维吾尔语评论文本主题抽取研究
2013-04-23田生伟
禹 龙, 田生伟, 黄 俊
(1. 新疆大学 网络中心, 新疆 乌鲁木齐 830046; 2. 新疆大学 软件学院, 新疆 乌鲁木齐, 830008;3. 新疆大学 信息科学与工程学院, 新疆 乌鲁木齐 830046 )
1 引言
意见挖掘是自然语言处理研究领域中的热点问题。本文关注意见挖掘中的关键任务之一: 主题抽取。
在评论文本中, 主题存在显式和隐式两种形式。目前, 大部分主题抽取相关的工作关注的是显式主题抽取[1-16], 隐式主题获取方面的工作很少[17-18]。
从研究的粒度来看, 已有的主题抽取研究主要集中于篇章级[1-2](Document level)、句子级(Sentence level)[3-5]或特征级 (Aspect level)[6-7]。一个意见陈述可以是一个短语、子句或整个句子。因此, 篇章级和句子级的主题抽取是粗轮廓的; 特征级主题抽取无法抽取隐式主题。
在汉语和英语等大语种上, 主题抽取的研究已取得了一系列成果。但诸如维吾尔语等少数民族语言, 研究甚少, 需引起研究者们的重视。
针对以上问题, 本文提出了面向维吾尔语评论文本的主题抽取方法。该方法从意见陈述的角度抽取(显式陈述)或推断(隐式陈述)主题词。同时考虑到同一主题词在不同的语境中可能分属于不同的上位概念 (如“屏幕”, 可能是手机的屏幕, 也可能是电脑的屏幕), 为使主题抽取结果更具参考价值, 为每个意见陈述建立了意见陈述—主题四元组
本文余下部分组织如下: 第2节介绍主题抽取的国内外研究现状并提出本文的研究方法; 第3节为相关知识介绍; 第4节详细介绍主题抽取过程和相关算法; 第5节为实验和结果分析; 最后是本文的总结及展望。
2 相关工作
2.1 显式主题抽取
由于监督方法需要人工构建大型有标记的数据集合或相关领域知识, 代价十分昂贵。同时, 监督的学习方法对标注数据的依赖性很强, 可移植性差。因此, 大量主题抽取的研究工作主要采用无监督或半监督的方法。
一种无监督的思想是通过发现频繁的名词术语和可能的依赖关系, 利用关联规则挖掘实现主题的抽取[1, 8-9]。该方法能够有效地提取出意见文本中频繁的名词性主题词, 但对非频繁的主题词的识别效果欠佳。此外, 意见陈述中的主题词并非都是名词性词语, 还包含如动词或其他词性的词语。
LDA (Latent Dirichlet Allocation, LDA)模型及其改进模型近年来被广泛的应用于意见挖掘的主题抽取任务中[2,5, 10-12]。Titov 等[2]采用多粒度的主题模型抽取网络评论中的篇章级全局主题和滑动窗口内的局部主题。但该方法的粒度较粗, 同时也未建立全局主题和局部主题之间的关系。为更好满足意见挖掘领域的主题抽取需求, Jo等[5]提出了句子级的LDA (Sentence-LDA), 假设一个句子中的所有词都由同一个主题词生成。而实际上, 一个句子中可能存在一个以上的主题词。Mukherjee等[12]在LDA模型中引入了种子集合(Seed Sets), 提出的SAS模型 (Seeded Aspect and Sentiment Model, SAS) 和加入了最大熵 (Maximum Entropy) 组件的ME-SAS模型, 该方法同时对主题词进行了聚类。但是, 基于LDA主题模型的主题抽取方法粒度都较粗, 提取出的主题词也无法对应其意见陈述。本文改进的LDA主题模型: GLR-Cascaded LDA模型用于抽取全局主题和局部主题以及建立全局主题和局部主题的对应关系, 并对应到意见文本的每个意见陈述中。
基于传播和自举学习的方法则是半监督的思想, 它需要人工提供一些种子信息。Qiu等[13]和Li等[14]通过深入分析主题词和意见词的语法关系, 采用Bootstrapping算法对主题词和意见词进行双向扩充。该方法能够识别非频繁的主题词和非名词性主题词, 但其提取效果的好坏完全取决于句法依赖性分析结果。而来源于网民的网络评论书写很随意, 不拘泥于语法规则, 给句法依赖性分析增加了难度。因此, 该方法不适用于句法分析器性能还不够优越的维吾尔语等少数民族小语种。Zhu等[15]首先提取名词、动词、形容词、副词以及词频较高的多词词项 (multiword terms) 作为候选的主题相关词项, 然后采用SAB (Single-Aspect Bootstrapping) 算法对候选相关词项进行扩充, 得到主题相关词项集合ARTs, 再采用MAB (Multi-Aspect Bootstrapping) 算法得到主题词项集合。该方法不需要深入的句法分析, 只需简单的词法分析, 因此对基础研究资源相对较弱的维吾尔语同样适用。但是该方法提取的主题词是粗颗粒度的, 抽取的主题词无法与其对应的意见陈述建立一一对应关系。
在显式主题抽取任务中, Tian等[16]的工作与本文方法最为接近。为提高显式主题抽取的精度, 本文在建立模式时不仅考虑了词和词性信息, 还结合了维吾尔语的词缀、词干特点, 并在每个意见陈述的候选主题精炼过程中考虑了该陈述的全局主题和局部主题的影响。同时, 针对每个意见陈述, 建立主题词—意见词关系, 用于隐式主题的抽取。
2.2 隐式主题抽取
目前, 隐式主题抽取的相关研究工作不多, Su等[17]提出构建一个意见词和相应主题词的关联集合, 用以通过给定的意见词推断主题词, 而主题词和意见词的相关性通过共现信息获得。他们工作的主要贡献在于通过迭代地在主题词和意见词上应用相互加强聚类算法得到主题词簇和意见词簇, 因此, 单个主题词和意见词的关联可扩展为簇间的关联。仇光等[18]扩展了该方法, 在建立普通词与主题词之间的关联时, 不仅考虑了意见词, 同时也考虑了其他非意见词。本文提出的隐式主题推断算法, 不仅考虑了当前意见陈述中的意见词, 还同时考虑了与前一陈述主题的关系、当前陈述的局部主题和全局主题。算法介绍详见第4.3节。
3 相关知识介绍
3.1 本文相关术语介绍
定义1意见陈述(Opinion Claim, OC): 意见持有者针对某主题表达了具有情感的意见表述。
定义2全局主题(Global Topic, GT): 篇章级主题。一般为领域或实体等上位概念的词语。
定义3局部主题(Local Topic, LT ): 段落级主题。可能为实体(上位概念)或实体的属性(下位概念)。
定义4当前主题(Current Topic, CT): OC的直接主题。一般是下位概念。
定义5显式陈述(Explicit Claim, EC): 包含具体表示主题的词汇或短语的OC。
定义6隐式陈述(Implicit Claim, IC): 不包含具体表示主题的词汇或短语的OC。
定义7意见陈述—主题四元组(Opinion Claim- Topic Quadruple, OCTQ): OCTQ表示为:
定义8意见词 (Opinion Words, OW): OC中能体现对主题持何种态度的词汇或短语。
(再来谈谈笔记本的性能。处理速度非常快, 散热也不错。就是充一次电用不到一个小时, 有点受不了。)
3.2 全局主题和局部主题的关系
全局主题一般为领域词或实体等上位概念, 局部主题分为局部上层主题和局部下层主题。局部上层主题对应于全局主题或与全局主题相关的上位概念; 局部下层主题对应于当前主题或与当前主题相关的下位概念。因此, 若局部主题为局部上层主题, 则局部主题和全局主题为相等或相关关系; 若局部主题为局部下层主题, 则局部主题和全局主题为从属关系。
3.3 隐式主题的表现形式
在隐式陈述中, 隐式主题的表现形式有如下三种:
(1) 隐式陈述的主题隐藏在邻近的上下文中。又分为两种情况:
a. 主题出现在前文的客观表述中, 未出现在当前意见陈述的范围内。
b. 两个意见陈述共用一个主题且该主题只在某一个意见陈述控制范围, 则另一个意见陈述的主题表现为隐式主题。
(2) 隐式主题是显式主题的更确切表达。如 “吃起来香酥可口.” 表面上“吃起来”是该意见陈述的主题, 但“味道”才是更确切的主题。
(3) 主题词完全隐藏。这种情况的隐式主题可通过意见词确定其当前主题。例如“真的很贵啊!”, “贵”很容易就知道在说“价格”。
3.4 隐式陈述主题与前一陈述主题的关系
隐式陈述主题的一个重要特征, 是它与前一陈述主题有密切的关联性。主要有以下四种情况。
(1) 隐式陈述的主题即为前一陈述主题或其同义表述;
(2) 隐式陈述的主题是前一陈述主题的上位概念或下位概念;
(3) 隐式陈述的主题是前一陈述主题的衍生主题;
(4) 隐式陈述的主题是前一陈述主题的相关主题。
3.5 维吾尔语相关语法特征
3.5.1 维吾尔语词缀与主观评价形式

3.5.2 维吾尔语时范畴与主观性
时, 即是与语言的时间性密切相关的一个语法范畴。我们往往认为它是客观的。但是看似客观的“时”, 在维吾尔语中其实蕴含着丰富的主观性。维吾尔语“时”的主观性主要体现在动词的“时”范畴上。当时间形式的范畴意义和起具体化、确切化作用的上下文不一致的时候, 往往会较明显地体现出说话人对所说内容的主观情态意义, 表现出较强的主观性。这在维吾尔语中主要体现在:
(1) 过去时形式表达非过去时的意义;
(2) 非过去时形式表达过去时的意义。例如,

汉语: 王昭君是一个美丽的弱女子,但是她的胸怀、气度和见识不亚于张骞和班超。
此外, 维吾尔语名词的格和名词词尾, 形容词词尾, 动词词尾都有明显的语法特征。

4 主题抽取算法
主题抽取的过程如图1 所示。主题抽取最终目标是为每个意见陈述建立意见陈述—主题四元组

图1 主题抽取过程
4.1 局部主题和全局主题抽取及“全局—局部主题”关系建立
4.1.1 GLR-Cascaded LDA模型生成过程

图2 GLR-Cascaded LDA模型
GLR-Cascaded LDA模型框图如图2所示, 它是层级的LDA模型。该模型的第一级是段落级的LDA模型, 用于抽取局部主题, 抽取结果作为第二级的可观察变量。第二级是改进的LDA模型, 同时采样文档中的词语和该词语所在段落的局部主题, 抽取全局主题并建立“全局—局部主题”关系。
GLR-Cascaded LDA模型是层级的LDA 模型。
第一级生成过程如下:
对局部主题采样:
φkl~Dir(β);
对语料中的第p个段落p∈[1 ,P]
采样局部概率主题分布:
θp~Dir(α)
采样段落长度:
Qp~Poiss(ξ)
对段落p中的第q个单词q∈[1 ,Qp]
选择局部主题zlp,q~Mult(θp)
生成一个单词wp,q~Mult(φzlp,q)
第二级生成过程如下:
对全局主题采样:
ψkg~Dir(ε);
对语料中的第m个文档m∈[1 ,M]
采样全局主题概率分布:
μm~Dir(γ)
采样文档长度:
Nm~Poiss(τ)
对文档m中的第n个单词n∈[1 ,Nm]
选择全局主题zgm,n~Mult(μm)
生成一个单词wm,n~Mult(φzgm,n)
对全局—局部关系采样:
φzg,zl~Mult(δ)
对语料中的第m个文档m∈[1 ,M]
采样文档中局部主题数量:
C~Poiss(σ)
选择全局主题zgm,n和局部主题zlm,c
生成一个全局—局部关系:
R~Mult(φzg m,n,zl m,c)
4.1.2 GLR-Cascaded LDA模型求解
为得到第一级的θ,φ和第二级的ψ,φ,μ分布, 主要有三种方法: 变分贝叶斯推断((Variational Bayesian Inference, VB), 期望传播(Expectation-Propagation, EP)和Gibbs采样。本文采用Gibbs采样。根据式(1)计算出的概率, 对每个文档中的每个词项的主题词的更新是基于Gibbs采样的第一级段落级的LDA中最重要的过程。
其中zli=j表示将段落中的第i个词项由局部主题j生成;Zli表示除第i个词项外的所有局部主题集合;W表示语料中所有词项集合表示除第i个词项外, 局部主题j生成词项t的次数表示除第i个词项外, 局部主题λ在段落m中发生的次数;V表示语料中词项的个数;Kl表示局部主题的个数;α和β分别为段落—主题和主题—词项Dirichlet分布的超参数。对所有段落中的所有词项通过N次迭代的Gibbs采样, 段落—局部主题分布θ和局部主题—词项分布φ分别如式(2)和(3) 所示, 其中分别表示局部主题kl生成词项t的次数和局部主题kl在段落m中发生的次数。
在第二级改进的LDA模型中, 对于给定的超参数, 所有潜在变量和可观察变量的联合概率如式(4)所示。其中C表示局部主题的个数,Nm表示文档m中词项的个数。
文档中的第i个词的全局主题为j, 且该全局主题与第k个局部主题相关的条件概率计算如式(5)所示。式(5)的详细推导过程请参见附录A。


4.2 显式陈述主题抽取
显式主题在显式陈述范围中是以显见方式表达的, 陈述中包含具体表示主题的词汇或短语。在显式陈述主题抽取中, 本文继承文献[18]的研究成果: 采用半监督的Bootstrapping和无监督的Bootstrapping相结合的方法提取维吾尔语评论文本中的主题。半监督的Bootstrapping方法从给定的种子词和种子模式出发; 无监督的Bootstrapping方法从半监督Bootstrapping过程中生成的冗余模式出发, 提取主题词。在模式匹配上采用模糊匹配和多次匹配的方式。限于空间,抽取过程的相关介绍详见文献[18]。以下主要介绍本文的改进之处。
在模式表示方面,本文不仅考虑了词和词性特征, 还考虑了维吾尔语意见陈述中主题词词干和词缀的语法特征, 语法特征详见第3.5小节。根据这些特征, 在模式表示中增加了词干特征和词缀特征。即, 模式中有词模式、词性模式、词干模式、词缀模式。词干模式可以使主题词的指向性更加明确,避免在附加不同词缀后, 同一主题词被判断为不同主题词; 词缀模式则有助于意见词的发现。例如, 在某些中性形容词之后附加表爱词缀, 则这些词会表现出较强主观性, 可以有助于判断附加了此类词缀的形容词即为意见陈述中的意见词。又因为意见词是主题词抽取的重要特征, 从而在客观上也说明词缀模式对主题词抽取具有重要作用。例如,

模式不仅包含了主题信息, 还附加了其对应的意见词信息。每个模式可作为一个完整意见陈述模式, 代表同一类型的意见陈述。提取出意见陈述中的主题词的同时, 还提取出其对应的意见词, 建立主题—意见词关系集合, 用于隐式陈述的主题抽取过程。
本文增加了对候选主题的精炼过程。对于提取出多于一个主题的意见陈述, 通过该意见陈述的全局主题和局部主题对当前主题的映射关系, 对出现的多个候选主题进行精炼。
显式陈述主题抽取目标是为每个显式陈述构建意见陈述—主题四元组
4.3 隐式陈述主题推断
隐式主题在隐式陈述范围中未用显见的方式表达, 陈述中不包含具体表示主题的词汇或短语。因此, 无法直接从隐式陈述中抽取, 需要结合意见词和前文信息进行推断。
本文深入分析了隐式主题的表现形式(3.3节)、隐式陈述主题与前一陈述主题的关系(3.4节)。用于推断隐式陈述中主题的隐式主题推断算法, 相关推断规则即是基于这些特点制定的。设CT(C_Claim)表示当前隐式陈述的当前主题, 隐式主题推断算法规则如下:
Rule 1CT(C_Claim)=CT(OW)
CT(OW)表示通过意见词直接推断出的主题。
Rule 2CT(C_Claim)∈RT(L_Claim)
RT(L_Claim)表示前一陈述主题的上、下义或相关主题列表。
Rule 3CT(C_Claim)=CT(L_Claim)
CT(L_Claim)表示前一陈述的当前主题。
Rule 4CT(C_Claim)∈Topic-Stack
Topic-Stack表示前文中部分陈述的主题所构成的主题栈。
Rule 5CT(C_Claim)∈RT(LT)
其中RT(LT)表示与局部主题相关的主题列表。
Rule 6CT(C_Claim)=LT(C_Claim)
LT(C_Claim)表示当前陈述的局部主题。
Rule 7CT(C_Claim)∈RT(GT)
RT(GT)表示与全局主题相关的主题列表。
Rule 8CT(C_Claim)=GT(C_Claim)
GT(C_Claim)表示当前陈述的全局主题。
在隐式主题推断时, 可能存在同时满足多个规则。为利用隐式主题推断算法中的这些规则, 必须为它们设置优先级。根据隐式陈述的特点分析, 我们建立如下优先级关系:
Rule 1 > Rule 2 >Rule 3 > Rule 4 > Rule 5 > Rule 6 > Rule 7 > Rule 8
在隐式主题推断算法运行时, 需要为每个隐式陈述更新和维护如下信息:
(1) 通过意见词推断出的主题, 可能为空;
(2) 前一陈述的主题和其上、下义或相关主题列表;
(3) 前文中部分陈述的主题所构成的主题栈;
(4) 该陈述的局部主题和与局部主题相关的新主题列表;
(5) 该陈述的全局主题和与全局主题相关的新主题列表。
通过意见词推断主题的过程如图3所示。
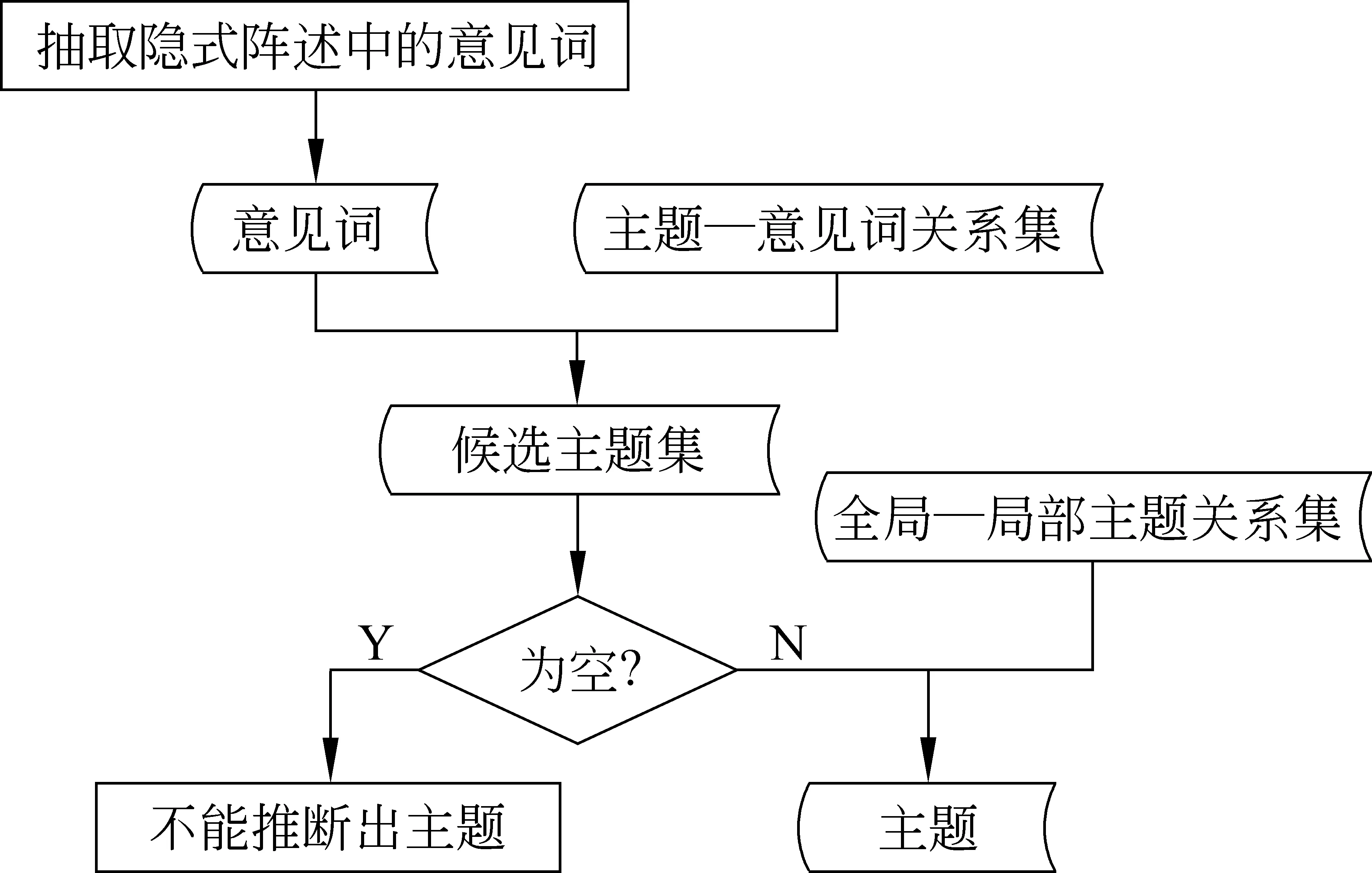
图3 意见词推断主题过程
维护信息(2)中主题上、下义或相关主题的关系建立是通过本课题组前期研究的词聚类方法建立的相同或相关词语簇; (3)中主题栈中的主题主要存储段落内该陈述之前的陈述的主题; (4)和(5)中列表的更新通过全局主题和局部主题抽取及“全局—局部主题”关系建立过程实现。(2) (4) (5)列表中的候选词均计算了其对该陈述的影响因子且按影响因子的降序排列, 影响因子计算如公式(9):
其中,Oo表示与当前隐式陈述中意见词o为近义词的意见词集合,Tt表示候选词t的同义词集合.p(Oo,Tt)表示集合Oo中任意词与集合Tt中任意词在意见陈述中的共现次数,p(Oo)表示集合Oo中任意词的出现次数,p(Tt)表示集合Tt中任意词的出现次数。
隐式陈述主题抽取目标是为每个隐式陈述构建意见陈述—主题四元组
5 实验及结果分析
5.1 实验数据
实验所用数据主要来自于人民网、天山网、昆仑网等网站的维吾尔文版和一些大型维吾尔文BBS网站。内容涵盖产品评论、文学评论、人物评论等。共496个评论文本, 1 759条意见陈述, 其中显式陈述1 302条, 隐式陈述457条。语料数据的详细分布如表1 所示。

表1 语料数据详细分布
实验所用语料均经过人工标注。首先, 我们将标注人员分为两组, 分别独立对语料进行标注,在标注过程中只允许组内讨论; 然后, 对两组标注后的语料进行一致性检查,对标注一致的,则认为标注正确; 对于标注不一致的地方, 邀请第三方参与进来一起进行投票表决。所标注的内容有全局主题、局部主题、全局—局部主题关系和每个意见的意见四元组; 并构建全局主题、局部主题和全局—局部主题3个标准库, 每个库中的元素都是按照元素的被标注次数进行降序排列。以上3个标准库为GLR-Cascaded LDA模型抽取实验提供标准参照, 用于测试该模型性能; 意见四元组为陈述级主题抽取提供标准参照, 用于测试本文算法整体性能。
5.2 实验结果及分析
5.2.1 全局—局部主题抽取实验
利用GLR-Cascaded LDA模型进行全局—局部主题的抽取。全局主题和局部主题主要为名词或代词, 因此在抽取结果中过滤了其他词性的词语。GLR-Cascaded LDA模型第一级参数设置如下:α=0.1,β=0.01, 局部主题数Kl=50, 迭代次数N=1 000。第二级参数设置如下:γ=0.1,ε=0.01,δ=0.1, 全局主题数Kg=20, 全局—局部关系数R=4, 迭代次数N=1 000。得到的局部主题、全局主题、全局—局部主题关系分别如表2、3、4 所示。限于空间, 抽取结果只列出TOP 10 项。

表2 局部主题抽取结果TOP 10

表3 全局主题抽取结果TOP 10

表4 全局—局部主题关系抽取结果TOP 10
从表2~3中可以看出, GLR-Cascaded LDA模型在单字词全局主题和局部主题抽取上取得了很好的实验效果。但传统的基于LDA模型的思想未考虑文档中的词与词之间的联系, 无法抽取多词全局主题和局部主题, 也无法建立全局—局部主题关系。

5.2.2 陈述级的主题抽取实验
从产品评论、文学评论、人物评论领域和开放领域 (包含所有的语料数据) 分别进行陈述级的主题抽取实验。
图4 给出了显式陈述主题抽取的实验结果。从图中可见, 在产品评论领域和开放领域的各项评价指标均超过了82.00%; 人物评论领域也只有正确率略低于80.00%, 为79.76%; 在文学评论领域各项评价略低于其他领域和开放领域, 这是因为在文学评论文本中表达方式和表现手法较为丰富, 给实验带来了一定干扰。

图4 显式陈述主题抽取结果
图5为隐式陈述主题抽取实验结果。对比图4和图5可以看出, 各领域和开放领域的隐式主题抽取的实验结果均低于显式主题抽取结果。这是因为在隐式主题抽取过程中用到了显式主题抽取过程中的结果, 因此, 在隐式主题抽取过程中也会将显式主题抽取中的一些错误知识认为是正确的, 并加以参考和运用, 这对隐式主题抽取的实验结果有一定的影响。不过, 从整体上看, 特定领域和开放领域的各项实验评价指标均在70%以上, 这说明了本文方法在隐式主题抽取上的有效性。
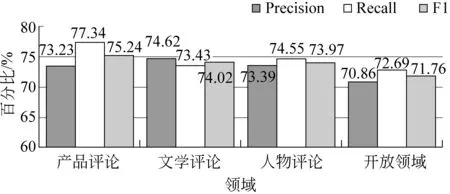
图5 隐式陈述主题抽取结果
图6为主题抽取的最终结果 (包括显式的和隐式的)。综合图4、5、6, 每个特定领域和开放领域抽取结果的正确率、召回率、F1值相差均不大。这说明本文方法通用性强,不仅不依赖于领域知识, 能在各领域之间灵活切换, 而且适用于开放领域。

图6 主题抽取结果
6 结论及下一步工作
本文设计的针对维吾尔语评论文本的主题抽取方法, 既能抽取显式陈述的主题, 又能推断隐式陈述的主题, 抽取的最终目标是为每个意见陈述建立意见陈述—主题四元组
本研究的进一步工作主要包括: (1) 在上、下义主题词语簇和相关主题词语簇的建立上还比较粗糙。为提高提取结果的精确性, 我们将进一步完善上、下义主题词语簇和相关主题词语簇的构建方法; (2) 由于维吾尔语属于黏着语, 而目前维吾尔语词干提取的精度不高。因此, 我们将进一步提高词干提取的精度, 对抽取出的主题词进行词干提取。
[1] Hu Min-qing, Liu Bing. Mining and Summarizing Customer Reviews[C]//Proceedings of the 10th International Conference on Knowledge Discovery and Data Mining. Seattle, Washington, USA, 2004: 168-177.
[2] Titov I, Mcdonald R. Modeling Online Reviews with Multi-grain Topic Models[C]//Proceeding of the 17th International Conference on World Wide Web. Beijing, China, 2008: 111-120.
[3] 张莉, 钱玲飞, 许鑫. 基于核心句及句法关系的评价对象抽取[J]. 中文信息学报, 2011, 25(3): 23-29.
[4] 顾正甲, 姚天昉. 评价对象及其倾向性的抽取和判别[J]. 中文信息学报, 2012, 26(4): 91-97.
[5] Jo Y, Oh A. Aspect and Sentiment Unification Model for Online Review Analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining. Hong Kong, China, 2011: 815-824.
[6] Thet T T, Na J, Khoo C S G. Aspect-based sentiment analysis of movie reviews on discussion boards[J]. Journal of Information Science, 2010, 36(6): 823-848.
[7] Chen Li, Qi Luo-le, Wang Feng. Comparison of feature-level learning methods for mining online consumer reviews[J]. Expert Systems with Applications, 2012, 39(10): 9588-9601.
[8] Liu Bing, Hu Min-qing, Cheng Jun-sheng. Opinion observer: analyzing and comparing opinions on the Web[C]//Proceedings of the 14th international conference on World Wide Web. Chiba, Japan, 2005: 342-351.
[9] Ojokoh B A, Kayode O. A Feature-Opinion Extraction Approach to Opinion Mining[J]. Journal of Web Engineering, 2012, 11(1): 51-63.
[10] 刁宇峰, 杨亮, 林鸿飞. 基于LDA模型的博客垃圾评论发现[J]. 中文信息学报, 2011, 25(1): 41-47.
[11] Li P, Jiang J, Wang Y. Generating templates of entity summaries with an entity-aspect model and pattern mining[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala, Sweden, 2010: 640-649.
[12] Mukherjee A, Liu B. Aspect Extraction through Semi-Supervised Modeling[C]//Proceedings of 50th Annual Meeting of Association for Computational Linguistics. Jeju, Republic of Korea, 2012: 339-348.
[13] Qiu Guang, Liu Bing, Bu Jia-jun, et al. Opinion Word Expansion and Target Extraction through Double Propagation[J]. Computational Linguistics, 2011, 37(1): 9-27.
[14] Li Su-ke, Guan Zhi, Tang Li-yong, et al. Exploiting Consumer Reviews for Product Feature Ranking[J]. Journal of Computer Science and Technology, 2012, 27(3): 635-649.
[15] Zhu Jing-bo, Wang Hui-zhen, Zhu Mu-hua, et al. Aspect -based opinion polling from customer reviews[J]. IEEE Transactions on Affective Computing, 2011, 2(1): 37-49.
[16] Tian Sheng-wei, Yu Long, Huang Jun, et al. Extraction of Uyghur Evaluation Object[J]. International Journal of Digital Content Technology and its Applications, 2012, 6(2): 61-68.
[17] Su Qi, Xu Xin-ying, Guo Hong-lei, et al. Hidden Sentiment Association in Chinese Web Opinion Mining[C]//Proceedings of the 17th international conference on World Wide Web. Beijing, China, 2008: 959-968.
[18] 仇光, 郑淼, 张晖,等. 基于正则化主题建模的隐式产品属性抽取[J]. 浙江大学学报(工学版). 2011, 45(2): 288-29.
附录A:公式(5)的推导过程
∵Γ(x+1)=xΓ(x) 当x>0时
