希尔伯特黄改进算法在语音增强中的应用
2013-07-10李楠,邓舒
李 楠,邓 舒
(东北电力大学信息工程学院,吉林吉林132012)
0 引言
语音是人类最重要的交流工具,在语音通信、识别等领域,语音信号常常受到传输系统或周围环境的噪声影响而使听者无法识别出说话者的内容。目前,研究较多的语音消噪方法有谱减法、MMSE 谱估计法和小波方法等。谱减算法[1]在假设语音信号是短时平稳这一特性上提出,与实际语音特性有点不符,所以消噪后的结果不太理想,而且还会引入“音乐噪声”;MMSE 谱估计法[2]必须要对语音频谱进行统计估计,语音频谱的估计结果对最后的消噪结果有很大影响,而且算法计算量较大;小波方法[3-4]对语音去噪结果受到小波基的限制,不同小波基产生的消噪结果也不相同,算法缺乏通用性。
希尔伯特黄变换(HHT)克服传统方法上的不足,它是一种自适应时域分析方法,不需要选择基函数来对信号进行分解,可以根据信号局部的时变特征进行时频分解得到信号的瞬时频率,能够真实地描述信号的物理特征[5]。现有HHT 语音消噪算法主要是以结合阈值算法来进行语音去噪[5-6],但是针对不同语音信号,选择的阈值不同,不具有普遍性而且消噪结果并不令人满意。本文利用奇异值分解(SVD)算法来改善这一问题,奇异值分解方法是一种非线性滤波方法,对于处理非线性、非平稳信号具有良好的数值稳健性,本文提出一种基于希尔伯特黄和奇异值分解的语音消噪方法,该方法的消噪效果优于传统的方法。
1 希尔伯特黄变换
希尔伯特黄变换是一种分析非线性、非平稳信号的有效方法,这一方法提出了固有模态函数(IMF)的概念和经验筛选(EMD)的方法。固有模态函数是一种简单的振动模式,它是由经验模态分解得到的。IMF 必须满足以下两个条件:
①在整个信号长度上,一个IMF 的极值点和过零点数目必须相等或至多只相差一个。
②在任意时刻,由极大值点定义的上包络线与极小值点定义的下包络的平均值为零。
经验模态分解算法就是把信号分解成许多固有模态函数。具体步骤如下:
假设任意的信号s(t),首先求出信号的所有极大值点和极小值点,利用三次样条插值得到信号的上、下包络,求出上、下包络线的平均值,即为m1,然后得到s(t)与m1差值记为c1,即

如果得到的差值c1满足IMF 的两个条件,就认为它是第1 个IMF 分量,记为h1。如果c1不满足IMF的两个条件,把c1作为新的数据,重复上面步骤,直到差值满足IMF 的两个条件,就认为它为第1 个IMF分量。将原信号减去第1 个IMF 分量,即

式中,r1称为逼近分量,该过程为一次筛选。将r1视为新s(t),重复以上过程,就可以筛选出第2 个IMF分量h2,第3 个IMF 分量h3,…。筛选的终止条件是rn足够小或它是一个单调函数,最后得到解释式为

由此可知,信号是由多个单分量信号组成的,每一个IMF 分量反映了信号的特征尺度。通过EMD分解,把信号分解成不同的特征信号[6]。
2 奇异值分解算法
奇异值分解是一种非线性滤波,它把有用信号矩阵分解成一系列奇异值和奇异值矢量对应的时域子空间。首先,将带噪信号构造成hankel 矩阵,然后,通过对hankel 矩阵进行奇异值分解得到有用信号的奇异谱,通过奇异谱确定奇异阶数,这样就能比较直观地、自适应地对信号进行消噪。
假设带噪信号为X=[x1,x2,x3,x4,…,xN],构造成hankel 矩阵Dm
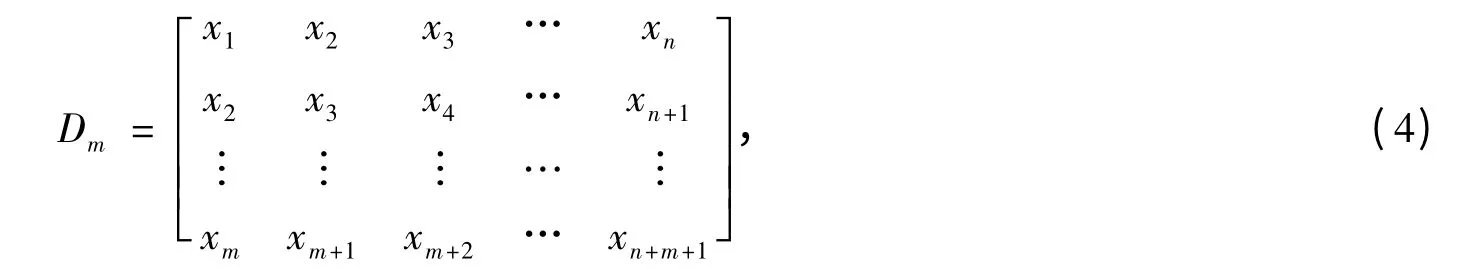
其中,1 <n <N,而且n + m +1 = N;Dm∈ℝm×n。
根据奇异值分解理论,对Dm进行奇异值分解,存在一个m × l 维矩阵U、一个l × l 维矩阵Λ 和一个n ×l 维矩阵V,Dm= UΛVT。对角矩阵Λ 的主对角线元素Λ = diag(λ1,λ2,λ3,…),其对角阵的元素是Dm的奇异值,且λ1≥λ2≥λ3≥…λn≥0。
由于信息熵是考察信号所包含的信息量的指标之一,引用了奇异熵的概念,

式中,k 为奇异熵阶次;△Ei为奇异熵在阶次i 处增量,
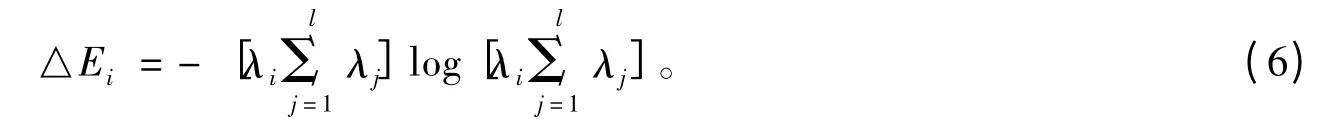
奇异熵对于信号信噪比变化十分敏感,对于未受噪声干扰的原始信号,在低阶次的奇异熵增量就达到饱和,它的奇异熵增值平稳在一个合适的常数,这就说明信号的信息量达到饱和。带噪信号的奇异熵增值随着阶次的增加而逐渐减少,这就说明信号的信息量受到噪声的影响会随着降噪阶次的升高而下降,但最终也会达到饱和。信号信噪比越低,奇异熵增量的递减的速度也就越快,达到饱和的速度也就越快。信号信噪比较高时,奇异熵增量值是缓慢减小,达到饱和度的速度比较慢。但对于同一信号,不管信噪比是高还是低,降噪饱和度阶次是一样的。所以,可以利用这一特点来准确的确定所需降噪的阶次[7-13]。
3 基于HHT-SVD 的语音消噪新算法
3.1 带噪语音信号模型
现实生活中的噪声多是以加性噪声为主,因此,只讨论语音信号被加性噪声污染的去噪模型

式中,y(t)是带噪的语音信号;x(t)是纯净的语音信号;n(t)是白噪声,白噪声的均值与时间无关,它的功率谱密度是一个常数的随机信号。
3.2 新算法的主要步骤及流程
该文根据EMD 分解得到语音信号的特性,提出基于HHT-SVD 的语音消噪算法。图1 为本文算法的流程图,算法步骤如下:
(Ⅰ)带噪语音信号通过EMD 分解,得到具有不同频率的单分量信号,即为IMF 分量。
(Ⅱ)通常前3 个IMF 分量为高频分量,含有大量噪声和语音清音部分,因此利用软阈值进行处理。
(Ⅲ)剩下IMF 分量认为是较低频分量,含有少量的噪声信号,进行相空间重构的奇异值分解处理。
(Ⅳ)对各个IMF 分量进行EMD 重构,得到消噪后的语音信号。
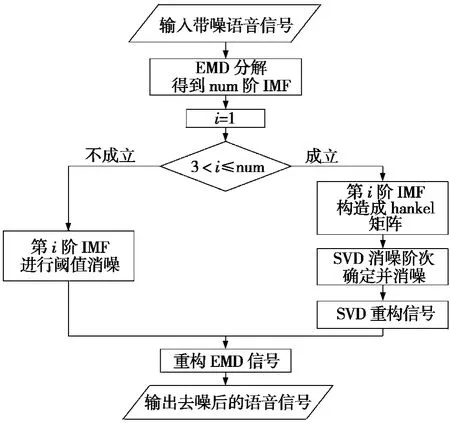
图1 HHT-SVD 的算法流程图
4 仿真结果与分析
4.1 实验1
实验1 所选的纯净语音为女声“one”,采样频率为10 kHz,16 bit 量化,采样点数为8 000。将这段语音信号叠加上N(0,σ2)的高斯白噪声。输入信噪比为-4 的带噪语音信号,如图2 所示。将纯净语音信号和带噪语音信号分别进行EMD分解后,得到各自的IMF 分量,如图3 所示。限于篇幅,图3 中只列出前8 个IMF 分量。经验模态分解算法可以把语音信号分解成各个频率不同的单分量信号。由图3 对比可知:高频分量信号中包含了大量的噪声和少量有用的语音信号,通过分解得到波形可以发现少量的有用语音其实是语音信号清音部分,它的波形类似于白噪声,频率高,能量小。如果把高频分量信号完全抑制会影响到语音信号的可懂性。
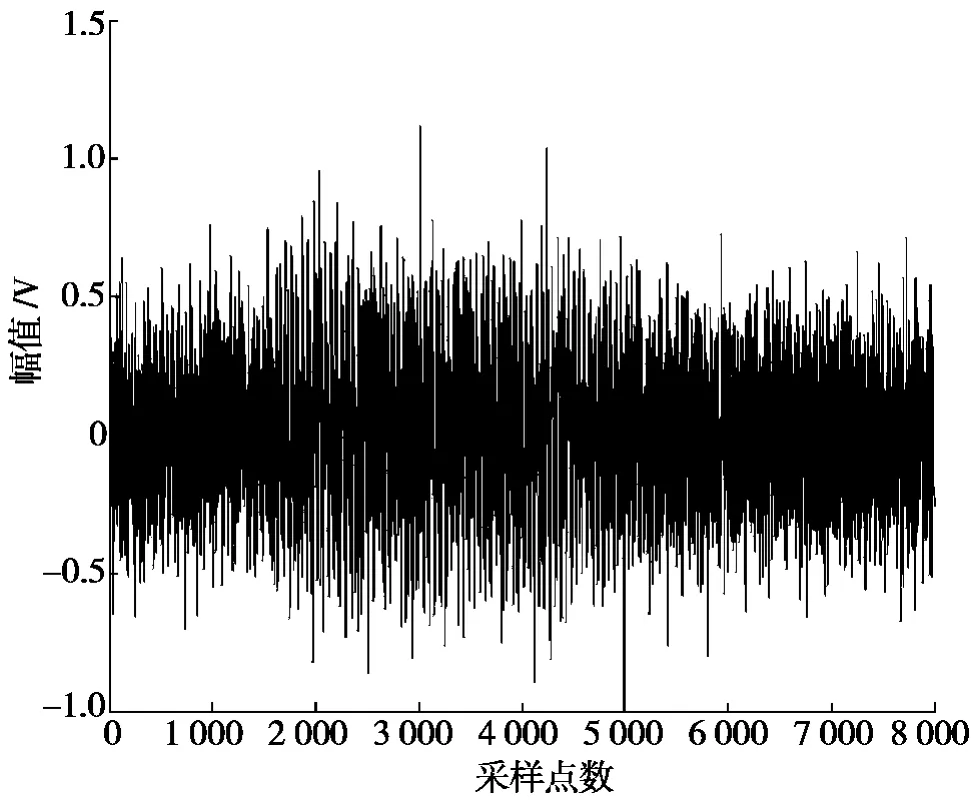
图2 输入信噪比为-4 的带噪语音信号
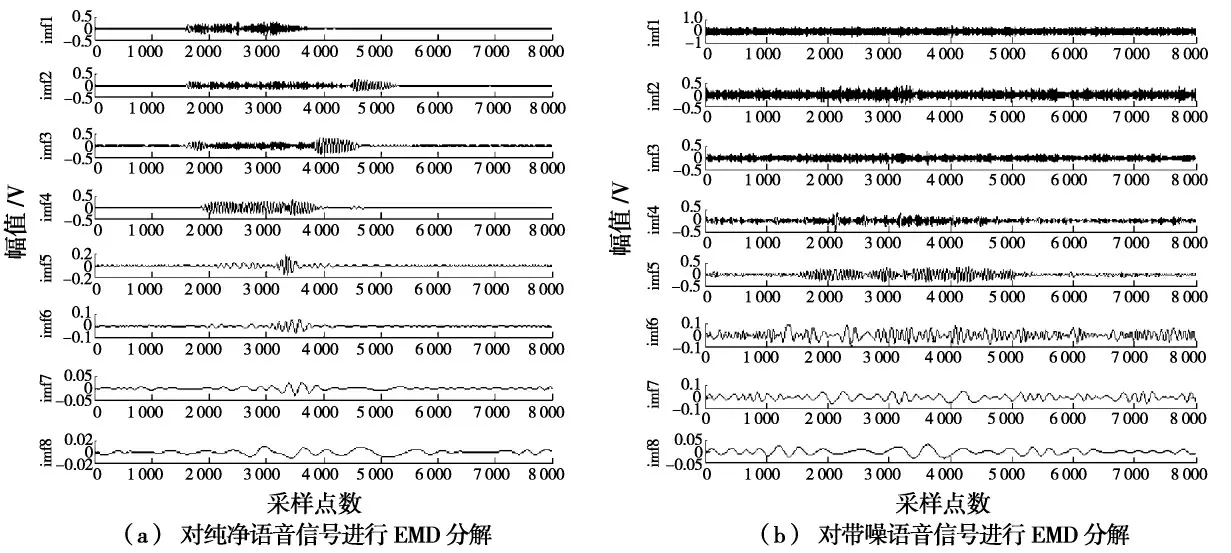
图3 纯语音信号和带噪语音信号的EMD 分解
EMD 分解得到的较低频部分含有大量的语音信号和少量的噪声含量,由于语音信号的浊音部分能量大多处于较低频段内,因此,EMD 的分解在较低频段内的语音信号是浊音信号,但是EMD 是根据信号自身特性进行自适应的分解,因此,分解出较低频段内频率相同的噪声含量。
利用HHT-SVD 进行语音消噪处理时,SVD 降噪阶次的确定是关键步骤,理论研究表明可以根据奇异熵的增量变化来确定SVD 的降噪阶数。图4 给出了各IMF 分量的奇异熵增量与降噪阶数的关系。由图4 可以看出:IMF1 ~IMF3 分量由于噪声含量过大,使得奇异熵增量最后不能趋于一个常数,不能很好的确定降噪阶数。所以本文针对IMF1 ~IMF3 利用软阈值进行处理。对于IMF4 ~IMF11 分量奇异熵增量最后都能趋于一个常数,因此,可以根据奇异熵增量确定降噪阶数,进行SVD 消噪。
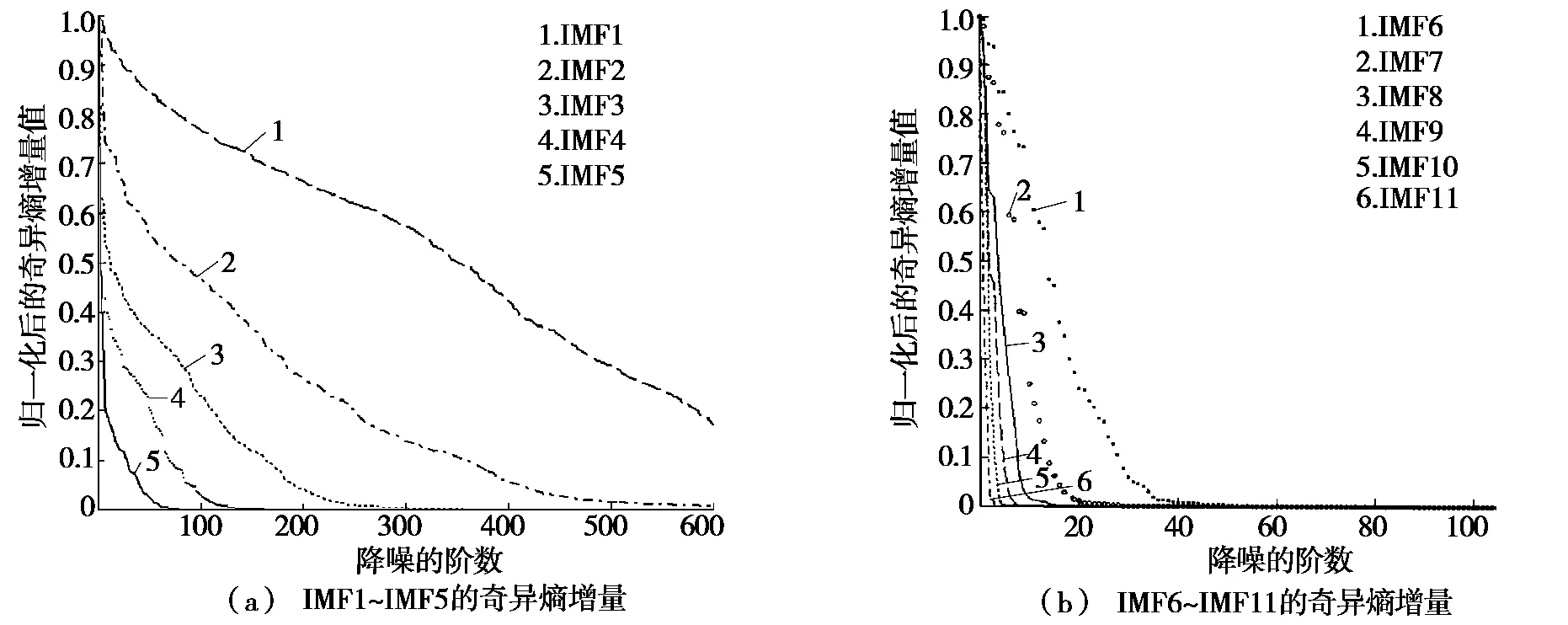
图4 输入信噪比为-4 各阶IMF 奇异熵增量
利用小波、传统HHT 及小波算法对带噪语音信号进行消噪,结果如图5 所示。仿真结果表明:传统的小波和HHT 方法不能大量的去除噪声,而且消噪后的语音信号可懂度也受到了影响。本文的方法不但能大量的去除噪声,而且还保留少量语音清音部分,提高语音的可懂度。

图5 输入信噪比为4 dB 的语音文本下本文方法与小波、传统HHT 方法的比较
改变输入噪声方差σ2,可以得到不同的输入信噪比的语音信号。不同算法的输入信噪比与输出信噪比的对比关系如表1 所示。在输入信噪比较高的情况下,利用HHT-SVD 算法消噪后得到的输出信噪比明显高于小波和传统HHT算法消噪后的信噪比。在输入信噪比较低的情况下,利用HHT-SVD 算法消噪的效果略高于小波和传统HHT 算法消噪的效果。因此,本文算法能够有效的去除噪声,而且去噪效果优于小波和传统HHT 算法。
4.2 实验2
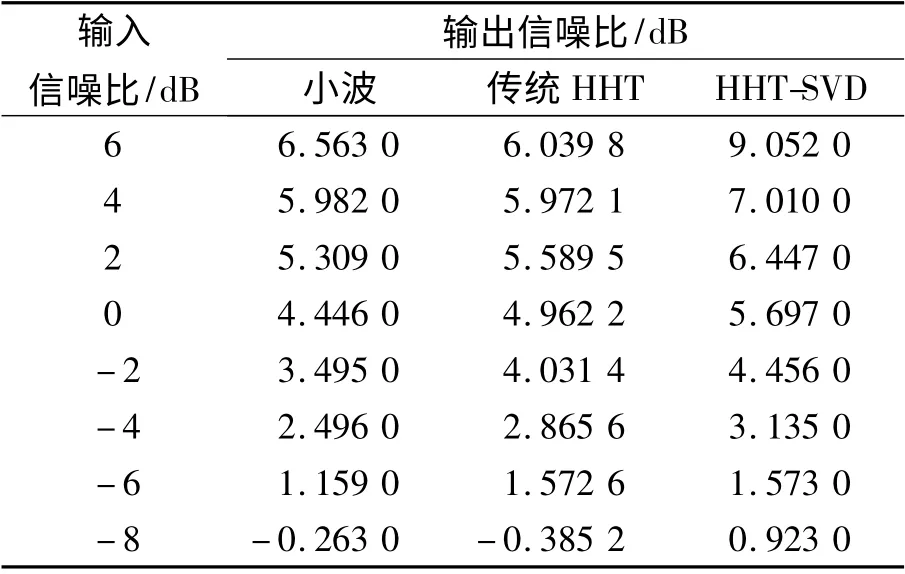
表1 几种算法的性能比较
实验2 所选语音为女声“你好”,采样频率为22 050 Hz,语音采样点数为55 130。该语音是在实际环境中用Windows 录音机录制的一段语音信号,这段语音中的噪声源由老旧风扇扇叶声和旧电脑的系统声音构成。对比结果如图6 所示,与小波方法和传统的HHT 方法相比,本文的方法也能够大量的去除实际的带噪语音信号里的背景噪声,而且没有降低语音的可懂度。
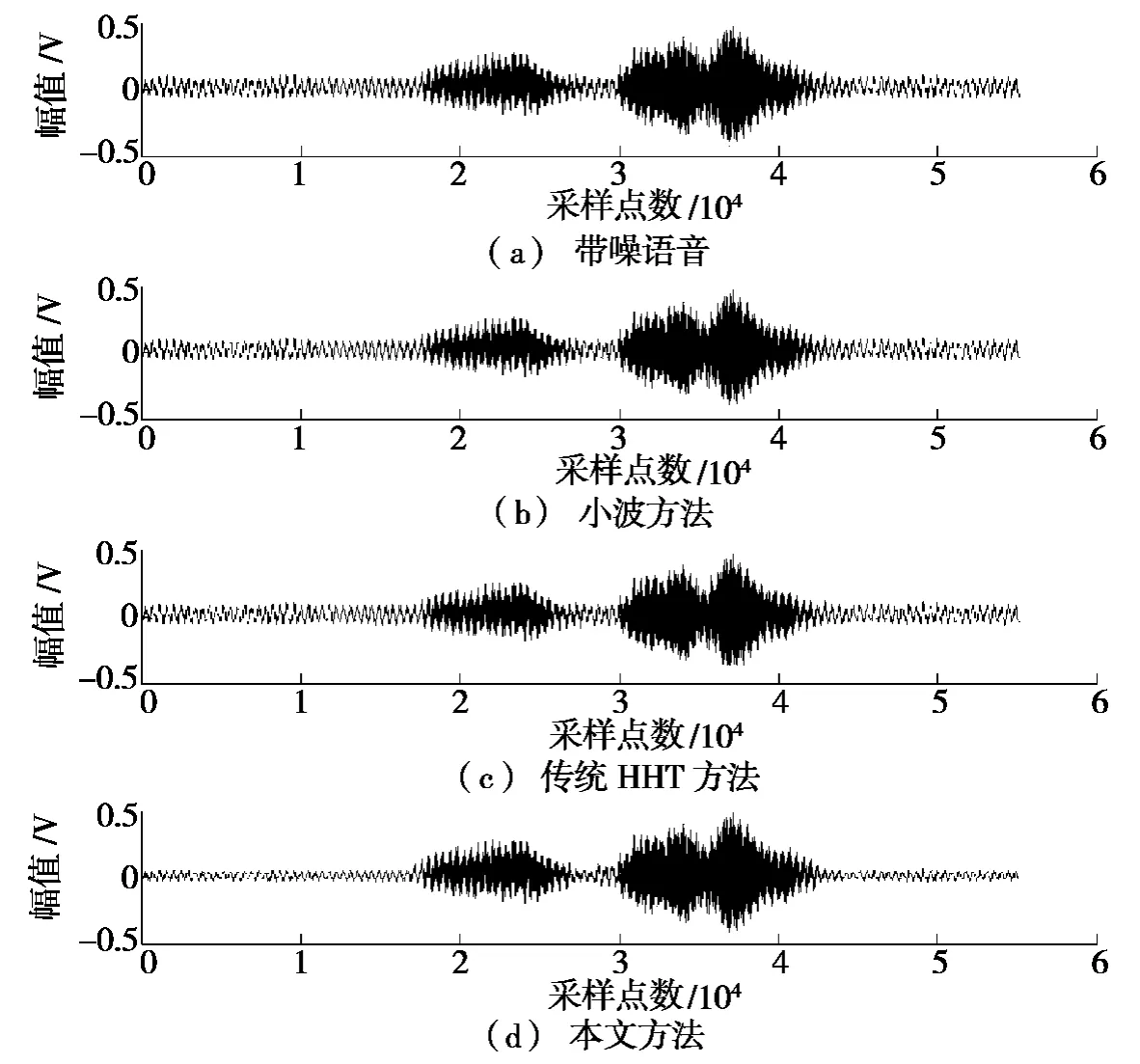
图6 实际带噪语音去噪算法对比
5 结束语
本文是将希尔伯特黄和奇异值分解算法相结合来对带噪语音信号进行消噪处理,针对语音信号不同频段特性,采用不同的消噪方法。高频段采用软阈值去噪,低频段利用奇异熵增量值确定消噪阶数后采用SVD方法去噪。仿真实验表明:两者结合消噪效果优于采用单一方法的去噪效果,输出信噪比得到明显提高,同时也改善了语音质量。
[1] Boll S F. Suppresion of Acoustic Noise in Speech Using Spectral Subtraction[J]. IEEE Trans Acoust Speech Signal Process,1979,27:113-120.
[2] Ephraim Y,Malah D.Speech Enhancement Using a Minimum Mean-square Error Short-time Spectral Amplitude Estimator[J].IEEE Trans Acoust Speech Signal Process,1984,32:1109-1121.
[3] 李野,吴亚锋,刘雪飞.基于感知小波变换的语音增强方法研究[J].计算机应用研究,2009,26(4):1313-1315.
[4] 刘雅琴,周炜.基于小波变换的说话人语音特征参数提取[J].河南科技大学学报:自然科学版,2005,26(4):44-46.
[5] 宋倩倩,于凤芹.基于Hilbert-Huang 变换和听觉掩蔽的语音增强算法[J].声学技术,2009,28(3):280-283.
[6] Zou X J,Li X Y,Zhang R. Speech Enhancement Based on Hilbert-huang Transform Theory[J]. Proceeding of the First International Multisymposiums on Computer and Computational Sciences,2006(4):2581-2586.
[7] Xin L R,Feng W D,Pu H.On the Application of SVD in Fault Diagnosis[J].Proceeding of IEEE International Conference on Susytems,Man and Emetics,2003(4):3763-3768.
[8] Norden E H,Zhang S,Steven R L,et al.The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Nonstationary Time Series Analysis[J].Proc R Soc Lond A,1998,454:903-995.
[9] 钟佑明,秦树人,汤宝平.Hilbert-Huang 变换的理论研究[J].振动与冲击,2002,21(4):13-17.
[10] 胡谋法,董文娟,王书宏,等.奇异值分解通滤波背景抑制和去噪[J].电子学报,2008,36(1):111-116.
[11] 王太勇,王正英,胥永刚,等.基于SVD 降的经验模式分解及其工程应用[J].振动与冲击,2005,24(4):96-98.
[12] 梁霖,徐光华,侯成刚.基于奇异值分解的连续小波消噪方法[J].西安交通大学学报,2004,38(9):904-908.
[13] 王艳,金太东,杜明娟,等.改进的小波变换阈值去噪方法[J].河南科技大学学报:自然科学版,2007,28(3):46-48.
