中文文本分类中特征选择方法的改进与比较
2012-11-28田野,南征,郑伟,王星
田 野,南 征,郑 伟,王 星
(1.河北北方学院理学院,河北 张家口075000;2.复旦大学信息科学与工程学院,上海200433)
常用的特征选择方法有以下几种:文档频率方法 (DF)、信息增益 (IG)、期望交叉熵 (ECE)、χ2统计 (CHI)、文本证据权 (WET)等[1]。这些方法的基本思想都是对每一特征集词条,计算它的某种统计的度量值,然后设定一个阈值T,把度量值小于T的那些特征过滤掉,剩下的即认为是有效特征。以上是文本分类中比较经典的一些适合类内特征选择方法,实际上还有很多其他文本特征选择方法[2,3],如低损降维法、频率差法、基于特征贡献度的特征方法等。国内外很多学者对一些常用特征选择方法进行了对比研究,比较典型的有Y.Yang的特征降维实验[4],实验结果证明;在英文环境中,当IG和CHI等统计方法的计算费用太高而变得不可用时,可以安全地使用DF来代替它们。对于中文文本分类问题而言,代六玲等采用支持向量机 (SVM)和KNN两种分类器分别考查了不同的特征选择方法的有效性[5],实验结果表明,在英文文本分类中表现良好的特征选择方法MI在不加修正的情况下,并不适合在中文文本分类中进行特征选择,如何有效降低特征向量的维数,并尽量抽取有效带有类别信息的特征,是进行文本特征选择关键。
在文本分类系统中,有效的特征选择算法来降低特征维数的同时,不仅能够减少系统的代价和运行时间,而且能够提高分类的精度。因此,从大量候选特征中找出最优特征子集是十分必要的。
1 文本分类中特征选择方法的改进
如果一个词条能够带有只代表某一类的丰富类别信息,同时在其他类别中很少出现,那么该词条可选取作为对应类别的类别特征。为了最大效率的选取出能够代表各类类别信息的典型特征,采用对每个类训练文本集中分别选取代表此类的关键词条作为特征,这样按类来选取特征,特征的类别代表性将更强。为此,依据此思想对上述DF、ECE、CHI、WET特征选择算法进行了改进,改进后的特征选择方法如下:
1.1 文档频率 (DF)
从训练语料中分类别统计出包含某个特征的文档的频率 (个数),然后根据设定的阈值,当该特征的DF值小于某个阈值时,从特征空间去掉该特征项。

n(t,ci)为ci类中包含特征t的文档数,该方法优点是方法简单、易行、计算的复杂度低。
1.2 信息增益 (IG)
信息增益用来计算词条出现与不出现时对应的信息量差别,从而预测对类别的贡献。
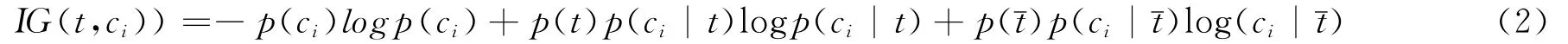
1.3 期望交叉熵 (ECE)
它既考虑了词频也考虑了词的出现与类别的关系。
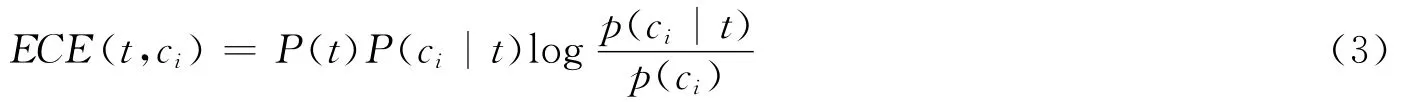
1.4 文本证据权 (WET)
文本证据权衡量给定类的概率与给定特征时类的条件概率之间的差别,它的定义为:
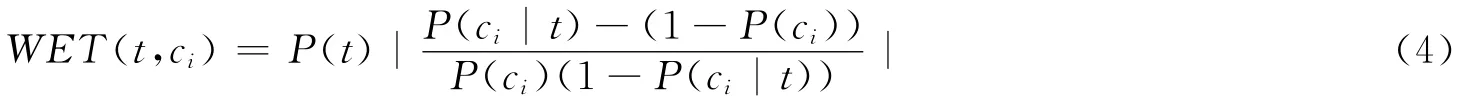
1.5 χ2 统计量 (CHI)
χ2(CHI)用来衡量特征词t与类ci之间的相互依赖关系的,如果t与类ci之间相互独立,那么特征t的CHI计算值为零。
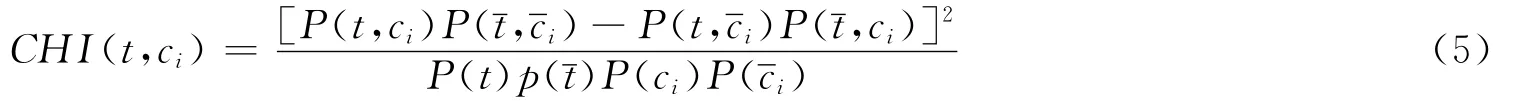
2 不同特征选择方法的比较
2.1 实验目的及实验设计
本实验目的是通过分类实验探讨在SVM分类算法下改进之后的5种类内特征选择方法对应的特征提取效果。
实验采用复旦大学收集的中文语料库,选用其中的5个类别:环境、交通、计算机、教育、医药,其中训练样本694篇,测试样本345篇,每个类别的训练语料大小均不相同。实验采用目前性能最好的分类器SVM用于分类,核函数使用线性核函数。
2.2 性能评价
实验采用宏平均准确率MacroP,宏平均召回率MacroR,宏平均MacroF1值作为评估指标,其中F1测试值综合考虑了文本分类的查准率与查全率,其具体计算公式如下:

2.3 实验结果及分析
图1是采用复旦大学语料,选择不同的特征提取方法和不同类内特征值数目时,对应的F1均值曲线。表1展示了每个特征选择方法的最佳分类效果。
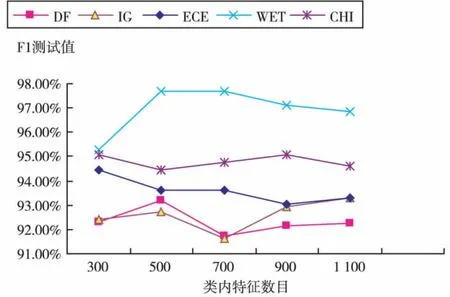
图1 改进后的不同特征选择方法分类结果
从图1曲线可以看出改进后特征选择方法特征提取效果最好的是WET方法,其次是CHI方法,在接下来是ECE方法,效果最差的是DF法,IG法表现也一般。
从图1和表1中可以看出WET法在每类抽取700维特征时,分类效果达到最佳值,其F1值为97.669%,分类效果好于DF、IG、ECE和CHI法,DF和IG法效果不是十分理想,原因在于DF法提取类内特征时考查高频特征词条,忽略了有价值的稀有低频特征词条,IG法原公式借助信息论考查词条t的出现与否对整个语料集的贡献度,理论上十分成熟,不适合用于单类别的考查。
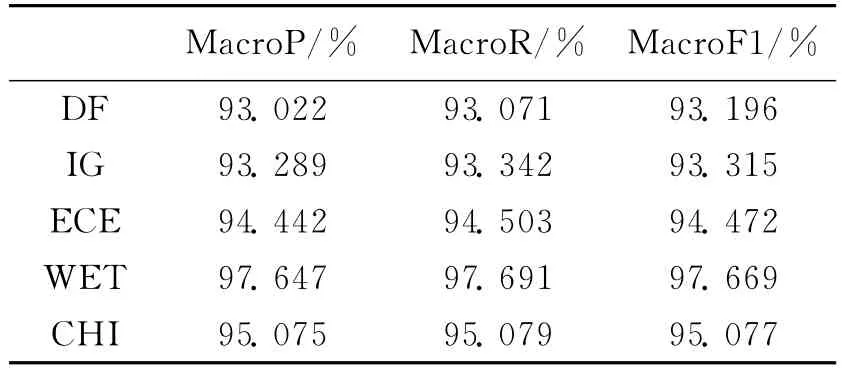
表1 改进后的不同特征选择方法最佳分类效果
3 结 论
本文通过分类实验考察了5种改进后的类内特征选择方法DF、IG、WET、ECE、CHI对特征提取质量的影响,实验结果表明:WET方法适合用于SVM分类中提取类内特征,特征提取效果较好;改进后CHI法特征提取效果次之,改进后DF和IG法不合适用于提取类内特征。本文的贡献在于为中文文本分类如何提取有效特征选择提供了指导和依据。
[1]郑伟,王锐.文本分类中特征提取方法的比较与研究 [J].河北北方学院学报:自然科学版,2007,23(06):51-54.
[2]寇苏玲,蔡庆生.中文文本分类中的特征选择研究 [J].计算机仿真,2007,36(09):197-199.
[3]孟佳娜.基于特征贡献度的特征选择方法在文本分类中的应用 [J].大连理工学报,2010,51(04):611-615.
[4]Yang YM,Pederson JO.A comparative study on feature selection in text categorization[A].Proceedings of the 14thInternational Conference on Machine learning [C].Nashville:Morgan Kaufmann,1997:412-420.
[5]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究 [J].中文信息学报,2004,18(01):26-32.
