基于Coreseek+Python的分布式全文检索方法
2014-04-11许建南
罗 盘,许建南,李 忠
(1.解放军电子工程学院,安徽 合肥 230037;2.海军指挥学院,江苏 南京 211800)
0 引言
近几年,互联网规模飞速扩张,数据库技术不断进步,数据库用户的数据量也在快速增长,越来越多的企业或网站已经拥有了TB级容量的数据,数据条目已经达到甚至超过了十亿条,互联网已经进入了“大数据”时代。随着数据量的增加,海量数据的存储、搜索和分析成为了新的技术难题,如何从海量的数据库中找到正确有效的记录,已经成为下一代搜索技术的主要竞争点。
对于数据检索技术而言,其性能主要有3个指标:(1)检索对象规模大小。只有足够大的数据规模,其查询结果才能满足用户的需求;(2)性能。搜索引擎需要在短时间内对海量数据进行查询,向用户返回查询结果;(3)搜索结果的质量。保证对关键词的命中率,对无用信息进行过滤,并向用户返回准确的查询结果[1]。
为了提高搜索引擎的性能,目前主流的方法是为数据库建立索引,但是随着数据量的增加,单一服务器的检索性能已经达到饱和。为此,建立分布式检索可以改善查询延迟问题(即缩短查询时间)和提高多服务器、多CPU或多核环境下的吞吐率(即每秒可以完成的查询数)。这对于大量数据(即十亿级的记录数和TB级的文本量)上的搜索应用来说是很关键的。
此外,在对数据库建立索引时,不同的数据库对应不同的操作方式,而且查询手段也有区别,这对传统的数据库搜索引擎提出了挑战——为了使来自不同数据库的数据能够融合,需要在应用层针对不同的数据库进行搜索引擎的设计,或者将不同数据库内的数据迁移到统一的数据库内,这样会增加搜索引擎使用的难度。
本文利用Coreseek全文检索引擎和Python数据源程序接口,实现一个以MySQL数据库为主,可兼容多种类型数据库的分布式全文检索引擎,可向使用者提供更加快速、精确并具有良好数据兼容性的全文检索服务。
1 Coreseek全文检索引擎简介
Coreseek是一款开源的中文全文检索引擎,它在Sphinx(SQL Phrase Index,一个由俄国人 Andrew Aksyonoff开发的高性能独立全文搜索软件包)的基础上,针对中文搜索和信息处理领域进行专门的开发和优化,适用于行业垂直搜索、论坛站内搜索、数据库搜索、文档文献检索、信息检索、数据挖掘等应用场景。
该软件支持多种数据来源,包括MySQL数据库、PostgreSQL数据库、xmlpipe2数据管道,并支持Python可编程数据源。性能方面,该软件具备:
(1)高速建立索引的能力,可在现代CPU上达到10 MB/s的速度。
(2)高速搜索能力,在2~4 GB的文本建立的索引上搜索,平均0.1s内获得结果。
(3)支持大容量数据,在单一CPU上,实测最高可对100GB的文本建立索引。
该软件还支持主从式的分布式搜索,可在单一节点失效的情况下保存正常运行[2]。
Coreseek全文检索引擎主要包括4部分:
(1)indexer:用于创建全文索引;
(2)searchd:一个守护进程,用于向其他软件提供全文检索服务;
(3)sphinxapi:用于向searchd请求服务的客户端API库,默认支持 PHP,Python,Perl,Ruby,Java 等多种语言,也可自行开发客户端API;
(4)mmseg:Coreseek使用的中文分词和词典处理工具库。
2 基于Coreseek+Python的分布式数据检索
2.1 基于Coreseek的分布式处理模型及实现
2.1.1 Coreseek 的分布式处理模型
分布式查询的关键思想是对数据进行水平分区后并行处理,常见的分布式数据库(DDBS)类型包括:同构型(homogeneous)DDBS和异构型 DDBS,其中同构型DDBS又包括同构同质性和同构异质型2种。同构同质型即各个站点上的数据库的数据模型都是同一类型,而且是同一种数据库服务器。同构异质型即各个站点上的数据库的数据模型相同,但是数据库服务器类型不同。异构型即各个站点上数据库的数据模型类型各不相同[3]。
Coreseek能够支持灵活的分布式结构,原因是任意一个searchd实例既可以作为分布式结构的主控端对搜索结果做聚合,也能够作为从属端只进行本地搜索。其基本处理模型如图1所示。
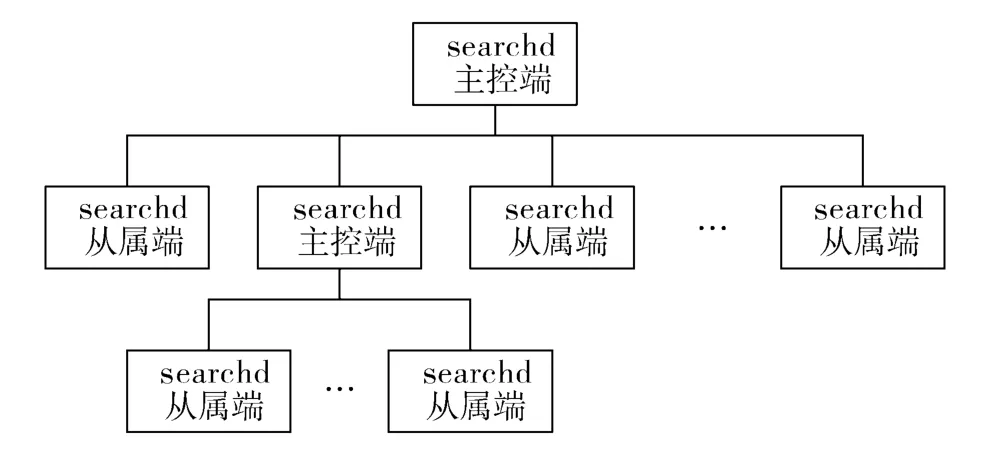
图1 Coreseek分布式处理模型
Coreseek能够提供2种方式的检索服务:
(1)local方式,即将索引文件和searchd放到同一台主机上,由searchd程序直接访问文件系统内的索引文件来进行数据检索;
(2)agent方式,即由searchd启动一个守护进程,该进程会作为从属端为它的主控端提供对本地文件系统内的索引文件进行检索的服务。
当searchd收到一个对分布式索引的查询请求时,它做如下操作(如图2所示):

图2 searchd查询请求处理步骤图
(1)针对收到的查询请求,查询系统配置文件,根据索引声明执行下一步操作;
(2)若索引声明指向本地索引,则对本地索引依次进行搜索,获取查询结果;
(3)若索引声明指向远程代理,则根据指定的主机、端口和索引名连接到远程代理,执行并行查询,获取搜索结果;
(4)对搜索的结果进行合并,删除重复项后返回给客户端。
需要指出的是,本地索引仅使用1个CPU或1个核,同一个代理的多个索引是依次搜索的,要并行处理,可以为每个分布式索引声明多个本地索引,每个本地索引可以在其他分布式索引中多次引用。
2.1.2 利用Coreseek实现分布式处理的过程
(1)系统安装。
Coreseek的系统安装过程比较简单,Coreseek项目网站上提供了针对多种操作系统的程序安装文件和详细的安装手册,可以根据系统情况进行选择并参照手册进行安装。
(2)创建索引。
通常在建立索引时,可直接对整个数据库内的数据建立索引,如果数据规模较大,可以对数据源进行水平分区,并分别建立索引。Coreseek可以利用indexer对数据源建立索引,在建立索引时需要使用conf配置文件,关于conf配置文件详细的配置方法可参考Coreseek使用手册。以MySQL为例,对conf文件的主要配置项进行说明。
一个conf文件至少包含4节内容:source,index,indexer,searchd,其中 source和 index是成对出现,并且可以存在多对,如果对数据库分区,可在同一个配置文件里放入所有index的配置。下面是配置文件内容节选:


配置文件创建完毕后可以使用命令行工具indexer创建索引,初次建立索引时可以使用all参数对配置文件中列出的所有索引进行重行编制索引。执行下面的命令建立索引:
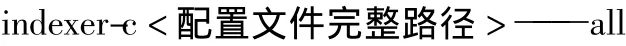
(3)启动从属端searchd守护进程。
通常,在索引文件建立完毕后就能使用searchd提供索引服务,在运行searchd时,需要使用和建立索引时相同的conf配置文件,执行下面的命令创建索引服务守护进程:

此时,searchd会监听一个端口,为其客户端程序提供索引服务,同时还能作为一个从属端,在分布式索引中接收主控端的索引请求。
(4)创建主控端配置文件。
为了实现分布式索引,此处需要建立一个新的conf配置文件,该conf配置文件可以只包含index和searchd两节,下面是一个主控端配置文件的内容节选:


(5)启动主控端searchd守护进程。
主控端配置完毕后可使用searchd启动索引守护进程,并接收客户端的索引请求。在进行检索时,进程会根据配置文件的配置并行地对其从属端进行检索,在获得所有结果后对结果进行去重合并,然后返回给客户端。同时,一个主控端还可以作为其他守护进程的远程从属端。这种配置方式使得Coreseek能够创建极其灵活的分布式结构,用户可以根据索引大小和检索复杂度,对索引文件进行不同层次的分区,达到检索服务的负载均衡。
需要注意的是,主控端的conf文件不能被indexer用于更新其从属端的索引,更新索引时需要在每个从属端进行。
2.2 用Python数据源程序接口处理多种类型数据源的实现
Python是一种面向对象、直译式计算机程序设计语言,其语法简洁而清晰,具有丰富和强大的类库。Coreseek的另一个特性是实现了对Python数据源的支持,因此只需要使用Python连接到其他数据服务器上,就能让Coreseek实现对该数据库的检索。Coreseek在使用Python数据源前需要先安装对应的库文件,这里以连接MSSQL数据库文件为例。首先为Python安装 pymssql库,然后编写 Python代码访问MSSQL数据库服务器,获取数据源。Python代码编写的要点是:创建MainSource类,并实现GetScheme(),GetFieldOrder(),Connected(),NextDocument()4个方法。这4个类的主要功能如表1所示。
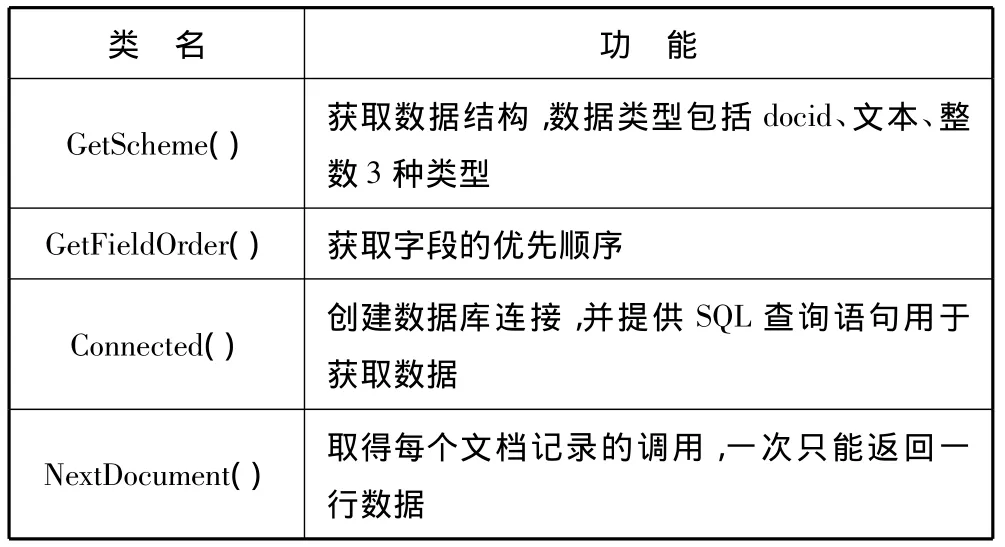
表1 M ainSource类方法功能说明
Coreseek的indexer可以直接访问该Python文件,利用所提供的4个方法取得建立索引所需的所有信息,完成索引的建立。在实际建立索引前,可以使用Python调用上述4种方法连接数据库获得数据,以检查Python获得的数据是否正确。
在使用Python作为数据源时,同样需要conf配置文件,其内容和MySQL的配置文件大致相同,但需要添加和修改一些关键信息,下面是对需要修改的关键内容的节选:

使用Python作为数据源建立索引时,indexer不再受配置文件里mem_limit参数的限制,也就是说indexer可以根据索引源的大小自行获取足够的系统资源,用于索引创建。索引创建完毕后,可使用searchd提供索引服务,同样,可以将searchd作为从属端加入到分布式检索的主控端内,这样可以轻易实现多种类型数据库的数据融合而不需要将数据迁移到统一的数据库服务器上,真正实现了对多种数据源类型的良好兼容性。
3 实验结果及分析
为了测试Coreseek分布式全文检索引擎的性能,在实验室搭建测试环境对检索效率进行实验对比。测试环境使用的主机为普通PC机(主机1作为主要测试平台,系统配置 Intel Core i5-2400@3.10GHz,4G内存;主机2提供分布式检索的一个从属端,系统配置 AMD Athlon IIX4 631@2.60GHz,4G 内存)。数据源为研究室积累的数据库中的6个表,总数据量约为7550万。其中,每个表建立一个索引,分别使用单服务器分布式索引和多服务器分布式索引2种方式进行检索性能测试,并使用MySQL默认的全文检索引擎作为参照,使用相同的关键词进行查询,将查询结果进行比较分析。其结果如表2所示。
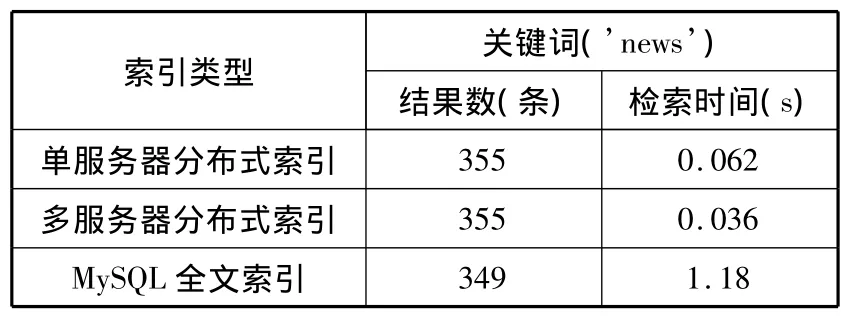
表2 查询结果对比
由表2可知,Coreseek的全文检索引擎速度较快,一般在0.05s内可以得到查询结果,相比MySQL自带的全文检索引擎,速度提升近20倍。使用多服务器的分布式索引比使用单服务器的分布式索引速度提高近2倍。
此外,向Coreseek的分布式索引里添加Python数据源索引作为从属端,进行检索测试,发现Coreseek可以自动将Python数据源的检索结果合并到最后的结果中。因此,Coreseek的分布式结构和对Python数据源的支持这些特性对于客户端都是透明的,这样有利于将Coreseek作为组件应用到更复杂的系统中。
4 结束语
通过构建基于Coreseek的分布式全文检索引擎对大量数据进行检索,无论是检索响应时间还是检索质量,都比MySQL默认的全文检索引擎有较明显的提高。对Python数据源的支持使得Coreseek可以兼容不同类型的数据库,提高了搜索引擎的扩展性。使用Coreseek可以建立灵活的分布式结构,能够充分利用现有的硬件资源实现一个性能优越的全文检索引擎。
[1]蒋建洪.主要分布式搜索引擎技术的研究[J].科学技术与工程,2007,7(10):2418-2424.
[2]Beijing Choice Software Technology Inc.Coreseek开源中文检索引擎功能和特性[DB/OL].http://www.coreseek.cn/products/ft_feature,2013-01-06.
[3]邵佩英.分布式数据库系统及其应用(第2版)[M].北京:科学出版社,2005.
[4]周程远,朱敏,杨云.基于词典的中文分词算法研究[J].计算机与数字工程,2009,37(3):68-71,87.
[5]刘永丹.文档数据库若干关键技术研究[D].上海:复旦大学,2004.
[6]Jain A K,Dubes R C.Algorithms for Clustering Data[M].Prentice-Hall,1988.
[7]Inderjit Dhillon,Jacob Kogan,Charles Nicholas.4 Feature Selection and Document Clustering[DB/OL].http://callisto.nsu.ru/documentation/CSIR/selected/doc_clustering/kogan.pdf,2014-03-20.
[8]Sebastiani F.Text Categorization[DB/OL].http://nmis.isti.cnr.it/sebastiani/Publications/TM05.pdf,2014-03-20.
[9]Zobel J,Moffat A.Inverted files for text search engines[J].ACM Computing Surveys,2006,38(2):1-56.
[10]Guyon I,Elisseeff A.An introduction to variable and feature selection[J].The Journal of Machine Learning Research,2003,3(3/1):1157-1182.
[11]祈延莉,赵丹群.信息检索概论[M].北京:北京大学出版社,2006.
[12]吴栋,滕育平.中文信息检索引擎中的分词与检索技术[J].计算机应用,2004,24(7):128-131.
[13]李志蜀,李果.中文搜索引擎的原理剖析及开发实现技术[J].计算机应用研究,2001,18(11):96-99.
[14]苏云.搜索引擎Google检索技巧研究[J].甘肃科技,2005,21(2):69-71,56.
[15]张彬.面向中文网络信息检索的自动分词系统设计与算法实现[D].上海:华东师范大学,2007.
[16]何晓阳,吴治蓉,连丽红.国内搜索引擎研究状况分析[J].现代情报,2005,25(2):165-167,173.
[17]宛玲,杨秀丹.试析中文搜索引擎的评价标准[J].情报科学,2000,18(1):28-31,38.
[18]孙坦,周静怡.近几年来国外信息检索模型研究进展[J].图书馆建设,2008(3):82-85.
[19]黄昌宁.中文信息处理中的分词问题[J].语言文学应用,1997,21(1):72-78.
