智能蠕虫自动遏制方案
2013-08-13□王欣
□王 欣
(太原旅游职业学院,山西太原030006)
互联网目前已经发展成为当今世界上规模最大、拥有用户最多、资源最广泛的通信网络。在全球经济和人们的生活中起着越来越重要的作用,与此同时,随着计算机蠕虫的出现,网络安全也受到了极大的挑战,许多重要数据遭到破坏和丢失,造成社会财富的极大浪费。例如:SQL Slammer蠕虫病毒在十分钟内感染了互联网上的90%的易感主机[1];“红色代码Ⅱ”蠕虫病毒,该蠕虫2001年7月19日从开始发作的9个小时里,它就感染了35万多部计算机系统[2],造成经济损失12亿美元。因此,我们需要自动检测和及时响应防御网络蠕虫病毒。
网络蠕虫的自动遏流技术为网络中的每台主机设定一个扫描率的上限[3,4]。利用该方法能自动遏制具有快扫描率的蠕虫,然而对扫描率缓慢的蠕虫没有效果,原因是正常的网络流量和蠕虫扫描的网络流量之间差别非常小[5],在不影响网络正常工作的情况下设置蠕虫扫描率阈值是非常困难的。
美国学者塞尔克等人[5]提出了基于扫描次数的遏流技术,针对每台具有独立IP地址的主机,设置其在一个时间周期内的扫描次数的阈值,通过累积效应将蠕虫的异常扫描从正常网络扫描中区分出来。然而,对于具有扫描率低且易感率高的智能蠕虫,该方法仍然无效。本文的研究目的就是要限制这类蠕虫的传播。
本文提出了基于局域网的遏流技术,该方法利用同一局域网内用户信息需求上的相似性,为每个局域网而不是个体主机设置其在一个时间周期内扫描次数的阈值,如果子网在一个周期内对不同IP地址的总扫描次数超过了设定的阈值,就认为这个网络可能被蠕虫病毒感染,他的扫描率就会被限制。实验结果表明,本方法可以有效地检测出智能蠕虫引起的网络流量,实现控制智能蠕虫病毒的目的,但对正常网络流量的影响很小。马卫东等人[6]的研究也表明同一局域网内用户访问网站呈现幂律分布和集聚现象,具有相似特性。
1 相关的工作
下面我们通过Staniford提出的简单蠕虫感染(RCS)模型[7]来研究蠕虫的传播,假设在一个系统没有打好补丁的且感染速度恒定的网络环境下,蠕虫传播方程式如下:
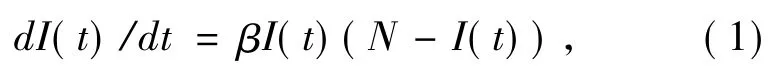
其中,I(t)代表t时刻网络中感染节点的数量,β代表蠕虫感染率,N代表网络中节点的总数量。
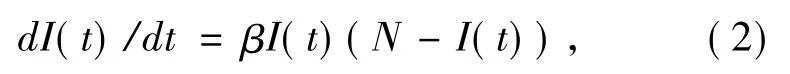
在(1)的基础上,我们将RCS模型速率控制方案进行修改,对定时扫描率加入一个限制因素[3,4]:其中,β1为限流因子且β远大于β1,这个方案只能有效地减缓快速蠕虫病毒,而对慢扫描蠕虫病毒无效。为了能有效分隔蠕虫流量与正常流量,蠕虫检测系统的研究人员[8]提出了使用卡尔曼滤波器来检测蠕虫。
Kabiri等人[9]开发了一个网络入侵检测系统(NIDS),但系统中的知识库需要手工维护。为了自动获取蠕虫检测系统中的知识库,文献[10,11]引入了机器学习的方法。
傅建明等人则提出了基于邻居报警模式的蠕虫遏制模型[12],该模型的前提是要求免疫节点受感染时必须向其邻居发送报警信号,如果邻居不发送警报,则该模型将失去作用。
2 蠕虫遏制方案
在本节中,我们首先介绍智能蠕虫遏制方案,然后给出一些模拟结果。令Ms是局域网扫描次数的阈值,即一个局域在一个周期内允许的最大扫描次数;Sf表示对可疑局域网所允许的最大扫描率,即对可疑网络遏流后该网络的最大扫描率。下面给出遏制蠕虫的方案:
I.对每个局域网,设置计数器来监控不同IP地址流量,计数器初始值为零;
II.当子网有新的IP地址扫描请求时,增加该子网计数器的值。
III.如果子网计数器的值达到了阈值,这时他的扫描率将被限制为Sf。
IV.在一个时间周期结束后,释放可疑子网的扫描控制率,然后复位计数器,重新回到I。
注意到Ms和Sf的取值对蠕虫病毒的传播有很大的影响,由此我们可以设定一个允许的感染比例来反求上述参数的值,这部分将在后面的实验部分进一步说明。
Nlanr[13]的跟踪了贝尔实验室的400位工作人员一个星期内的网络访问数据,总共访问了46K个不同的IP地址。也就是说单位小时内该子网联系的IP地址总数为280个。然而,与这些IP地址接触的总人次数超过了60K,反映了该子网用户对网络访问的聚集特性。
尽管本文设计的方案对所有子网均有效,为简单起见,我们假设每个子网有400个终端主机,并且只有一个公共的IP地址分配给Web代理服务器。当这个Web代理服务器被感染了病毒后,那么内部主机被蠕虫病毒感染的几率也会很高(实验中假定为50%)。此外,由于蠕虫在局域网内的传播速度非常快,我们忽略内部传播时间。我们假设蠕虫的扫描率为每小时2,低于文献[13]中排前10的主机的扫描速率。设P=0.005代表漏洞密度,那么感染率(β)为每小时0.01。
首先仿真了系统中随机扫描的智能蠕虫的传播过程,图1给了扫描次数阈值(Ms)取不同值时的模拟结果。
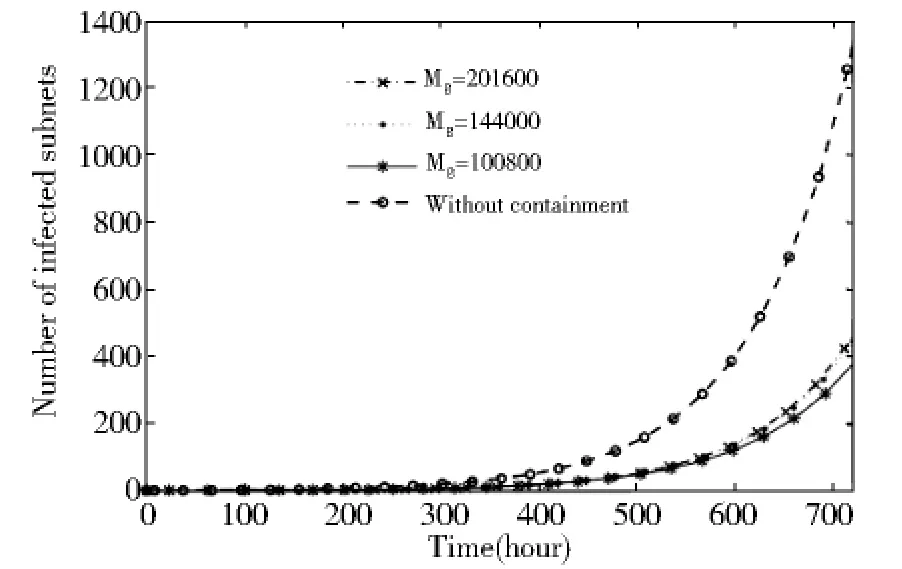
图1 不同扫描次数阈值(Ms)与RCS系统对比
图1表明,本文给出的遏流技术能有效地遏制智能型蠕虫的传播,与RCS系统比较能遏制66%以上的蠕虫传播。图1还表明,不同的局域网扫描次数阈值之间的遏流效果差别很小,这是因为最大的阈值也能有效地遏制智能蠕虫的传播。
图2给出了当对可疑子网采用不同遏流率(Sf)时的影响。其中,检测周期为30天,局域网扫描次数阈值(Ms)为100800。
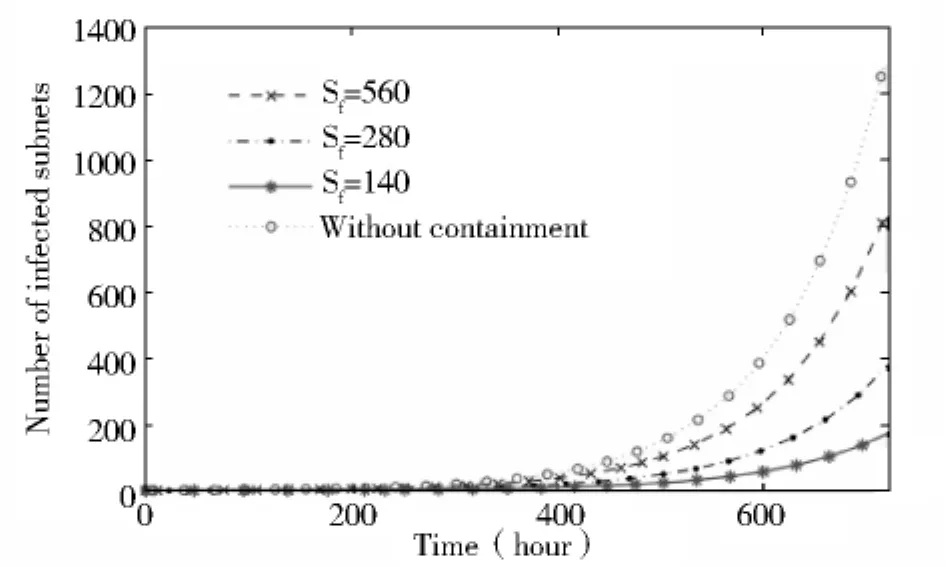
图2 不同遏流率(Sf)与RCS系统对比
正如图2所示,当可疑子网的扫描率被限制为140时,感染蠕虫的子网总数小于200,仅仅是RCS系统的1/7。此外,图2还表明子网感染总数与SF值成正比。然而,即使可疑子网的扫描率(Sf)为560,两倍于正常网络扫描率,本系统对网络蠕虫的遏制效果仍然高于33%。
3 动态免疫的影响
在上一节中,并没有考虑系统修复及动态免疫的影响。但实际是,防病毒程序会动态扫描蠕虫所利用的漏洞。如果漏洞被修复,感染的进度将会受到阻碍。
为了能模拟动态修复对蠕虫传播的影响,在本文的遏制系统中引入了几何时间修复策略(TTR)[14]。在每个时间步长上,受感染的子网变为免疫状态的概率为δ。在模拟系统中,令δ=0.003,即平均修复的时间为两周,图3为仿真结果。
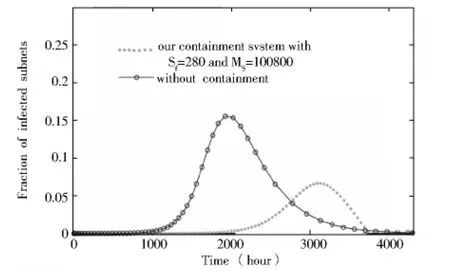
图3 考虑动态免疫的对比
从模拟显示的结果来看,当动态免疫被考虑时,RCS模型有15%以上的易感子网将被感染,而基于局域网的遏流模型仅仅有7.5%的易感子网被感染,表明本文的遏流系统能产生50%的遏制作用。此外,基于局域网的遏流系统还能推迟感染峰值的到来,为遏制蠕虫传播提供准备时间。
我们还模拟了动态修复率δ取不同值时对蠕虫传播的影响,图4给出了当δ分别取0.0014,0.003和0.0035时的情况。其中,Ms和Sf分别取100800和280。
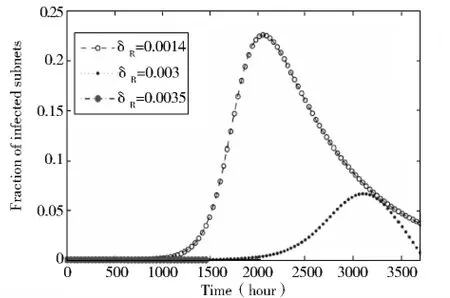
图4 δ=0.0014,0.003和0.0035时的感染比例
从图4我们发现,如果平均修复时间不超过两周时间,随机扫描蠕虫将不会启动,这为我们有效地控制随机扫描蠕虫的传播是非常重要的。
4 结论
最近,有关网络安全和恶意软件的研究多集中在了防病毒系统和病毒之间,如快速的入侵检测[15]与自动的病毒遏制[5],然而他们对扫描率缓慢且易感率高的蠕虫却是无效的。
在本文中,我们利用同一子网内用户信息需求的相似性,提出了基于局域网的遏流技术来限制慢扫描和脆弱性高的智能蠕虫。研究结果表明,无论是否考虑动态免疫本文提出的方法对慢扫描和高易感性的智能蠕虫都是有效的。也就是说,可以给出一个合理的阈值并利用该阈值将感染子网与正常子网区别开来,为防病毒系统提供了有价值的信息。该方法可以很容易地限制恶意软件在笔记本电脑[16]与手机病毒[17]的传播。
下一步,我们计划建立模型刻画同一子网内用户信息需求的相关性,同时利用从企业网络中的真实数据来评估本文提出的遏流系统。我们的研究仅限于随机扫描蠕虫病毒的传播,接下来我们将研究拓扑感知蠕虫传播模型并提供相应的遏制系统。
[1]Moore,D.,Paxson,V.,Savage,S.,Shanon,C.,Staniford,S.,Weaver,N.:Inside the slammer wor.IEEE Security and Privacy journal,2003.
[2]Moore,D.,Shanon,C.:The Spread of the Code - Red Worm(CRv2)(2001),http://www.caida.org/research/security/code-red/#crv2.
[3]Williamson,M.M.:Throttling viruses:Restricting propagation to defeat malicious mobile code.Technical Report HPL -2002 -172,HP Laboratories Bristol,2002.
[4]Wong,C.,Wang,C.,Song,D.,Bielski,S.,Ganger,G.R.:Dynamic Quarantine of Internet Worms.In:Proc.IEEE Int’l Conf.Dependable Systems and Networks,2004:73-82.
[5]Sarah,S.H.,Shroff,N.B.,Bagchi,S.:Modeling and Automated Containment of Worms.IEEE Transcations on Dependable and Secure Computing,2008(5):71 -86.
[6]马卫东,王 磊,李幼平,等.用户需求行为对互联网动力学整体特性的影响[J].物理学报,2008(3).
[7]Staniford,S.,Paxson,V.,Weaver,N.:How to Own the Internet in Your Spare Time.In:Proc.Usenix Security Symp.,2002:149 -167.
[8]Zou,C.C.,Gong,W.,Towsley,D.:Monitoring and Early Warning for Internet Worms.In:Proc.ACM Conf.Computer and Comm.Security,2003:190 -199.
[9]Kabiri,P.,Ghorbani,A.A.:Research on Intrusion Detection and Response:A Survey.International Journal of Network Security,2005(1):84 -102.
[10]Kolter,J.Z.,Maloof,M.A.:Learing to detect malicious executables in the wild.In:Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2004:470 -478.
[11]Moskovitch,R.,Gus,I.,Pluderman,S.,Stopel,D.,Feher,C.,Glezer,C.,Shahar,Y.,Elovici,Y.:Detection of Unknown Computer Worms Activity Based on Computer Behavior using Data Mining.In:Proc.IEEE Symposium on Computational Intelligence and Data Mining,2007:202-209.
[12]Fu,J.M.,Chen,B.L.,Zhang,H.G.:A Worm Containment Model Based on Neighbor- Alarm.In:Xiao,B.,Yang,L.T.,Ma,J.,Muller - Schloer,C.,Hua,Y.(eds.)ATC 2007.LNCS,vol.4610,pp.449—457.Springer,Heidelberg(2007).
[13]Nlanr.:Bell Lab - I Data Set(2007),http://pma.nlanr.net/Traces/long/bell.html.
[14]Debany Jr.,W.H.:Modeling the Spread of Internet Worms Via Persistently Unpatched Hosts.IEEE Netw,2008(22):26-32.
[15]Stephenson,B.,Sikdar,B.:A Quasi- Species Model for the Propagation and Containment of Polymorphic Worms.IEEE Trans.Computers,2009(58):1289 -1296.
[16]王骥东,俞建军,李 琦.网络蠕虫检测技术研究与实现[J].计算机时代,2009(9).
[17]亓 璐,吴海峰,翟 鹏,等.网络蠕虫扫描策略和检测技术的研究[J].计算机安全,2010(5).
