威布尔脆弱性比例危险模型的等级似然估计和应用*
2014-03-23王宁宁徐淑一
王宁宁,徐淑一
(1.广州医科大学公共卫生学院,广东 广州 510182;2.中山大学岭南学院,广东 广州 510275)
Cox[1]比例危险模型自从1972年提出以来一直是占据生存数据分析的主要模型,在面对同一个体的重复观测时(或者数据按照不同来源分组时),对生存数据的建模需要考虑个体的异质性影响。Keyfitz和Littman发现忽略个体的异质性会导致对协变量系数的估计有偏。Hougarrd与Aalen也发现,忽略个体的异质性时,估计出的相对危险率都有偏高的倾向,Lancaster对失业持续时间建模时,发现模型中忽略脆弱性因子会导致低估协变量效应。Pickles等[2]对脆弱性模型的回顾性总结中表明,一般来说,模型中忽略异质性的影响会使得协变量系数的估计向0这个方向接近。将脆弱性(Frailty)因子引入模型就是考虑到这种不可忽略的异质性。脆弱性模型是Cox提出的比例危险模型的一个推广,脆弱性模型允许同一个体的重复观测数据之间或者同一个组内的个体之间具有相关性,广泛应用于多元生存数据分析中。
经典的脆弱性比例危险模型h(tij|vi)=h0(tij)exp{xijβ+vi}=h0(tij)exp{xijβ}ui,下标ij表示第i个体的第j次重复观测。除了参数向量β之外,v的分布函数F(v)以及基本危险率h0都是未知的。在很多脆弱性比例危险模型的应用中,基本危险率通常认为是不规则的形式,通过非参数方法估计。有很多学者对基本危险率是非参数设定的脆弱性模型的估计进行了研究,McGilchrist 和Aisbett以及McGilchrist研究了对数正态脆弱性模型,利用Cox的部分似然(Partial Likelihood)方法估计参数,并且使用这种模型来分析肾感染的数据,但是没有处理数据打结的情况。近年来的研究主要集中于非正态脆弱性模型的估计,比如,出于数学上处理的方便,Klein及Nielsen等建立了伽马(Gamma)脆弱性模型的EM算法。Hougaard建议了三种脆弱性因子的分布:伽马分布、逆高斯(Inverse Gaussian)分布和正稳定(Positive stable)分布,Hougaard[3]详细讨论了脆弱性因子的分布的选择。EM算法在估计带有不可观测的协变量模型是很有用的技术,见Mclachlan等[4]。EM算法的收敛对初始值的选择和停止计算的规则非常敏感,而且EM算法需要脆弱性因子在给定观测数据下的条件期望,除了伽马分布,逆高斯分布等几种特定的分布,一般情况下,无法写出解析表达式,而是需要数值算法,而且参数估计的方差也不能直接获得(Louis,Jamshidian等[5])。
由Lee等[6]提出的带随机效应的广义线性模型的等级似然(Hierarchicacl Likelihood)估计方法,允许随机效应因子是任何分布,等级似然方法近年来开始应用于生存数据的混合模型估计,展现了良好的应用前景。Ha等[7]将等级似然估计方法用于脆弱模型的估计,估计了随机效应(脆弱性因子)呈正态分布和Gamma分布的情形,并证明了在给定随机效应分布参数的情况下,最大化边际似然得到的协变量系数估计和最大化等级似然得到的协变量系数估计是一致的。自此,等级似然估计方法在纵列数据的生存分析与混合模型方面的应用研究进一步展开,如Ha等[8-9]、徐淑一等[10]的研究。近年来学术界关于等级似然方法的应用研究仍在继续,如Lee等[11]使用等级似然方法估计预测疾病测绘时相对风险的的区间,模拟显示其不弱于贝叶斯方法。Noh等[12]使用等级似然建立非线性混合效应模型处理纵向数据。Noh等[13]使用等级似然方法提供了一种减弱对数据缺失机制不正确假定的影响并提供了实例和模拟研究。Lee等[14]把等级似然函数方法用于缺失数据的建模并应用于厚尾分布的纵向数据分析。Wu等[15]使用等级似然解决因子分析模型中二元相应变量的情形,使用简单而且高效。王宁宁等将该方法推广到AR(1)相依结构的脆弱性模型研究。
本文考虑Cox比例危险的脆弱性模型,允许数据打结以及删失的情况下,假设脆弱性因子服从威布尔分布。对固定参数的估计和随机效应实现的预测采用联合最大化扩展似然方法,实际上扩展似然即为等级似然,但是等级似然要求特定的随机效应尺度,见Lee和Nelder等;而随机效应分布参数则采用调整的轮廓等级似然进行估计。本文推导了模型的等级似然函数和估计过程,并将不同分布的脆弱性模型做对比研究。
1 随机效应是威布尔分布的半参数比例危险模型的估计
威布尔分布广泛应用于生存时间以及可靠性试验的统计分析中,Peto和Lee认为在一定条件下失效时间应该是威布尔分布。威布尔分布的危险率函数是h(t)=γtγ-1(尺度参数设为1),当形状参数γ大于1时,危险率随时间而增加;当γ等于1时,危险率函数是常数;当γ小于1时,危险率是减函数。威布尔分布灵活的危险率形式使得它非常适合作为生存时间的模型,在生命科学领域,已经有许多的统计学家采用威布尔分布来分析数据。由于威布尔分布的危险率函数的简单性和灵活性,威布尔分布在多元生存分析中也非常有用。Kimber和Crowder在对异质性建模时使用威布尔分布作为生存分布,Lancaster在考虑异质性的持续数据的比例危险模型中采用威布尔分布。
令Tij(i=1,2,…,q,j=1,2,…,ni)是第i个个体(组)的第j次重复观测,假定给定Ui=ui的的条件下,数据对(Tij,Cij)是条件独立的,而且Tij与Cij条件独立;并且给定Ui=ui,{Cij,j=1,2,…,ni}不含有ui的信息。Cij为删失时间,设Tij的条件危险率为比例危险形式,Ui之间独立同分布,设其服从威布尔分布,考虑危险率函数
hi(t|ui)=h0(t)exp{xiβ}uiexp(-E(logui))
(1)
ui服从威布尔分布,其密度函数为
f(ui)=λρ(λui)ρ-1exp{-(λui)ρ}
(2)
对脆弱性因子ui进行变换,使ui的对数为零均值,令ui=ewi,那么wi=log(ui)具有极值分布
(3)
此时,
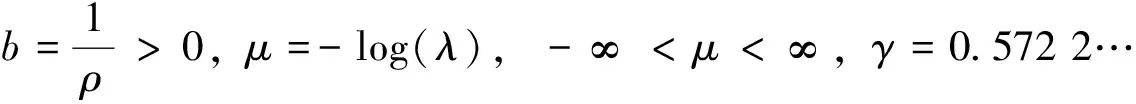
(4)
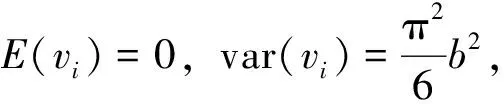
hi(t|ui)=h0(t)exp{xiβ+vi}
(5)
于是,等级似然函数可以写成
(6)
其中
l1ij=δij{logλ0(yij)+ηij}-{Λ0(yij)exp(ηij)}
(7)
(8)


(9)
对h*关于β,v一起最大化,可以得到β和v的估计,估计过程采用Newton-Raphson迭代。
对随机效应分布参数b的估计,Lee和Nelder建议使用最大化调整的轮廓似然估计,调整的轮廓似然为
(10)
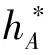
2 各种随机效应模型的比较和模拟研究
为了进一步研究不同的脆弱性模型,下面对随机效应的不同分布生成模拟数据,采用不同的脆弱性模型进行估计。为了进行比较,也把带有随机效应生成的生存数据用一般的Cox 比例危险模型进行估计并和随机效应模型估计结果进行比较,用以检查忽略随机效应对模型估计的影响,模型设为
(11)
其中,i=1,2,…,q,j=1,2,…,ni,也就是说假定q个病人,每个病人有ni个重复观察;或者观察数据按照其自然状态有q个组,每个组内有ni个个体。


表1 正态随机效应生成的生存数据的估计结果1)
1)Cox是指Cox比例危险模型,LNM指对数正态脆弱性模型,GAM指伽马脆弱性模型,WEL指威布尔脆弱性模型;MEAN指200次模拟估计的平均值,SD是200次模拟估计的标准离差,SE是指平均的标准差,95%CP为95%的置信区间包含参数真值的比例。下面表2、表3相同
由表1可以发现,删失率为0.1时,三种随机效应模型的估计结果差别不大,尤其是伽马脆弱性模型的估计最为精确,绝对误差为0.001 4,似乎最为合适的脆弱性模型应该是伽马脆弱性模型。删失率的增加到0.3时,不再是伽马脆弱性模型估计最精确,而是威布尔脆弱性模型估计最精确,绝对误差为0.012 4,而此时伽马脆弱性模型最差。删失率增加到0.5时,这种变化趋势已经很明显了,此时威布尔脆弱性估计最精确,绝对误差仅为0.011 6,而且和相对低的删失率情况下估计结果差别很小,而其它两种脆弱性模型误差都比较大,尤其伽马脆弱性精确度很差。从这三种脆弱性模型的估计结果来看,假如真实的随机效应是对数正态的,估计时分布的误设带来的误差不是很明显,然而,当删失率提高时,威布尔脆弱性模型却能大大改善回归系数的估计。进一步地,我们发现,模拟估计的标准差和平均的SE基本一致,说明用等级似然函数关于参数的二阶导数矩阵地相反数地逆作为估计的方差也很精确。

表2 伽马随机效应生成的生存数据的估计结果
由表2的结果可以看出,删失率为0.1时,三种随机效应模型估计结果差不多,绝对误差都比较小,伽马模型估计的最精确,但是删失率增加到0.3,再增加到0.5的时候,伽马脆弱性模型估计结果不如另外两种模型精确,这种变化趋势很明显,尤其删失率比较高时,比如说0.5时,威布尔脆弱性模型估计最为精确,对数正态模型次之。


表3 威布尔随机效应生成的生存数据的估计结果
上述三种分布的随机效应生存数据的模拟估计还显示:如果不采用随机效应模型,协变量系数的估计将会严重偏离,整体上均呈现高估的趋势,绝对值上是低估,这说明,如果模型中忽略异质性(Frailty)的影响,会使得估计结果存在很大谬误。模拟还发现,即使采用了错误的脆弱性模型,也比不用脆弱性模型估计结果好得多,这说明,实际中,对纵列生存数据建模和估计,要非常小心数据是否存在个体或者组别的异质性,以及注意模型是否忽略了重要因素而导致估计不准确。在实际中,我们推荐使用威布尔脆弱性模型。
模拟研究还发现,用不正确的脆弱性模型以及随着删失率的增加,估计也呈现高估趋势(协变量参数在绝对之上是低估趋势)。究其原因,我们认为是由于随机效应的存在,一方面增加了参数估计的不确定性,另一方面,由于随机效应问题,使得生存数据的波动存在于两个方面,一是协变量的影响,二是随机效应的影响,如果随机效应高估,那么协变量参数会呈现低估现象。观察表1到表3的模拟结果,我们发现,当随机效应方差低估时,协变量系数会高估;当随机效应方差高估时,协变量系数则低估。
威布尔随机效应生成的生存数据,用威布尔脆弱性模型估计的随机效应分布参数也相当精确,δ的真实值为1,删失率为0.1、0.3、0.5时估计的参数分别为0.978 69(0.184 45)、0.962 53(0.170 6)、0.915 83(0.154 32),括号内为模拟估计的标准差,可以看出,他们也是显著的,而且,对威布尔随机效应模拟的数据,用调整的轮廓等级似然函数的二阶导数估计方差,也是比较精确的,因为估计的标准差和用二阶导数计算的平均的SE差别不大,仅有一点高估。其它两种脆弱性模型的随机效应分布参数的估计也很精确,但是估计量的方差用调整的轮廓似然的二阶导数计算则偏误较大。由于不同随机效应分布的参数涵义不一致,不同脆弱性模型随机效应参数的直接比较没有意义,但是按照和数据生成过程一致的脆弱性模型估计的随机效应分布参数与真值非常接近。
模拟还显示,对带有随机效应的生存数据,不能忽略随机效应的存在,否则,Cox模型会有很大偏误。对不同随机效应的生存数据,当然理论上是能够使用真实分布的脆弱性模型估计会很好,但是模拟研究发现,对正态分布、伽马分布、威布尔分
布这三种随机效应的生存数据来说,威布尔脆弱性模型估计结果显示出很大的优势,尤其当删失率提高时,这种优势最为明显。那么,我们可以得出这样的结论,当数据存在较大比例的删失时,不妨采用威布尔脆弱性模型。至于为何威布尔脆弱性模型显示出这么明显的优势,还有待于进一步研究。本文本文模拟采用的样本容量为200,而实际上样本容量为50的情况下,本文的模型也给出了非常类似的结果,这表明等级似然估计方法应用于脆弱性模型估计的时候对于小样本情形有很好的近似。
3 应用实例
下面对文献上常见的两个纵列生存数据的例子用前面讨论的各种脆弱性模型进行估计,一个是肾病感染数据,另一个是烧伤病人皮肤移植数据。
肾病感染数据来自于McGilchrist和Aisbett,总共有38个肾病患者做便携式肾透析,记录下在导管插入处发生感染的时间,从导管插入开始时记录时间,每个患者均被记录了两次发生感染的时间,如果某次感染发生时,导管已经由于感染或其它原因被移除,则这次感染时间被记录为删失。研究中主要考虑五个协变量的影响:年龄,用x1表示;性别,用x2表示,x2=1为女性,x2=0为男性;是否为血球性肾炎用x3表示,x3=1表示是血球性肾炎,否则x3=0;是否为急性肾炎,用x4表示,x4=1表示是急性肾炎,否则x4=0;是否为多囊肾病,用x5表示,x5=1表示是多囊肾病,否则x5=0否则。考虑每个病人的异质性,建立脆弱性模型为
H(tij|x1,x2,x3,x4,x5;ui)=h0(tij)·
exp(β1x1ij+β2x2ij+β3x3ij+β4x5ij+β5x5ij+vi),
i=1,2,…,38,j=1,2
每个病人有一个异质性因子vi,以此来体现每个病人两次感染之间的联系。对肾感染数据,采用一般Cox比例危险模型、对数正态脆弱性模型、伽马脆弱性模型、以及威布尔脆弱性模型进行估计,结果列在表4中,可以看出,性别比较显著,是个危险因素,这说明男性比女性更容易发生感染,这个结果与McGilchrist和Aisbett使用的边际似然估计的结果一致。不同脆弱性模型估计结果有一定的差别,而且都显示存在显著的随机效应,也就是说不同病人除了性别以及疾病类型之外,还有明显的个体差异。

表4 肾感染数据的各种模型估计结果
但是Klein的伽马边际似然方法给出的结果和一般Cox模型结果类似,而且利用Klein的检验说明该例不存在个体异质性。通过上一章的模拟研究,我们发现用调整的等级轮廓似然的二阶导数估计随机效应分布参数估计值的方差会偏低,但偏低并不是很严重,本例的估计结果显示存在个体异质性。Klein的异质性检验方法是个很一般的检验,功效往往很弱,经常检验不出异质性。Yus T.BOENG在他的博士论文研究中对参数基本危险率的威布尔脆弱性模型估计结果也证实存在个体异质性,而且提出了针对威布尔分布的基本危险率的得分检验证实存在异质性。根据上一节的模拟研究结论,当数据存在适量删失时,建议采用威布尔Frailty模型。
皮肤移植数据来自Batchelor 和hackett,研究了16个严重烧伤的病人,由于每一个病人多块皮肤需要移植,研究每块皮肤的治疗效果,有的病人只有一块皮肤移植,而有的病人有多块,这是一个非平衡的观测数据,不同病人做皮肤移植的块数不同,最多的有四块,因此同一个体可以有多个生存时间,适合建立脆弱性模型研究。这个数据只考虑了一个协变量因素,就是人白细胞抗原(human leukocyte antigen,HLA)的匹配好坏,模型设为:H(tij|x;ui)=h0(tij)exp(β×HLAij+vi),HLA为1表示匹配的好,0表示匹配的不好,i=1,2,…,16,j=1,…,ni。采用一般Cox比例危险模型和三种脆弱性模型进行估计,结果列在表5中。

表5 皮肤移植数据的各种模型估计结果
我们发现,HLA的影响是显著的,是影响皮肤移植生存的重要因素,不同脆弱性模型估计结果差别很小,对数正态脆弱性模型和威布尔脆弱性模型估计结果比较接近,伽马脆弱性模型和Cox模型估计结果比较接近,而且都显示了存在显著的随机效应,尤其是威布尔模型,显示个体存在明显的异质性。
4 结 论
本文主要考察了并非指数族分布的威布尔脆弱性模型的建模,使用等级似然方法对其进行估计。结果显示,等级似然方法可以很好给出威布尔脆弱性模型的估计结果,调整的轮廓等级似然可以用来估计得到精确的随机效应的参数。模拟结果显示在纵列持续数据分析和应用中,对带有随机效应的生存数据,不能忽略随机效应的存在,否则,Cox模型会有很大偏误。对不同随机效应的生存数据,当然理论上是能够使用真实分布的脆弱性模型估计会很好,但是模拟研究发现,对正态分布、伽马分布、威布尔分布这三种随机效应的生存数据来说,威布尔脆弱性模型估计结果显示出很大的优势,尤其当删失率提高时,这种优势最为明显。本文模拟和应用研究均表明,等级似然估计在实际应用中对于中等以下规模(样本容量50以下)的样本数据具有很好的稳健性。因此,除了伽玛脆弱性模型和对数正态脆弱性模型之外,威布尔脆弱性模型是也是一个非常值得应用的模型。
参考文献:
[1]COX D R.Regression models in life tables (with discussion) [J].J Roy Statist Soc:Ser B,1972,34:187-220.
[2]PICKLES R,CROUCHLEY.A comparison of frailty models for multivariate survival data [J].Statistics in Medicine,1995,14(13):1447-1461.
[3]HOUGAARD P.Frailty models for survival data [J].Lifetime data analysis,1995,1(3):255-273.
[4]MCLACHLAN G,PEEL D.Mixtures of factor analyzers [J].Finite Mixture Models,2000:238-256.
[5]JAMSHIDIAN M,JENNRICH R I.Acceleration of the EM algorithm by using quasi-Newton methods [J].Journal of the Royal Statistical Society:Series B (Statistical Methodology),1997,59(3):569-587.
[6]LEE Y,NELDER J A.Hierarchical generalized linear models [J].Journal of the Royal Statistical Society:Series B (Methodological),1996:619-678.
[7]HA IL DO,LEE Y,SONG J K.Hierarchical likelihood approach for frailty models [J].Biometrika,2001,88(1):233-233.
[8]HA IL DO,LEE Y,SONG J K.Hierarchical-likelihood approach for mixed linear models with censored data [J].Lifetime data analysis,2002,8(2):163-176.
[9]HA IL DO,LEE Y.Multilevel mixed linear models for survival data [J].Lifetime Data Analysis,2005,11(1):131-142.
[10]徐淑一,王宁宁.竞争风险下纵列数据的随机效应建模和估计[J].中山大学学报:自然科学版,2007,46(1):7-10.
[11]LEE Y,JANG M,LEE W.Prediction interval for disease mapping using hierarchical likelihood [J].Computational Statistics,2011,26(1):159-179.
[12]NOH M,LEE Y,KENWARD M G.Robust estimation of dropout models using hierarchical likelihood [J].Journal of Statistical Computation and Simulation,2011,81(6); 693-706.
[13]NOH M,WU L,LEE Y.Hierarchical likelihood methods for nonlinear and generalized linear mixed models with missing data and measurement errors in covariates [J].Journal of Multivariate Analysis,2012,109:42-51.
[14]LEE D,LEE Y,PAIK M C,et al.Robust inference using hierarchical likelihood approach for heavy-tailed longitudinal outcomes with missing data:An alternative to inverse probability weighted generalized estimating equations [J].Computational Statistics & Data Analysis,2013,59:171-179.
[15]WU J,BENTLER P M.Application of H-likelihood to factor analysis models with binary response data [J].Journal of Multivariate Analysis,2012,106:72-79.
