基于BIC的语音识别模型压缩算法
2014-04-11李柏岩
邹 灿,李柏岩
(东华大学计算机学院,上海 201620)
0 引言
语音识别[1]是人类让机器去听懂人类语言的一种技术。对语音识别最早的研究可以追溯到上个世纪由AT&T贝尔实验室开发的Audrey语音识别系统,语音识别的研究者开始将人工神经网络引入语音识别。随后语音识别实现重大的突破,在语音识别中使用了隐马尔科夫模型(Hidden Markov Model,HMM),李开复博士实现了第一个基于隐马尔科夫模型的语音识别系统[2]。隐马尔科夫模型也是目前语音识别中关键的技术。最近在语音识别中应用了深度神经网络技术[3]。
在当今飞速发展的快节奏社会中,移动设备给人们带来方便,使得它在人们生活中占有越来越重要的地位。因此,移动设备中的语音识别应用势必会顺应市场的发展越来越火。移动设备的语音识别可以通过2种方式来实现:(1)通过联网在服务器端进行识别,再将结果返回给移动设备;将语音模型存放在移动设备本地,而实现移动端直接识别。它的优点是不需要将语音模型存放在本地,进而为本身缺乏存储空间的移动设备节省了空间;缺点是设备必须联网,而且服务器端也必须不间断地运作,当移动设备没有网络的时候就无法进行识别。(2)将模型存储在本地直接识别。它的优点是不需要移动设备联网,随时都可以进行识别;缺点是需要将占存储空间比较大的模型存储在存储空间稀缺的移动设备上。
针对上述将语音模型存储在移动设备本地进行识别的缺点,本文对其进行优化,将语音模型进行压缩并且尽量保证语音模型的识别率,从而使得移动设备的语音识别可以在无网络的情况下进行本地识别。
在本文中使用到的语音模型压缩的关键技术是通过贝叶斯信息标准[4](BIC)对模型进行选择。通过贝叶斯信息标准的值将模型的混合高斯组件数压缩到指定的数量,从而减少模型占用的存储空间。而BIC在对高斯模型的压缩过程中,优化了组件的聚类,使得聚类的界限更加清晰,从而保证了语音模型的识别率尽量地高。当然除了BIC之外,对于模型压缩还可以使用AIC[5](赤池信息准则,Akaike Information Criterion),但是BIC准则所选择模型相对而言比较接近真实模型,所以本文选择利用BIC准则进行试验。
1 贝叶斯信息准则(BIC)
贝叶斯信息准则是依据贝叶斯决策理论的一种模型选择方法。贝叶斯决策理论是贝叶斯派归纳理论的重要组成部分,是在不完全情报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最后决策。
贝叶斯决策理论是统计模型决策中的一种基本的方法,它的基本思想是:已知条件概率密度参数表达式和先验概率,利用贝叶斯公式转换成后验概率,再根据后验概率的大小进行决策分类。
因为基于隐马尔科夫模型与混合高斯模型的语音模型中,对于隐马尔科夫链中的每一个状态的基本参数都是由混合高斯模型构成。本文提出的模型压缩的问题,主要是通过BIC对语音模型中的隐马尔科夫模型中的每一个状态的混合高斯模型进行选择,从候选的高斯模型中挑选出合适的一个集合。
BIC是一种模型选择的似然估计准则。设建模的数据集为X={xi:i=1,2,…,N},候选的参数模型集合为M={mi:i=1,2,…,K},每个参数模型M 的最大似然函数为L(X,M)。令N(M)表示模型中参数的数量,则BIC准则定义为:

贝叶斯信息选择的过程是选择令BIC值最大化。这个过程的条件是独立的大样本的空间贝叶斯过程。
2 基于BIC的语音识别模型压缩算法
当进行模型压缩时,所遇到的问题是如何选择2个聚类去合并。本文采用贝叶斯信息准则进行选择,它的具体操作如下:设建模的数据集为X,候选的参数模型集合为M,N(M)表示模型中参数的数量,每个参数模型M的最大似然函数为L(X,M)。对于模型中的每一个组件的后验概率都可以通过公式(1)计算得出。假设组件A和B的BIC通过公式(1)计算出来的值为V1和V2,而合并之后的新组件计算出来的BIC值为V3。为了使模型的后验概率最大,挑选所有组件组合计算出来的(V3-V1-V2)值最大的那个进行合并,直到组件数减少到目标数。因此,获得的压缩模型的后验概率最大。优化模型组件,使得压缩的模型比非压缩的模型的同等组件数的模型识别率高。
下面描述如何使用BIC对模型进行压缩。
已知进行模型压缩的数据集合为X,进行模型压缩的模型组件集合为Ck={ci:i=1,2,…,k}。对于混合高斯模型中的每一个组件Ci服从的高斯分布为N(μi,∑i),其中μi是样本的均值向量,∑i是样本的协方差矩阵。这样,混合高斯模型组件的参数数量为设每一个组件中样本的数量为ni,则对于每一个组件的BIC值为:

通过BIC对模型压缩时,每一次将一个模型的2个组件合并成一个,从而使得模型减少1,如果要将一个组件数为m的模型压缩成组件数为n的模型,那么将要进行m-n次合并。压缩的方法是从下而上的,每次合并的2个组件需要满足一定的要求,从而达到压缩后保证识别率尽量高。
设当前的聚簇集合为 S={s1,s2,…,sk},s1与 s2是当前要合并的2个组件,合并s1与s2之后得到新的组件为s,这样得到新的组件集合为S={s,s3,…,sk},模型中的每一个组件si都服从多元高斯分布N(μi,∑i)。根据公式(2),可得到合并s1与s2之后模型组件集合的BIC值与合并之前的BIC值差值为:
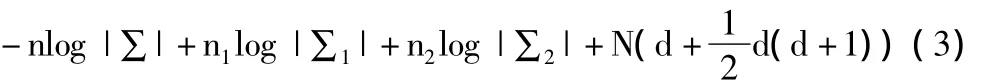
其中n=n1+n2,它是合并之后的组件s的样本大小,∑为合并之后的组件s的协方差矩阵。
本文在使用BIC进行模型压缩时,模型初始组件数为n,目标组件数为m的压缩。每次搜索通过公式(3)计算结果中最大的2个组件,将此2个组件进行合并;然后进行新一轮的搜索、合并,直到组件数达到最终要求个数。
3 实验结果与分析
本文实验中使用的语音模型是利用HTK语音识别系统训练,训练时使用的语料库是WSJ语料库,识别测试时,从WSJ语料库中抽取出来250个句子。一个组件数为8的triphone模型结构如下:

其中~s后面接的是语音模型的名称,<NUMMIXES>后面接的数字表示该模型中所拥有的GMM组建个数。其中每一个组件都拥有<MIXTURE>(后面接的是GMM组件的编号和GMM组件的权重)、<MEAN>(后面接的是均值向量的长度和均值的向量)、<VARIANCE>(后面接的是方差向量的长度和方差的向量)、<GCONST>(后面接一个常数)。从结构上看,每个triphone模型中组件的参数占用的存储空间比重很大,所以本文主要是通过减少GMM模型组件的个数来压缩模型。
在实验中主要对非特定语音模型(不针对特定发音人、环境的语音模型)和做过自适应的特定人语音模型(针对某一特定人进行过自适应的语音模型)进行多阶段压缩,并进行识别结果测试。作为对比,本实验对随机压缩所得到的语音识别模型和未压缩的具有相同组件数的语音识别模型进行识别结果测试,其中随机压缩是指随机抽取待压缩模型的组件进行合并所得到的语音识别模型。
实验1 非特定语音模型识别实验。
将一个大小为156M、组件数为64的非特定语音模型分别压缩至组件数为 32、18、16、12、10、8、6、4 的模型,测试其识别率(接受率),然后作为实验对照,对随机压缩所得到的语音识别模型和未压缩的同等组件数的语音识别模型进行测试识别率,其结果如图1所示。
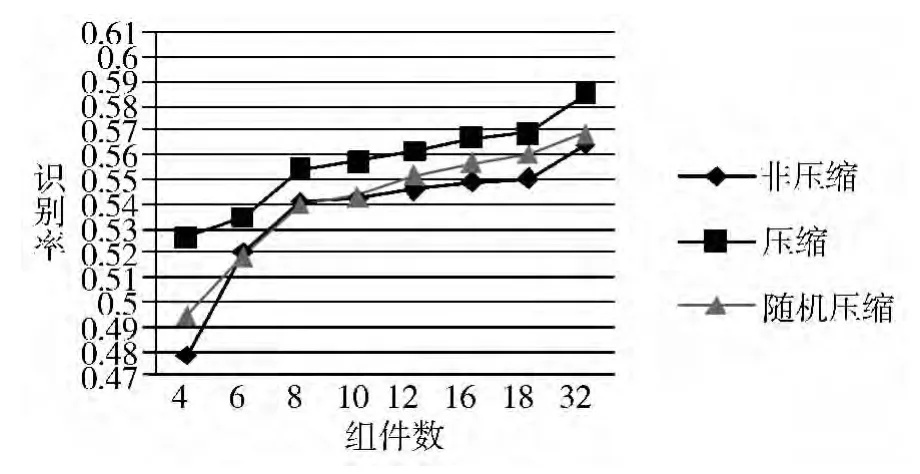
图1 非特定语音模型识别结果
由图1可以看出,由64个组件压缩的指定组件个数的语音模型比未压缩的指定组件数的模型的识别率明显要高,也要比随机压缩到同等组件数的模型的识别率高。
实验2 特定人语音模型识别实验。
把一个大小为156M、组件数为64的特定人语音模型分别压缩至组件个数为 32、18、16、12、10、8、6、4的模型,然后作为实验对照,对随机压缩所得到的语音识别模型和未压缩的同等组件数的语音识别模型进行测试识别率,其结果如图2所示。

图2 特定人语音模型的识别结果
图2的结果进一步表明,对特定人模型压缩的模型比未压缩的同等组件数的模型的识别率要高,也比随机压缩之后的同等组件数的模型的识别率要高。
4 结束语
本文提出利用BIC模型选择准则对模型进行压缩的方法,能够有效地将一个模型压缩成指定组建数量的模型,从而减少模型的大小。本文提出对于模型选择压缩的一个结束条件,是在一定范围内通过人工指定模型的组件数,从而有效地控制模型的大小。实验结果表明,压缩之后的语音模型的识别率比未压缩的相同组件数的模型的识别率要高,也要比随机压缩到同等组件数的模型的识别率高。
[1]Jurafsky D,Martin.Speech and Language Processing:An Introduction to Natural Language Processing,Computational Linguistics,and Speech Recognition(2nd ed)[M].Prentice Hall,2008.
[2]Juang B H,Rabiner L R.Hidden Markov models for speech recognition[J].Te chnometrics,1991,33(3):251-272.
[3]Xie Chen,Adam Eversole,Gang Li,etal.Pipelined Back-Propagation for Context-Dependent Deep Neural Networks[DB/OL].http://research.microsoft.com/apps/pubs/?id=173312,2012-09-10.
[4]Gideon Schwarz.Estimating the dimension of a model[J].The Annals of Statistics,1978,6(2):461-464.
[5]Akaike H.A new look at the statistical identication model[J].IEEE Transactions on Automatic Control,1974,19(6):716-723.
[6]Jin H,Kubala F,Schwartz R.Automatic speaker clustering[C]//Proceedings of the1997 DARPA Speech Recognition Workshop.1997:108-111.
[7]Legetter C J,Woodland P C.Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models[J].Computer Speech and Language,1995,9(2):171-185.
[8]Geoffrey J McLachlan,Thriyambakam Krishnan.The EM Algorithm and Extensions(2nd ed)[M].Wiley,2008.
[9]Lawrence Rabiner,Biing-Hwang Juang.Fundamentals of Speech Recognition[M].USA:Prentice Hall,1993.
[10]Akaike H.A new look at the statistical identification[J].IEEE Transactions on Automatic Control,1974,19(6):716-723.
[11]Schwarz G.A second-order approximation to optimal sampling regions[J].The Annals of Mathematical Statistics,1969,40(1):313-315.
[12]Schwarz G.A sequential student test[J].The Annals of Mathematical Statistics,1971,42(3):1003-1009.
[13]Tong H.Determination of the order of a Markov chain by Akaike’s information criterion[J].Journal of Applied Probability,1975,12(3):488-497.
[14]吴华,徐波,黄泰翼.基于三音子模型的语料自动选择算法[J].软件学报,2000,11(2):271-276.
[15]韩兆兵,贾磊,张树武,等.连续语音识别中声学建模的组合聚类算法研究[J].中文信息学报,2003,17(4):33-38.
[16]郝杰,李星.汉语连续语音识别中经典HMM的实验评测[J].计算机工程与应用,2001,37(13):1-4,101.
