基于用户生成内容的产品搜索模型
2013-04-23王海雷章彦星赵海玉
王海雷,章彦星,赵海玉,张 铭
(1. 北京大学 光华管理学院,北京 100871;2. 中国民生银行 博士后工作站,北京 100031;3. 北京大学 信息科学技术学院,北京 100871)
1 引言
随着Internet的普及和web技术的蓬勃发展,大批B2C/C2C购物网站、专业评测网站、第三方评论网站、购物社区的兴起,构成了电子商务领域的信息链。越来越多的人倾向于在网络上自由表达观点,大量的用户生成内容能够帮助用户更全面地了解产品,做出理性的决策。
正如搜索引擎是互联网的信息入口,产品搜索毫无疑问是电子商务的重要入口。Kumar等人2010年发表的文献[1]指出,在所有通过网络购物的用户中有20.1%的用户在购物之前使用了产品搜索,而产品搜索占互联网搜索总量的19.91%。
产品搜索与传统IR领域的网页搜索相比具有新的特点[2],主要表现在: 搜索的应用类型不同,搜索的内容来源不同,搜索的结果粒度不同,搜索的用户需求不同。如何综合利用各种类型的客观产品数据和主观用户生成内容,设计符合用户需求的搜索模型,是产品搜索面临的重要挑战。
现有的产品搜索模型大多只考虑产品的客观数据,这些搜索模型与用户需求即消费者购买决策的考虑因素不甚相符。近年来,有一些研究将用户生成内容(如产品评价)应用于解决产品搜索问题。这类搜索模型大多基于用户评分、用户评论数等结构化数据,或者基于对用户评论文本进行语法结构和较粗粒度的语义情感分析选取的模型特征,往往缺乏能有效结合客观数据和用户生成内容的具有理论支持的搜索模型。
本文内容组织如下: 第1节是目前产品搜索的相关工作;第2节介绍本文提出的产品搜索模型的理论基础及MNL模型的原理;第3节详细阐述模型特征选择和参数训练的方法;第4节通过实验对训练产品搜索模型进行解释,双盲实验显示,本文提出的搜索模型比基准算法有显著的提高。
2 研究背景
现有的产品搜索模型,通常与传统信息检索领域文档搜索模型类似,对生产厂家提供的产品介绍、性能参数等客观数据进行建模,基于元数据匹配与否[3]、文本相似度、文档结构[4]和链接等特征构建搜索模型,搜索模型及排序标准与用户选购产品的实际需求之间存在着不小的差异。
近年来,有一些研究将用户生成内容应用于解决搜索问题。Scaffidi等人实现的Red Opal系统[5]使用词性标注和关联规则挖掘的算法从用户评论中识别产品特征;Zhang等人通过对数码相机和电视类产品的用户评论进行主客观分类,识别出其中表示比较意义的句子,对比较句进行情感分析构建以产品为结点的偏序集,然后使用图模型对产品进行排序[6];Li等人对酒店的用户评论进行分析,选择酒店的价格、地理位置、服务等客观数据,以及用户评分、用户评论的可读性和特征粒度的情感分析等特征,使用有监督的学习方法训练了随机系数模型作为酒店搜索排序模型,并实现了酒店搜索的原型系统[7-8]。
文献[5]的产品搜索模型仅仅基于单一产品特征的情感分析结果,搜索效果较差;文献[6]对比较句进行分类并构建图模型,考虑到用户评论中比较句的数据来源比较稀疏,而且句子主客观分类的准确性不高,对搜索结果影响较大。文献[7-8]通过对英文用户评论进行情感分析获取的模型特征对搜索结果的影响甚微,而且没有考虑通常影响消费者选择商品的品牌等因素。
考虑到用户生成内容在电子商务中的作用,以及现有产品搜索模型的缺点,本文以消费者行为分析和离散选择分析的相关理论为基础,设计了一个结合产品客观数据和用户生成内容的产品搜索模型。从产品客观数据中选取品牌、价格、上市时间、销售商家数等模型特征,结合从用户生成内容中提取的用户评分、评论数、评论的特征粒度的情感分析等,使用有监督学习方法训练MNL模型对产品进行搜索。
3 产品搜索模型
3.1 理论基础
首先假设消费者在选择产品前,能够尽可能多地了解产品信息以做出理性抉择。因此,不妨假设所有使用产品搜索的消费者都是理性的。
假设1(理性假设) 所有使用产品搜索的消费者都是理性的。
产品搜索的关键问题之一,在于如何确定产品的评价标准。根据马歇尔的《经济学原理》[9],可以用消费者剩余(consumer surplus)的概念来衡量消费者在购买一件产品时获得的净收益,下面给出消费者剩余的形式化定义:



(2)


联立(1)(2)(3)可得,消费者i购买产品j的消费者剩余可表示为:

以上理论模型用消费者剩余量化了理性消费者选择产品的评价标准,可以作为产品搜索模型的排序依据。
3.2 MNL模型
消费者选择产品是个离散选择问题,MNL模型是一种最基本的离散选择模型,用于研究影响购买行为的诸多因素,由McFadden提出[12]并演绎成混合Logit模型[13]。对上一节公式(4)进行分解,可以表示成如下形式:
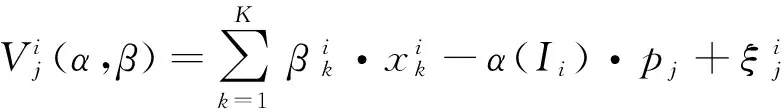
MNL模型以以下假设为前提[12]。
假设2(消费者同质化假设) 所有消费者是同质化的,即消费者的偏好是一致的,且消费者本身的特征(如占有财富)也是相同的。
假设3(产品独立性假设) 不同产品之间是独立的,即不同产品之间不可以线性替代。
根据消费者同质化假设,公式(4)中模型参数的值对所有消费者都是相等的,因此可以推导成如下形式:



(8)
4 模型训练
4.1 特征选择
根据来源及粒度,产品搜索模型选取的特征可以分为如表1所示的三类。

表1 模型特征分类
其中,产品粒度的模型特征来自于产品的结构化数据;评论粒度的模型特征来自于用户生成内容中的结构化数据,以及对非结构化文本的句法结构、语法进行浅层分析;而评论特征粒度的模型特征,需要对用户评论进行基于特征的情感分析,研究评论语义和语境维度的特征。
首先给出产品特征的定义。产品特征,通常是指产品的组成部分、功能、性能、属性等某些细节方面。

具体包括两步骤: 第一步,特征词识别及评论句分类;第二步,情感极性分析。第一步如算法1所示。
算法1.特征词扩展及评论句分类算法


第1步: 将用户评论D={d1,…,dm}按句切分为;

第3步: 对于词典中的每个词语w,计算它与每个特征的相似度χ2(w,Ai);
第4步: 对于每个特征Ai,将词语按相似度降序排序,取前p个词语加入Ti;
重复步骤2~4,直到T不再扩张为止。
其中算法第3步,根据文献[15]计算词语与特征的相似度χ2,公式如下:

第二步情感分析的算法描述如下所述:
算法2.情感极性判断算法



第2步: 根据中文WordNet的形容词同义词集合,以及人工构建的情感词集合,判断候选情感词的极性;

4.2 参数学习
根据公式(5),产品的消费者剩余不是一个直接可观测的变量,因此无法直接用来进行参数估计。MNL模型基于IIA假设,将消费者剩余转换成消费者选择产品的概率计算公式。而公式(8)中消费者i选择产品j的概率,可以近似于该产品的市场占有率,即:
其中,dj是产品j的销量,dtotal是市场在售的同类产品的总销量。
对公式(8)两边取对数,然后结合公式(10)可以推得:

根据公式(11),因变量dj可以从电子商务网站的统计数据中得到,因此,在大规模数据集的基础上,可以使用最小二乘法解得模型参数α和βk。
本文使用M5算法[14]进行特征选择,该算法基于标准相关系数选择要删除的模型特征,然后根据信息熵理论的AIC准则[15]计算删除特征后的模型误差,迭代直到获得模型误差最小的特征集合。
算法3.特征选择M5算法
输入: 模型特征
输出: 经过选择的模型特征
第1步: 计算模型特征的标准化相关系数;
第2步: 去除其中标准化相关系数最小的模型特征;
第3步: 根据AIC准则计算模型误差;
第4步: 重复1~3直到模型误差不再减小。
AIC准则的计算公式为AIC=2k-2ln(L),其中,k是模型参数的个数,L是根据似然度函数计算的模型的最大似然度。给定一组统计模型,其中最优的模型具有最小的AIC值。因此,M5算法实质上是基于AIC准则的特征选择的贪心算法。
5 实验结果与分析
5.1 数据集
本研究在2011年11月到2012年4月,从中关村在线和淘宝网爬取了手机、笔记本电脑、数码相机三个大类,共计15 505款产品,151 594条用户评论,3 158 658条价格销量数据。在丢弃重复、缺失、冲突数据,并且对产品按所属的系列进行聚类后,得到数据集规模如表2所示。

表2 数据集规模
对产品进行聚类的操作能够有效地处理数据稀疏问题,有助于提高搜索模型的准确率。
5.2 模型解释
在以上数据集上,作者训练了手机、笔记本电脑、数码相机类的搜索模型,其特征及权重如表3所示。

表3 手机类模型特征及权重
图1所示的是产品的上市时间、商家数、价格、评论数、用户评分,以及11个来自用户评论情感分析等模型特征两两之间的相关性系数和联合分布。其中,矩阵最后一列为模型特征与因变量之间的相关系数,除此之外,矩阵对角线为模型特征的直方图,右上部为模型特征两两间的相关系数,左下角为模型特征两两间的联合分布。
如图1所示,某些模型特征,如评论数,其本身与因变量之间就具有显著的相关性,无疑是一个很显著的模型特征。而特征两两之间通常不具有显著的线性相关性。此外,通过用户评论情感分析得到的模型特征,其分布往往也比较符合正态分布,这与本文选择模型的预期是一致的。
对模型特征进行假设检验,得到高于显著性水平的模型特征各54个、30个、40个。表3所示是手机类搜索模型显著性最高的30个特征及其权重。
可以看出,产品的上市时间、销售商家的数目、价格、评论数目和用户评分,无疑对用户选择产品的概率有着显著的影响。对时效性较强的电子产品而言,相较于上市已久的老产品,用户往往愿意选择刚上市的新款;销售商家数目的多少,在一定程度上能反映产品的受欢迎程度;产品价格也不是越便宜越好,手机市场激烈的竞争导致了产品价格与质量的理性回归,较高价格的款式通常功能、 性能、 外观上令用户的满意度更高,觉得物有所值;评论数目的多少以及用户评分的高低无疑对用户选购商品是一个很重要的参考,大量的相关研究已经证实了这一点。

图1 手机类模型特征的相关性及联合分布
5.3 双盲实验
为了定量地测量本文提出的搜索模型的准确性,作者对随机选取的120名产品搜索用户进行了双盲测试。
作者训练了手机、笔记本电脑、数码相机类的搜索模型,对比中关村在线和淘宝网的搜索结果,并且实现了基于文本相似度的相关性、用户评分、评论数、价格降序、价格升序、销售商家数、上市时间由新到旧,同时考虑到用户对低价/高价以及新上市商品的偏好,实现了基于价格和上市时间的综合算法,以此作为基准算法,计算用户对本文提出的搜索模型的偏好。表4为双盲实验的结果,表中数据的百分比表示: 相对于基准算法而言,认为本文的搜索模型更好的用户所占的比例。

表4 用户双盲实验结果
相较于基准算法,本文的搜索模型的具有显著的统计学意义上的提高。其中,中关村在线只提供简单的搜索功能,并没有一个完整的排序模型支持;而淘宝网作为大型B2C商家,其搜索结果综合地考虑了产品本身的质量、价格,以及销售商家的资质和提供的服务质量等,与本文搜索模型的目的不尽相同,其结果不具有完全意义上的可比性。而其他基准算法,大多是基文本相似度或者其他产品本身或用户评论的单一属性来权衡产品,与用户需求存在较大差异。
6 结束语
本文从消费者的真实需求出发,提出了一个基于用户生成内容的产品搜索模型。该模型以消费者行为分析和离散选择模型为理论基础,结合了客观的产品数据和主观的用户生成内容,权衡了产品的品牌、价格、用户评分以及从用户评论中获取的关于产品功能、性能、外观等各个因素。实验结果表明,本文提出的模型明显优于基准算法。本文选择的MNL模型基于用户同质化假设,预测产品的消费者剩余来作为搜索排序的依据,也就是给出大众对产品的性价比排序。
目前对中文用户评论的情感分析研究,虽然从文档粒度逐步细化到特征粒度,但仍不够精细。情感极性的判断依旧停留在语义层面上,对情感分析结果的精度和广度都有较大的影响。未来考虑如文献[16]使用机器学习的方法对情感词极性进行语境层次的分析,希望能有较大的改善。
[1] R Kumar, A Tomkins. A characterization of online browsing behavior[C]//Proceedings of the 19th international conference on World wide web, Raleigh, North Carolina, USA, April 26-30, 2010: 561-570.
[2] G Singh, N Parikh, N Sundaresn. User behavior in zero-recall ecommerce queries[C]//Proceedings of SIGIR, Beijing, China, 2011: 75-84.
[3] K P Yee, K Swearingen, K Li, et al. Faceted Metadata for Image Search and Browsing[C]//Proceedings of CHI 2003, April 5-10, 2003: 401-408
[4] Z Nie, J R Wen, W Y Ma. Webpage understanding: beyond page-level search[C]//Proceedings of ACM SIGMOD Record, 37(4), 2008: 48-54
[5] C Scaffidi, K Bierhoff, E Chang, et al. Red Opal: product-feature scoring from reviews[C]//Proceedings of EC’07, 2007: 182-191.
[6] K Zhang, R Narayanan, A Choudhary. Voice of the customers: mining online customer reviews for product feature-based ranking[C]//Proceedings of WSON2010. Boston, Ma, 2010:11-11
[7] B Li, A Ghose, P G Ipeirotis. A Demo Search Engine for Products[C]//Proceedings of WWW 2011, March 28-April 1, 2011.
[8] B Li , A Ghose, P G Ipeirotis. Towards a theory model for product search[C]//Proceedings of WWW 2011, March 28-April 1, 2011.
[9] A. Marshall. Principles of Economics[M]. London, Eighth ed. Macmillan and Co., 1926.
[10] K Lancaster. Consumer Demand: A New Approach[M]. Columbia University Press, New York, 1971.
[11] S Rosen. Hedonic prices and implicit markets: Product differentiation in pure competition[J]. Journal of Political Economy, 1974, 82(1): 34-55.
[12] D McFadden. Conditional Logit Analysis of Qualitative Choice Behavior[M]. Academic Press, New York, 1974.
[13] http://elsa.berkeley.edu/reprints/mcfadden/zarembka.pdf
[14] D McFadden, K Train. Mixed MNL Models for Discrete Response[J]. Journal of Applied Econometrics, 2000, 15(5):447-470.
[15] E Frank, M Hall, G Holmess, et al. Weka[J]. Data Mining and Knowledge Discovery Handbook, 2005, VIII, pp. 1305-1314.
[16] H Akaike. A new look at the statistical model identification[J]. IEEE Transactions on Automatic Control, 1974, 19(6):716-723.
