一种基于碰撞位指示的射频识别标签防碰撞算法
2014-06-02李志坚赖顺桥
李志坚赖顺桥
一种基于碰撞位指示的射频识别标签防碰撞算法
李志坚*①②赖顺桥②
①(华南理工大学电子与信息学院 广州 510640)②(广州市光机电技术研究院 广州 510663)
多标签碰撞是射频识别(RFID)技术在推广应用中必须克服的一个问题。针对目前RFID标签防碰撞算法存在识别效率低的不足,该文提出一种基于碰撞位指示的RFID标签防碰撞的碰撞位指示算法(CBIA)。通过跟踪待识别标签的碰撞位,采用碰撞位编解码技术,对待识别标签进行重复分组,直到所有标签都被正确识别。算法通过确定性分组,避免了空闲时隙的产生。仿真结果表明,采用CBIA算法的多标签识别系统,吞吐率可以达到每时隙0.7个标签,CBIA算法识别效率优于优化查询跟踪树算法(OQTT)和碰撞跟踪树算法(CTTA)算法。
射频识别;防碰撞算法;位跟踪技术;吞吐率
1 引言
射频识别(Radio Frequency IDentification, RFID)是上世纪90年代兴起的一种非接触式自动识别技术。近年来,随着物联网技术的发展,RFID被广泛应用于军事、供应链、卫生保健和公共管理等领域[1,2]。由于RFID系统标签和读写器共用一个无线频道,当多读写器和多标签同时占用频道通信时,信号相互干扰,发生了碰撞。

ALOHA算法易于实现,成本低廉,但是由于算法的时隙是随机分配,因此可能造成某些标签长时间无法识别,亦即存在标签饥饿(tag starvation)问题。
基于树的分组算法是确定型算法,算法依据确定的分组规则,对活动标签反复分组,直到每个组内只含一个标签或者不含标签,从而识别所有标签。根据分组规则的不同,基于树的分组算法又进一步分为二进制树搜索算法(Binary Tree protocol, BT)和查询树算法(Query Tree protocol, QT)。基本的BT算法和QT算法都存在空闲时隙,降低了系统效率。
采用碰撞位跟踪技术可以提高基于树的分组算法的系统效率。增强防碰撞算法(Enhanced Anti-collision Algorithm, EAA)和碰撞跟踪树算法(Collision Tracking Tree Algorithm, CTTA)[11,12]分别是对基本的BT算法和QT算法,都采用了碰撞位跟踪技术。这两种算法都检测最高碰撞位,之后按照最高碰撞位分别为‘0’和‘1’把碰撞标签分成两组,从而避免了空闲时隙的产生,提高了系统效率。
但是,当活动标签数量很大时,EAA算法和CTTA算法都存在大量的碰撞时隙。减少碰撞时隙可以进一步提高系统效率。文献[8]提出的优化查询跟踪树算法(Optimal Query Tracking Tree, OQTT)算法。该算法在识别开始时,先通过碰撞位置估计标签数量,之后依据最优分组规则把待识别标签分成若干组,每一组都采用CTTA算法进行识别。OQTT减少了识别最初的碰撞时隙数量,提高了识别效率。
OQTT算法只在查询树首层增加了分支,而在每个子查询树里面仍采用CTTA算法。因此,在标签数量很大的时候,识别初期的碰撞时隙还是比较多。进一步减少碰撞时隙,可以进一步提高系统效率。
本文正是基于进一步减少碰撞时隙的思想,提出一种基于碰撞位指示的RFID多标签防碰撞算法(Collided Bits Indicator Algorithm, CBIA)。CBIA通过跟踪待识别标签的碰撞位,采用碰撞位编解码技术,对待识别标签进行重复分组,直到所有标签都被正确识别。算法的创新点在于增加了查询树每一层的分枝数量,同时避免空闲时隙的产生,进一步压缩了查询树的层数,减少了碰撞时隙的数量,提高了系统效率。本文通过数学分析,给出了CBIA算法的占用时隙的估计模型,并在此技术上得出了系统吞吐率估计。仿真结果表明,相对于现有查询树算法CTTA和OQTT算法,CBIA具有更快的识别速率和更高的吞吐率。
2 基于碰撞位指示(CBI)的RFID防碰撞算法
2.1 算法的预设条件
(1)标签ID采用曼彻斯特编码[13],长度为,读写器能够正确识别非碰撞位和碰撞位。读写器中设置一个查询前缀堆栈S和两个寄存器碰撞位模板(Collided Bits Mask, CBM)和识别位模板(Recognized Bits Mask, RBM),分别用于记录碰撞位和已识别位数据。
(2)标签中设置一个2位的碰撞位指示(CBI) 寄存器。当接收读写器广播的CBM时,标签顺序取出ID中的高位碰撞位,形成一个二进制数,这个二进制数成为碰撞位编码CBC(Collided Bits Code),然后根据CBC把CBI的第CBC位置‘1’,其他位置‘0’。
(3)标签中设置一个状态寄存器SF,标签根据SF的值在不同的时候响应读写器命令。
2.2 算法的命令格式
(1)Act (0)命令:读写器广播这个命令,有效通信范围内所有标签回送各自ID给读写器同时把状态标志位SF置‘1’。
(2)Req (opt):查询命令。其中参数‘’是一个长度为()的二进制数,可以是查询前缀序列或者CBM,由参数opt区分。参数opt为‘0’时,‘’是一个查询前缀序列。若标签ID的高()位与‘’一致,则标签回送剩下的-()位给读写器并把状态标志位SF置‘1’。参数opt为‘1’时,‘’是一个CBM。状态标志位SF为‘1’的标签回送CBI给读写器并把SF清零。
2.3 算法流程图
CBIA算法的流程图如图1所示,其主要步骤如下:
步骤1 读写器初始化,清空堆栈S,清零CBM和RBM。广播Act (0)命令。识别范围内所有标签回送ID并置位SF;
步骤2 读写器检测碰撞位,设置CBM和RBM。如果没有检测到碰撞,读写器识别一个标签;若只存在一个碰撞位,则读写器识别两个标签。如果存在多个碰撞位,读写器跟踪所有碰撞发生的位置,并把CBM对应位置‘1’。读写器识别所有未碰撞位,把RBM对应位置上置位已识别数码;
步骤3 读写器发送命令Req(CBM,1)。有效识别范围内,SF为‘1’的标签回送CBI并把SF置‘0’;
步骤..4 读写器接收CBI,并跟踪所有碰撞位位置,然后根据碰撞位位置译码得到CBC。例如,若读写器接收到8位CBI为“000x0xx0”,x表示该位发生碰撞。则表示碰撞发生在第1,第2和第4位,那么读写器可以译码出3个CBC,分别是“001”,“010”,“100”;
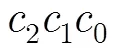

图1 CBIA流程图
步骤6 若S不空,则读写器从S中取出一个查询前缀序列,并广播Req(prefix,0)命令。有效识别范围内,ID高位与前缀一致的标签回送剩余ID,并把SF置‘1’。算法跳转到步骤2;
步骤7 若S读空,则所有标签都被识别,识别过程结束。
2.4 算法应用举例
图2给出了一个利用CBIA算法识别7个标签TagA~TagG的示例。图中x表示该位发生碰撞。CBC长度为4。在第1个时隙,读写器广播启动命令,所有标签都响应读写器命令。在第2个时隙,读写器广播CBM“111111111111011”。SF为‘1’的标签回送CBI,并置 SF 为‘0’。在本示例中,标签A, B, F和G 的CBI相同,均为“000001000000000”,对应CBC为“1010”;标签C的CBC是“0101”回送CBI “0000000000100000”;标签D 的CBC是“0001”回送CBI“00 00000000000010”;标签E 的CBC是“0111”回送CBI“0000000010000000”。读写器接收端接收到的CBI为“00000x00x0x000x0”。这样读写器可以根据碰撞位发生位置计算所有的CBC,分别是“1010”,“0111”,“0101”,“0001”。然后读写器就可以生产4个查询前缀序列“1010”,“0111”,“0101”,“0001”,并压栈。在第3个时隙,读写器取出一个查询前缀序列“0001”,并广播查询命令。标签D高4位与这个前缀一致,所以它回送剩余ID位,这样标签D成功识别。同样标签 C和 E 分别在第4个和第5个时隙被识别。第6个时隙,读写器广播查询前缀“1010”,标签A, B, F 和G 同时回送剩余ID位并置各自SF为‘1’。读写器接收CBI“0x0xx0x0”。此时碰撞位位数为4,那么这4个标签可以在下个时隙一次识别。在第7时隙,读写器广播CBM “000001011010”,标签A, B, F和G回送CBI。读写器接收CBI“00x00x0000x 0x000”经译码得CBCs:“1101”,“0101”,“1010”,“0011”,然后把CBC嵌入到RBM中可识别这4个标签。此时,S为空,识别过程结束,所有标签都被识别。
3 算法性能分析
算法性能可以通过估计识别个标签所需要的时隙树和估算系统吞吐量进行衡量。
在数学分析之前,有必要区分CBIA算法的两种碰撞:
可识别碰撞:读写器在接收标签回送ID数据时,如果检测出碰撞位数不大于CBC位数,则碰撞的多个标签可通过译码CBC全部识别。
不可识别碰撞:读写器在接收标签回送ID数据时,如果检测出碰撞位数大于CBC位数,则碰撞的多个标签不可在一次译码中识别,这种碰撞为不可识别碰撞。
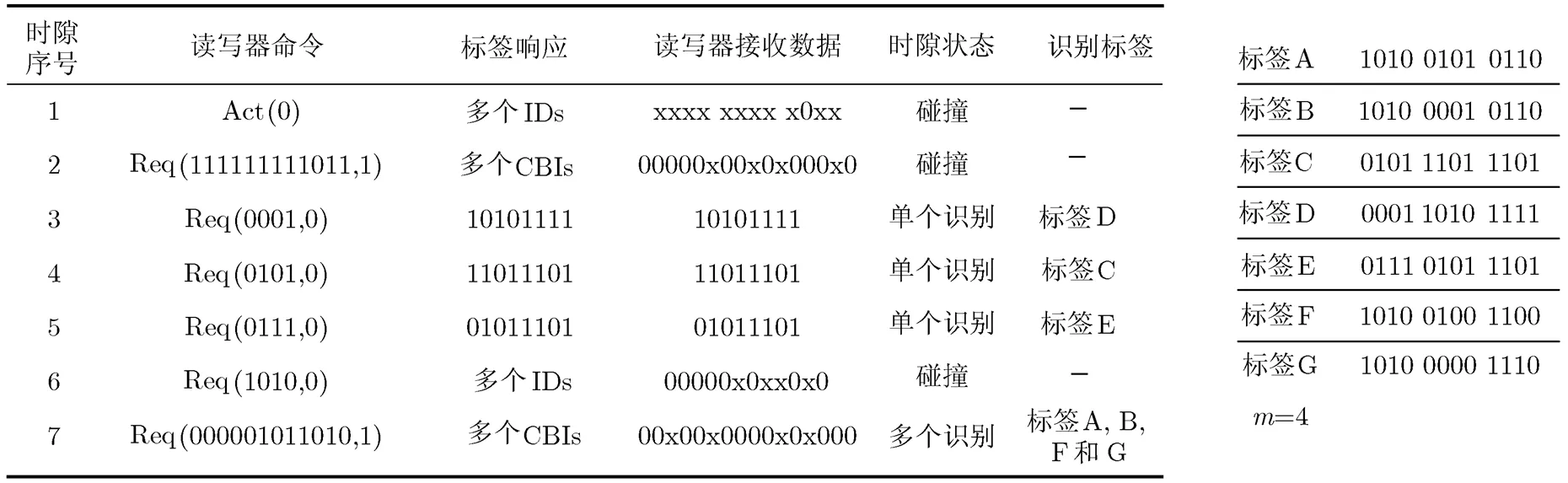
图2 CBIA示例
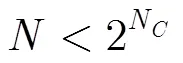
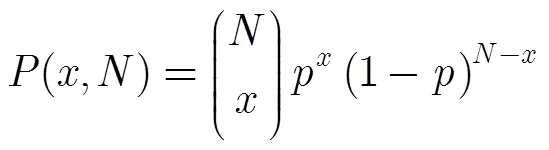
由于每个数位等概率取得‘0’和‘1’。所以=1/2。当个标签ID的同一位上均为‘0’或者‘1’时,该位不会发生碰撞。这样个标签某位不发生碰撞的概率为
(2)
相应地,该位发生碰撞的概率为
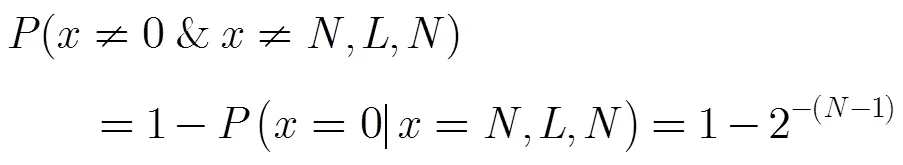
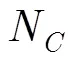
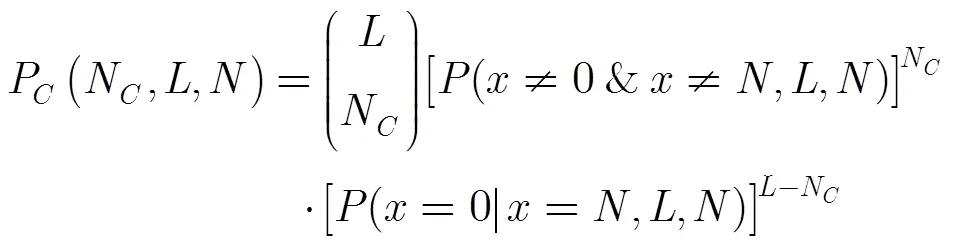
在一棵完整的CBIA查询树中,每个父节点可以产生2个子节点,第层有2子节点。每个子节点对应一个查询前缀序列。个标签ID中具有相同前缀的标签ID数量服从二项分布

同样,由于标签ID是均匀分布,因此标签前缀等概率出现,从而有

当只有一个标签具有某一前缀时,该标签可以直接识别。由式(4),单标签被识别的概率为
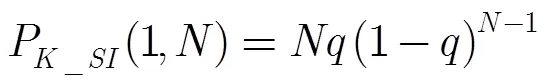
当多个标签具有相同前缀,但回送数据仅有一个碰撞位时,说明当前只有两个标签响应读写器查询命令,这样两个标签可以一次识别。识别概率为

当多个标签具有相同前缀,但回送数据碰撞位数n不大于时,通过下一个时隙CBC译码,这些标签都可以识别出来,这种情况发生的概率为
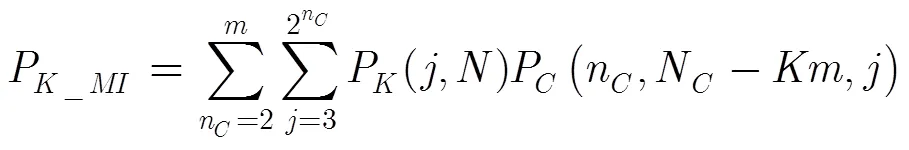
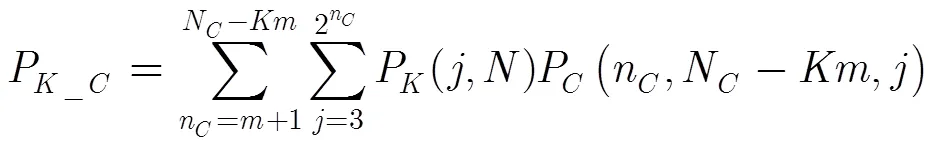
如果用P表示CBIA查询树上第层的第个节点被访问的概率。显然当0,00/N1,也就是CBIA的根节点总是被访问到。


进而有
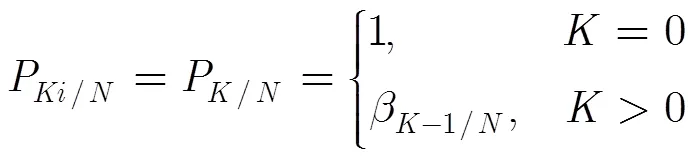
这样,CBIA算法访问节点的数学期望为
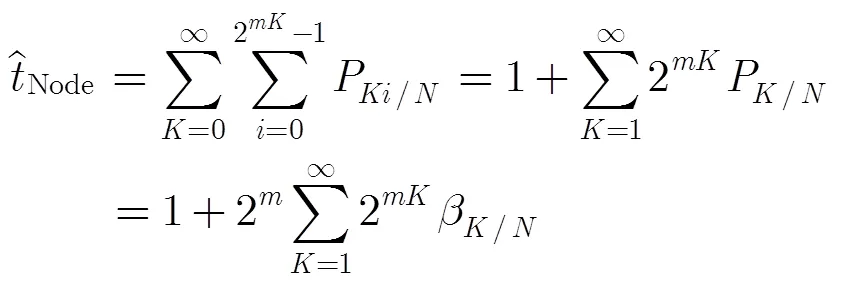
综上,有CBIA识别个标签的时隙树为

进而可得系统的吞吐率为
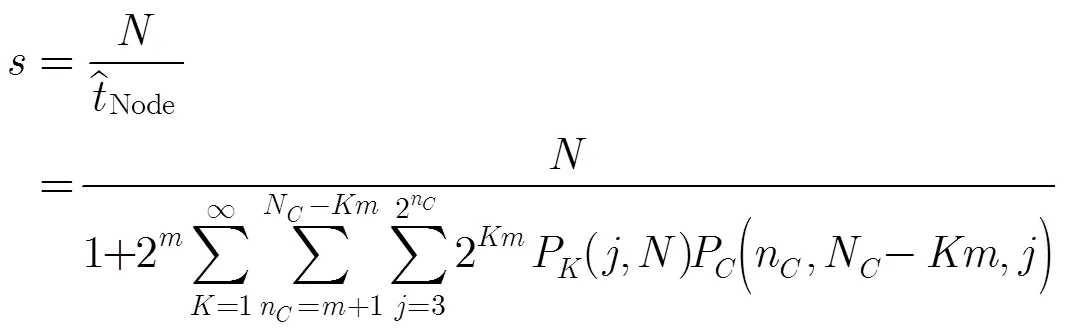
需要说明的是,在实际识别过程中,CBIA查询树的层数不可能无穷大,它与系统设置的标签CBC位数有关。
4 实验仿真分析

仿真结果表明:相比于CTTA, OQTT算法,CBIA算法平均识别时隙数优势明显,且随着待识别标签数据的增大,算法性能优势越明显。在系统吞吐率方面,CBIA算法性能优于其他两种算法,平均每个时隙可识别0.7个标签,优于OQTT算法的吞吐率仅为0.6和CTTA的0.5。
图4反应了CBC位数和标签ID位数对CBIA算法性能的影响。图4(a)中,标签ID位数固定为64位,标签CBC位数分别为2,4,6,8,10位。图4(b)中,标签数量固定为1000个,标签ID位数分别为32,48,64,96和128位。仿真结果表明,当CBC位数为6时,识别相同数量的标签所用时隙最少。
5 算法的性能对比优势和标签硬件开销分析
本节主要分析CBIA算法与CTTA, OQTT的对比优势,并分析CBIA获取这些优势所付出的硬件成本。
5.1 算法的性能对比优势
CTTA, OQTT和CBIA都是查询树算法QT的改进,其核心思想是不断地对待识别标签进行分组,直到组内标签可以一次识别。这几种算法性能差异,是由各自采取的分组协议引起的。
CTTA每次只处理一个碰撞位。每次检测到碰撞位,CTTA自动把待识别标签分成碰撞位为‘0’和‘1’的两组,直到组内仅含一个标签或者仅含有两个只有一个冲突位的标签,识别这些标签。CTTA采用确定性分组,避免了空闲时隙的产生。然而,CTTA每次只把组内待识别标签划分成两个小组。这样,在标签数量较大时,CTTA搜索深度会很深。而且,在识别初期,每一组内待识别标签数量很大,碰撞概率很高,在标签数量较大时,碰撞时隙数量非常可观,识别效率不高。
OQTT对QT算法的改进仅在于识别最初的最优化分组,而在之后的各组内识别过程仍旧采用CTTA算法。尽管采用了碰撞位跟踪技术,但每次也仅处理一个碰撞位。这一方面,CTTA算法的不足,在OQTT算法中仍然存在。另一方面,OQTT的最优化分组是随机分组。当标签ID不服从均匀分布时,OQTT的最初分组会不平衡[8],从而使得某些组内待识别标签非常多,而某些组内待识别标签很少,甚至没有。其结果是OQTT算法性能下降。

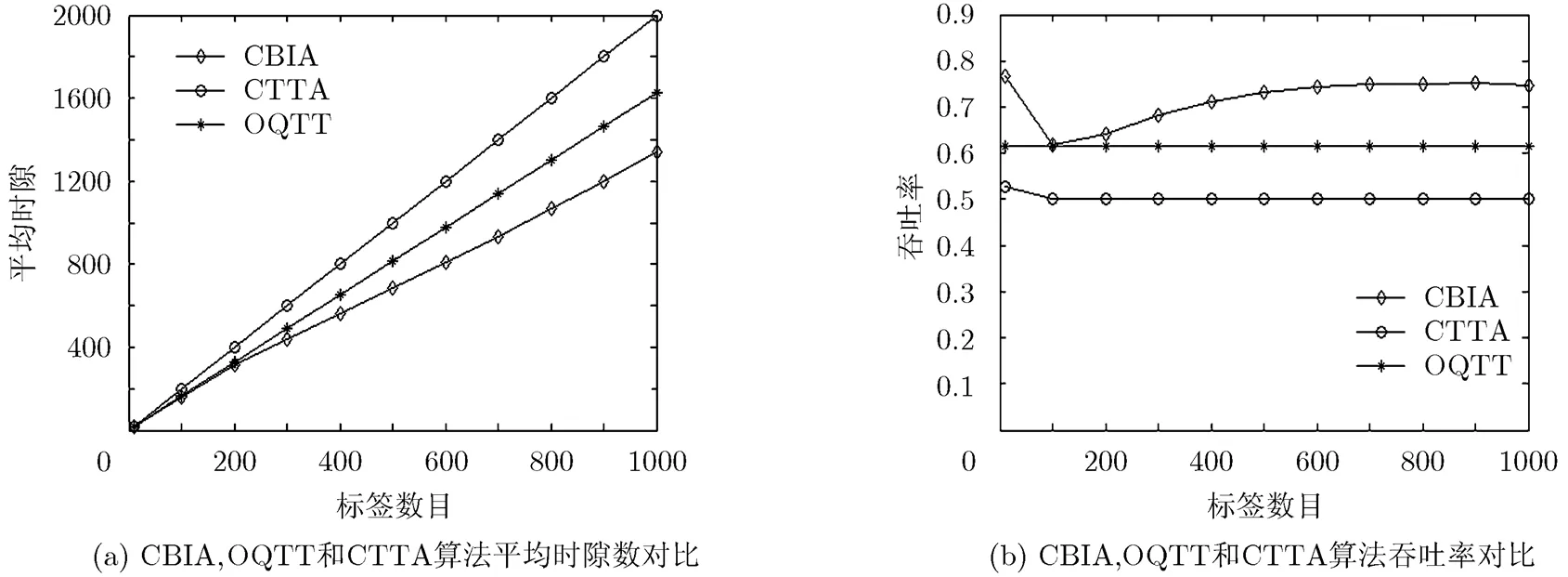
图3 算法性能比较

图4 CBC位数和ID位数对CBIA性能影响仿真
CBIA算法与OQQT算法比较,其最大特点是确定性分组。与OQTT的随机分组不同,CBIA算法在最初分组时采用确定性分组,每个小组内都有待识别标签,不会出现无标签的小组。因此,CBIA可以避免OQTT算法在最初分组时的空闲时隙的产生。而之后的识别过程,OQTT组内采用CTTA算法,这样,CBIA算法对CTTA算法的优势也同样体现在对OQTT算法的比较中。
5.2 标签硬件开销分析
CTTA是采用了位跟踪技术的QT算法。QT算法是一种无记忆防碰撞协议,标签在识别过程中不需要存储任何数据,每次回送剩余标签ID。因此,CTTA算法标签中无存储资源,硬件成本低廉。
OQTT是对CTTA算法的改进,继承了CTTA算法的无记忆的特点。但是,OQTT算法在最初的进行标签数量估计时,需要标签根据协议产生一个log2位的随机数,并根据这个随机数对一个位的二进制数(其中是标签ID的位数)进行位调制[8]。因此,OQTT算法在硬件开销方面,将增加随机数生成模块和位调制模块。
CBIA算法也是CTTA算法的改进。根据协议需要,标签接收读写器广播的CBM,并根据CBM的非零位位置和标签ID的对应位产生一个二进制数,并用这个二进制数对2位CBI进行位调制。因此,CBIA算法与OQTT类似,都增加了二进制数生成和位调制的硬件开销。但是,由于CBC位数小于log2, CBI位数小于,因此,与OQTT比较,CBIA算法所消耗的硬件资源更少。考虑到标签需把调制后的二进制数回送读卡器,OQTT算法回送一个位的二进制数,而CBIA算法仅回送一个2位的CBI,因此,CBIA比OQTT的通信数据量更少。
6 结束语
本文提出了一种新颖的RFID多标签防碰撞算法,CBIA。该算法利用碰撞位跟踪技术,对待识别标签进行重复分组,直到所有标签都被正确识别。算法增加了查询树的每一层分叉数目,同时避免了空闲时隙的产生,压缩了查询树的层数,减少了碰撞时隙的数量。仿真结果表明,采用CBIA算法的多标签识别系统,吞吐率可以达到每时隙0.7个标签,CBIA算法识别效率优于OQTT和CTTA算法。最后,CBIA和OQTT都增加了一些硬件开销,但是CBIA硬件开销低于OQTT。
[1] Zuo Y J . Survivable RFID systems: issues, challenges and techniques[J].,,-:, 2010, 40(4): 406-418.
[2] Mohamed B, Adel M, and Belkacem F. Dual antenna for physical layer UHF RFID collision cancelling[C]. 2012 International Conference on Multimedia Computing and Systems, Melbourne, Australia, 2012: 623-628.
[3] Lee C C and Lin S Y. A double blocking dynamic framed slotted ALOHA anti-collision method for mobile RFID systems[C]. 2012 Sixth International Conference on Genetic and Evolutionary Computing, Kyushu, Japan2012: 581-584.
[4] Jiang Y J, Xu Y F, and Wang Q. Cancellation strategy in dynamic framed slotted ALOHA for RFID system[C]. 2013 IEEE Wireless Communications and Networking Conference (WCNC), Shanghai, China,2013: 854-859.
[5] Wang S, Hong W J, and Li S F. A slot-wise LMMSE estimate algorithm for frame slotted aloha protocol of RFID system[C]. 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 2012: 1-5.
[6] Xue J B, Wang W H, Li S B,.. Anti-collision algorithm based on counting mechanism and multi-state binary[C]. 2013 Fifth Conference on Measuring Technology and Mechatronics Automation, Hong Kong, China, 2013: 276-282.
[7] Landaluce H, Perallos A, and Zuazola I J G. A fast RFID identification protocol with low tag complexity[J]., 2013, 17(9): 1704-1706.
[8] Lai Y C, Hsiao Y L, Chen H J,.. A novel query tree protocol with bit tracking in RFID tag identification[J]., 2012, 12(10): 2063-2075.
[9] Yang Y K, Cui C S, Zhou T F,.. Improvement on RFID-based binary anti-collision algorithm[C]. 2012 International Conference on Computer Science and Service System, Nanjing, China, 2012: 515-518.
[10] Jin D, Ma Y M, Fan Z P,.. A RFID anti-collision algorithm based on multithread regressive-style binary system[C]. 2012 International Conference on Measurement, Information and Control, Harbin, China, 2012: 365-369.
[11] Liang C K and Lin H M. Using dynamic slots collision tracking tree technique towards an efficient tag anti-collision algorithm in RFID systems[C]. 2012 9th International Conference on Ubiquitous Intelligence & Computing and 9th International Conference on Autonomic & Trusted Computing, Fukuoka, Japan, 2012: 272-277.
[12] Bai Y, Xuan X W, Teng J F,.. An anti-collision algorithm based on collision bit position and splitting[C]. 2010 6th International Conference on Wireless Communications Networking and Mobile Computing, Chengdu, China, 2010: 1-4.
[13] Piao C H, Fan Z J, Yang C Y,.. Research on group-based polling anti-collision algorithm for RFID tag identification[C]. 2010 International Forum on Information Technology and Applications. Kunming, China, 2010: 185-188.
李志坚: 男,1981年生,讲师,研究方向为物联网RFID关键技术与应用、雷达信号处理.
赖顺桥: 男,1981年生,工程师,研究方向为物联网RFID关键技术与应用.
An Anti-collision Algorithm Based on Collided Bits Indicatorin Radio Frequency Identification Systems
Li Zhi-jian①②Lai Shun-qiao②
①(,,510640,)②(,510663,)
Multiple tags collision becomes an important factor blocking the popularization of Radio Frequency IDentification (RFID). To improve the identification efficiency and reduce the communication overhead, an novel algorithm, anti-Collided Bits Indicator Algorithm (CBIA) is proposed base don Bits Indicator Algorthm (BIA). Using the collision bit tracking technology and collided bits coding technology, the reader splits the tags into smaller subsets according to the identified collided bits. This process is repeated until all collided bits are solved. CBIA groups the tags into determinate subsets to avoid generating idle slots. The analysis and simulation results show that the average throughput of CBIA is 0.7 tags per slot, which is better than that of other algorithms, such as Optimal Query Tracking Tree protocol (OQTT) and Collision Tracking Tree Algorithm (CTTA).
Radio Frequency IDentification (RFID); Anti-collision algorithm; Bit-tracking technology; Throughput
TN92
A
1009-5896(2014)12-2842-06
10.3724/SP.J.1146.2013.01759
李志坚 leemu1001@126.com
2013-11-08收到,2014-06-30改回
广东省科技计划 (2010A011300016),广州市科技计划(2011J4100034)和中央高校基本科研业务费自主项目(2009ZM0097)资助课题
