汽车诊断中脚本自动生成工具的研究
2013-08-20丁燕敏
丁燕敏 刘 炜
(上海大学 计算机工程与科学学院,中国 上海200072)
1 汽车故障诊断简介
1.1 汽车故障诊断技术发展简介
汽车诊断技术发展至今,大致经历了以下三个阶段:
第一阶段为20 世纪70 年代至20 世纪80 年代初。 此阶段中,汽车的维修方式主要通过维修人员通过摸、看、听等传统方式及个人经验,通过纯手工工具进行故障判断与排除。 纯手工的诊断方法不但要求维修工程师具有一定的经验, 而且最终诊断的准确性也得不到保障。
第二阶段为20 世纪80 年代初至20 世纪80 年代末,此阶段开始使用故障诊断仪器进行检测。 此阶段中,通过使用故障诊断仪器对故障信息进行采集,虽有效提高了诊断效率与准确性,但依然不能对汽车故障给出最终判断。最终的诊断结果依旧需经验丰富的汽车维修工程师给出。
第三阶段为20 世纪80 年代末至今,此阶段开始大量使用专业的综合性故障诊断仪器进行汽车故障检测。专业的综合性故障诊断仪器有着自动化、智能化等特点,它可完成从故障信息采集、故障判断与定位、读取/清除故障码等一系列功能,减少了故障诊断对个人经验的依赖性,提高了诊断的正确性及维修工程师的工作效率。
1.2 汽车诊断软件简介
现行的汽车诊断软件由诊断系统基本平台与业务数据库构成两者构成。诊断系统平台提供车型选择,数据通信,结果显示等与诊断业务无关的基本功能;而诊断仪相关的业务则有由数据来驱动。其中,汽车常规诊断业务数据因具有一定的通用性,故此类业务可统一成系列数据表格模板;针对诊断业务中的特殊功能则通过特别定制的脚本实现。
2 方案设计
内嵌于诊断软件的脚本因其主要实现诊断业务中的特殊功能,所以其业务逻辑相对复杂。 根据实际现行经验,完整生成一个最终可执行脚本大致有以下几个步骤:
根据诊断业务逻辑,画出与其相对应的流程图:
1)依据流程图,手动编写脚本;
2)手动提取诊断业务相关的逻辑数据,生成数据文件;
3)手动编辑脚本测试文件;
4)编译及修改脚本,生成最终可执行脚本文件;
5)测试并修改脚本,生成最终提交脚本文件。
从上述的脚本开发流程中可以得出脚本开发中存在的以下几个问题:
1)脚本开发过程中,由于大部分工作都需手工完成,可能会存在一定的人为错误;
2)当需开发脚本的数量很庞大时,开发人员的效率不能保证。
综上,若通过第三方工具替代原开发流程中部分的步骤,不但可大大减少脚本的开发时间,而且能有效提高最终的业务数据质量。
2.1 方案概述
考虑到整个脚本开发中,除去最终实测外,只有诊断业务理解也即流程图的绘制是一定需要人工参与的,而其余部分皆可由自动化工具替代。因此将流程图作为切入点,软件通过对流程图的解析,自动生成脚本文件开发所需文件,软件系统框图如图1 所示。首先,本工具会将脚本开发人员需按事先定义好的的流程图规范绘制流程图通过转化器,生成相应的脚本XML 文件,源流程图中的每个图形被对应转换成XML 中的node,每个node 都有其唯一对应的ID。 随后,转化生成后的脚本XML 文件与事先定义的脚本语言规范配置XML 文件一同被系统解析器解析,生成可执行的脚本文件、脚本验证时的测试文件及诊断业务数据文件。本软件按功能模块可以分成流程图转换与系统解析两大部分,下面将会进行详细阐述。
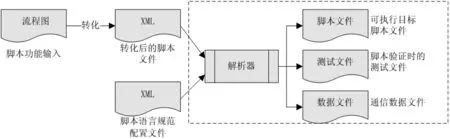
图1
2.2 详细论述
2.2.1 流程图转换
由流程图转换后的XML 文件(covtd.xml),将作为系统解析器的输入文件。 covtd.xml 处理了原始流程图中的分页跳转、页内跳转和子流程。covtd.xml 文件有以下三大节点类型:Process(过程处理), Screen(终端显示), Session (数据收发)。 Process 节点对应流程图中Terminator(起/止符)、Condition(条件判断)以及Deal(运算处理)图形;Screen 节点对应流程图中的Screen 图形; Session 节点则对应流程图中的Send Command 图形。由于covtd.xml 文件涵盖了生成最终文件所需所有信息,所以指定了流程图规范来描述信息,同时便于解析工具解析。
运算处理节点(Deal):
运算处理项中所涵盖的内容包括单一的赋值运算及复杂的逻辑运算等情况;其次,各表达式中使用的变量类型及其作用域又是各不相同的。 综上所述,结合脚本使用情况,规定了下列规范:
变量命名中需表明变量类型,基本格式为:数据类型_ 描述。数据类型可参照C 语言,若数据类型为数组形式时,需在数据类型字段中加上 “Array” 及在描述字段后加上 “[]” 符号。 例:int_Speed=90,byte_Angle=0x30,byteArray_Version[]=0x20,0x21,0x30
流程图中单个节点中,可有多行表达式。 且每一行表达式中可嵌套多个运算表达式。
数据收发节点(数据的一次收发可看成为一个会话,故简称Session):
数据收发部分由发送与接收两个部分组成, 分别通过关键字“Cmd”与“Rcv”区分表示。
鉴于接收与发送的数据长度为可变的,故在关键字后需追加“[]”。
发送的数据包可以是直接字符型的,例:Cmd[]=0x14,0xFF,0xFF;也可是由变量与直接字符混合组成的, 例:Cmd [0]=0x14, Cmd [1-2]=int_Ecode。符号“[]”不填写内容时,表示需发送数据即为赋值的内容;符号“[]”填写数字时,表示需发送的数据列中的内容将被等号右边的内容替换,符号“[]”所填内容为被替换的数据起止地址。
接收数据的表达式中需填写有用的数据包最大长度,例:Rcv[16]。
2.2.2 系统解析
系统解析器首先会对转换后的XML 文件与脚本规范XML 文件中定义类目进行匹配,检测。检测无误后,方可进入内容解析。XML 内容解析由标签管理,变量管理,表达式解析及命令拼接这四部分构成。解析的过程有两步:
第一步:初析。本阶段只完成各节点内容到脚本语言的语义翻译,保留XML 文件中各节点相关原始信息,如变量名,节点间跳转ID,数据信息等。
第二步:精析。 此阶段通过查询各数据表,取得最终输出值并替换原XML 相关信息,删除初析阶段构建的冗余信息,生成最终脚本文件。
标签管理:标签管理分为临时标签与最终标签。 临时标签是解析XML 文件时创建的,每一个Node 都会有其对应的标签;最终标签是指输出至最终脚本文件。解析器对XML 的解析是以Node 为单位进行的,在对Node 解析过程中无法判别此Node 节点是否被其它Node 节点所调用,所以需要通过创建临时标签作为标注。由于XML 文件中所有输入解析器的Node 节点都会创建临时标签,其中必有无用标签。因此,需对标签表进行遍历,删除冗余标签。
变量管理:XML 文件中定义的变量对应到最终可执行脚本中时,变量名由某个存储空间表述。 考虑到实际可使用的存储空间有限,因此需对各变量进行管理。 根据变量的使用,指定以下规则:
(1)只作用于执行单次的流程且不隶属于循环分支的节点中定义变量视为局部变量;其余节点中定义的变量则视为全局变量。
(2)储存回包状态的变量与循环计数器在未特别指明时为全局变量,并为其指定默认存储空间。
XML 文件中的所有变量都通过一个变量表管理,其中该表的key ID 为变量名。 在XML 文件的初析阶段,根据规则1,首先筛选出全局变量与局部变量;其次,为全局变量分配存储空间并更新变量表中的对应信息。 精析阶段,根据当前剩余存储空间并结合规则2,为局部变量动态分配存储空间。考虑到每个脚本都皆为单进程、顺序执行,故对局部变量的存储空间进行复用,即每个存储空间可与多个局部变量对应。 当某局部变量的生命周期到达后,需对之前动态分配的存储空间进行释放,同时更新动态变量分配状态表。
表达式解析:表达的解析通过堆栈解析。 解析时首先将取得的表达式(中缀表达式)翻译成后缀表达式,翻译流程如下:
中缀表达式翻译成后缀表达式的方法:
Stp1: 从左向右依次从输入字串中取得字符ch
Stp2: 若ch 是操作数,直接输出
Stp3: 若ch 是运算符(含左右括号),则:
a:若ch = '(',将ch 放入栈
b:若ch = ')',依次输出栈中的运算符,直到遇到'(' 为止
c:若ch 既不为')' 也不为'(',那么就和堆栈中顶点位置的运算符top 做优先级比较
1:若ch 优先级比top 高,则将ch 压入栈
2:若ch 优先级低于或者等于top,则输出top,然后将ch 压入栈Stp4: 若表达式已读取完,而栈中仍有运算符时,则将栈中运算符依次由顶端输出
其次,根据翻译后的后缀表达式求解最终结果,其求解流程如下:后缀表达式计算方法:
Stp1:从左向右扫描后缀表达式数组,依次取出一个数组元素ch;
Stp2:若ch 是表达式,就压入栈;
Stp3: 若ch 是运算符,就从栈中弹出此运算符需要用到的表达式的个数(二元运算符需要2 个),创建一个新二元表达式,然后把二元表达式压入栈。
Stp4:若数组处理完毕,栈中最后剩余的表达式就是最终结果。
2.3 测试文件构建
通过机器实现测试文件的自动构建, 可以减少开发人员的工作量,提高工作效率。 当然,若是通过机器生成的测试文件不够准确、全面,则开发人员仍需手动检查、修改测试文件,从而使工作效率更低。
此处的脚本测试,是指通过软件模拟实车与汽车诊断仪的通信数据包,验证脚本逻辑流程的正确性。测试过程中,用户需先指定需加载的测试文件;测试文件加载完成后,模拟软件根据测试文件中所罗列的指令数据项,模拟实车与诊断仪通信时的指令数据。 测试文件中需涵盖的指令集中,既会有Reset 这种前后动作逻辑无关指令,又会有读取特定故障码后再清除读出的故障码此类前后动作逻辑相关指令;同时通过直接解析XML 文件,可完整提取各出各指令间的逻辑关系。因此,在解析XML 文件的同时,需收集数据收发指令的信息。鉴于,每一组数据指令都由一条请求指令与一条响应指令构成,故将命令收发节点作为两个指令组的分割标志。
前后动作逻辑无关指令收发数据包内容是固定的。 对应到XML文件的数据收发节点中,即为只有“Cmd[]=0xXX,0xYY……”这一行命令赋值表达式。由于此类指令的收发包内容与格式都可在协议中找到明确的定义,因而,根据数据收发节点中的命令这一个条件即可构建此类指令的测试内容。
前后动作逻辑相关指令中的部分内容由用户定义的,即指令是部分可变的。对应到XML 文件的数据收发节点中,即存在多行“Cmd[]=”此种命令赋值表达式。 对于此类指令中的不变部分的获取方法,可借鉴前后动作逻辑无关指令。 指令中的可变部分,可能是由前驱节点计算获取,也可能需与后继节点中的判断条件匹配。所以对此类指令,需解析完从本命令节点至下一命令节点间的所有节点后,才可构建测试文件。考虑到指令中的可变部分与前驱节点的关联可由一组混有变量名的数学运算式表述;且本程序在对XML 解析的过程中,会对所有变量创建对应的信息表,包括该变量的类型,缺省值,字节序,取值范围,被赋值情况等。因此,结合变量信息表对数学运算式进行语法分析,即可提取出有效数据,并构建请求指令。同样的,对于响应指令包内容需与后继节点判断条件匹配的情况,结合后继判断节点中的判断条件及变量信息表,即可构建响应指令包。
3 结论
本工具现已投入到脚本开发的工作中,根据开发人员的实际使用后的反馈情况,在开发脚本的过程中,通过使用本工具后,现脚本开发所需时间大约为原来脚本开发时间的70%。 同时,由于目前所开发的工具支持的脚本语言有限,给使用带来一定的局限性。 日后的工作将侧重兼容更多的脚本语言,扩展本工具适用范围,提高工具的实用性。
[1]何云东,黄昶.复杂表达式解析和计算的研究实现[J].中国科技信息,2009(8):35-36.
[2]彭四伟,朱群雄.基干源代码分析的逆向建模[J].计算机应用研究,2006.
[3]冯进,丁博,史殿习,等.XML 解析技术研究[J].计算机工程与科学,2009,31(2):120-124.
[4]徐爱春,章坚民.基于XML/XSLT 代码自动生成技术研究[J].杭州电子工业学院学报,2004,24(4):64-68.
[5]王茹,宋瀚涛.XML 文档结构定义规范:XML Schema[J].计算机应用研究,2002,19(1):127-129.
