商业银行信用风险管理模型探究——基于BP-Adaboost强分类器的分析
2013-09-06程冬民
程冬民,彭 雷
(1.山东财经大学马克思主义学院,山东济南 250014;2.山东临朐中国建设银行,山东临朐 262600)
一 引言
商业银行的信用风险管理一直是人们关注的焦点,在商业银行建立后的几百年里,尽管人们几乎采用了各种方法对信用风险进行判别和控制,但是现有的信用风险评估模型因为自身的局限仍然难以适应非线性风险的复杂性。因此,构建具有较强的逼近非线性函数的信用风险模型具有重要现实意义和应用价值。
1990年Odom&Sharda[1]建立神经网络模型并运用该模型对银行破产进行了考察,开创了神经网络应用于信用风险管理的先河。此后Tam&Kiang[2](1991)使用神经网络信用风险评估模型对企业的财务指标信用评分的研究,以及Altman&Macro[3](1994)对意大利财务危机的预测,Kiviluoto[4](1998)用自组织神经网络和学习向量机(Learning Vector Quantization,LVQ),Salchenberger[5](1992)使用神经网络系统和LR对于信用风险管理进行的比较,都说明了神经网络在处理非线性问题方面的优势。但是他们对于神经网络只是停留在使用的层面上,没有进一步的探寻优化神经网络的方法。
随着神经网络在信用风险管理上的应用,许多学者逐渐认识到神经网络在处理财务数据时存在的问题,因而在数据的处理上或是在方法的优化上做出了很大的努力。Back[6](1996)等建议用遗传算法与神经网络结合起来协同工作,Piramuthu[7](1998)等采用符号特征样本的技术处理输入数据都取得了较为明显的效果。国内学者在引进神经网络以后,也为神经网络模型的优化进行了卓有成效的努力。如许佳娜、西宝[8](2004)采用层次分析法对神经网络模型的改进,以及郭英见、吴冲[9](2009)采用DS证据理论将神经网络和SVM的输出结果进行的融合,都在一定程度上增强了神经网络模型的判别准确率,但他们在神经网络的权值设定上仍然没有找到很好的设定规则。
本文从理论层面阐述了可以应用于商业银行信用风险管理的BP-Adaboost强分类器信用风险管理模型,并以2012年350家上市公司的财务数据为样本基础,考察了该系统应用于商业银行信用风险管理的可行性,并比较了该模型与原有的BP神经网络系统的优劣。最后对该系统在商业银行的应用前景进行了分析评价。
二 BP-Adaboost强分类器模型的构建
在人工神经网络(Artificial Neural Network,ANN)中根据信息流向和网络的拓扑结构,可以将ANN分为前馈网络和反馈网络两大类。反向传播(Back Propagation,BP)网络(如图1)就是一种多层前馈神经网络,采用误差反向传播算法(Error Back-propagation Algorithm,简称BP算法),是目前应用最广泛的一种神经网络。但是根据之前较多学者的研究结果,BP神经网络却难以克服特征记忆无选择性的缺点,导致训练好的分类器系统分类可信度受到影响。而Adaboost算法以多次迭代算作为运算核心思想,可以提取有效分类信息并进行迭代运行,从而可以起到优化BP神经网络的效果。
BP-Adaboost强分类器模型的构建是在基于BP(Back Propagation,BP)神经网络的弱分类器基础之上,通过加入Adaboost算法,构建一种更为高级的分类器系统,从而对神经网络系统特别是BP神经网络系统的分类以及特征记忆能力给予很好的优化。具体来讲,其核心思想即:针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。对于弱分类器中分类误差较大的训练数据组调整并给予更大的权重,然后重新予以训练,直到取得较好的训练效果。每个分类函数都有一个权重,分类越好的函数,对应的权重就越大。经过多次迭代以后,最终的强分类器由各个弱分类器加权得到。BP-Adaboost模型把BP神经网络作为弱分类器,反复训练BP神经网络的预测输出,通过Adaboost算法把得到的多个BP神经网络弱分类器组成一个强分类器。
在模型的初始设计基本完成后,需要将经过筛选和处理的数据输入到模型当中进行模型的训练和记忆,并不断调整原有参数的设置,这样才能够训练出符合分类标准的模型。
三 数据指标的预处理
(一)样本数据的选取
1.样本数据财务指标的选取
在进行模型的初始处理时,需要选取多少样本数据,以及选择样本数据中的哪些指标进行系统训练都会影响系统训练的准确性。样本选取太多,虽然能在一定程度上增强系统的泛化能力,但又会使系统对稀少特征失灵[10]。本文在进行数据选择时,总结了在神经网络信用风险研究领域取得过一定学术成果的专家的研究成果,并以现行商业银行进行信用风险评估的数据指标为基础,共收集了2012年350家上市公司的财务数据,这其涵盖了房地产、医药、机械、化学化工、有色金属行业、煤炭、钢铁等几个较大的板块,没有包含银行和券商等金融板块的上市公司。其中ST公司80家,正常上市公司270家。对这350家公司在其营业能力、现金流量、营运能力、发展能力、风险水平、偿债能力六大类数据指标的基础上,共收集了35个财务数据指标。
由于企业的财务数据指标之间不可能完全独立,而且数据之间存在多重共线性的可能性较大,因而较多的数据指标“必然会使提供的数据发生重叠,甚至会抹杀事物的真正特征”[11]且较多的指标会造成系统构建的复杂,因而本文在进行数据预处理的时候采用主成分分析,选取其中能够最大程度体现样本特征的数据作为系统训练和预测样本。
经过主成分分析,保留方差累计贡献率大于85%的主成分得到以下指标:营业利润率、净资产收益率、资产报酬率、现金流量比、资本支出折旧比存货周转率、营业收入增长率、总资本增长率、营业收入增长率、财务杠杆系数、速动比率、现金比率、产权比率、成本费用率等13个主成分指标。根据主成分负荷矩阵可以了解主成分与原始数据指标的相关关系。
2.异常财务数据指标的处理
由于目前部分公司在进行贷款评估时,为了提高授信级别,会采用虚假的财务数据报告。这种虚假表现出上市公司提供的财务数据指标不正常。财务数据指标异常模式通常以统计异常模式和专家知识异常模式两种方式出现在商业银行信用风险的评估当中。统计异常模式是指个体过度偏离整体的数据行为,如某个企业的现金流量通过不断的现金交易而虚增,某企业以虚构资产结构的形式改变资产负债率等等。统计模式异常体现在财务数据报告中的数据特征明显偏离正常的行业品均数据水平,在进行统计模式异常的检验时,通常以行业平均水平与样本数据的波动率为比较标准,如果与计算的行业平均指标严重偏离,则可认为存在统计模式异常。专家知识异常模式是指违约企业利用寻机性会计进行财务粉饰,其中包括对企业偿债能力、现金及可变现资产的流动性以及企业获利能力的粉饰。对于异常财务指标,本文在进行信用风险预测模型训练前,通过设定的数据识别系统进行异常数据指标的识别和清除。这样,就可以使得为了进行模型训练的而输入到初始样本集中的数据在一定程度上的准确性,从而减少财务数据指标不正常系统初始设置给企业带来的误差。
本文在对财务数据指标进行预处理时,对于统计异常模式,以某行业的多数正常企业的均值与波动率之比确定隶属函数[12],以该函数提出异常企业的财务数据指标。通过较为固定的计算方式考察该企业的财务数据指标是否可以作为模型训练样本。对于专家知识异常模式,本文主要参照同类文献的处理方法,以某行业某公司长期的年报数据为参考进行判断,从而避免纳入异常财务指标。
(二)学习样本数据的选取、处理
作为学习样本来讲,样本选取最有利的原则就是既要满足系统平稳发展的要求,又要使系统能够体现突变的特征,能够准确概括输入数据的一般性和特殊性。在本文中,笔者将350家样本中的240家财务状况良好的公司数据样本以及60家ST公司的数据样本作为训练数据;以剩余50家企业的财务数据样本作为预测样本。输出结果为布尔型离散变量1和0,对应输出结果为“正常”、“违约”。
四 实证研究及结果评价
在以上设计的基础上,我们利用Matlab设计了一个系统对上述程序进行仿真。网络拓扑结构可由用户根据需要来确定,网络的隐含层数及节点数可以根据用户的需要和实际情况来确定,学习因子和动量因子都是根据需要通过键盘输入确定,使一个程序能够实现多个研究项目共享同一套程序代码。另外,我们将初始权值、学习好的权值、训练数据集、测试数据集、应用数据集等数据分别建立文件。样本学习只需进行一次,学习成功后将学习好的权值保存到文件中,测试和实际应用时直接调用已学习好的权值和数据文件。如果系统有较大变动,使不同信用公司的财务比率特征有新的差异,这时可重新选择样本,并进行成功学习后,模型又可投入使用。从这种意义上说,本模型属动态可调整模型,具有良好的适应性。对于两种分类预测模型的预测结果比较,笔者在文中通过考察收敛速度和判误率等指标进行比较。
(一)单隐层BP-Adaboost模型
对于单隐层的BP-Adaboost模型,由于网络层次设置的不同特别是隐含层数节点数会对模型的收敛效率和准确率产生影响,因而在本文中笔者尝试采用不同的隐含成节点数构建系统,通过实证结果比较采用不同隐含层节点数设置时模型的仿真结果(见表1)。
由表1可以看出,在采用不同隐含层节点数构建系统时,系统的仿真结果会产生大小不同的误差。根据前人在进行神经网络的研究时得到的结果,隐含层节点数不宜采用超过输入数据指标的个数,否则会造成模型泛化能力的降低。本文沿袭了这一规律进行模型的设定和构建,因而本文对于超过14的节点数,没有考虑进行模型的仿真模拟。同时,系统隐含层节点书如果少于系统的层次设定数量,也会造成模型对于数据指标的特征抽取能力过弱,所以对于小于4的节点数,本文同样没用纳入模型的仿真处理。而且随着隐层节点数逐渐接近于样本维数,系统对于训练样本进行判别时所产生的第一类错误和第二类错误[13]都呈现逐渐减少的趋势。隐含层节点数到达10以后,两类错误的判别出现率几乎降低为零。同样,对于预测样本而言,也呈现了同样的变化趋势。

表1 不同隐含层节点数系统误差一览表
由此可以看出,在不断增进隐含层节点数至样本维数的情况下,模型对于样本的泛化能力有了较为明显的提高。但是在提高模型运算精度的时候,需要将模型的收敛速度考虑到其中。由于系统在隐含层节点数达到13的时候系统误差达到了一个较为理想的判误比率水平,因而本文将隐含层节点数设定为13进行初始系统的构建。通过预测样本的输入训练、BP系统自身的回馈调整以及Adaboost算法的加权优化,本文得到了强弱预测器对预测样本的处理结果对比(见图1)。
可以看出,在50个预测样本输入到模型当中以后,在BP神经网络中两个样本的预测结果的误差值都降低到了极低的水平,这也再次说明了采用13的隐含层节点数设置是符合本文所选定的财务数据指标的要求的。但是可以看出,经过Adaboost算法优化后的强预测器却实现了比原有BP神经网络更好的分类预测要求。对于图1中体现的序列15左右的样本,可能是由于数据预处理工作中出现的正常误差,没有剔除个别行业的异常数据造成的。同时,经济形式的变化、行业发展形势的差别也会造成一定波动。
(二)双隐层BP-Adaboost模型

图1 单隐层模型强弱分类器预测误差比较
为进一步验证Adaboost算法BP神经网络系统的改进,本文尝试考察双隐含层模型的分类效果对比。与之前的模型设置类似,只需要在隐含层之后再加入一道隐含层,其他的参数设置如节点数,迭代算法等,本文仍然采用与单一隐含层模型相同的设置。将预测样本输入到模型当中以后,得到的强弱预测器的预测结果如下(见图2)。
可以看出与单一隐含层强弱预测器比较,双隐含层预测器的对预测样本的考察结果具有较大的不稳定性,误差的绝对值范围有了较为明显的变大趋势。
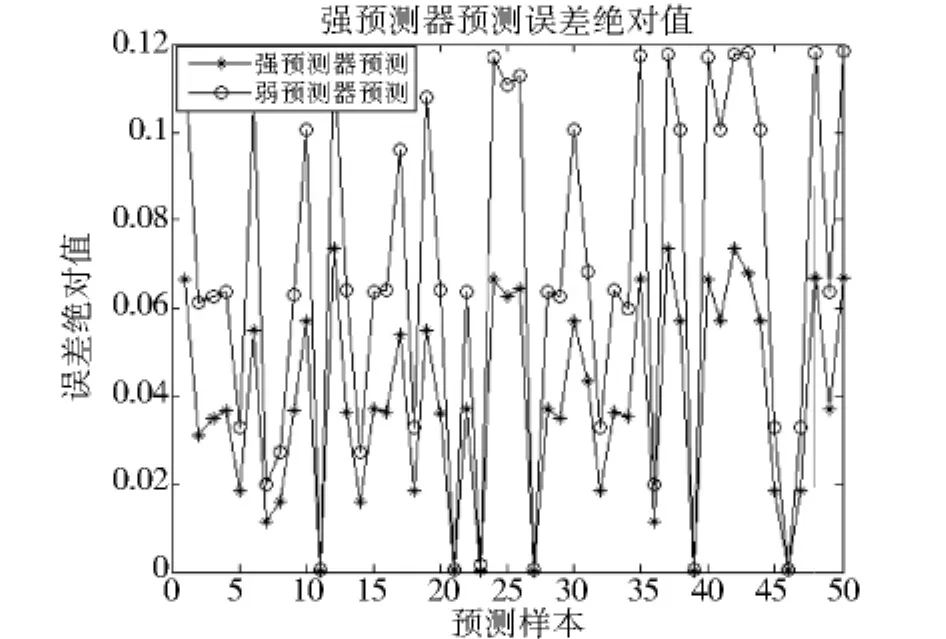
图2 双隐层模型强弱分类器预测误差比较
这也从实证中验证了“理论上讲增加隐含层数可以提高网络的预测精度”这一前人的判断是不准确的。Lippman R P[14](1997)曾经指出,一定条件下,对于较小规模的网络,增加隐含层数并不能提高网络的预测准确率;利用单一的三层神经网络可以逼近任意较为简单的映射关系。比较强弱预测器的预测结果,可以得出同样的结论:Adaboost算法以其加权和注重重点的优势,可以较为准确的判断出那些样本特征是在企业贷款违约中起到较为明显作用的重点。虽然我们看不见重点,却可以将判断企业贷款违约的这个“黑盒子”进一步优化。
就以上实证结果进行分析可以看出,采用Adaboost算法对原有BP神经网络进行优化以后,可以在较大程度上提高商业银行信用风险评估系统的准确率,提高系统的判别精度。同时,本文中笔者还进行了相关收敛速度的考察,得出BP-Adaboost强分类器在提高模型预测精度的同时,并没有在很大程度上影响模型的收敛速度。
五 应用前景分析
本文的研究,在一定程度上为商业银行信用风险管理模型的改进提供了一种改进的可能。在目前国内多家多有商业银行仍然使用以Logitech模型为基础的信用风险评估系统的情况下,一种符合非线性数据特征的模型亟待浮出水面。与现行信用风险评估模型相比较,BP-Adaboost模型的优点体现在以下几个方面:第一,非线性拟合的特点可以更准确的识别客户财务数据的特征,从而避免在进行信用风险评估时的偏差;第二,多重数据的特征通过不通的网络层次设置,也可以避免单纯采用加权平均得分带来的单一性,使得信用风险评估所带来的结果具有说服力;第三,BP-Adaboost强分类器信用风险评估模型中参数的设置比较灵活,可以将代表不同时期经济发展特征因素添加进去,增加了与时俱进的因素。
当然,由于模型的效果只是基于理论上的探讨,还有经过实践彻底的检验,所以在各个商业银行考虑进行基于该模型的商业银行信用风险系统的开发时,也需要考虑到自身模型的发展阶段与该模型的差距,如何利用已有的数据库模式充分的训练该模型的准确性和收敛性,以及自身客户所具备的实际条件和财务数据状况。
[1]OdomM D,Sharda R A.Neural Network for Bankruptcy Prediction,International Joint Conference on Neural Network[R].San Diego,CA,1990:163-168.
[2]TamK Y,Kiang M.Managerial Applications of Neural Networks,the Case of Bank Failure Predictions[J].Management Sciences,1987,vol.38(l):926-947.
[3]Altman E.Marco Getal.Corporrate distress diagnosis:comparisons using linear discriminant analysis and neural networks(the Italian experience)[J].Journal of Bank-ing and Finance,1994(18):511-540.
[4]Kiviluoto K.Predicting Bankruptcies with the Self-organizing Map [J].Neurocomputing 1998(21):199-201.
[5]Salchenberer L M,Ciner E M,Lash N A.Neural Networks:A New Tool for Predicting Thrift Failu-res[J].Decision Sciences,1992(23):899-916.
[6]Back B,Laitinen K.Sere.Neural networks and genetic algorithms for ankruptcypredictions[J].Expert Syst.,1996(4):407-413.
[7]Piramuthu S,Raghavan H,Shaw M.Using feature construction to improve the Performance of neural network[J].Management Science,1998(44):416-430.
[8]徐佳娜,西 宝.基于HAP-ANN模型的商业银行信用风险评估[J].哈尔滨理工大学学报,2004(6):94-95.
[9]郭英见,吴 冲.基于信息融合的商业银行信用风险评估模型研究[J].金融研究,2009(1):95-106.
[10]于立勇.商业银行信用风险评估预测模型研究[J].管理科学报,2003,6(5):46-52.
[11]高铁梅.计量经济分析方法与建模[M].北京:清华大学出版社,2005:465-466.
[12]张德峰.MATLAB神经网络仿真与应用[M].北京:电子工业出版社,2009:320-321.
[13]Tam K.Neural Network Models and the Prediction of Bankruptcy[J].omega,1991,vol.119(19):429-445.
[14]Stanley B.Lippman,C++Primer(3RD)[M].北京:人民邮电出版社,2006:145-146.
