基于OpenFlow的报文分类算法研究与实现*
2014-03-23吕昭,李韬
吕 昭,李 韬
(国防科学技术大学计算机学院,湖南长沙410073)
1 引言
随着互联网的发展,今天的互联网业务对互联网提出了越来越高的传输质量要求,为了满足互联网新的业务需求,斯坦福大学提出了一种新型网络交换模型—Open Flow。OpenFlow的开放性和创新的网络互连概念使其发展迅猛,成为近年来新兴的热门技术。
OpenFlow 1.1规范[1]规定流表项由头域、计数器和操作组成,其中头域是一个15元组,是流表项的标识;计数器用来计数流表项的统计数据;操作标明了与该流表项匹配的数据包应该执行的操作。通过将数据流与流表中的流表项匹配,从而决定转发的目的端口。与传统的报文头5元组匹配规则相比,OpenFlow的15元组规则更加增加了数据流匹配的难度[2]。因此,15元组匹配的报文分类是研究OpenFlow报文分类技术的重点和难点。
2 报文分类问题
2.1 报文分类问题描述
由于互联网应用中多样化和差异化的需求,网络设备需要能够根据网络中报文字段对报文进行差异化处理。报文分类就是为了满足网络的差异化处理而产生的。它是根据报文头部信息的关键字段对报文进行分类,网络设备针对不同类别的报文可以采取不同的操作[3]。
报文分类的分类器一般都包含一个分类规则库,该规则库含有几百到几百万条过滤规则(F1,F2,F3,…,Fn)。每条过滤规则可以含有s个匹配域(Fi[1],Fi[2],…,Fi[s]),其中每个匹配域都对应报文的一个头字段。过滤规则的域有四种表达形式,可以是一个精确的值,也可以是前缀表示(常用于地址匹配)、范围表示(常用于端口号匹配)或含有通配符表示[4]。
每个头字段具体的匹配方式由过滤规则相应域的表达形式决定,共有三种不同的匹配方式:
(1)精确匹配:报文头字段的值与过滤规则匹配域的精确值匹配。
(2)前缀匹配:报文头字段的值符合过滤规则匹配域规定的前缀。
(3)通配符匹配:报文头字段的值符合过滤规则规定的任意比特掩码(Arbitrary Bitmask),如过滤规则01*1,第三位为0或1时均可以匹配。
当一个报文的d个头字段与一条过滤规则的全部d个域均匹配时,就称该报文匹配该规则。由于过滤规则的交叠性,一个报文可能匹配规则库中的多条过滤规则,因此选取这些过滤规则中优先级最高的规则进行匹配[5]。
2.2 相关工作
按不同的匹配方式可以将报文分类算法进行分类:
适合精确匹配的报文分类算法主要有简单的线性匹配、基于Hash的匹配等算法。其中简单的线性匹配实现简单,但查找效率差,大部分基于精确匹配的报文分类算法都是基于Hash函数的。
适合前缀匹配的报文分类算法主要有基于查找树的算法,如Grid-of-trie算法、BV和ABV算法以及HiCuts算法与HyperCuts算法等。
适合统配匹配的报文分类算法主要有基于硬件TCAM以及有限状态机匹配等算法,其中,TCAM算法匹配速度快,但是功耗成本过高。有限状态机匹配速度没有TCAM快,但是成本功耗较低,适合大型规则库。
3 OpenFlow报文分类问题
OpenFlow是一个软硬件的网络流转换接口。它的核心思想很简单,就是将原本完全由交换机/路由器控制的数据包转发过程,转化为由Open-Flow交换机(Open Flow Switch)和控制服务器(Controller)分别完成的独立过程。转变背后进行的实际上是控制权的交换。Open Flow交换机会在本地维护一个与转发表不同的流表(Flow Table),如果要转发的数据包在流表中有对应项,则直接进行快速转发;若流表中没有此项,数据包就会被送到控制服务器进行传输路径的确认,再根据下发结果进行转发。OpenFlow的开放性和创新的网络互连概念使其发展迅猛,成为近年来新兴的热门技术。
Open Flow定义的流规则可以通过用户的需求来设定。OpenFlow灵活的流报文分类可以被看做传统五域分类的拓展[6]。Open Flow规范1.1对于每一个报文需要匹配的bit数从104增加到278,每个报文对15个字段进行所有的报文规则匹配。15个报文头字段包括32位的Ingress port,64位的Metadata,18位的源/目的以太网地址,16位的以太网类型,12位的VLAN号,3位的VLAN优先级,20位的MPLS标签,3位的MPLS流量类,32位的源/目的IP地址,8位的IP协议号,6位的Tos号以及16位的源/目的端口号。规则中字段的每一位可以被指做准确的数字或者是通配符,IP地址字段也可以作为一个前缀[1]。
OpenFlow交换机需要对15个报文头字段进行分类匹配,并且针对每一个规则,报文头各个字段都会进行不同的匹配方式,因此给报文分类带来了更大的困难。针对Open Flow的报文分类问题,把规则字段做一个简单的分类,其中Ingress port、Metadata、以太网类型、VLAN号、VLAN优先级、MLPS标签、MPLS流量类、IP协议号、IP Tos号、源/目的端口号均需要进行精确匹配。源/目的以太网地址可以进行通配符匹配,源/目的IP地址可以进行前缀匹配或者通配符匹配。针对前缀匹配问题,已经有人进行了充分的研究,并且前缀匹配实际上是通配符匹配的一种特例。因此,本文将主要研究精确匹配和源/目的以太网地址和源/目的IP地址的通配符匹配。
本文将采用分而治之的思想,如图1所示。首先将这些字段分为需要进行精确匹配的字段和需要进行通配符匹配的字段。然后,将这两类字段分别在精确匹配引擎和通配符匹配引擎中进行规则匹配,分别得出匹配结果。最后将这两个引擎匹配的结果进行汇总,最终匹配到一个优先级最高的规则。这样分开处理可以有效提高报文分类的效率。
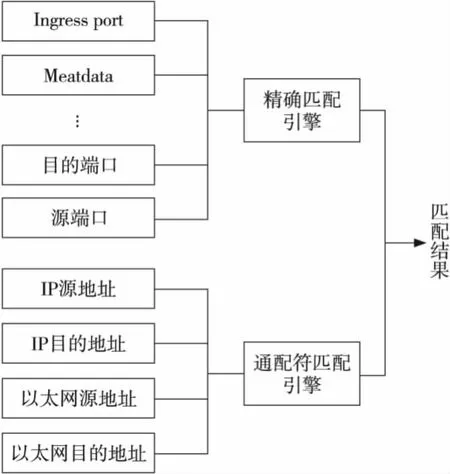
Figure 1 Schematic diagram of packet classification for Open Flow图1 OpenFlow报文分类示意图
本文中大部分字段都是基于精确匹配,基于Hash的报文分类算法Bloom Filter[7,8]在基于软件的设计基础上[9],具有很好的性能和效率,能够支持较大规模的规则库。因此,精确字段匹配引擎通过Bloom Filter进行设计实现。源/目的以太网地址和源/目的IP地址基于通配符匹配,可以通过TCAM[10]进行匹配。但是,TCAM自身具有功耗大、成本高的缺点,并且不适合大型的规则库。因此,本文提出了复杂字段匹配采用正则表达式匹配,通过构建有限自动机的方法来进行设计实现。这种方法具有良好的性能和效率,与TCAM相比成本较低,并且适合大型的规则库[11]。
4 基于Bloom Filter的精确报文分类算法
Bloom Filter基于Hash查找,在报文不命中的情况下分类效率大大高于哈希链表方法,对于需要进行精确匹配的字段具有很高的分类效果,并且适合硬件实现。因此,本文实现了一种改进型的计数型链表Bloom Filter算法(OF_CBF Open Flow_Counter Bloom Filter)进行报文的精确匹配。
4.1 OF_CBF算法设计
对Bloom Filter进行规则的插入不会产生任何问题,但是对Bloom Filter进行删除规则操作会存在一定的问题。如果将被删除数据产生的k个索引值对应的特征向量中的值置为0,则有可能导致数据集合中产生相同索引值的其他元素查询失败。为了解决Bloom Filter删除规则,提出了计数型Bloom Filter[12]的概念。在一个计数型Bloom Filter中,每个索引值对应的特征向量不再是单独的一位,而是一个计数器。图2显示了计数型Bloom Filter的基本结构。其中X、Y、Z为报文规则,特征向量由计数器代替原来的一位表示。其中Hash函数个数k=2。如图2所示,当插入一个数据时,索引值对应的计数器数值加1;同样,当删除一个数据时,计数器的数值减1。
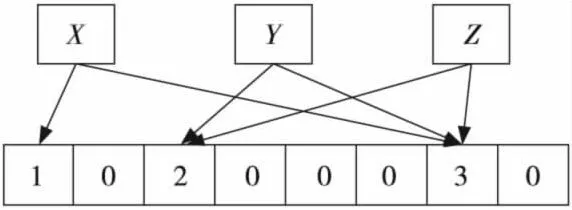
Figure 2 Counting bloom filter图2 计数型Bloom Filter
不难发现,计数器的数值反映了产生相同索引值的数据的个数。此时需要考虑的问题是对计数器的大小要选取适当,避免出现数值溢出的情况。
本文针对Bloom Filter查找方面的特点,面向Open Flow的简单字段进行精确的报文匹配,并且基于网络处理器的硬件结构,将计数型Bloom Filter与动态链表进行有效结合,提出OF_CBF算法。动态链表的作用是存储规则以便查询时进行精确匹配。对于每个规则首先执行k次Hash计算,然后根据得到的j(≤k)个Hash key访问特征向量,以特征向量为纽带,并行对动态链表进行相应的操作,同时使用动态链表进行精确匹配可以有效解决假阳性的问题。
OF_CBF算法有如下特点:
(1)运用计数型Bloom Filter来代替标准的Bloom Filter。计数型Bloom Filter不仅完全具备了标准Bloom Filter的一切性能,而且很好地解决了集合中规则删除时可能产生的查询失败问题。
(2)在计数型Bloom Filter查询结果的基础上,引入动态链表执行规则的精确匹配。不论是标准Bloom Filter还是计数Bloom Filter,其假阳性的产生是不可避免的,只能通过对某些参数的设置来使其产生的概率最小。在此动态链表提供精确匹配的目的是及时对假阳性进行检测,对错误匹配结果做出更正,提高报文分类算法结果的准确性。
图3是一个OF_CBF的结构示例,图中计数器为每一个特征向量对应的计数器,首地址为每一个特征向量对应的存储规则的动态表项,X、Y为报文规则。
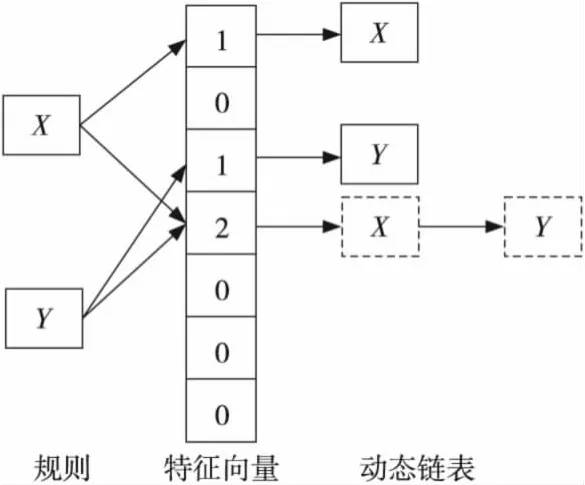
Figure 3 Schematic diagram of OF_CBF图3 OF_CBF结构示意图
本文提出的OF_CBF算法针对传统的计数型链表Bloom filter的存储规则进行了改进,减少了存储空间。由于添加每个规则,都会产生j个Hash key访问特征向量,而每个特征向量对应的链表均会存储该规则,这就会造成存储器的浪费。OF_CBF算法对这种情况进行了存储规则操作的优化,只访问最小的Hash key对应的特征向量,然后将规则存储在该特征向量对应的链表中。这样就避免了在不同的特征向量对应的动态链表中重复存储同一规则。图3中实线部分即为特征向量对应存储的动态链表,而虚线即为存储优化后不用存储的特征向量。由图3可以看出这个方法可优化大量的存储空间。
上述两个特点很好地反映出OF_CBF算法的本质。OF_CBF充分发挥了Bloom Filter基于Hash查找、针对报文的精确匹配的优势;同时,釆取有效措施尽力弥补其在删除规则和假阳性等方面的不足,使得Bloom Filter能够在报文分类领域有新的应用。
4.2 OF_CBF算法验证与分析
将算法OF_CBF用硬件语言实现后,再通过Xilinx公司生产的型号为V5系列的240T上进行综合实现,并对算法的功能和性能进行验证。
(1)功能验证。分别采用不同的Hash函数,首先通过大量随机报文,以检验报文分类结果是否正确。再将规则边沿的特定报文进行测试,以检测算法功能的完备性。经过测试,所有报文分类结果均正确无误,从而验证了算法功能的正确性。
(2)性能验证。通过不同Hash函数个数,再添加不同数量的规则来进行算法性能的验证。表1为不同Hash函数个数情况下,规则库个数不同时,通过器件进行综合实现得出的时钟频率表。
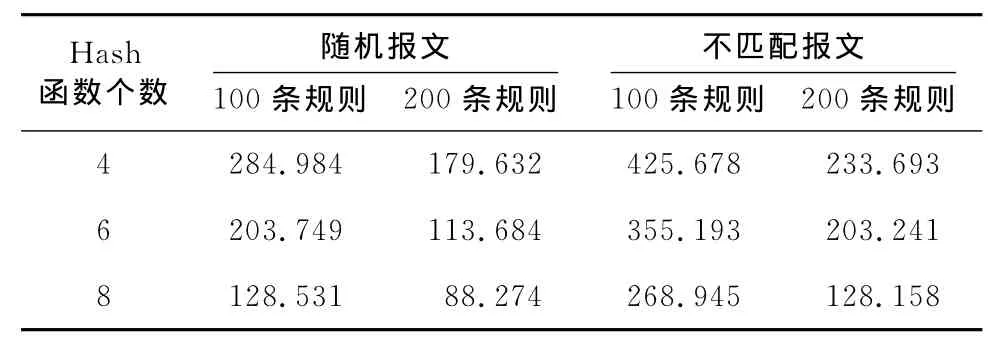
Table 1 Performance testing of OF_CBF表1 OF_CBF算法性能测试对比结果 MHz
通过表1可以看出,随着Hash函数个数的增加,算法匹配频率减小,说明算法匹配速度随着Hash函数个数增加而减小。而随着规则数目的增加,算法匹配的速度也逐渐减小。
同时可以看出,在4个Hash函数的情况下,当规则库有100条规则时,均不匹配的报文通过时的平均最快时钟频率为425.678 MHz,大于随机报文匹配的时钟频率284.884 MHz。这是由于OF_CBF的特点是先进行Hash索引,找到对应的特征向量进行查看,对应的特征向量匹配后再进行链表的精确匹配。因此,对于OF_CBF算法不匹配的查找开销要小于匹配的查找开销。
假设OF_CBF存储有n条规则,特征向量为m bits,计数器a位,存储器地址b位。对每一条规则我们用k个Hash函数对它进行运算,这些Hash函数的输出是[1,m]的值,规则字段的最长长度为d。对一个规则进行Hash计算平均得到j个Hash key。设k个Hash函数的运算是并行的,时间开销为1。
5 基于有限自动机的通配报文分类算法
正则表达式是对字符串操作的一种逻辑公式,是用事先定义好的一些特定字符及这些特定字符的组合,组成一个规则字符串,用这个规则字符串来表达对字符串的一种过滤逻辑[13]。
通过正则表达式进行通配符匹配是可行的[14]。而通过分析,正则表达式的匹配原理是有限自动机的匹配,正则表达式的匹配与有限自动机匹配是等价的,因此有限自动机的匹配实际上可以实现正则表达式的匹配。而有限自动机可以有效地在硬件中实现,因此我们可以通过有限自动机实现报文分类中的通配符匹配。通过一定的算法将正则表达式转换为有限自动机,从而实现高效的报文匹配操作[15]。
5.1 OF_FSMP算法设计
综上所述,通过将报文规则的正则表达式转换为有限自动机的方法可以有效解决报文分类问题。因此,本文设计实现了基于有限自动机的报文匹配算法——OF_FSMP算法,用以解决网络处理器中面向Open Flow的通配符匹配问题。
(1)OF_FSMP算法结构。OF_FSMP算法通过存储器将相应的状态数、匹配结果以及最终状态标志位进行存储。设地址位为n位,则地址位的前(n-1)位为当前的状态数,第n位当前输入条件,即当前应该输入的报文的某一位。而存储器存储的信息分为下一跳的状态数、终止状态标志位以及结果位。因此,设当前状态数为state,则mem[state,Pkt[i]]为存储的下一跳状态数据结构。以此来跳转最终输入匹配结果。
(2)OF_FSMP算法设计。OF_FSMP算法主要包含三个步骤:构建自动机、存储自动机和通过自动机匹配规则。其中,构建状态机又包含添加规则和删除规则。构建状态机和通过存储器的数据结构存储状态机的过程均是通过软件实现的。报文匹配的过程是通过硬件实现的。图4是OF_FSMP算法的流程图。

Figure 4 Schematic diagram of OF_FSMP图4 OF_FSMP算法结构示意图
OF_FSMP算法的匹配报文模块通过状态机实现。其中Pkt_Valid为报文有效信号,当Pkt_Valid=1时输入的Pkt信号有效。Res_Valid信号为结果有效信号,Ready信号为准备信号,Ready=1算法可以开始下一次匹配。状态机如图5所示。其中,
WAIT状态为初始等待状态;若Pkt_Valid=1,则转到INI状态。
INI状态为初始化状态,将查询状态置0,转到PRO状态。
PRO状态为查询过程。通过当前的查询状态,将报文的每一位当做输入,进行查询状态的转换,最终当转换到最终状态时,转到FINISH状态。否则转到PRO状态,继续进行查询。
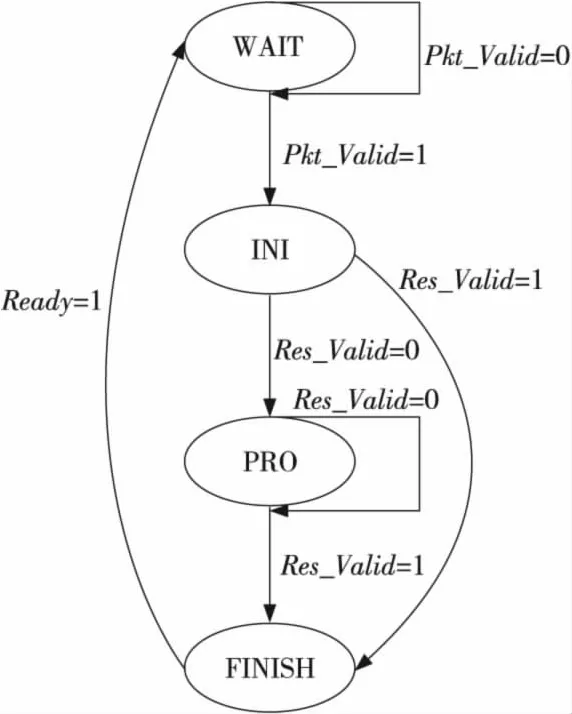
Figure 5 State machine of OF_FSMP图5 OF_FSMP算法状态机
FINISH状态为停止状态,若Ready信号置1,则转到WAIT状态。
5.2 OF_FSMP算法验证与分析
将算法OF_FSMP用硬件语言实现后,再通过Xilinx公司生产的型号为V5系列的240T进行综合实现,并对算法的功能和性能进行验证。
(1)功能验证。先通过软件协同,将系统匹配的规则进行存储,再测试大量随机报文。经过测试,所有报文分类结果均正确无误,从而验证了算法的功能正确性。
(2)性能验证。与Net Logic公司33100系列TCAM对比,进行性能验证。表2是TCAM与通过FPGA综合实现的OF_FSMP算法的性能对比情况。

Table 2 Performance testing analysis of TCAM and OF_FSMP表2 TCAM与OF_FSMP算法性能对比
通过表2进行纵向比较,我们可以看出随着规则库的增加,OF_FSMP算法的空间消耗变大,匹配速度变慢。这是由于用于匹配的有限自动机规模增加。但是,由于可以通过前期软件协同优化有限自动机,使其空间消耗变大的趋势和匹配速度减慢的趋势越来越小,说明算法比较适合大规模规则库的扩展。通过表2进行横向比较,我们可以看出在空间消耗和匹配速度上,OF_FSMP算法均不如TCAM算法。虽然TCAM具有良好的查询性能,但其实现1 bit的查询功能需要10~12个晶体管,而SRAM只需4~6个晶体管[16]。因此,TCAM相比OF_FSMP算法存在功耗高、价格贵的缺点。
假设OF_FSMP算法合并后的状态数为s,则算法最坏情况下的时间复杂度为O(s),即将所有状态都遍历了一遍。最好情况下的时间复杂度是1,即为直接匹配。OF_FSMP算法的空间复杂度为O(s·(2+log2s))。OF_FSMP算法实现的硬件开销较小,并且具有较高的匹配速度,在实际应用下的效率较高。适合针对网络处理器,面向OpenFlow的通配符匹配进行高效的报文分类。
6 结束语
当前的网络技术高速发展,网络流量不断增加,网络应用技术不断更新,为了满足互联网新业务的需求,OpenFlow技术营运而生并得到了快速的发展。Open Flow技术对于报文的处理是以报文分类作为支撑的。本文针对OpenFlow报文分类的不同匹配方式,通过Bloom Filter实现了一种面向OpenFlow精确报文分类的算法——OF_CBF,通过正则表达式和有限自动机的匹配,实现了面向OpenFlow通配符报文分类的算法——OF_FSMP。这种分而治之的方法可以有效解决OpenFlow基于多元组的灵活的匹配规则。下一步的工作重点是进行大量的报文分类实验分析,进一步完善优化算法。
[1] Open FlowSwitch specification 1.1.0[EB/OL].[2013-07-21].http:∥www.openflowswitch.org/doucuments/openflow-spec-v1.1.0.pdf.
[2] Jiang W,Prasanna V K.Scalable packet classification on FPGA[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2012,20(9):1668-1680.
[3] Song H,Lockwood J W.Efficient packet classification for network intrusion detection using FPGA[C]∥Proc of the ACM/SIGDA 13th International Symposium on Field-programmable Gate Arrays,2005:238-245.
[4] Sun Yi,Liu Tong,Cai Yi-bing,et al.Research on packet classification algorithm[J].Application Research of Computers,2007,24(4):5-7.(in Chinese)
[5] Gao Lei,Tan Ming-feng,Gong Zheng-hu.Survey and evaluation of IP packet classification algorithms[J].Computer Engineering &Science,2006,28(3):70-73.(in Chinese)
[6] Ganegedara T,Jiang W,Prasanna V.FRUG:A benchmark for packet forwarding in future networks[C]∥Porc of 2010 Performance Computing and Communications Conference(IPCCC),2010:231-238.
[7] Dharmapurikar S,Krishnamurthy P,Sproull T S,et al.Deep packet inspection using parallel bloom filters[J].Micro,IEEE,2004,24(1):52-61.
[8] Bin Xiao,Yu Hua.Using parallel bloom filters for multiattribute representation on network services[J].IEEE Transactions on Parallel and Distributed Systems,2010,21(1):20-32.
[9] Bloom B H.Space/time trade-offs in Hash coding with allowable errors[J].Communications of the ACM,1970,13(7):422-426.
[10] Chisvin L,Duckworth R J.Content-addressable and associative memory:Alternatives to the ubiquitous RAM[J].IEEE Computer,1989,22(7):51-64.
[11] Liang Zhong-bin,Lan Ju-long,Xia Bin.Range encoding scheme based on TCAM packet classification[J].Network and Communication,2010,36(8):117-119.(in Chinese)
[12] Guo D,Wu J,Chen H,et al.Theory and network applications of dynamic bloom filters[C]∥Proc of the 25th IEEE INFOCOM’06,2006:1-12.
[13] Chen Qian.A fast string matching algorithm based on finite automation[J].Computer Technology and Development,2009(1):131-133.(in Chinese)
[14] Aho A V,Corasick M J.Efficient string matching:An aid to bibliographic search[J].Communications of the ACM,1975,18(6):333-340.
[15] Li Gang,Wu Liao-yuan,Zhang Ren-bing,et al.Research on algorithm of finite-automaton-based pattern matching and its applications[J].Journal of System Simulation,2007,19(12):2772-2775.(in Chinese)
[16] Chen Shu-hui,Sun Zhi-gang,Su Jin-shu.Research on range matching for wire-speed hardwares NIDS[J].Journal of Communications,2006,27(10):7-12.(in Chinese)
附中文参考文献:
[4] 孙毅,刘彤,蔡一兵,等.报文分类算法研究[J].计算机应用研究,2007,24(4):5-7.
[5] 高蕾,谭明峰,龚正虎.IP报文分类算法综述与评价[J].计算机工程与科学,2006,28(3):70-73.
[11] 梁仲斌,兰巨龙,夏斌.基于TCAM报文分类的范围编码方案[J].网络与通信,2010,36(8):117-119.
[13] 陈倩.一种基于有限自动机的快速串匹配算法[J].计算机技术与发展,2009(1):131-133.
[15] 李钢,吴燎原,张仁斌,等.基于有限自动机的模式匹配算法及其应用研究[J].系统仿真学报,2007,19(12):2772-2775.
[16] 陈曙晖,孙志刚,苏金树.线速硬件网络入侵检测系统的范围匹配研究[J].通信学报,2006,27(10):7-12.
