基于Web的DCI垂直搜索引擎的研究与设计
2013-07-03吴洁明冀单单韩云辉
吴洁明,冀单单,韩云辉
(北方工业大学 信息工程学院,北京 100144)
0 引 言
在互联网飞速发展的今天,互联网上的信息更是浩如烟海,据互联网数据中心于2010年的一则报道,2010年底全球数字信息总量将达到1.2ZB,预计到2020年这个数字将达到3.5ZB,其增长速度超过摩尔定律[1]。针对海量的数字信息,如何快速准确的获得有用的信息成为研究的重点。基于国际数字出版领域认可度较高的资源定位解析方案是美国出版者协会于1988年制定的数字对象唯一标识符DOI(Digital Object Identifier)标准,中国版权保护中心在深入研究国际现有的版权保护技术、相关的法规和标准后,结合数字资源出版服务领域的发展趋势,提出了数字作品版权唯一标识符(DCI),用于解决数字作品产业链中各个参与者的利益分享、技术创新和高效的维权机制[2]。目前,国内对于DCI的研究处于初级阶段,本文就是围绕这一问题,在Lucene开源技术、数据采集、信息抽取和索引搜索等基础上,设计实现用于解决互联网上海量DCI数据的垂直搜索引擎。
1 搜索引擎相关概述
1.1 垂直搜索引擎
根据数据收录范围不同,将搜索引擎分为通用搜索引擎和垂直搜索引擎。最常见的通用搜索引擎有:百度、Google和搜狗等。垂直搜索引擎是针对某些特定领域的专业搜索引擎,是搜索引擎的细分和延伸,是对某种专业信息的整合,是针对某一特定领域、某一特定人群或某一特定需求,提供有一定价值的信息和搜索服务,准确搜索出用户所需要的信息。垂直搜索引擎的特点就是“专、精、深”,且具有行业色彩[3]。由于垂直搜索引擎侧重自己独有专业信息的搜索,可以专注于自己的特长和核心技术,采用更有效的信息采集策略,保证信息技术的及时更新。因此在专业信息方面,垂直搜索引擎比通用搜索引擎有很明显的优势,常见的垂直搜索引擎有:汽车垂直搜索引擎、旅游垂直搜索引擎等。
1.2 Heritrix概述
Heritrix是用Java语言开发的开源网络爬虫框架,采取深度遍历网站的资源数据,将资源数据采集保存到本地,分析采集到的每一个有效的URL 地址,并提交HTTP 请求,从而获得相应的结果,最后生成本地文件和日志信息。Heritrix在抓取过程中可以用来获取完整的、精确的站点内容的复制,将抓取的内容保存到本地而不做任何修改,数据采集结构如图1所示,Heritrix的优点在于它的可扩展性和灵活性。
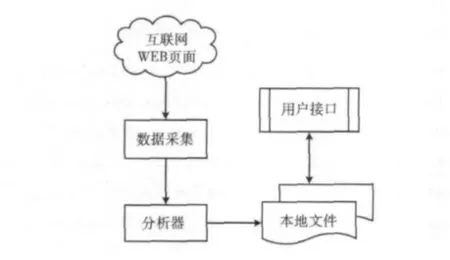
图1 数据采集结构
1.3 Lucene概述
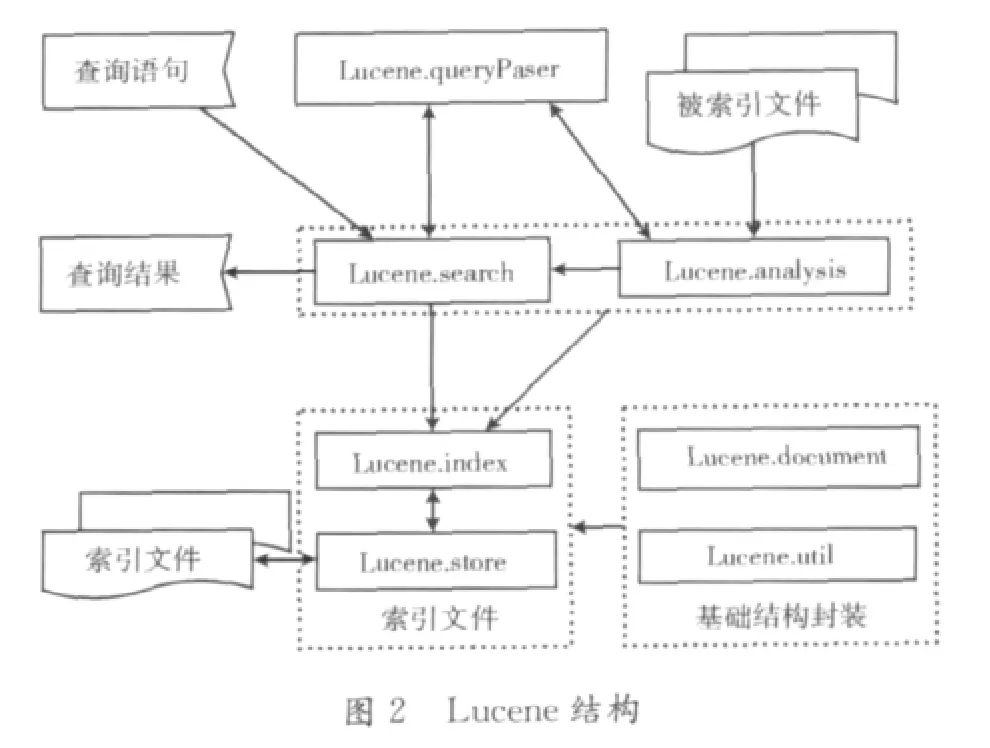
Lucene是跨平台的用Java语言开发的一个开放源码的全文检索工具包。Lucene最初由Doug Cutting编写,目的是为软件开发人员提供简单易用的应用程序接口,通过重载Searcher类、Analyzer类以及增加爬虫系统等对象实现一个完整的搜索引擎系统[4]。关于Lucene的项目主要有:邮件列表管理系统Eyebrows中的检索和归档、基于Web的论坛系统Jive和Eclipse的全文检索部分等。Lucene的有点主要有:索引文件独立于应用系统,采用倒排索引技术建立索引文件,提供丰富强大的API接口,如提供布尔查询、模糊查询和分组查询等,其结构如图2所示。
2 搜索引擎设计
2.1 DCI搜索引擎结构
基于Web的DCI垂直搜索引擎结构如图3所示,采用的技术主要包括:数据采集、网页信息抽取、索引器、检索器等。
如图3所示,DCI搜索引擎核心模块包括:数据采集、网页信息抽取、索引器和检索器等。
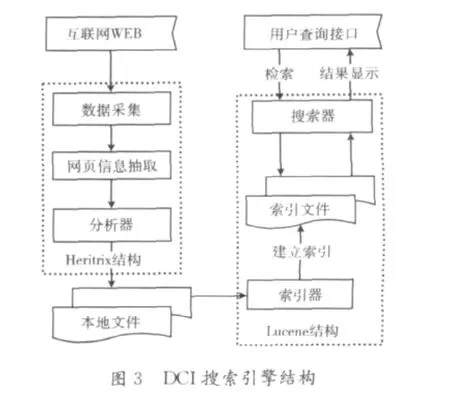
(1)数据采集:采用网络爬虫技术进行数据的采集,采用广度优先算法,采集处理URL链接,采集完的数据保存在本地文件中;
(2)网页信息抽取:遍历所爬取到本地的网页文件,先进行HTML文件的标记进行规范化处理,再读取树节点的纯文本信息。
(3)索引器:将文本信息进行分词处理,并采用倒排索引技术建立索引,并将生成的索引文件保存到本地;
(4)检索器:对于用户输入的查询关键词在索引文件中进行检索,将检索结果按照排序算法返回给用户。
2.2 Hits算法及数据采集
Hits 算 法(hyperlink-induced topic search )是由Kleinberg提出的基于超链接关系分析的网页排名算法。提供了用于对网页质量进行评估的两种类型:权威型(authority)和目录型(hub)。权威型网页是指对于特定的搜索时,网页提供最好的相关信息。目录型网页是指提供很多指向其他权威型网页的超链接。Hits算法适用于处理页面数量较少的情况,如网页数量在几万以内是,速度较快,其针对的只是特定查询主题的互联网子图,没有考虑网页的内容,当一个页面里出现多个主题时会处理主题漂移现象。Hits算法的改进可以基于内容和超链接的分析相结合的主题相关度上分析处理,如对URL地址信息、锚文本信息、祖先网页信息(网页链接分析和内容分析)、页面的深度(网页超链接)等做为权重信息。
本文的数据采集采用的是基于广度优先的数据采集过程,具体描述如下:
(1)在线程池中,选择一个预定的URL;
(2)从选择的URL 网址获取文件内容;
(3)分析、归档下载到的内容,如果包函想要找的文字信息,则写入磁盘镜像目录;
(4)从分析到的内容里面根据策略选择URL,加入预定队列;
(5)标记已经处理过的URL,己经处理过的URL 则不再处理;
(6)从第(1)步继续进行,直到所有的URL 处理结束,抓取工作结束。
数据采集处理器链处理流程如图4所示。
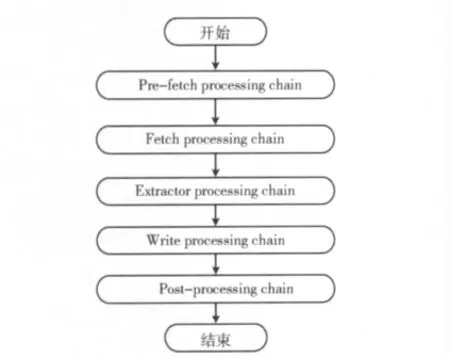
图4 数据采集处理器链
(1)预取链:做准备工作,对抓取时的一些先决条件的判断;
(2)提取链:获得资源,解析网络传输协议;
(3)抽取链:用于解析当前获取的服务器返回的内容;(4)写链:用于将抓取到的信息写入磁盘;
(5)提交链:将解析出来的URL 有条件地加入到待处理队列中。
2.3 网页信息抽取
从内容上一个网页一般包括导航信息、正文信息、广告信息、版权信息和相关链接等,如果直接对整个网页保存并建立索引,会降低检索结果的精确度,为了使网页的信息尽可能全面准确,本文先对网页的所有部分的文本进行全部抽取,然后重点分析处理正文信息。网页信息包括结构化和非结构化的信息,因此需要对其进行预处理,将其转化为数据结构清晰、语义明确的格式。本文采用一种基于统计方法的信息抽取,这种方法适应于网页中的正文信息放在table中,采用如下两步:

(1)网页规范化处理。根据网页中规范的HTML 标记,可以把网页表示成一棵树型结构,网页规范化处理主要内容如下:网页中“<”和“>”只能用于表示标记,其他非标记的地方出现“<”和“>”时,全部用<和&gt替换;对所有的标记都保证其开始和结束相互配对出现;将标记中的属性值放在一对引号中,如<a href="www.ncut.edu.cn"></a>的形式;多个标记之间不能交叉嵌套[5]。
(2)获取节点信息。经过规范化处理的网页,就可以表示成一个树型结构,从属性结果中获取包含正文信息的节点。找到HTML 文档中包含所有的table节点,遍历每个节点并去除标记,得到不含有任何标记的纯文本,并将得到的纯文本信息保存在本地磁盘中,网页文本信息抽取流程图如图5所示。
2.4 倒排索引
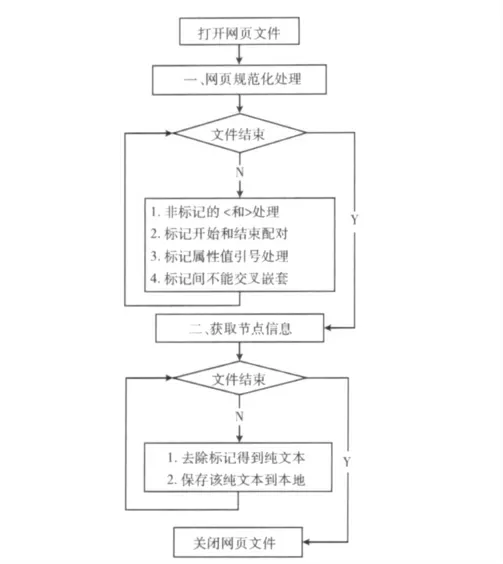
图5 网页信息抽取流程
在Lucene倒排索引中,项(Term)是最小的索引单位,它直接代表了一个关键词以及其在文件中的出现位置和出现次数等信息,若干的项组成域(Field),域是一个关联的元组,域是由一个域名和一个域值组成,若干的域组成文档(Document),文档是提取了某个文件中的所有信息之后的结果,若干的文档组成段(Segment),内存中的段数量达到指定数量时将会合并成一个段,若干段组成子索引(Index),子索引可以组合为索引,也可以合并为一个新的包含了所有合并项的内部元素的子索引。在Lucene中采用段索引的生成方式,合并阈值影响着内存与硬盘中索引文件的个数。每添加一个Document将生成一段索引被内存持有,当段索引的个数超过合并阈值时,就会通过merge(合并)的过程将一段索引合并为段索引[6]。
例如有文本1和文本2:
文本1:research and design of vertical search engine.
文本2:research and implement of search engine.
首先对文本1和文本2提取关键词,按照一般索引得到结果如表1所示,按照Lucene倒排索引得到结果如表2所示。由表1和表2可知,一般索引关键词数量随着文本内容成线性关系增长,而倒排索引当出现相同关键词时,只需要修改相应记录信息,节省索引文件的存储空间并提高检索效率[7]。Lucene建立索引文件过程中,对于表2中的关键词,在文本中出现位置和次数,分别保存在如词典文件,位置文件和频率文件中。其中词典文件中有指向位置和频率文件的指针。
2.5 建立索引
将分词后的DCI数据采用倒排索引技术建立索引可分为如下4步:
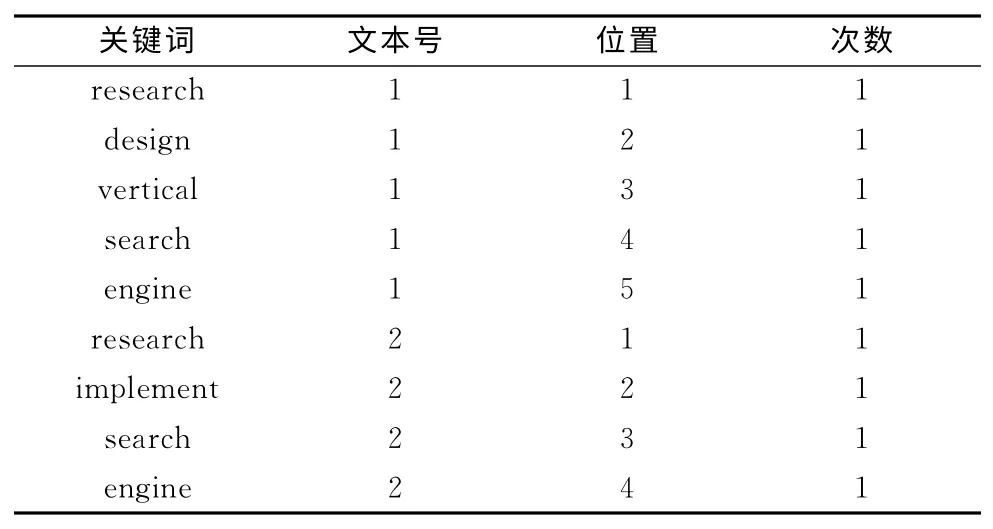
表1 一般索引
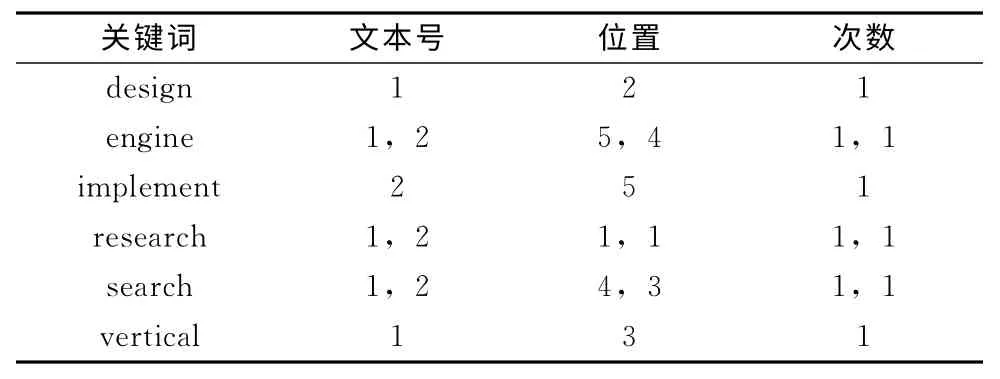
表2 倒排索引
(1)从数据库中获取DCI数据,针对一条数据进行解析,取出每个字段和值,按照数据库字段对应Lucene域的方式生成Field对象;
(2)将生成的Field添加到Document中生成Document对象;
(3)通过IndexWriter类的addDocument方法建立索引,在建立索引时,Lucene会对数据进行分析处理;
(4)直到没有要更新的数据,则索引创建完成并关闭索引器。当大量数据建索引时,在向磁盘写入索引文件时会出现瓶颈,在Lucene内存中有一块缓冲区来解决此问题。

2.6 搜索模块
检索模块的系统结构如图6所示,主要进行以下处理:关键词预处理、同义词扩展、查询优化和Lucene索引检索等[8]。首先,查询预处理模块对查询请求进行筛选和过滤并分割出关键词,去除没有意义的字符,如“的”,“哈”,“哎”等干扰字符,将查询请求处理成最原始的,最便于查询处理的状态;接着,对关键词进行同义词查询扩展,通常用户给定的查询请求常被解析成独立的实词,从语义词库中获取相应的同义词组,比如关键词:价格,可以扩展成:价值、售价等,这样可以在更广泛的概念上检索出与用户请求相关的信息;然后,将关键词分派给查询优化模块进行逻辑关系分析,将搜索词传递给搜索引擎模块;最后,结合Lucene搜索提供的API实现搜索。
Lucene提供实现搜索API包括:QueryParser将用户输入的查询关键词分析处理后,生成查询Query对象;IndexSearcher对Query对象进行搜索后结果返回在Hits集里;Lucene的相关度排序算法将搜索结果排序显示给用户。
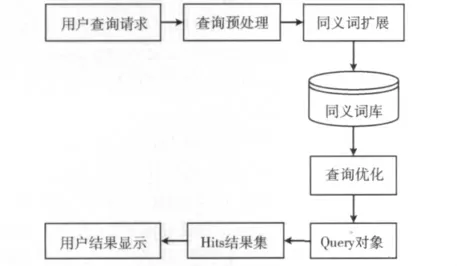
图6 检索模块结构

2.7 相关度排序算法及改进
在使用关键词查询的时候,一般会得到大量符合条件的结果,用户一般只会关注结果排在前面的几页,因此对于搜索结果排序变得尤其重要,本文是基于Lucene的垂直搜索引擎,Lucene 是结合了布尔模型和向量空间模型,Lucene原始的排序公式如下
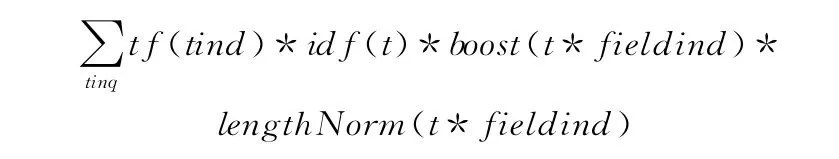
通过这个评分公式得到的是原始分数,但是由Hits结果集返回的关于某文档的评分却不是其原始得分,而是当评分最高得分的文档如果超过了1.0,那么将所有评分都会以这个此评分为标准进行计算,因此所有Hits对象的得分都只能小于或等于1.0[9]。Lucene排序公式主要考虑了检索词的词频、反转文档概率和文档长度,但是忽略了检索词之间关联关系,本文提出如下改进算法[10]。

3 实验结果与分析
基于本文的理论分析,本文系统实现是用Java语言编写,搜索界面用JSP页面显示,索引文件采用Lucene的本地文件,相应的硬件环境是:Intel Core Due CPU i5 2.5GHz和2GB内存;软件环境是:JDK1.6、Tomcat6.0、Myeclipse6.5和WinowsXP等。基于25万条DCI数据建立索引,并提供相应的检索服务,并以下两方面对DCI搜索引擎实验分析:
(1)基于Web的DCI垂直搜索引擎与传统的基于数据库的搜索引擎的比较如表3所示。由表3可知,该搜索引擎在数据源、分词算法、索引和查询分析等都比传统的搜索引擎有很大的改进和提高。
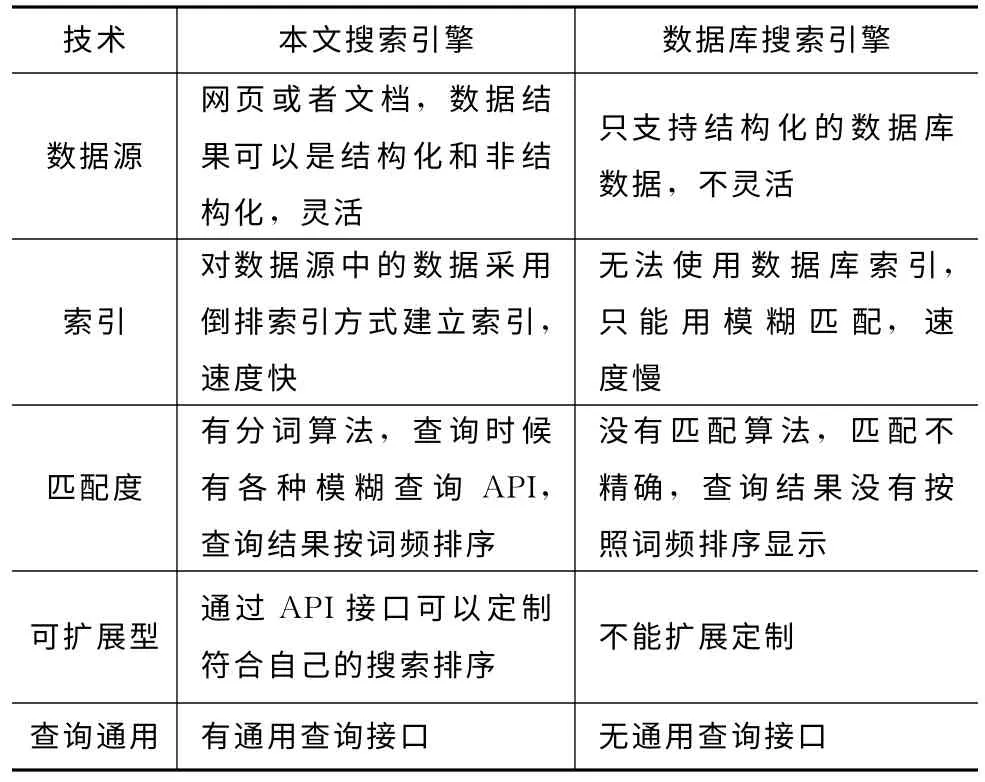
表3 搜索引擎比较表
(2)在网页信息抽取方面,实验选择一下四个网站进行抽取,如表4所示,本文的抽取方法表现了较好的准确率,基本在95%左右。
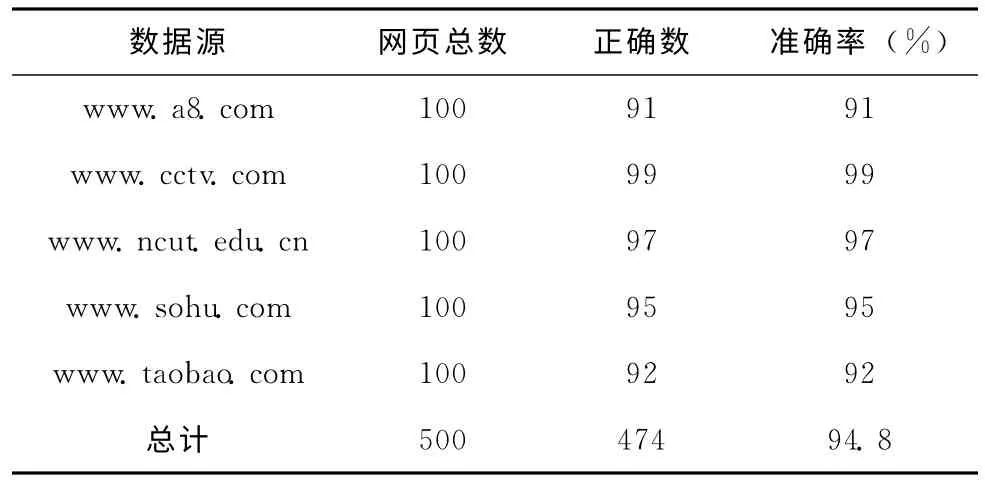
表4 网页信息抽取结果
(3)在索引器搜索方面,基于25万条DCI数据进行搜索,如表5所示,本搜索引擎确实实现了DCI数据的快速搜索功能,关键词检索响应时间全部在100ms之内完成。
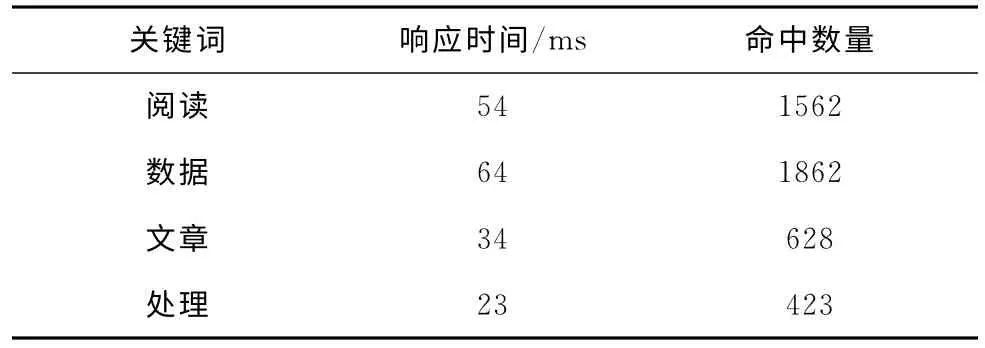
表5 关键词检索响应结果
4 结束语
垂直搜索引擎以其更准确、更有效的检索而越来越受到用户的重视,在深入学习研究Lucene和Heritrix等开源技术之后,本文先对DCI搜索引擎的整体结构进行了分析,接着对各个功能技术进行了分析与设计。在网页信息抽取方面本文提出的基于统计的抽取技术,在很大程度上提高的抽取的准确度,还提出分析了Lucene的相关度排序算法并对其进行改进,最终设计了DCI垂直搜索引擎,并且实现DCI海量数据的快速准确搜索。同时,本系统还有一些有待改进的地方,比如以后可以进一步研究分布式技术来提高搜索效率等。
[1]LI Xuelian.IDC:in 2020the total amount of the explosion of digital information will reach 35ZB[EB/OL].[2010-05-10].http://tech.hexun.com/2010-05-10/123653027.html(in Chinese).[李雪莲.IDC:数字信息大爆炸2020年总量将达35ZB[EB/OL].[2010-05-10].http://tech.hexun.com/2010-05-10/123653027.html.]
[2]Huelmarc.DCI baidu baike[EB/OL].[2011-12-02].http://baike.baidu.com/view/1733861.htm(in Chinese).[Huelmarc.DCI百度百科[EB/OL].[2011-12-02].http://baike.baidu.com/view/1733861.htm.]
[3]FU Qiang.Lucene research and implementation on the vertical search engine application to university library books[J].Journal of Taiyuan Normal University,2011,10(4):103-107(in Chinese).[付强.基于Lucene的高效图书垂直搜索引擎的研究与实现[J].太原师范学院学报,2011,10(4):103-107.]
[4]CUI Xiaobo.SOA overview[EB/OL].[2006-01-05].http://blog.csdn.net/byfq/article/details/2411442(in Chinese).[崔晓波.SOA 概 览[EB/OL].[2006-01-05].http://blog.csdn.net/byfq/article/details/2411442.]
[5]SUN Chengjie,GUAN Yi.A statistical approach for content extraction from web page[J].Journal of Chinese Information Processing,2004,18(5):17-22(in Chinese).[孙承杰,关毅.基于统计的网页正文信息抽取方法的研究[J].中文信息学报,2004,18(5):17-22.]
[6]QIU Zhe,FU Taotao.Developing its own search engine--Lucene 2.0+Heritrix[M].Beijing:People’s Posts and Telecommunications Press,2007(in Chinese).[邱哲,符滔滔.开发自己的搜索引擎—Lucene 2.0+Heritrix[M].北京:人民邮电出版社,2007.]
[7]ZHAO Ke,LU Peng,LI Yongqiang.Design and implementation of search engine based on Lucene[J].Computer Engineering,2011,37(16):39-41(in Chinese).[赵珂,逯鹏,李永强.基于Lucene的搜索引擎的设计与实现[J].计算机工程,2011,37(16):39-41.]
[8]JIANG Yifeng,WANG Hua,ZHANG Yuhong,et al.Design and implementation of semantic search engine based on Lucene[J].Computer Engineering and Design,2008,29(20):5336-5341(in Chinese).[蒋一峰,王华,张玉红,等.基于Lucene的语义检索系统的设计和实现[J].计算机工程与设计,2008,29(20):5336-5341.]
[9]Otis Gospodnetic,Erik Hatcher.Lucene IN ACTION[M].TAN Hong,transl.Beijing:Publishing House of Electronics Industry,2007(in Chinese).[Otis Gospodnetic,Erik Hatcher.Lucene IN ACTION 中文版[M].谭鸿,译.北京:电子工业出版社,2007.]
[10]WANG huan,SUN Zhirui.Research of semantic retrieval system based on domain-ontology and Lucene[J].Journal of Computer Application,2010,30(6):1555-1660(in Chinese).[王欢,孙瑞志.基于领域本体和Lucene的语义检索系统研究[J].计算机应用,2010,30(6):1555-1660.]
