基于决策树与质谱分析数据的癌症判别
2013-11-08杨慧中
严 勇, 王 鑫, 杨慧中
(1.无锡职业技术学院 继续教育学院,江苏 无锡 214121;2.江南大学 物联网工程学院,江苏 无锡 214122)
模式识别(Pattern Recognition)是对感知信号(图像、视频、声音等)进行分析,对其中的物体对象或行为进行判别和解释的过程,是信息科学和人工智能的重要组成部分。模式识别所研究的理论和方法在很多科学和技术领域中得到广泛的认可和重视,近些年越来越多地被应用在生物医学工程领域,如进行医学图像处理、生物电信号分析、细胞的识别以及中医诊断治疗,它已经成为生物医学工程中的重要研究手段。
本文拟用模式识别领域常用的决策树与Ada-Boost技术来处理医学领域常用的质谱分析数据,对癌变细胞和正常细胞进行有效分类,这将对疾病的治疗与预防有着广泛而积极的意义。
1 数据介绍
本文拟分析的数据集来自下面链接的网络资源:http://home.ccr.cancer.gov/ncifdaproteomics/ppatterns.asp。
该数据提供了大量的质谱分析数据,供医疗机构进行癌症诊断的研究。本文拟使用研究的算法对其进行分类研究,即根据特定病人的质谱分析数据,来自动推断该病人是否患有癌症。该数据集共有216个样本。为了合理地设计一个推广性能较好的分类器,也为了准确地评估设计好的分类器,随机选用其中152个作为训练数据集,32个作为训练中使用的验证数据集,32个作为测试数据集。
2 分类树与AdaBoost技术
2.1 决策树与分类树
决策论中,决策树由一个决策图和可能的结果(包括资源成本和风险)组成,用来创建到达目标的规划。决策树是一个利用像树一样的图形或决策模型的决策支持工具,包括随机事件结果,资源代价和实用性。决策树建立并用来辅助决策,是一种特殊的树结构,也是一个算法显示的方法。决策树经常在运筹学中使用,特别是在决策分析时,它帮助确定一个能最可能达到目标的策略。如果在实际中,决策不得不在没有完备知识的情况下被在线采用,一个决策树应该平行概率模型作为最佳的选择模型或在线选择模型算法。决策树的另一个使用是作为计算条件概率的描述性手段。
机器学习中,决策树是一个预测模型[1]。它表示的是一种对象属性与对象值之间的映射关系。决策树中的各个节点代表是所要描述的对象,而每个分叉路径则表示为可能实现的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。决策树学习也是资料探勘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式地对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。另外,随机森林分类器[2]将许多决策树结合起来以提升分类的正确率。
2.2 分类树的提升
随机森林对分类树的集成,是基于袋装(bagging)的机制,而实际使用中还有提升(boosting)的集成机制。
AdaBoost算法是二元分类问题中常用的一种提升方法[3]。它针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器)。理论证明,只要每个弱分类器分类能力比随机猜测要好,当其个数趋向于无穷个数时,强分类器的错误率将趋向于零。AdaBoost算法中不同的训练集是通过调整每个样本对应的权重实现的。最开始的时候,每个样本对应的权重是相同的,在此样本分布下训练出一个基本分类器h1(x)。对于h1(x)错分的样本,则增加其对应样本的权重;而对于正确分类的样本,则降低其权重。这样可以使得错分的样本突出出来,并得到一个新的样本分布。同时,根据错分的情况赋予h1(x)一个权重,表示该基本分类器的重要程度,错分得越少权重越大。在新的样本分布下,再次对基本分类器进行训练,得到基本分类器h2(x)及其权重。依次类推,经过T次这样的循环,就得到了T个基本分类器,以及T个对应的权重。最后把这T个基本分类器按一定权重累加起来,就得到了最终所期望的强分类器。
AdaBoost具有以下优势:快速,易于编程,不需要调整参数,可以组合任何学习算法,不需要关于弱分类器的先验知识等。
3 关键特征排序
特征选择,通过只选择被测特征(预测变量)的一个子集来创建模型,降低了数据的维数。选择准则通常涉及最小化拟合不同子集的模型的一个特定的预测误差的度量。算法搜索一个预测变量的子集,以最优化模型的测量响应,最优化的约束条件为要求的特征、排除的特征、或者子集的大小。为了避免过拟合,对于高维数据,在进行分类之前,首先要进行降维。降维的方法之一就是从特征向量中选择出显著性较高的特征。
质谱分析数据是高维数据。以本文的数据集为例,其维数高达15 000。在进行数值实验之前,根据类可分性准则(这里使用的准则是相对熵,即KL距离),将数据中的关键特征排序,取其中的前10位作为分类预测使用的特征向量。常用的类可分性准则有:t检验准则、KL距离准则、Chernoff界准则。这三者都假定各个类服从正态分布,而ROC准则与Wilcoxon测试准则则属于非参数检验。
4 实验与分析
本文使用KL距离可分性准则,选出15个最显著的特征。在获取显著性较高的特征之后,使用以分类树为弱学习器的AdaBoost算法进行实验。实验所得的置换误差曲线如图1所示。从图中可以看出,随着决策树的个数的增大,模型的置换误差迅速减小。
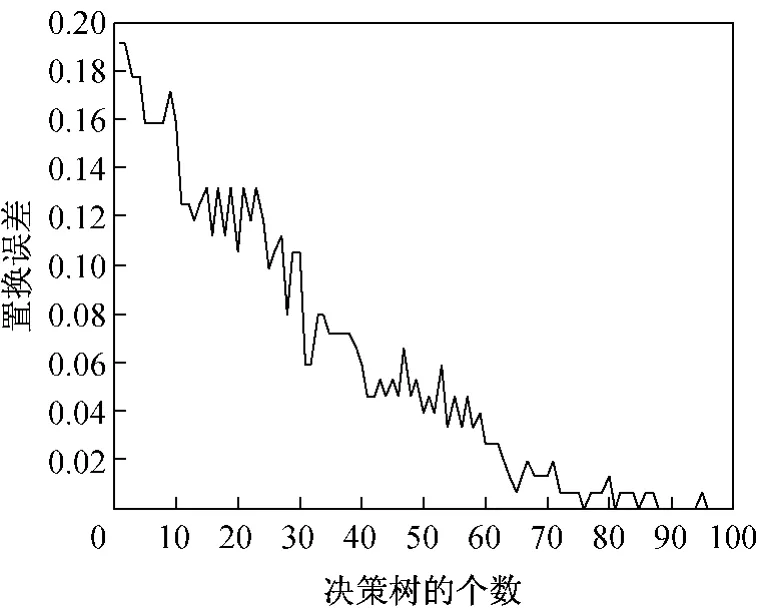
图1 置换误差曲线
Hold误差是对推广误差的更好的一种评估。图2给出了该模型的Hold误差曲线。决策树个数较小的时候,该模型就达到了较低的推广误差。但是,随着决策树个数的增大,推广误差仍呈现出减小的趋势。
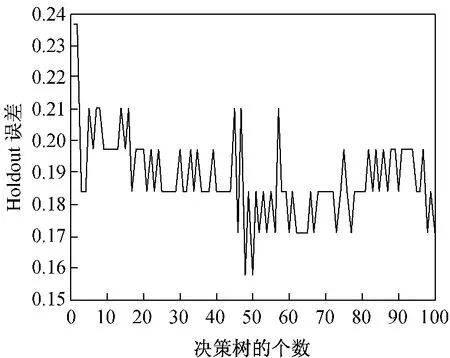
图2 Holdout误差曲线
AdaBoost的优异性能可以从间隔最大化的角度来解释。尽管集成分类器变得越来越大,但是间隔很可能也在增大,所以,最终的分类器实际上接近于一个更简单的分类器,从而降低了测试误差。
相比于经典的支持向量机[4-5],二者相同点是:都通过最大化间隔来工作,都在高维空间中寻找线性阈值函数;不同点是:使用不同的范数来度量间隔,SVM 使用核技巧来处理高维空间,而Ada-Boost使用弱分类器在空间中搜索;SVM最大化最小的间隔,而AdaBoost最大化间隔分布[6]。
5 结论
本文研究了基于决策树的AdaBoost的质谱数据分析。首先,介绍了AdaBoost的一般理论,然后,以分类树为弱学习器,调整集成学习器中的弱分类器的个数,研究了弱分类器个数对分类性能的影响。最后,将AdaBoost与SVM类比,从大间隔学习的观点出发,解释了AdaBoost的优势。
[1]Safavian,S.R.and D.Landgrebe.A survey of decision tree classifier methodology [J].IEEE Transactions on Systems,Man and Cybernetics,1991,21(3):660-674.
[2]Breiman L.Random Forests[J].Machine Learning,2001,45(1):5-32.
[3]Schapire,R.and Y.Freund,et al.Boosting the Margin:A New Explanation for the Effectiveness of Voting Methods[J].The Annals of Statistics,1998,26(5):1651-1686.
[4]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[5]Cortes,C.and V.Vapnik.Support-Vector Networks[J].Machine Learning,1995,20(3):273-297.
[6]Freund,Y.and R.Schapire.A Desicion-Theoretic Generalization of On-Line Learning and an Application to Boosting[J].Lecture Notes in Computer Science,1995,904:23-27.
