贝叶斯网络在预测银行信贷风险中的应用
2014-03-26周森鑫吴德成
周森鑫,李 超,吴德成
(安徽财经大学 管理科学与工程学院,安徽 蚌埠 233000)
一 引言
随着我国金融体制改革的深入发展,银行作为信贷中心的地位日益突出。与此同时,贷款纠纷不断发生,借款人拖欠贷款的现象非常普遍,拖欠数额也十分惊人,从而严重地影响了信贷工作的正常进行。[1]因此,如果能够根据先前的贷款拖欠数据预测哪些潜在客户可能在偿还贷款时有问题,就可以对这些存在“不良风险”的客户减少贷款额度或者是提供其他产品,这对银行加强风险管理是一个有效途径。
贝叶斯网络(Bayesian network)作为一种概率推理方法,目前已经成为人工智能领域的研究热点之一。[2]但是大多数文献的研究点侧重于谈论贝叶斯网络运用于操作风险管理的思路和框架,结合银行实际操作流程的深入探讨比较少。[3]Alexander(2000,2003)最早研究了贝叶斯网络在特定类型的操作风险方面的应用。国内方面,陆静等(2012)建立了基于贝叶斯网络的商业银行全面风险预警系统。[4,5]刘家鹏(2008)通过建立一个客户流失模型说明了贝叶斯网络的作用。
本文旨在运用贝叶斯网络方法,将已经存在的、表面看似不相关的属性结合起来构建概率模型,以此预测潜在偿还贷款可能存在问题的客户,并通过制定相应的风险控制或为他们提供其1他产品来减少银行贷款风险。
二 CRISP-DM过程描述
CRISP-DM (cross-industry standard process for data mining),即为“跨行业数据挖掘标准流程”,为一个KDD工程提供了一个完整的过程描述。[6,7]该模型将一个KDD工程分为6个不同的阶段。
1.商业理解。
这一阶段的主要任务是确定商业目标,即从商业角度确定项目的目标和所要达到的效果,然后根据这种知识确定数据挖掘的目标。在本文中,该目标就是利用银行现有的真实数据,采用最合适的任务安排和挖掘算法,为银行提供一个现成可用的,经过评估的贷款拖欠者预测模板,而不需要用户自己建立模型就可以解决实际问题。
2.数据理解。
数据理解的关键是数据源的选择。本示例为了获得现有的贷款拖欠数据,需要从名为 bankloan.sav 的数据文件中把流bayes_bankloan.str选择出来。然后为数据源添加一个类型节点,我们可以看出,影响default的因素有:年龄、学历、最近工作的工龄、收入、信用卡债务、其他债务......
3.数据准备。
在构建模型时,有些目标字段的值不完整或者是空值,如果不经过数据的处理直接进行数据的使用,可能会导致预测结果的错误,为了排除这些观测值以防止在模型评估中使用,就需要对数据进行处理。在例中,我们为类型节点添加一个选择节点,并在在“条件”框中,输入 default = '$null$',这样就可以达到对数据进行缺失处理的目的。
4.模型建立。
Clementine提供了多种预测算法,如C5.0、神经网络、Logistic回归等,本文中我们选用贝叶斯网络节点建模,具体的操作过程如下所示。
Step 1 :将一个类型节点添加到源节点bankloan.sav,并将default字段的方向设置为输出,其他所有字段的方向设置为输入。
Step 2 :由于我们构建了多个不同类型的贝叶斯网络,要对它们进行比较,从而确定哪个模型具有最好的预测效果。因此我们在选择节点之后添加三个贝叶斯网络节点,将模型的名称分别设置为“TAN”“Markov”“Markov-FS”,其中第三个模型不仅具有马尔科夫覆盖结构,而且使用了特征选择预处理来选择与目标变量有重大关联的输入。
Step 3 :通过运行上述三个贝叶斯网络节点就可以生成相应模型,在这里我们可以查看它们的详细信息,如图1所示。可以看出,左列包含节点网络图,可显示目标与其最重要预测变量之间的关系,以及各预测变量之间的关系;右侧显示变量的重要性,它表示评估模型时每个变量的相对重要性。
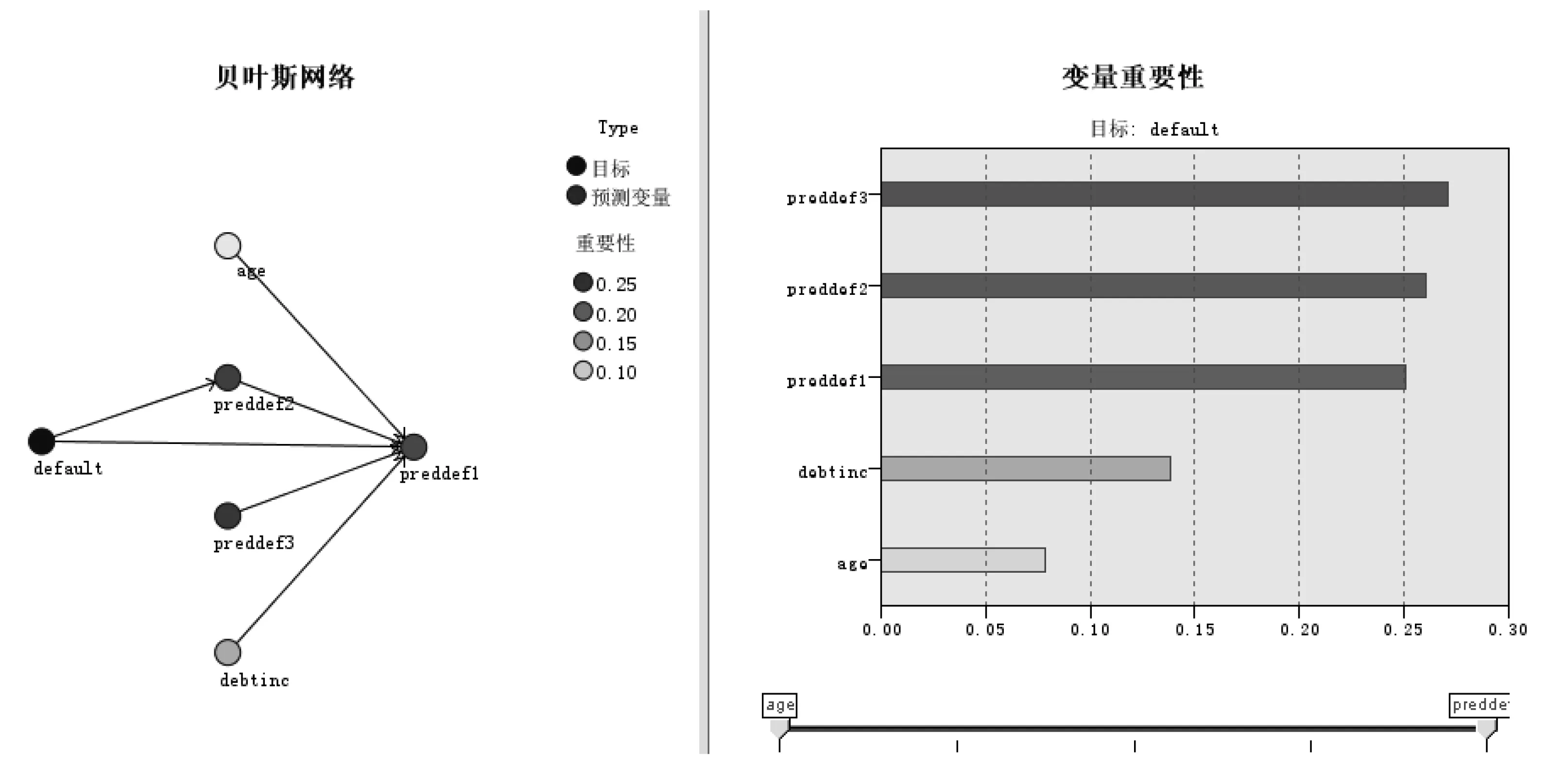
图1 贝叶斯网络及变量重要性图
Step 4 :将TAN模型块附加到选择节点,将Markov模型块附加到TAN节点,将Markov-FS模型块附加到Markov节点。
Step 5 : 为了避免输入,要重新命名评估图形上的模型输出。将过滤节点附加到 Markov-FS 模型块。在右侧的字段栏中,将 $B-default、$B1-default 和 $B2-default 分别重新命名为 TAN、Markov和 Markov-FS。
Step 6 :将评估图形节点附加到过滤节点上,然后使用图形节点的默认设置来执行它。这样就可以生成一个收益图表。

图2 模型评估结果图
图2显示,每个模型类型都生成了相似的结果,但是马尔可夫模型要稍微好一些。但是要检查每个模型的预测效果,我们更倾向于使用分析节点而不是评估图形。
三 模型分析
为了从多种模型中选择最佳预测效果的模型,需要利用预测集的数据来检验模型的准确度,对数据流的执行结果进行评估。我们将分析节点附加到过滤节点上,然后使用分析节点的默认设置来执行。在完成模型实施阶段之后,数据流设计中的数据流图如图x所示:
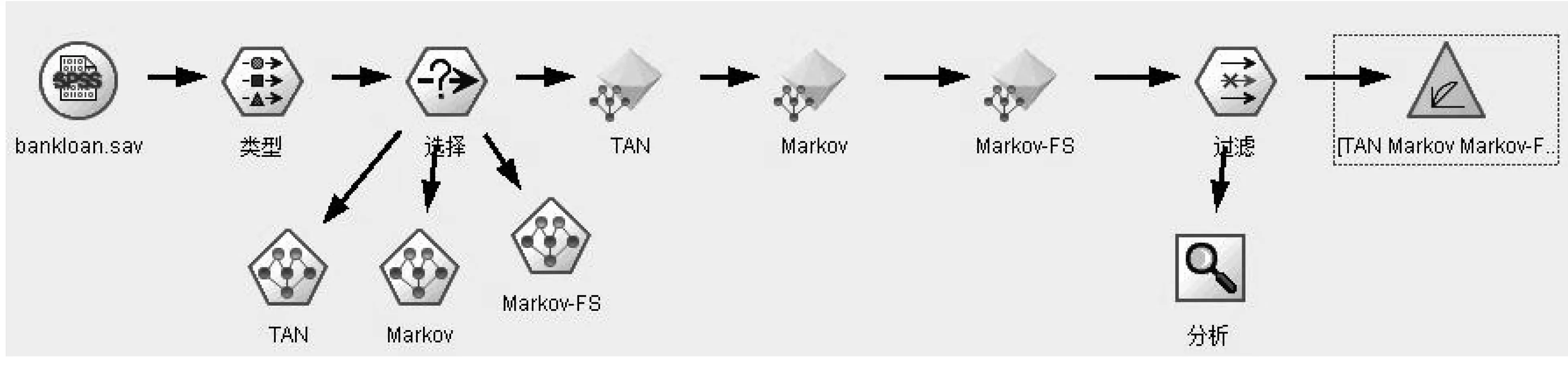
图3 模型实施阶段数据流图界面
图3展示了数据挖掘流程的一个完整过程,这些步骤是在数据挖掘工具的指导下一步步自主建立的。完全符合CRISP-DM标准流程,并且将数据挖掘的流程可视化地展示在用户面前,能够让用户了解并指导数据挖掘的全过程。
通过运行分析节点,我们可以得到每个模型的预测效果,具体结果如图4所示:

图4 模型预测数据分析图
图4显示了依据正确和不正确的预测百分比得出的准确性。就像前面的“评估图形”一样,本图显示马尔可夫模型在正确预测方面要稍微好一些,但是,Markov-FS 模型仅落后马尔可夫模型几个百分点。这可能就意味着使用 Markov-FS 模型要更为方便一些,因为它计算结果所需的输入更少,因此节省了数据收集和输入的时间以及处理时间。
四 总结
首先,本文详细地介绍了数据挖掘工具在预测银行贷款拖欠方面的实际需求,通过一个简单、完整的实例,从商业理解、数据理解、数据准备、模型建立、模型比较到部署实施,将CRISP-DM通过可视化的方式展示出来,最后通过对实际数据的分析结果,得出最准确的预测模型,并且使用户能够很容易的掌握数据挖掘的具体操作,具有切实可操作性。
其次,贝叶斯网络建模灵活性,且预测结果不会受个别损坏的历史数据的影响。这就使得该方法在流程和环境时刻变化、操作风险和损坏数据缺乏的银行业具有无可替代的优势。同时,基于贝叶斯网络强大的演算推理功能,可以精确地预测出各个变量的影响程度,使得银行在风险控制方面更具主动权。
[1]吕文江. 当前拖欠银行货款的原因、后果及对策[J].政治与法律,1990(5):48-49.
[2]Jia wei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2008.
[3]陆静,王捷.基于贝叶斯网络的商业银行全面风险预警系统[J].系统工程理论与实践,2012,32(02):225-235.
[4]刘睿等.运用贝叶斯网络量化和控制商业银行操作风险[J].投资研究,2011,30(07):106-117.
[5]陆静,唐小我.基于贝叶斯网络的操作风险预警机制研究[J].管理工程学报,2008(04):56-61.
[6]百度百科,CRISP-DM定义. http://baike.baidu.com/link?url.
[7]郭鑫.基于CRISP-DM的流程可视化数据挖掘工具的研究与实现[D].上海:东华大学,2009.
[8]Alexander, C Bayesian Methods for M easuring Operational Risk[J].Derivatives, Use Trading and Regulation, 2000,6(2):166-186.
