基于统计和规则的常用词的兼类识别研究
2013-07-25柴玉梅昝红英
夏 静,柴玉梅,昝红英
(郑州大学信息工程学院,河南郑州450001)
0 引言
在中文信息处理领域的研究中,汉语语料库的质量具有举足轻重的作用,高质量的语料库越来越受到学者们的关注。目前有许多研究领域都使用到了汉语语料库,比如:机器翻译、语音识别、文字识别、信息检索等。要得到高质量的语料库,词性标注是基础,目前汉语的词性标注已经成为一个很重要的研究课题。由于词的兼类现象的普遍存在,给词性标注带来了很大困难,因此,正确识别兼类词的词性是词性标注问题的关键之一。
“兼类词“指的是在一定的词类体系中兼属两个或两个以上不同词类的词。那么,兼类词的数量与给定的词性标记集有关,一般情况下,词性标记集越详细,词的兼类情况就越复杂。兼类词的数量虽然不多,但使用频率很高,因此解决好兼类词的词性标注问题对于提高词性标注的正确率具有重要意义。目前对于兼类词的词性标注的研究,有许多相关的技术和文献:基于分类器集成的兼类词消歧研究[1]、基于条件随机场 (CRFs)的中文词性标注方法[2]、基于分类的汉语语料库词性标注一致性检查[3]等。这些研究中有些仅仅是选取词作为特征,在数据稀疏时会影响分类的结果;有些仅仅是采用了一种方法对兼类词进行了研究没有充分的对比说明,并且没有考虑到上下文窗口对标注的影响,针对目前的研究现状兼类词的识别问题还有待进一步的研究。
本文基于兼类词的词性与它所在的上下文环境之间的依赖关系,综合考虑了影响兼类词识别的词语信息、词性信息以及词语和词性的复合信息作为特征,通过对上下文窗口的设置来改变特征语料的提取,不断进行测试以找到合适的窗口。采用统计的不同方法和规则的方法分别对兼类词的识别进行了进一步的研究,并取得了较好的结果。
1 常用词的兼类识别
近年来,在自然语言处理 (NLP)研究中,已经有许多机器学习的统计模型,其中有隐马尔科夫模型 (HMM)、支持向量机 (SVM)、最大熵 (ME)以及条件随机场(CRF)等,本文采用了在词性标注方面应用较多且效果比较好的条件随机场模型、最大熵模型和k最近邻算法对兼类词进行标注,针对统计方法效果不够理想的词,又尝试了规则的方法进行标注,最后给出了相应的实验结果,并进行对比分析。
1.1 基于条件随机场模型的识别
条件随机场 (conditional RandomFields,CRF)的概念自2001年被J.Lafferty等人[4]提出以来,被广泛应用在信息抽取、命名实体识别、语义角色标注[5]、汉语词义消歧[6]等领域。CRF的突出优点就是可以相对任意地加入任何与处理对象相关的语言学特征,并且能够充分考虑上下文中的特征,综合利用词和词性等资源,所以,对于基于CRF模型的兼类词识别,主要考虑选取哪些特征对词性识别有利,而不必顾及其他的因素。
兼类词的词性识别看做是一个序列标注任务,通过判断该兼类词所在的不同的上下文环境,即考虑词语、词性以及词语和词性的复合信息进行特征的选取,并根据这些特征判断其所属的词性。
在基于CRF的兼类词词性标注中,需要将训练文件和测试文件转换成一定的文件格式。训练和测试文件必须包含多个块,一个中文句子对应一个块,块与块之间用空格间隔,每个块包含多个tokens,每个token必须写在一行上,且包含多个列,各列之间用空格间隔。Token的定义可以根据具体的要求来选择,如词语信息、词性信息等。我们需要对语料进行预处理,把含有该兼类词的所有句子都提取出来。表1为上下文窗口为4的数据格式。
在表1中,W代表的是该兼类词,W-i(i=1、2、3……),P-i(i=1、2、3……)分别代表在上下文环境中该兼类词左边 (上文)紧邻的词语和词性信息。W+i(i=1、2、3……),P+i(i=1、2、3……)分别表示在上下文环境中该兼类词右边 (下文)紧邻的词语和词性。P表示该兼类词的词性编码。
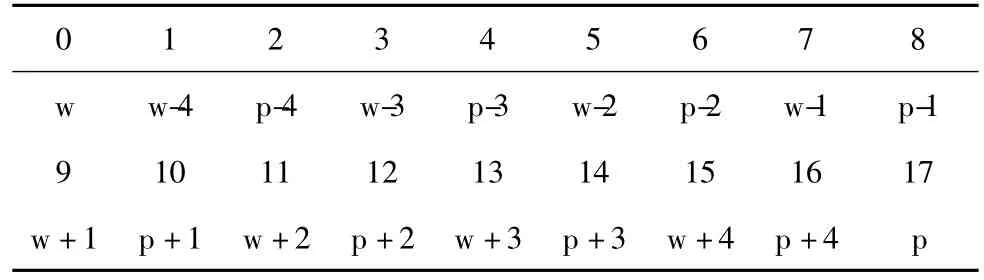
表1 上下文窗口为4的数据格式
例如,兼类词“以”的上下文窗口为4的数据格式如下
以根本 a利益 n,wd并 c此 rz作为 vl改革 v发展 v p
模板文件可以定义一元特征、二元特征及n元特征,同时也可以定义复合特征。模板的格式样例如下所示:
#Unigram
U01:%x[0,1]/%x [0,2]
U02:%x[0,3]/%x [0,4]
U03:%x[0,5]/%x [0,6]
U04:%x[0,7]/%x [0,8]
U05:%x[0,9]/%x [0,10]
U06:%x[0,11]/%x [0,12]
U07:%x[0,13]/%x [0,14]
U08:%x[0,15]/%x [0,16]
#Bigram
B
通过选择不同的模板进行标注,我们需要得到以下结果,用兼类词“以”为例,如下是标注后的结果:
以根本a利益n,wd并c此rz作为vl改革v发展v p p
对比标注后的结果,第17列代表兼类词“以”在未标注语料句子中的原始词性,即标注前的词性;第18列表示实验标注后的词性,即CRF标注的结果。
1.2 基于最大熵模型的识别
最大熵模型的概念最早是由E.T.Jaynes在1957年提出[7],其基本原理就是当把不完整的信息当做依据去做预测时,应当由满足分布限制条件且熵最大的概率分布得到,也就是对未知的知识进行预测时根据已有的知识建模,而对未知的知识不做任何的假设。在自然语言处理中,最大熵模型已经有许多重要的应用,在词义消歧[8]、词性标注[9]、文本情感倾向性分类[10]、组块分析等方面取得了较好的效果,因为其对特征之间不要求其独立性,所以不用考虑它们之间是否会相互影响。
针对最大熵模型在兼类词识别的问题上,可以把兼类词的目标类看成是在其上下文的环境中所发生的概率,这个语境条件可以包括上下文的词语、词性以及句子结构等信息特征。在本文中主要考虑选取哪些特征对兼类词的识别有用而不用顾及其它的因素,通过对语料的大量分析,主要选择兼类词所在上下文中的“词语”信息、 “词性”信息、“词语+词性”复合信息作为ME模型的特征,对于不同的兼类词来说,特征选择不同识别结果也会不同。本文把最大熵模型应用在兼类词的识别方面,并取得了较好的实验结果。
在基于ME的兼类词词性标注中,需要将训练文件和测试文件转换成如下的文件格式

其中,lable是兼类词标注的类别,f1,f2,…,fn是提取特征的相应标号,v1,v2,…,vn是所提取的不同特征。
例如,上下文窗口为4的兼类词“以”所使用的训练数据和测试数据格式:
“p w0=以 w-4=根本 p-4=a wp-4=根本a w-3=利益 p-3=n wp-3=利益n w-2=,p-2=wd wp-2=,wd w-1=并 p-1=c wp-1=并 c w+1=此p+1=rz wp+1=此rz w+2=作为 p+2=vl wp+2=作为vl w+3=改革 p+3=v wp+3=改革v w+4=发展 p+4=v wp+4=发展v”
其中,w表示词语,p表示词性,wp表示词语与词性的组合特征,,w0表示待标注的兼类词,p为待标注兼类词的词性编码。对于测试数据来说第一列可以去掉,但为了便于实验结果的统计,保留测试数据中的第一列。当标准语料经过预处理得到上述格式后,就可以根据需要的不同特征对数据进行不同的预处理。
1.3 基于K最近邻算法的识别
K近邻方法 (k-nearest neighbor,KNN)是基于统计的分类算法,是数据挖掘分类算法中比较常用的一种方法,它是由Cover和Hart在1968年首次提出的,属于懒惰学习方法,思想十分简单直观,原理上依赖于极限定理。分类思想是:给定一个待分类的样本x,首先找出与x最接近的或最相似的K个已知类别标签的训练集样本,然后根据这K个训练样本的类别标签确定样本x的类别。
在KNN算法中,所选择的邻居都是已经正确分类的对象,该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。同时,在类别分类的时候,影响分类的结果只与少量的最相似样本相关,所以,KNN算法可以有效的避免样本分布不平衡所带来的影响。在这里k的选择比较关键,如果k值太小,可能对数据的局部特征比较敏感导致分类结果不稳定,k值太大,也会平滑掉单个数据点产生的影响,造成结果偏差。
在基于k最近邻算法的识别中,我们选择数据挖掘中最常用的工具weka进行实验,针对需要得到的不同特征结果,编写预处理程序,不需要写特征模板。在这里,我们分别选取了 (词、词性、词+词性)3种不同特征对实验语料进行了处理,并且通过选择合适的窗口得到不同的特征信息,综合考虑了在KNN方法中,这3种特征对兼类词识别的影响。
1.4 基于规则的方法
基于规则的兼类词识别,就是针对兼类词在不同上下文中的使用构建识别规则,然后通过编制识别程序,对语料库中的兼类词进行词性识别和标注。目前,郑州大学自然语言处理实验室根据现代汉语虚词用法特征的不同表现,构建了三位一体的虚词知识库[11-12]。
本文主要是针对一些用统计方法识别效果不够好的兼类词考虑基于规则的方法,即根据它们不同词性的不同特征,抽取其中具有可操作性的判断条件,利用BNF范式对兼类词的词性进行了描述。具体做法是:首先根据这些兼类词在上下文中的词语、词性信息以及在句子中的结构关系构建一组规则,未来得到正确性和完备性更好的规则,需要在大量的语料上对规则进行反复测试、改进,最终得到识别效果比较好的规则库。
兼类词词性的规则可以形式化描述为:
<ID > → [F][M][L][R][N][E]
F→<词1>|<词2>|…|a|v|n|…
M→<词1>|<词2>|…|a|v|n|…
L→<词1>|<词2>|…|a|v|n|…
R→<词1>|<词2>|…|a|v|n|…
N→<词1>|<词2>|…|a|v|n|…
E→<词1>|<词2>|…|a|v|n|…
其中,ID为所识别的兼类词的词性编码,F表示句首信息,M表示其左边搭配的词语或词性信息,L表示其左边紧邻的信息,R表示其右边紧邻的信息,N表示其右边搭配的信息,E表示句末信息。
如下是兼类词“首先”的规则描述样例:
MYM首先
@ <c>→N^N→其次|第二|然后|随后|之后|再
@ <d>→R^R→v
@ <c>→F^F→ ~
@ <d>→N^N→ [w]*v
兼类词的每一个词性规则都可以看做是一个模式表达式,因为符号的特殊性,这个模式语言的定义并不能认为是正则表达式。在本文中我们考虑把兼类词的识别问题看成是字符串的匹配问题,而正则表达式在文本字符的处理方面具有高效、易用的优点,所以考虑将BNF范式的规则转换成正则表达式,即将BNF形式的规则中各种特征所定义的词性进行实例化,然后用实例化后所得到的词集去替换对应的词性字符,在对其它的匹配字符也做相应的转化,就得到了规则的正则表达式,最后对语料在特征属性匹配器上进行字符串的匹配,根据匹配结果确定兼类词的词性编码。
具体的算法思想如下:
(1)初始化语料库和兼类词的规则库,读取的语料按行存放,即将文本语料切分成一个个的句子,并以动态数组的形式读入内存中,兼类词的规则是以哈希表的形式写入内存。
(2)读取待识别的一个整句,并找出句子中所要识别的兼类词以及对应的规则,然后对整句进行预处理,得出兼类词在原始语句中的位置。
(3)第三步是一个规则解析、识别匹配的过程,在找到待标兼类词的规则后,按照规则顺序读取规则,按照规则的描述由匹配器调度程序确定出发的匹配器类型,然后由相应的匹配器解析规则并进行对应的匹配。
(4)最后根据匹配的结果确定兼类词的词性标注结果,如果这个句子中的所有兼类词都已经标注完毕,就转到上一步中继续读取下一个句子,循环进行,直到所有句子都标注完毕。
以2000年1月份分词和词性标注的《人民日报》语料作为兼类词识别研究的语料库之一,下面是包含兼类词“首先”的语料样例:

机器在对其进行识别的时候,首先要读取语料文件和规则文件,也就是对语料和规则进行初始化,语料以行为单位读入数组中,规则是以哈希表的形式存放在内存中,读取一条规则判断是否与数组中的语料匹配,如果匹配不成功,则继续读取第二条规则,判断是否与语料进行匹配,如果匹配成功,则把该规则所表示的词性代码标注在语料上。如下是兼类词“首先“标注后的结果样例:


2 实验设计与分析
实验语料采用的是2000年1月的已完成切词和词性标注的《人民日报》语料,并进行人工校对后作为实验用的标准语料。标注系统的性能很大程度上取决于训练和测试模型所使用的特征,根据不同模型训练数据的格式和兼类词语境的特点,我们把上下文窗口的有效范围控制在 (-5,5),即考虑该兼类词在句子中上下文窗口5以内的词语、词性及 (词语+词性)复合信息,这样可以获得较好的识别结果,如果窗口再增大,有效信息也不会明显的增加,反而会带来更多的噪音。
2.1 基于条件随机场方法
本文采用CRF++工具包 (CRF++:Yet Another Toolkit[CP/OL].http://www.chasen.org/ ~ taku/software/CRF++)作为自动标注工具。为了更好地验证模型的性能,对每个词都采用了4折交叉验证,最后得到各个词的平均交叉结果。
表2是3种不同特征的CRF模型实验结果对比,对常用的兼类词进行了实验,下表中选取了几个具有代表性的兼类词。其中,a代表使用词语为特征的信息,b代表使用词性为特征的信息,c代表使用 (词语+词性)复合特征的信息。

表2 CRF准确率
从表2的实验结果可以看出,用基于统计CRF模型的方法进行兼类词的识别,正确率基本上可以达到90%以上,当选取兼类词上下文的词性信息做为特征进行兼类词的识别时,正确率比其他两种特征 (词语或者词语+词性)都要高,由此可见,特征模板b能够有效的提高兼类词标注的正确率。当然也不排除出现的个别现象,比如上面的兼类词“首先”就是在选取词语为特征时正确率比较高。
2.2 基于最大熵方法
本文在基于最大熵的兼类词识别实验中,模型的训练和测试使用了Zhang Le的最大熵工具包maxent maxent(http://homepages.inf.ed.ac.uk/s0450736/maxent_too lkit.html)。
在本文实验中,我们对实验所用的标准语料按照maxent工具包可识别的格式进行预处理。我们选取了不同的特征(a词语特征、b词性特征、c词语+词性复合特征)进行实验,对每个词的ME模型都采用了4折交叉验证,得到各个词的平均交叉结果,并把3种不同特征的结果进行比较分析。表3是三种不同特征的ME模型的实验结果对比。
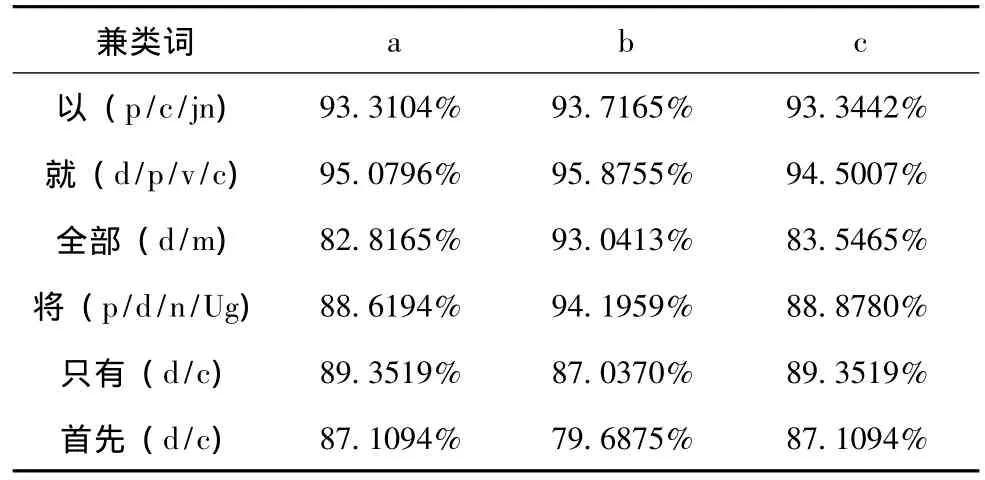
表3 ME准确率
由表3的实验结果可以得出,用基于最大熵模型的方法对兼类词进行识别时,大部分兼类词在选取特征模板b(上下文的词性信息)进行实验时正确率比较高,但整体分类效果不如CRF模型的好。也有一些个别现象,如兼类词“首先”的ME正确率略高于CRF模型的结果。
2.3 基于k最近邻的方法
我们用的是数据挖掘最常用的工具weka进行分类实验,首先通过预处理程序对实验语料进行不同特征的处理,通过实验选取合适的k值,并且经过大量的交叉验证实验得出,大部分的词都是在交叉系数为10或者11时正确率比较高。表4是3种不同特征的KNN方法的实验结果对比。
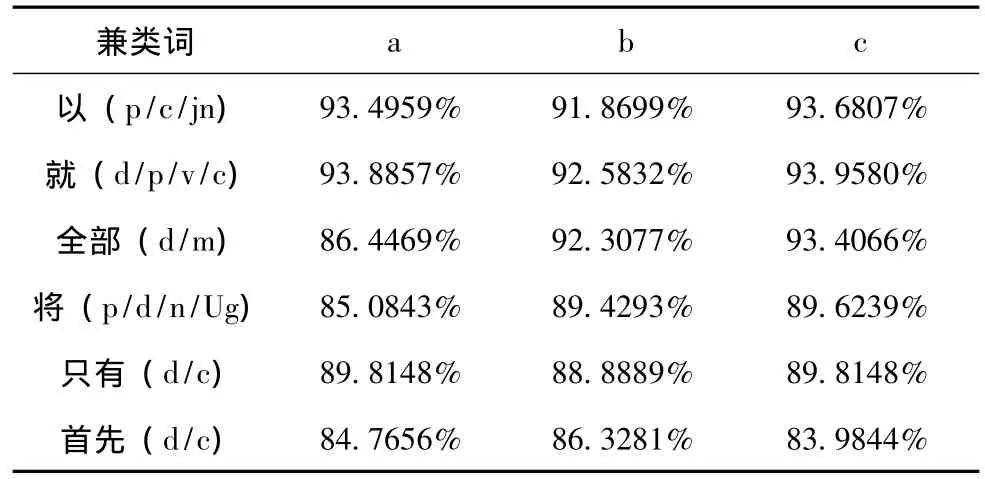
表4 KNN准确率
由表4的实验结果可以得出,用基于k最近邻的方法对兼类词进行识别时可以有效的提高识别的正确率,并且标注正确率可以达到90%左右。当我们选取上下文的 (词+词性)为特征时,也就是用特征模板c可以更好地提高识别正确率,但整体效果不如前两种方法。有些兼类词的个别现象主要是由于它的词性在语料中分布不均匀所造成的。
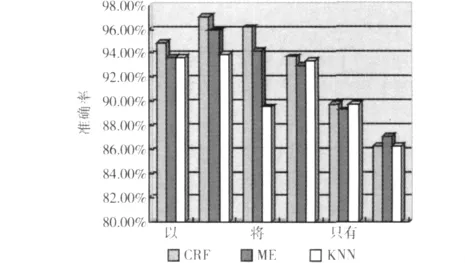
图1 三种统计方法的实验结果
从图1的结果可以看出,在用基于条件随机场方法对兼类词进行识别,并且选取词性信息作为特征模板时,正确率比较高,总体上优于ME方法和KNN方法,并且在用不同的统计方法进行兼类词的识别时,针对不同的方法选取对其有效的特征信息也是很重要的。但观察图1中兼类词的实验结果发现,这些词并不是都存在一致的现象,如:“首先”就是ME模型识别效果比较好,针对这些个别现象,我们考虑了规则的方法。
2.4 基于规则的方法
针对以上统计方法识别效果不够好的兼类词,如:“首先”、“只有”等,这些兼类词在用统计方法以及特征选取时跟大部分兼类词的情况不一致,对于这些个别现象的词,又尝试了利用规则的识别方法,以下是规则的实验结果。
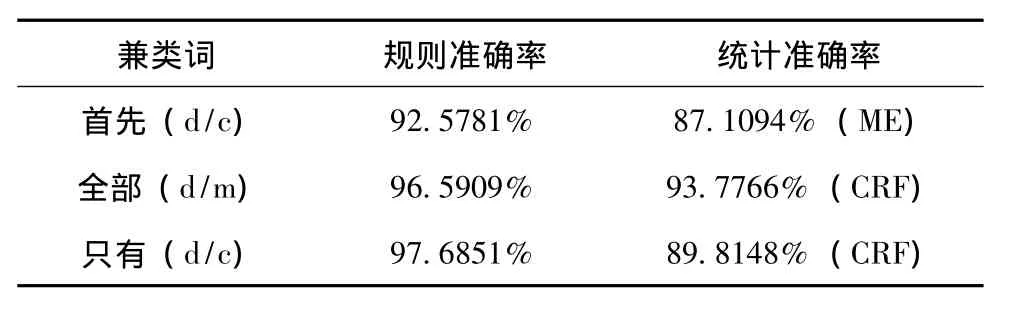
表5 规则结果对比
对于统计方法识别结果不好的词,可能是由于这些词在不同上下文的语境中很难找到一个整体一致的特征,其特征呈现多样化,以此影响了识别的准确率。由表5结果可以看出,这几个兼类词的规则识别效果高于统计方法的结果,所以针对基于统计方法识别准确率不高的兼类词,可以尝试利用规则的方法来进一步的提高其正确率,当然这里边获得一个综合性很高的规则是很重要的,需要经过在大量的语料上进行测试,不断发现规则的问题,并且反复的修改规则库来提高识别的正确率。
3 结束语
本文主要使用了基于条件随机场、最大熵、K最近邻三种统计方法对常用的兼类词进行识别研究,并针对不同的方法分别考虑了兼类词本身的特点以及在上下文中的词语、词性以及词语+词性的综合信息对其产生的影响,通过对上下文窗口的设置进一步改变对特征的提取以达到较高的识别准确率。针对统计方法中的个别现象又考虑了用规则的方法进行研究,并介绍了规则的形式化描述及基于规则的兼类词识别算法思想。进一步的工作是针对更多的兼类词尝试用规则的方法进行识别,完善规则库,并且尝试用聚类的方法对兼类词的识别进行研究。
[1]ZHANG Yizhe,QU Weiguang,LIU Jinke.Research on disambiguation of multiple syntactic category words based on ensemble of classifiers[J].Journal of Nanjing Normal University,2010,33(4):144-147(in Chinese).[张一哲,曲维光,刘金克.基于分类器集成的兼类词消歧研究[J].南京师大学报,2010,33(4):144-147.]
[2]HONG Mingcai,ZHANG Kuo,TANG Jie.A Chinese part of speech tagging approach using conditional random fields [J].Computer Science,2006,33(10):148-151(in Chinese).[洪铭材,张阔,唐杰.基于条件随机场 (CRFs)的中文词性标注方法 [J].计算机科学,2006,33(10):148-151.]
[3]ZHANGHu,ZHENG Jiaheng.Consistency check on POStagging of Chinese corpus based on classification [J].Computer Engineering,2008,34(8):90-92(in Chinese).[张虎,郑家恒.基于分类的汉语语料库词性标注一致性检查 [J].计算机工程,2008,34(8):90-92.]
[4]Lafferty J,McCallum A,Pereira F.Conditional random fields:probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th ICML-01,2001:282-289.
[5]Cohn T,Blunsom P.Semantic role labeling with tree conditio-nal random fields[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning.Ann Arbor,Michigan:Association for Computational Linguistics,2005:169-172.
[6]MIAO Xuelei.Chinese word sense disambiguation method based on conditional random fields[D].Shenyang:Shenyang Aerospace U-niversity,2007(in Chinese).[苗雪雷.基于条件随机场的汉语词义消歧方法研究[D].沈阳:沈阳航空工业学院,2007.]
[7]Jaynes E T.Information theory and statistical mechanics [J].Physics Reviews,1957.
[8]CHEN Xiaorong,QIN Jin.Maximum entropy-based chinese word sense disambiguation [J].Computer Science,2005,32(5):174-176(in Chinese).[陈笑蓉,秦进.基于最大熵原理的汉语词义消歧[J].计算机科学,2005,32(5):174-176.]
[9]ZHANG Lei.Chinese POStagging study based on maximum entropy[D].Dalian:Dalian University of Technology,2008(in Chinese).[张磊.基于最大熵模型的汉语词性标注研究 [D].大连:大连理工大学,2008.]
[10]PENG Qiwei.Classification of emotional tendency of the Chinese text based on statistical methods[D].Taiyuan:Shanxi University,2007(in Chinese).[彭其伟.基于统计方法的中文文本情感倾向分类研究[D].太原:山西大学,2007.]
[11]ZAN Hongying,ZHANG Kunli,CHAI Yumei.The formal description of the modern Chinese adverb usage[C]//The8th Chinese Lexical Semantics Workshop Proceedings,The Hong Kong Polytechnic University,2007(in Chinese).[昝红英,张坤丽,柴玉梅.现代汉语副词用法的形式化描述 [C]//第八届汉语词汇语义学研讨会论文集,香港理工大学,2007.]
[12]ZAN Hongying,ZHANG Kunli,CHAI Yumei.Studies on the functional word knowledge base of modern Chinese[J].Journal of Chinese Information Processing,2007,21(5):107-111(in Chinese).[昝红英,张坤丽,柴玉梅.现代汉语虚词知识库的研究 [J].中文信息学报,2007,21(5):107-111.]
