缺失森林算法在缺失值填补中的应用
2014-03-10中南大学公共卫生学院流行病与卫生统计学系410078胡国清陈立章谭红专
中南大学公共卫生学院流行病与卫生统计学系(410078) 沈 琳 胡国清 陈立章 谭红专
缺失森林算法在缺失值填补中的应用
中南大学公共卫生学院流行病与卫生统计学系(410078) 沈 琳 胡国清 陈立章 谭红专△
目的介绍R环境下缺失森林算法在缺失值填补中的应用并评价其填补效果。方法通过实际数据阐述填补估算流程,比较缺失森林算法与直接删除法处理缺失数据的效果。结果当数据缺失率为10%时,缺失森林算法填补的效果明显优于删除法;当数据缺失率在20%时,两种方法处理缺失值的效果都不太理想,效果相近。当缺失率达50%时,3种类型的变量估算的误差已经较大,两种方法的估算效果均欠佳。结论缺失森林算法在软件操作上简便,并且对数据结构和分布的要求宽松,可充分利用现有记录的信息,能较为准确地反应调查的真实情况,在实际工作中具有较好的应用价值。
缺失森林 随机森林 决策树 缺失值
缺失森林是国外学者近些年提出的一种新的非参数填补方法。这种算法基于随机森林,随机森林是一种自然的非线性建模工具,它可以处理混合类型的数据[1]。作为一种非参数方法,它允许数据中存在交互作用和非线性效应,同时对于数据的结构形式要求极少。它通过在第一步中用已观测值训练出一个随机森林,然后再预测缺失值,最后进行重复迭代来处理缺失值问题。其突出特点是能处理混合类型的数据,即使在高维数据、交互作用和非线性数据结构的复杂情况下也不受限制。由于其准确性和稳健性,随机森林已在一些复杂研究中得到了充分的应用[2-3]。随机森林算法要求应变量是完整的,才能训练出森林。故Stekhoven(2012年)在此基础上做出了改进,提出了缺失森林算法,它可以直接用已观测到的完整部分数据集训练出的随机森林来预测缺失值,而不依赖于因变量的完整性[4]。本文利用湖南省洞庭湖洪灾区7~15岁儿童的创伤性应激障碍(posttraumatic stress disorder,PTSD)发生情况及其影响因素的流行病学调查资料,比较了缺失森林算法和直接删除法处理缺失数据的效果,显示数据缺失在不同比例情况下该法的应用效果,以反映其实际应用价值。
缺失森林填补步骤
假定数据是一个n×p维的矩阵(n例观察对象,p个变量),即X=(X1,X2,…,Xp),将其中任意一个可能含缺失值的变量记为Xs,在该变量上含有缺失值的观察对象记为可将数据集分为以下四个部分:
(1)变量Xs的已观测值,记为
(2)变量Xs的缺失值,记为
(3)在变量Xs上有观察值的观察对象的其他变量(除了变量Xs以外的),记为
(4)在变量Xs上为缺失值的观察对象的其他变量(除了变量Xs以外的),记为
简单来说,就是将在变量Xs上没有缺失的所有个体当做训练样本,而在变量Xs上缺失的个体作为测试样本。这里需要注意的一点是并一定是完全观察到的变量,因为只是表示该观察对象是在变量Xs上都是有观测值的,同样的也不一定是完全缺失的变量。
具体的填补步骤如下:首先,用均数填补或其他填补方法对X的所有缺失值作初步的猜测,并将变量Xs(s可能是p个变量中的任意一个,故s=1,…,p)按照缺失值的数量升序排列(从缺失量最少的变量开始),令将这个初步填补后的矩阵为对于每一个变量Xs,缺失森林算法填补的主要过程是:
(3)重复此填补过程,直到符合停止标准γ,即新填补的数据矩阵和前一个数据矩阵的差值首次开始增加时(若含有两种数据类型,则为两种类型数据的矩阵差都增加时)。

应用举例
1.实例资料
本研究资料节选自1999年11月至2000年5月对湖南省洞庭湖洪灾区7~15岁儿童的创伤性应激障碍(PTSD)发生情况及其影响因素的流行病学调查,共计1892例资料完整的研究对象,模拟出含各种缺失比例(10%,20%,50%)的随机缺失数据。本文中选取4个对儿童发生PTSD有关的变量作为自变量,以PTSD(二分类变量)为因变量,进行Logistic回归分析,这些变量包括年龄(定量变量)、性别(二分类变量)、受灾程度(等级变量)、受灾经历(即曾被水围困等待救援与否,二分类变量)。统计分析过程在R软件(2.15.2)中实现。
2.缺失森林基本程序语句
(1)缺失数据集的输入及变量类型指定
d=read.csv(“填补文件名.csv”,colClasses=c(′factor′,′factor′,′numeric′,′factor′,′factor′))
#指定文件路径输入填补数据集(csv格式),指定填补变量的类型。
library(m issforest)#运行程序包
(2)用缺失森林算法进行填补
d.mis<-prodNA(d,noNA=0.1) #模拟10%的随机缺失
d.imp<-missForest(d,variablew ise=TRUE,ntree=600,m try=3)
#用缺失森林算法逐个变量进行填补,设置相应的森林参数
(3)对填补后的数据集进行分析
fit<-w ith(d.impS|ximp,glm(ptsd~ax7+age+degree+cx26,fam ily=binom ial))
summary(fit) #用logistic回归得到参数估计值
3.分析结果
(1)评价等级
令用不同缺失值处理方法计算出的回归系数为b1,用完整数据集计算出的回归系数为b2,则相对误差为(b1-b2)/b2×100%。优:填补后各回归系数的相对误差的绝对值≤10%;良:填补后各回归系数相对误差的绝对值≤20%;中:填补后各回归系数的绝对值≤50%;差:填补后各回归系数相对误差的绝对值>50%。
(2)评价标准
计算等级顺位累加构成比(优+良),如果累加优良率相同,可以参考相对误差的大小;如果填补后有回归系数相对误差>50%,则填补估算失效。
(3)填补结果
当缺失率为10%时,在6个变量中,缺失森林法填补后回归系数符合优和良的标准的分别为3和2,而删除法则分别为1和3;而且缺失森林法填补后的绝大部分回归系数的相对误差均小于删除法的结果。详见表1。

表1 10%缺失数据下不同处理方法的回归系数及其相对误差
当缺失率为20%时,缺失森林法填补后回归系数符合优的标准为1个变量,而删除法填补后回归系数符合良的标准的变量数为1,填补效果相近,都不太理想。详见表2。
当缺失率为50%时,缺失森林法填补后回归系数符合优的标准为1个变量,而删除法填补后回归系数符合优的标准的变量数为0。综合来讲,虽然两者处理效果都较差,但缺失森林法填补效果比删除法稍好,删除法对所有变量参数估算的误差都已经远远大于50%,处理失败。详见表3。
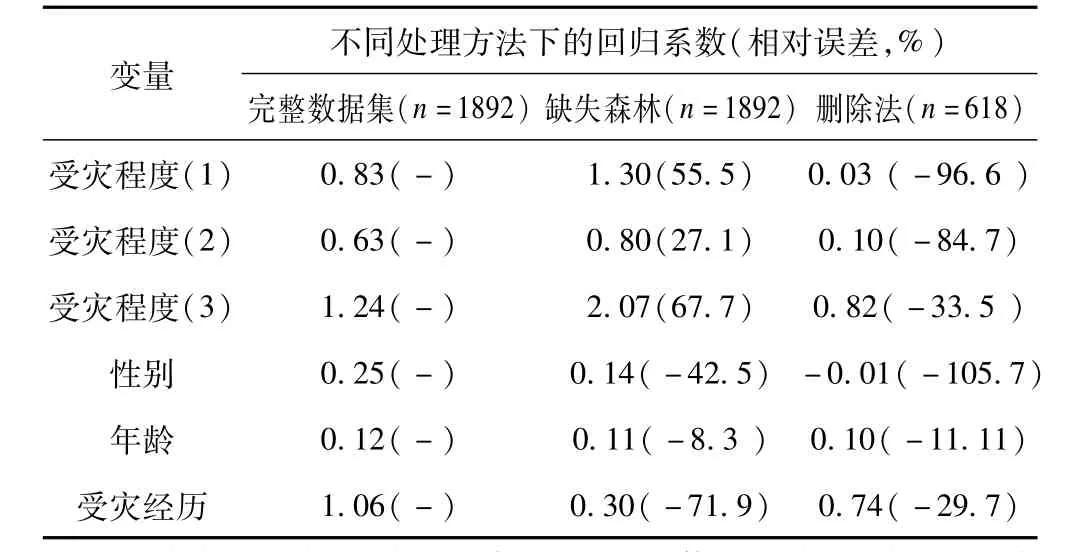
表2 20%缺失数据下不同处理方法的回归系数及其相对误差

表3 50%缺失数据下不同处理方法的回归系数以及相对误差
讨 论
要减少调查中的缺失数据,主要应从事前预防和事后补救两方面入手。事前预防是处理缺失数据最简便且最有效的方法,但现实中由于条件限制,往往不能完全解决问题。一般而言,在事后补救上则需要对缺失数据进行处理。在以往的流行病学调查研究中,国内研究中对于处理缺失数据的重视程度不够或存在方法误用的情况,往往只是简单地将有缺失值的对象剔除,仅对完全记录对象进行分析[6]。在统计方法与计算机技术日新月异的今天,我们应该借助一些有效的新方法来合理地处理缺失数据。
通过本研究的模拟填补试验发现,当数据缺失率为10%时,缺失森林算法填补的效果比用删除法处理的效果要好得多;当数据缺失率在20%时,两种方法参数估计的相对误差都增加,两种方法处理缺失值的效果相差不大,都不太理想;当缺失率达50%时,缺失森林的填补估算效果尚可,仍有1个变量的回归系数估计达到优的标准,而此时删除法对所有变量参数估算的误差都已经远远大于50%,处理失败。这说明缺失森林算法的填补效果在多数情况下都优于删除法;但当缺失比例过大时,再好的处理方法也无济于事。这与其他相关文献得出的结论一致[7]。
缺失森林这种新的非参数算法具有良好的应用前景,它不仅能同时处理不同类型的变量组成的多变量混合数据,同时对数据分布的假定前提条件很少。缺失森林算法的计算效率较其他填补方法高,且不需要对数据进行标准化、哑变量分类编号等预处理,操作简便易行[8-9]。Stekhoven等人的研究表明,缺失森林的填补效果优于已有的填补方法,如k最近距离填补或链式方程的多变量填补(multivariate imputation by chained equations,M ICE)。另外,缺失森林还可以通过袋外数据(OOB)填补误差估计值,而不需设定检验数据或进行繁琐的交叉验证。即使当数据集为高维数据(即当变量数量可能大大超过观察单位数)、变量间存在复杂的交互作用或非线性关系的情况下,缺失森林算法也能提供良好的填补结果[4]。因此,在处理大型复杂数据集的缺失值上,缺失森林将有明显的优势,尤其是在药物流行病学以及分子流行病学领域有巨大的应用潜力。
本研究的数据仅仅来源于一项基于洪灾的流行病学调查的模拟研究,因为是非平衡的观察性数据,多变量的回归系数彼此间有影响,故填补效果还有待进一步的研究深入探讨,得到的结论可能存在一定的局限性。今后,可以利用更多复杂的生物学或医学数据来验证并使用该方法,也可将这种新方法与更多其他的缺失值处理方法进行比较研究。
总之,缺失森林算法为处理缺失数据提供了新的选择,有关missForest程序包的更多扩展功能参见Stekhoven教授编写的程序包说明。
1.方匡南,吴见彬,朱建平等.随机森林方法研究综述.统计与信息论坛,2011,26(3):32-38.
2.武晓岩,李康.随机森林方法在基因表达数据分析中的应用及研究进展.中国卫生统计,2009,26(4):437-440.
3.李贞子,张涛,武晓岩.随机森林回归分析及在代谢调控关系研究中的应用.中国卫生统计,2012,29(2):158-163.
4.Stekhoven DJ,Buhlmann P.M issForest—non-parametric m issing value imputation form ixed-type data.Bioinformatics,2012,28(1):112-118.
5.Oba S,Sato M,Takemasa I,et al.A Bayesian m issing value estimation method for gene expression profile data.Bioinformatics,2003(19):2088-2096.
6.Karahalios A,Baglietto L,Carlin,et al.A review of the reporting and handling ofm issing data in cohort studies w ith repeated assessment of exposuremeasures.BMC Medical Research Methodology,2012,12:96.
7.Enders CK.Applied M issing Data Analysis.New York:The Guilford Press,2010:37-54.
8.Little RJ,Rubin DB.Statistical Analysis w ith M issing Data.2nd ed. New York:W iley,2002:59-74.
9.Buuren SV,Oudshoom K.M ICE:Multivariate Imputation by Chained Equations in R.Journal of Statistical Software,2010,7(16):1-68.
(责任编辑:郭海强)
Application of M issForest Algorithm for Im puting M issing Data
Shen Lin,Hu Guoqing,Chen Lizhang,et al(DepartmentofEpidemiologyandStatistics,SchoolofPublicHealth,CentralSouth University(410078),Changsha)
ObjectiveTo introduce the principle ofm issForest algorithm and its basic R procedure in imputingmissing data,and to assess the imputation effects ofm issForest.MethodsBased on real data sets w ith m issing variables and different missing rate,we introduce R procedure ofm issForest and compare the imputation results betweenm issForest and deletionmethod.ResultsM issForest outperforms deletionmethod asm issing rate is10%.As them issing rate is increasing by 20%,there are no obvious differences for thesemethods and the imputation effects of thesemethods dealing w ithm issing data are unsatisfactory.Whereasmissing rate ismore than 50%,the relative error of three kinds of variables for thesemethods is increasing dramatically,neithermethod is appropriate.ConclusionM issForest ismore attractive than othermultiple imputationmethods for its easy and simple usage in software,moreover it does not require assumptions about the distribution and structure of the data.W ith this new method,we canmake themostuse of the data in hand and havemore reliable results,so it isworth using w idely in practice.
M iss Forest;Random forest;Decision tree;M issing data
△通信作者:谭红专,E-mail:tanhz99@qq.com
