新的时间序列相似性度量方法
2014-02-09张海涛李志华张华伟
张海涛,李志华,孙 雅,张华伟
(1.江南大学物联网工程学院轻工过程先进控制教育部重点实验室,江苏无锡214122;2.江南大学物联网应用技术教育部工程研究中心,江苏无锡214122)
0 引 言
时间序列是以时间为坐标轴的一串观测数据的有序集合,具有明显的变化趋势特征,如持续上升、波峰、波谷等。相似性度量是数据挖掘的基础,针对时间序列数据的相似性度量已经成为时间序列数据挖掘的研究热点之一[1,2]。欧氏距离(euclidean distance,ED)[3]和动态时间弯曲距离(dynamic time warping,DTW)[4]是用于时间序列相似性度量的两种经典方法。欧式距离以计算简单、通用性好著称,但只能处理等长度的时间序列,并且无法识别时间序列的变化趋势;动态时间弯曲距离较好地克服了欧式距离的不足,支持时间序列的动态弯曲,但该方法计算复杂、时间复杂度高,限制了其应用范围。文献[5]提出了符号聚合近似(symbolic aggregate appro Ximation,SAX)方法,首先对时间序列进行符号化,然后对符号化后的数据进行相似性度量,具有简单易用、不依赖于具体实验数据等特点。
本文通过研究时间序列数据的变化趋势特征,概括出时间序列可能的变化趋势集合,并对其进行符号编码,在此基础上通过研究时间序列变化趋势的度量问题,提出了时间序列变化趋势的相似性度量(similarity measure of variation-trends,SMVT)方法。方法具有趋势特征描述客观、可快速有效地对时间序列数据进行压缩、能从变化趋势的角度对时间序列数据进行有效性度量等优点,并且SMVT满足距离的3种属性,丰富了时间序列数据度量方法的家族成员。通过借助模式识别领域的层次聚类方法对SMVT度量方法进行验证,实验结果表明该方法具有有效性、高效性和实用性特点。
1 分段聚合近似方法简介
给定时间序列S={s1,s2,…sn}其中n是其长度。将它转变成长度为w的时间序列S’={s’1,s’2,…s’w},其中w<n,并且s’j(j=1,2…w)满足

上述过程称为分段聚合近似(piecewise aggregate approximation,PAA)[6],分段聚合近似是时间序列相似性度量中应用比较广泛的数据降维方法[7,8],该方法在时间序列的处理上有着非常多的有点,如具有较高的压缩率,可快速有效地实现数据降维,解决时间序列数据量庞大的问题;对噪声数据有较好的去噪能力,分段过程在消除噪声的同时对时间序列起到数据平滑处理的作用。
2 时间序列变化趋势的相似性度量
SMVT方法的总体思想是:以分段聚合近似为变换函数对时间序列进行数据降维,然后根据时间序列的变化趋势对序列数据进行符号化,并在此基础上,通过定义趋势距离来度量时间序列之变化趋势的相似性。
2.1 时间序列变化趋势的符号化
对于时间序列来说,工程应用中更多地关注它的变化趋势,如持续上升、持续下降、波峰等。本文从时间序列的实际变化出发,经过统计分析,得出详细的时间序列变化趋势有9种:TF={持续下降,下降后平稳,波谷,平稳后下降,持续平稳,平稳后上升,波峰,上升后平稳,持续上升},并把TF符号化成{A,B,C,D,E,F,G,H,I}这样的字符集合,其中符号与TF中的变化趋势一一对映,即TF={A,B,C,D,E,F,G,H,I}。
假设有时间序列S={s1,s2,…si,…sn}其中n是其长度,则si(i=2,3…n-1)取实际采样值,并且对应的可能变化趋势vk∈TF(k=i-1)可以通过时间序列的趋势-符号编码字典(见表1)来符号化。其中,Xmax为时间序列S中任意两个下标相邻的数据sj,sj+1(j=1,2…n-1)之间差值的最大值,abs为取绝对值,ε(0<ε<1)是趋势区分阈值,在实验中根据经验来设定
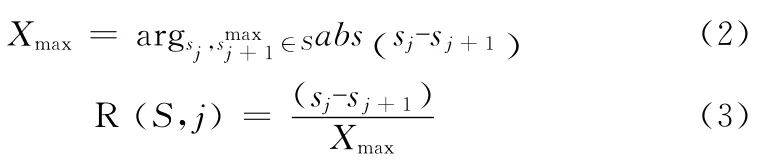
在趋势-符号编码词典中,对于任意两个趋势符号vx和vy(vx,vy∈TF)的比较,通过式(4)来实现

其中,asc(vx)和asc(vy)分别计算趋势符号vx和vy所对应字母的ASCII值。

表1 趋势-符号编码词典
时间序列的重新描述是时间序列相似性度量的前提。以趋势-符号编码词典为基础,首先提出时间序列的趋势符号化方法(trend symbolization method,TSM),该方法依据时间序列的变化趋势特征对时间序列进行符号化,将时间序列转换为趋势序列。对于时间序列S,其TSM符号化方法的步骤概括如下:
步骤1 根据式(1)对时间序列S进行数据降维处理,得到长度为w的时间序列S’={s’1,s’2,…s’w};
步骤2 根据趋势-符号编码词典(见表1),对时间序列S’进行趋势符号化,得到长度为w-2的趋势序列V={v1,v2,…vw-2}。
为更好地说明TSM方法,取长度为128的时间序列如图1中S1所示,对其进行符号化。首先,使用式(1)对时间序列S1进行数据降维处理,在此取w为16,则可以得到长度16的时间序列,如图1中的S2所示;然后,根据表1的编码词典进行符号化,取ε的值为0.05,最后得到长度为14的趋势序列{G,A,A,B,F,I,I,I,I,H,E,D,A,A},如图1中的S3所示。

图1 时间序列的趋势符号化方法过程
2.2 趋势距离
受文献[9]的启发,本文给出趋势距离(trend-distance,TD)的定义,从变化趋势的角度对时间序列进行相似性度量。
假定两个趋势序列,V1={v11,v12,…,v1i…,v1M}(i=1,2…M)和V2={v11,v22,…,v2j…,v2N}(j=1,2…N),它们之间的趋势距离TD(V1,V2)定义如下。
定义:Dist(0,0)=0

其中,μd,μi和μr(i,j)分别为插入、删除和替换3种操作的代价,文中μd和μi的值均为1,由式(6)、(7)可知0<μr(i,j)≤1;max(V1)和min(V1)分别为趋势序列V1中所有数据的最大值和最小值,max(V2)和min(V2)分别为趋势序列V2中所有数据的最大值和最小值;abs(max(V1)-min(V2))是max(V1)-min(V2)的绝对值,abs(min(V1)-max(V2))是min(V1)-max(V2)的绝对值,σmax为这两个绝对值中的最大值。
显然,不难看出,趋势距离计算的是从趋势序列V1转换到趋势序列V2的最小编辑操作代价,适用于长度不等的趋势序列之间的相似性度量。
以下我们来讨论趋势距离的非负性、对称性和三角不等式特性。
若增加一个趋势序列V3,参考编辑距离的性质[10-12],根据趋势距离的定义可知趋势距离的非负性和对称性显然是成立的,即很容易满足:
非负性:TD(V1,V2)≥0,当且仅当V1=V2时,TD(V1,V2)=0;
对称性:TD(V1,V2)=TD(V2,V1)。
对于趋势距离的三角不等式特性,证明如下:
设TD(V1,V2)=d1,TD(V2,V3)=d2,TD(V1,V3)=d3,则只需证明d2≤d1+d3。
证明:从趋势序列V2转换到趋势序列V3操作如下:先从V2转换到V1,趋势距离为TD(V2,V1),由对称性可知,TD(V2,V1)=TD(V1,V2)=d1;然后从V1转换到V3,趋势距离为TD(V1,V3)=d3;于是趋势序列V2通过d1+d3的编辑操作代价可以转换到V3。又知趋势序列V2和V3的趋势距离是从V2转换到V3的最小编辑操作代价,故有d2≤d1+d3。即满足三角不等式特性。
趋势距离与编辑距离的主要区别在于:编辑距离中,插入、删除及替换3种操作的代价均为1;趋势距离中,插入和删除操作的代价也为1,而对于替换操作,根据式(7)计算其代价。如,有趋势序列V1={A,B,D}、V2={A,B,E}和V3={A,B,F}。根据趋势序列中每个数据的意义,可知从V1转换到V2的操作代价应小于从V1转换到V3的操作代价,对于V1、V2、V3之间的相似性度量,无论使用编辑距离还是趋势距离,从V1转换到V2和从V1转换到V3均只需进行替换操作。在编辑距离中,从V1转换到V2与从V1转换到V3的替换操作代价均为1;而在趋势距离中,从V1转换到V2的替换操作代价为abs(DE)/4=0.25,而从V1转换到V3的替换操作代价为abs(D-F)/5=0.4。可见,趋势距离可以更精确地描述趋势序列间的差异。
2.3 SMVT方法
时间序列变化趋势的相似性度量方法(SMVT)概括如下:
步骤1 通过时间序列的趋势符号化方法(TSM)将时间序列符号化;
步骤2 根据趋势距离的定义,针对符号化的时间序列,度量其相似性。
3 仿真实验及分析
3.1 实验数据简介
为了检验本文提出的时间序列相似性度量方法—SMVT方法的有效性、高效性和实用性,仿真实验使用两组时间序列数据样本,具体见表2。

表2 实验数据简介
实验中对实验数据用式(9)的极差标准化方法进行预处理

其中,min(S)和max(S)分别为时间序列S中所有数据的最小值和最大值,处理后时间序列S中所有数据的变化区间在[0,1]之间。

图2 样本一中类别一的数据

图3 样本一中类别二的数据

图4 样本一中类别三的数据
3.2 实验结果及分析
本文实验软环境为Matlab 2009b,Windows 7旗舰版操作系统;硬环境为3.20GHz CPU、4GB内存的PC机。
为加强趋势距离的可理解性,举如下例子说明,对样本一数据,采用本文提出的方法进行仿真实验,取w=30,ε=0.05,使用TSM方法对图2中的b、c和图4中的g、h所示数据进行符号化,得到相应的趋势序列为:


进一步使用趋势距离计算上述4个趋势序列之间的距离可得:
TD(Vb,Vc)=2.5,TD(Vb,Vg)=7.875,TD(Vb,Vh)=7,TD(Vc,Vg)=7.625,TD(Vc,Vh)=4.75,TD(Vg,Vh)=3.625。由文献[13]的层次聚类方法可见,图2(b)和图2(c)所示的数据为一类,图4(a)和图4(b)所示的数据为一类。
对时间序列数据进行聚类是指通过相似性或相异性度量,将时间序列数据进行归类计算。为了验证本文提出的时间序列相似性度量方法的有效性、高效性和实用性特点,我们设计4种时间序列的相似性度量实验方案(见表3所述)。并对4种方案得到的数据结果采用文献[13]的层次聚类方法进行分析,利用文献[14]的方法计算聚类准确率。用方案一、方案三和方案四的实验结果检验SMVT方法的有效性,用方案一、方案二和方案四的实验结果检验SMVT方法的高效性,用方案一、方案二、方案三和方案四的实验结果检验SMVT方法的实用性。具体聚类结果如图5和图6所示,实验结果见表4和表5。

图5 样本一聚类结果

图6 样本二聚类结果

表3 时间序列的相似性度量实验方案

表4 样本一实验结果分析

表5 样本二实验结果分析
由图5,图6所示的方案一、方案三和方案四的聚类结果可知:相比于欧式距离、动态时间弯曲距离,方案四所述SMVT方法用样可以适用于时间序列的数据挖掘,而且具有较好的聚类结果,这说明本文提出的SMVT方法是有效地。
通过方案一、方案二和方案四的实验结果(见表4和表5)比较可知:相对于方案一和方案二,方案四的聚类效果最优,且聚类时间与方案一和方案二相近,可见方案四中所述SMVT方法在时间序列的聚类实验上表现出一定的高效性。
通过方案一、方案二、方案三和方案四实验结果比较(见表4和表5)不难看出:方案一的聚类速度最快,但聚类准确率最低;方案二相对于方案一来说,聚类准确率有所提升,但聚类时间也相应增加;方案三在4种方案中,聚类准确率最高,但聚类时间远高于其它3个方案;方案四的聚类准确率高于方案一和方案二,略低于方案三,但聚类时间略高于方案一和方案二,远小于方案三。从时间和准确率两个方面综合考虑,方案四在保持较高聚类准确率的同时,也较少地占用了聚类时间。可见,SMVT方法在时间序列聚类实验上综合性能比较好,相对其它的时间序列相似性度量方法具有较强的实用性。
4 结束语
时间序列的相似性度量是时间序列挖掘的关键环节。本文提出的SMVT方法,依据变化趋势对时间序列进行符号化,将时间序列转变为相应的趋势序列,并以此为基础,通过定义趋势距离来度量时间序列间的相似性。实验结果表明,该方法可以很好地从变化趋势的角度对时间序列进行相似性度量,效果明显,具有有效性、高效性和实用性特点,可应用于时间序列的数据挖掘计算。
[1]Lhermitte S,Verbesselt J,Verstraeten W W.A comparison of time series similarity measures for classi fi cation and change detection of ecosystem dynamics[J].Remote Sesing of Environment,2011,115:3129-3152.
[2]Tak-chung Fu.A review on time series data mining[J].Engineering Application of Artificial Intelligence,2012,24(1):164-181.
[3]XIE Fuding,LI Ying,SUN Yan,et al.Improved symbolization time series method[J].Computer Engineering and Design,2012,33(10):3950-3953(in Chinese).[谢福鼎,李迎,孙岩,等.改进的符号化时间序列处理方法[J].计算机工程与设计,2012,33(10):3950-3953.]
[4]Somaya Adwan,Hamzah Arof.On improving dynamic time warping for pattern matching[J].Measurement,2012,45(6):1609-1620.
[5]Antonio Canelas,Rui Neves,Nuno Horta.A SAX-GA approach to evolve investment strategies on financial markets based on pattern discovery techniques[J].Expert Systems with Application,2013,40(5):1579-1590.
[6]Nguyen Quoc Viet Hung,Duong Tuan Anh.An imporvement of PAA for dimensionality reduciton in large time databases[G].LNCS 5351:PRICAI 2008:Trends in Artificial Intelligence.Berlin:Springer Berlin heidelberg,2008:698-707.
[7]LI Guiling,WANG Yuanzhen,YANG Linquan,et al.Research on similarity measure for time series based on SAX[J].Application Research of Computers,2012,29(3):893-896(in Chinese).[李桂玲,王元珍,杨林权,等.基于SAX的时间序列相似性度量方法[J].计算机应用研究,2012,29(3):893-896.]
[8]LI Hailin,GUO Chonghui.Piecewise cloud approximation for time series mining[J].Knowledge-Based Systems,2011,24(5):492-500(in Chinese).[李海林,郭崇慧.基于形态特征的时间序列符号聚合近似方法[J].模式识别与人工智能,2011,24(5):665-672.]
[9]Alexandr Andoni,Robert Krauthgamer.The computational hardness of estimating edit distance[J].Society for Industrail and Application Mathemetics,2010,39(6):2398-2429.
[10]LIU Kun,YANG Jie.Trajectory distance metric based on edit distance[J].Journal of Shanghai Jiaotong University,2009,43(11):1725-1729(in Chinese).[刘坤,杨杰.基于编辑距离的轨迹相似性度量[J].上海交通大学学报,2009,43(11):1725-1729.]
[11]Alexandr Andoni,Robert Krauthgamer.The smoothed complexity of edit distance[J].ACM Transactions on Algorithms,2012,8(4).
[12]DAI Dongbo.Sequence clustering algorithms based on global and local similarity[J].Journal of Software,2010,21(4):702-717(in Chinese).[戴东波.基于整体和局部相似性的序列聚类算法[J].软件学报,2010,21(4):702-717.]
[13]Jiawei Han,Micheline Kamberi.Data mining:Concepts and techniques[M].3rd ed.USA:Morgan Kaufmann,2011:457-469.
[14]LI Zhigang,NIU Qiang.An improved symbolization time series cluster method[J].Microelectronics &Computer,2012,29(11)(in Chinese).[李志刚,牛强.一种改进的符号化时间序列聚类方法[J].微电子学与计算机,2012,29(11).]
