基于相关熵的盲源分离算法
2013-01-08成昊,唐斌
成 昊,唐 斌
(电子科技大学电子工程学院 成都 611731)
盲源分离起源于鸡尾酒会问题[1],即在嘈杂环境下如何通过不同传感器接收到的混合信号,分离出各个说话者的语音信号。在这过程中,并无先验信息或仅有较少的先验信息可用。随后,盲源分离被广泛扩展到了生物医学、雷达、通信和地震信号处理等领域。
为解决该问题,自文献[2]提出了H-J算法后,独立成分分析(independent component analysis, ICA)的理论体系逐渐成熟并被广泛应用到各个领域。ICA主要利用了源信号间的独立性假设,通过不同的角度对假设进行数学近似,从而达到盲源分离的目的。通常情况下,ICA算法多要求信号源中至多只有一个服从高斯分布。从信息极大化的角度出发,文献[3]提出了infomax算法;为避免自适应过程中的矩阵求逆,文献[4]提出了自然梯度算法;文献[5]利用四阶累计量矩阵,提出了特征矩阵联合近似对角化(joint approximative diagonalization of eigenmatrix,JADE)算法;为提高计算效率,文献[6]提出了固定点ICA算法(fixed point ICA, FPICA),又称为快速ICA(FastICA)算法等。这些算法的出发点在于利用一定的统计信息对源信号的独立性进行近似体现,在此基础上实现盲源分离。通常认为,采用四阶的统计信息即可较好地实现盲源分离,现有算法也大多基于四阶的统计信息。因此,从统计角度来说,盲源分离算法还有一定发展空间。
在统计信号处理方面,文献[7-12]提出了信息理论学习(information theoretic learning, ITL)的理论体系。ITL从信息论的角度,通过将传统的香农熵(Shannon’s entropy)到雷尼熵(Renyi’s entropy)的扩展,探索了有别于传统的矩和累计量的统计信息,并获得了大量应用。文献[13]指出将相关熵(correntropy)和时延信息相结合的相关熵函数(correntropy function),可以应用于对超高斯分布源和次高斯分布源组成的混合信号的分离,即信号源在峭度上需具有不同的符号,但算法中多个不同时延相关熵函数的估计使得算法复杂度较高。更进一步地,文献[14]提出并证明了基于相关熵的独立性测度,使得这一概念有了更完善的理论依据。
本文提出了基于相关熵的盲源分离算法,该算法不需要多个不同时延的相关熵函数的估计,而是通过利用相关熵近似体现各个源信号之间的独立性,建立合适的代价函数,实现盲源分离。
1 盲源分离模型

2 信息理论学习的信息度量
2.1 雷尼熵和信息势
信息理论学习采用了雷尼熵作为基础和出发点。雷尼熵定义为:

式中,p(x)为连续随机变量X的概率密度函数。本文主要研究X为连续随机变量的情况。当参数a=2时,雷尼熵和信息势变为最为常用的二次熵和二次信息势。
采用宽度s的高斯核,利用Parzen的概率密度函数估计方法[15],可得到二次信息势的估计为:


2.2 相关熵
在信息理论学习基础上,作为随机变量之间的广义相似程度的度量,定义相关熵为:

式中,k为满足kÎL¥的任意正定核。该相关熵指两个随机变量之间的互相关熵,为简明起见,在下文的分析中,均直接以相关熵进行说明。
传统的相关定义即为选取k(x,y)=xy的特殊情况,即只考虑二阶统计信息。在相关熵中,通常选取k为高斯核,得到:

可以看到,相关熵可以分解为X-Y的偶数阶矩的加权和,因此相关熵中蕴涵了比传统的相关更多的信息量。此外,相对于传统ICA方法多利用四阶统计信息,相关熵更广泛地考虑到了各偶数阶统计信息,提供了更有效实现盲源分离的可能。

式中,a和b为任意实数,且要求a¹0。该定义的提出允许对联合概率密度函数的积分可以沿平面上任意斜率的直线进行,且该直线不需要一定经过平面原点,其估计为:

此外,由于核的性质造成的非线性变换的存在,即使输入数据已经被中心化的情况下,得到的相关熵也并非总是零均值。因此,定义中心相关熵:
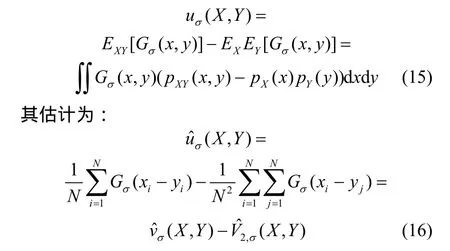
从而将信息势与相关熵的概念联系起来。
将式(13)的参数化相关熵与式(15)的中心相关熵结合起来,得到参数化中心相关熵:
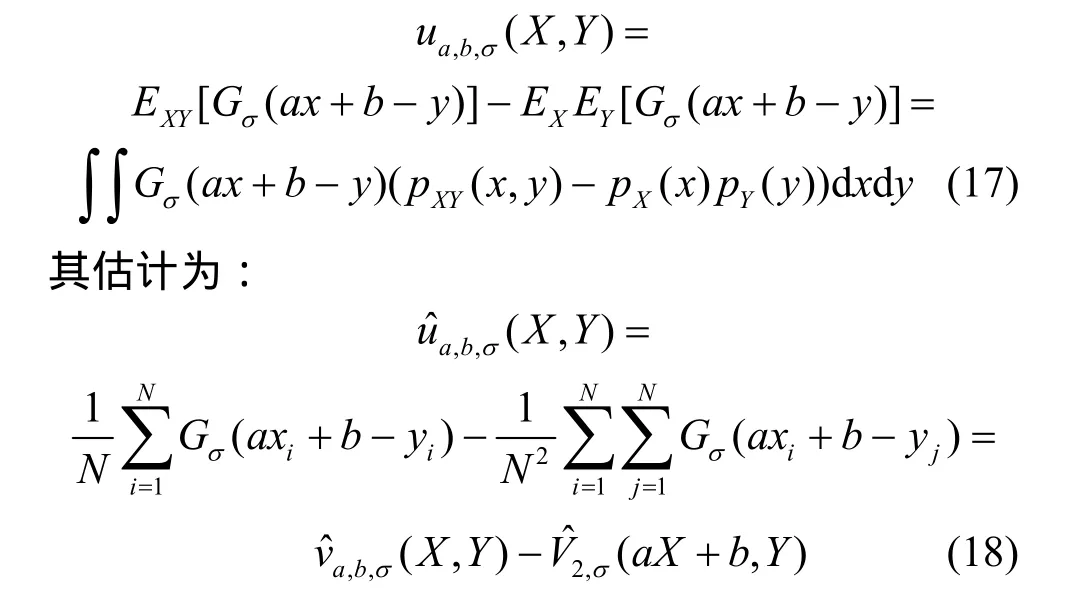
2.3 核宽度选取
在信息理论学习中,核宽度s是其中的一个自由参数。在核宽度的选取上,一个建议的准则为Silverman准则(Silverman’s rule):
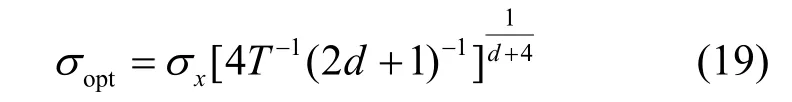
式中,T为数据长度;d为数据维度;xs为数据标准差。实际中,根据不同情况,选取不同的核宽度,可能会得到更好的性能。
3 基于相关熵的盲源分离
3.1 相关熵的独立性测度
在概率论中,传统的对随机变量间的独立性是通过概率密度函数定义的,即:

3.2 盲源分离算法
考虑由超高斯信号和次高斯信号混合得到的两路接收混合信号,按照常规的分离流程,首先对其进行球化,以去除其中的二阶相关并使得各路信号功率相同,得到预处理后的信号%x。此后的解混矩阵为一正交矩阵,可表示为旋转角度的形式:
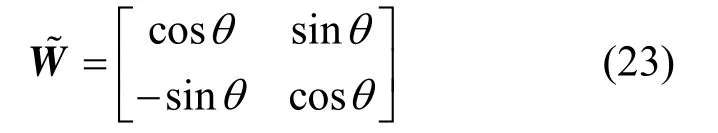
选取g(X,Y)作为代价函数,通过梯度下降法对其进行最小化,得到对应的旋转角q,从而获得恢复信号y。算法使得对解混矩阵中四个元素的寻优转化为对标量q的寻优,降低了计算维数。
算法的具体流程如下:
1) 对接收到的混合信号x进行球化,得到预处理后的信号;
2) 选取初值0q和小的角度增量Dq,计算:


4 计算机仿真
4.1 仿真参数设置与性能评价指标
在本文的计算机仿真中,分别采用拉普拉斯分布源和均匀分布源生成超高斯源信号和次高斯源信号。拉普拉斯分布的概率密度函数为:

这里不考虑盲分离中可能会出现的分离信号的反号与排序问题,即选择所有可能组合中最大的平均信干比作为输出。
4.2 仿真结果分析
实验1中,对于数据长度为1 000的两路源信号,在不同的旋转角下分别计算代价函数,关系曲线如图1所示。由于在盲分离中不考虑反号与排序问题,旋转角范围选择为由图1看到,代价函数在旋转角接近零时最小,近似体现了源信号之间的独立性;此外,代价函数与旋转角的关系曲线仅存在一个全局最小值,因此采用梯度下降法不会陷入局部最优。
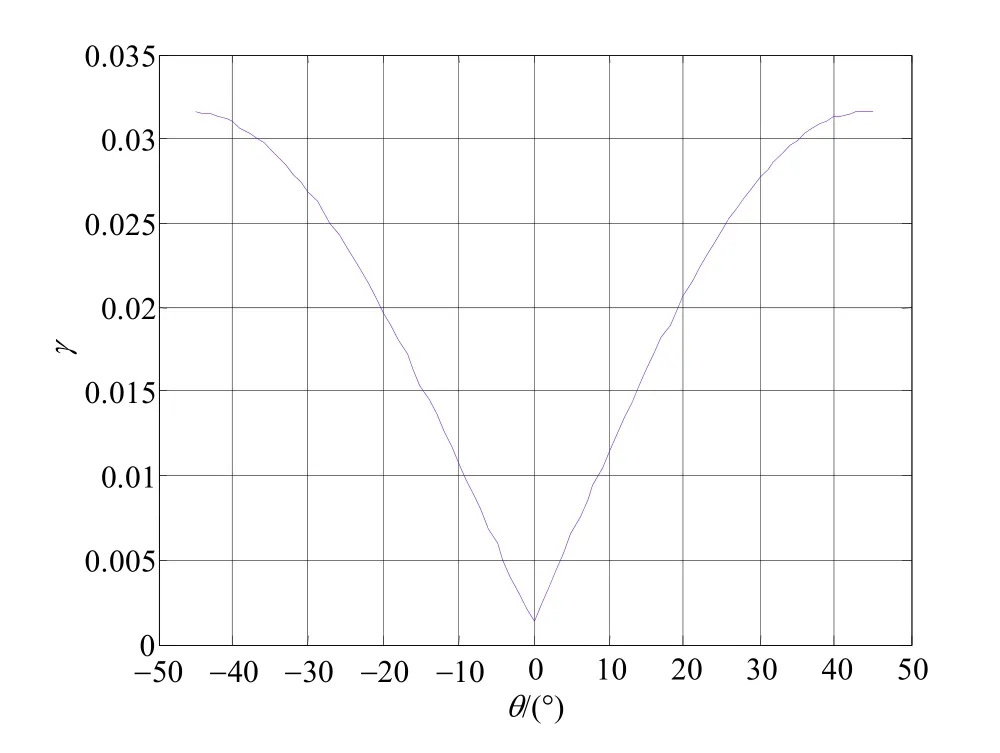
图1 代价函数与旋转角度关系曲线
实验2对本算法的分离效果进行了仿真,数据长度为1 000的源信号、混合信号以及利用本算法的分离信号如图2所示。可以直观看出,不考虑分离信号可能会出现的反号和排序问题,本算法有效地进行了分离。此外,在该次实验中,通过计算得到输出信干比为23.5 dB。

图2 源信号、混合信号与分离信号
实验3研究了核宽度的选取对于算法性能的影响,关系曲线如图3所示。其结果为100次仿真取平均值,数据长度为1 000。可以看到,在有无噪声情况下,本算法的性能受核宽度影响均不明显。
实验4研究了算法性能与数据长度的关系,并与传统的FPICA算法进行对比,其结果为100次仿真取平均值,如图4所示。可以看到,无噪声情况下,本文算法与FPICA算法类似,数据长度越长,算法性能越好,在数据长度接近1 000时,相对于传统的ICA算法,本文算法的性能优势开始体现。当输入中带有噪声时,两种算法性能出现明显降低,表明本文算法和传统ICA算法类似,对噪声较为敏感。在信噪比为30 dB时,较无噪声情况,输出信干比下降已较为严重,但本算法在数据长度接近1 000时,性能仍然优于FPICA算法。当信噪比降至20 dB时,两种算法的输出信干比进一步下降,且几乎与数据长度无关。此时的输出信干比约为5 dB,分离效果受到较大影响。在此情况下,本算法相对于FPICA算法优势已经不再明显。

图3 输出信干比与核宽度关系曲线

图4 超高斯分布源与次高斯分布源混合时输出信干比与数据长度关系曲线
实验5在实验4的基础上,将源信号中作为次高斯源的均匀分布源信号替换为一个雷达中常见的线性调频(LFM)信号,使其具有了时间结构。LFM信号的归一化起始频率为0.105,归一化带宽为0.082,仿真结果如图5所示。与实验4类似,在无噪声和信噪比30 dB时,数据长度越长,算法性能越好。在数据点数接近1 000时,相对于传统的ICA算法,本算法具有性能优势。同样,当信噪比降至20 dB时,两种算法分离性能均受到较大影响,且几乎不受数据长度影响,本算法相对于FPICA算法优势已不再明显。
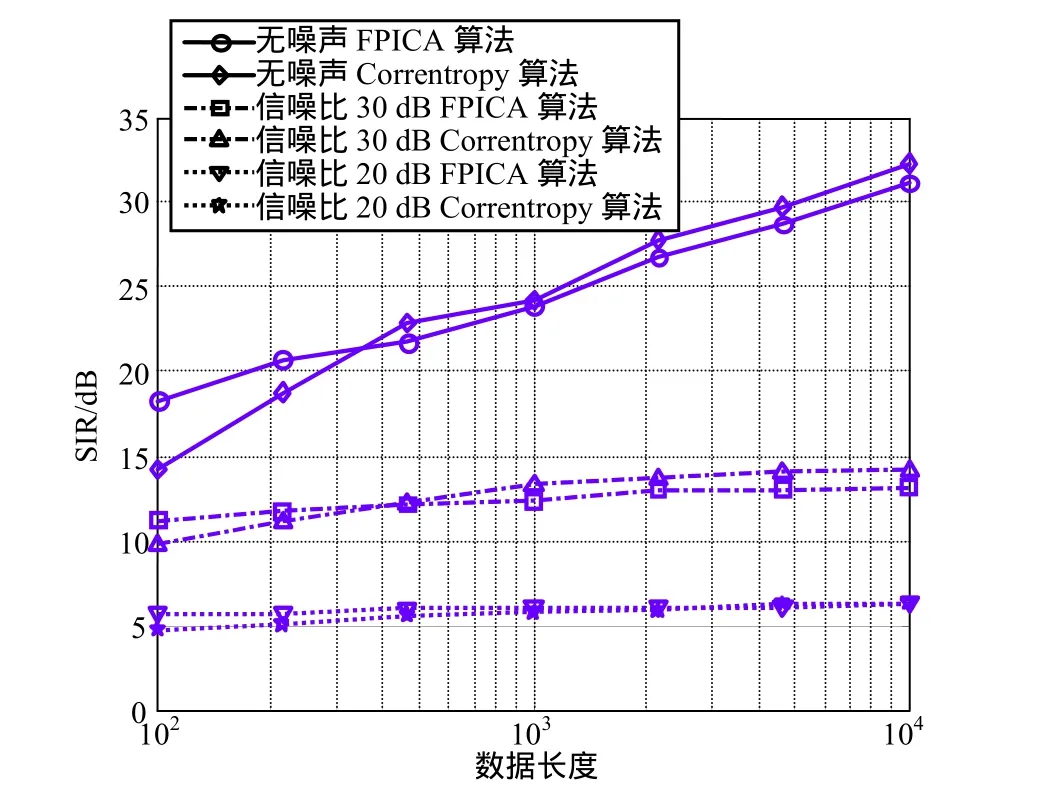
图5 超高斯分布源与LFM信号混合时输出信干比与数据长度关系曲线
5 结 论
本文从信息理论学习原理出发,基于相关熵与独立性测度的关系,在传统ICA方法多使用四阶统计信息的基础上,利用相关熵对其进行了扩展,实现对超高斯混合信号和次高斯混合信号的分离。仿真表明,本文算法优于传统的ICA算法。同时也表明算法受到核宽度选取的影响不大。但本文算法讨论的是对于超高斯分布源和次高斯分布源的分离,下一步的研究内容为如何在源信号峭度符号相同时进行分离,以便扩展到更多数目源信号的盲源分离中。
6 致 谢
作者在与Jose Principe、Sohan Seth和Ruijiang Li等人的交流中受益匪浅,在此表示感谢。
[1] CHOI S, CICHOCKI A. Adaptive blind separation of speech signals: cocktail party problem[C]//Proc International Conference on Speech Processing. Seoul, Korea: [s.n.], 1997:617-622.
[2] JUTTEN C, HERAULT J. Blind separation of sources, part I:an adaptive algorithm based on neuromimetic[J]. Signal Processing, 1991, 24(1): 1-10.
[3] BELL A J, SEJNOWSKI T J. An information-maximization approach to blind separation and blind deconvolution[J].Neural Computation, 1995(7): 1129-1159.
[4] AMARI S. Natural gradient works efficiently in learning[J].Neural Computation, 1998, 10(2): 251-276.
[5] CARDOSO J F. High-order contrasts for independent component analysis[J]. Neural Computation, 1999, 11(1):157-192.
[6] HYVÄRINEN A. Fast and robust fixed-point algorithms for independent component analysis[J]. IEEE Trans Neural Networks, 1999, 10 (3): 626-634.
[7] HILD II K, ERDOGMUS D, TORKKOLA K, et al. Feature extraction using information-theoretic learning[J]. IEEE Trans Pat Analy Mach Intell, 2006, 28(9): 1385-1392.
[8] SANTANA E, PRINCIPE J C, SANTANA E E, et al.Extraction of signals with specific temporal structure using kernel methods[J]. IEEE Transactions on Signal Processing,2010, 58(10): 5142-5150.
[9] PRINCIPE J. Information theoretic learning: renyi's entropy and Kernel perspectives[M]. New York: Springer, 2010.
[10] GUNDUZ A, HEGDE A, PRINCIPE J C. Correntropy as a novel measure for nonlinearity tests[J]. Signal Processing,2009, 89(1): 14-23.
[11] JEONG K H, LIU W, PRINCIPE J. The correntropy MACE filter[J]. Pattern Recognition, 2009, 42(5): 871-885.
[12] VERA P A, ESTEVEZ P A, PRINCIPE J C. Linear projection method based on information theoretic learning[C]//ICANN'10 Proceedings of the 20th international conference on Artificial neural networks: Part III. Thessaloniki, Greece: [s.n.], 2010: 178-187.
[13] LI R, LIU W, PRINCIPE J C. A Unifying criterion for instantaneous blind source separation based on correntropy[J]. Signal Processing, 2007, 87(8): 1872-1881.
[14] RAO M, SETH S, XU J, et al. A test of independence based on a generalized correlation function[J]. Signal Processing, 2011, 91(1): 15-27.
[15] PARZEN E. On the estimation of a probability density function and the mode[J]. Ann Math Statist, 1962(33):1065-1067.
