连接更新 triplei、triplej间的相似度。类似地,经过n次乘方后,就遍历了所有可能的路径,将 SimilarityMatrix[ i] [j]更新为 triplei、triplej最大相似度。
但是通过这样计算相似度的依据是什么呢?举个例子,比如:
triplei、triplej没有直接联系,即 SimilarityMatrix[i][j]=0;
triplei、triplek互 为 反 义,则 SimilarityMatix[i][k]=-1;
triplek、triplej互 为 同 义,则 SimilarityMatix[k][j]=1。
4)聚类。
应用k-medoids聚类算法进行聚类[19]。
5)极性聚类的极性判断。
根据类别中已知极性的意见词的正负倾向频率比例来判断聚类的极性。也就是说,如果类别中已知极性的意见词的正向频率高则类别的极性判定为正向,反之,判定为负向。同极性句中的特征-意见对的极性继承聚类中的极性。
4 实验结果与分析
4.1 特征意见抽取
为了进行实验,手工标注一个测试集realFOtest-Set,该测试集数据为网络关于产品雪肌精的评论的随机抽取集合。realFOtestSet中包含255条关于化妆品类中对于产品雪肌精的评论,对这些评论中的产品特征、相应同义词、和特征相关联的意见、区分意见的极性、程度副词等进行了标注。表4中展示了标注集的一些统计信息。

表4 测试集标注的统计信息
4.1.1 意见词发现实验结果
程度副词初始列表为知网提供情感分析用词语集中的词汇。
图3所示为根据程度副词(adv)发掘意见词opinion和由特征词feature发掘意见词的实验结果。实验集合中共有101个opinion,由程度副词推导出82个opinion,正确率为100%,召回率为81.2%。由特征词推导出29个opinion,正确率为55%,召回率为15.8%。由程度副词和特征词推导出的opinion共111个,正确率为88.2%,召回率为97.1%。由实验可以看出程度副词推导opinion的正确率和准确率都很高,在计算由特征词推导的opinion时统计的是根据程度副词没有找到的opinion。由特征词导出opinion时所引入的错误主要是由于一些修饰特征词的形容词误识为opinion所致。实验中由特征词导出opinion算法中的窗口大小为4。
由于根据特征词推导opinion算法中结果受窗口大小影响,因此基于窗口变化做了一组实验。从图4可看出,opinion召回率随窗口增大而增大,正确率却下降,窗口为4可使正确率和准确率达到稳定状态。

图3 推导opinion的实验

图4 窗口大小对推导opinion算法的影响
4.1.2 特征抽取实验结果
图5所示为特征抽取实验结果。实验数据中共有62个feature。实验中由opinion推导出的feature有41个,其中正确的有34个,特征抽取正确率为82.9%,特征抽取召回率为66.1%;由主观词推导出feature共5个,其中正确的有5个,特征抽取正确率为100%,特征抽取召回率为8.1%;由情感词推导出feature共4个,其中正确的有4个,特征抽取正确率为100%,特征抽取召回率为6.5%。3部分的特征抽取正确率为86%,特征抽取召回率为69.4%。
由于特征抽取算法效果和窗口大小有关,所以图6展示了算法准确率、召回率随窗口大小变化的情形。随着窗口的变大,召回率增大,准确率下降。

图5 特征抽取实验结果

图6 抽取算法准确率
4.2 极性判断
为了进行实验,准备了2个类别4种产品的测试集,实验结果如图7所示。从图7可以看出意见极性识别的准确率在70%左右,还是比较理想的。
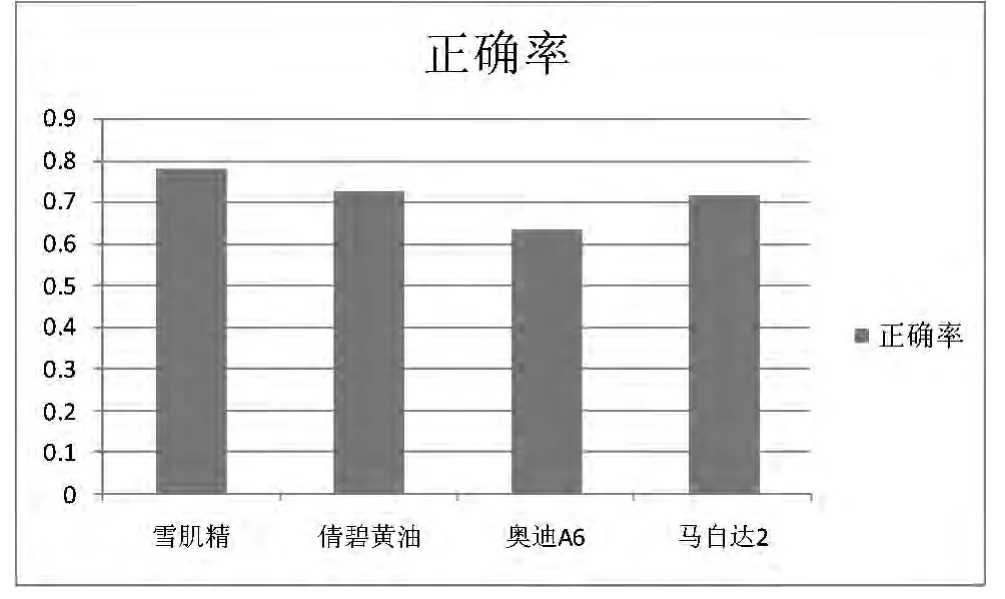
图7 极性判断有效性实验
与其他算法的比较:
由于这部分算法是对基于“连词”“种子词”进行极性判断的改进,因此进行了这2种算法的对比实验。在图8中召回数指的是通过各自算法可以确定的特征意见对偶的极性的数目。正确数是极性判断正确的数目。实验结果表明无论是召回数还是正确数,本文算法都优于文献[2]方法。

图8 极性判断对比实验
5 结束语
本文的研究对象是中文产品评论,研究目标是自动收集网络上关于用户指定产品的评论,对这些评论进行结构化,即按照产品特征组织评论,并判断对应特征意见的感情色彩。
产品评论结构化研究在英语、日语等语种上已经有了一定成果,但由于中文自身的特点,已有算法并不适用于中文产品评论,其问题主要有以下3点:
1)由于中文口语中句子成分省略现象普遍,造成了大量产品隐性特征,这大大增加了意见结构化中产品特征提取的难度。隐性特征的提取在意见挖掘领域一直是个难题。
2)由于中文二义现象更为突出,语义极性分析对上下文的依赖加强,这使得工作难度进一步加大。
3)基于以上问题,本文提出了针对中文的产品评论结构算法。算法包括2部分:产品特征、意见抽取模块;感情色彩判断模块。
本文实现了中文产品评论结构化系统review search。该系统根据用户输入的产品名称,返回网络上关于产品评论的结构化处理结果。系统的优点主要有,不受领域限制,自动抽取产品特征、意见;自动判断上下文相关的意见的感情色彩极性。
[1] Liu Bing,Hu Minqing,Cheng Junsheng.Opinion observer:Analyzing and comparing opinions on the Web[C]//Proceedings of the 14th International Conference on World Wide Web.2005:342-351.
[2] Hu Minqing,Liu Bing.Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2004:168-177.
[3] Turney P.Thumbs up or thumbs down?Semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics.2002:417-424.
[4] Popescu A-M,Etzioni O.Extracting product features and opinions from reviews[C]//Proceedings of the 2005 Conference on Human Language Technology and Empirical Methods in Natural Language Processing.2005:339-346.
[5] Hu Minqing,Liu Bing.Mining opinion features in customer reviews[C]//Proceedings of the 19th AAAI National Conference on Artificial Intelligence.2004:755-760.
[6] Ghani R,Probst K,Liu Yan,et al.Fano:Text mining for product attribute extraction[J].ACM SIGKDD Explorations Newsletter,2006,8(1):41-48.
[7] Ding Xiaowen,Liu Bing.The utility of linguistic rules in opinion mining[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2007:811-812.
[8] Gamon M,Aue A,Corston-Oliver S,et al.Pulse:Mining customer opinions from free text[C]//Proceedings of the 6th International Symposium on Intelligent Data Analysis.2005:121-132.
[9] Scaffidi C,Bierhoff K,Chang E,et al.Red opal:Productfeature scoring from reviews[C]//Proceedings of the 8th ACM Conference on Electronic Commerce.2007:182-191.
[10] 郭冲,王振宇.面向细粒度意见挖掘的情感本体树及自动构建[J].中文信息学报,2013,27(5):75-83.
[11] 文涛,杨达,李娟.中文软件评论挖掘系统的设计与实现[J].计算机工程与设计,2013,34(1):163-167.
[12] 马晓玲,金碧漪,范并思.中文文本情感倾向分析研究[J].情报资料工作,2013,34(1):52-56.
[13] 陆文星,王燕飞.中文文本情感分析研究综述[J].计算机应用研究,2012,29(6):2014-2017.
[14] 李芳,何婷婷,宋乐.评价主题挖掘及其倾向性识别[J].计算机科学,2012,39(6):159-162.
[15] Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[16] Pang Bo,Lee L,Vaithyanathan S.Thumbs up?Sentiment classification using machine learning techniques[C]//Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing.2002:79-86.
[17] Yu Hong,Hatzivassiloglou V.Towards answering opinion questions:Separating facts from opinions and identifying the polarity of opinion sentences[C]//Proceedings of the 2003 Conference on Empirical Methods for Natural Language Processing.2003:129-136.
[18] 董振东,董强.《知网》情感分析用词语集[EB/OL].http://www.keenage.com/cgi-bin/c_enroll.cgi,2007-10-21.
[19] Kaufman L,Rousseeuw P J.Finding Groups in Data:An Introduction to Cluster Analysis[M].New York:Wiley,1990.
