可编程本体推理工具比较与分析
2012-11-14利业鞑
利业鞑
(广东司法警官职业学院,广东广州 510520)
可编程本体推理工具比较与分析
利业鞑
(广东司法警官职业学院,广东广州 510520)
设计了本体推理工具的评测指标、评测方法和评测系统,用于评测可编程本体推理工具(支持DIG和Jena接口)的推理准确性和性能.显示不同的本体推理工具在推理准确性和性能方面差别很大,因此在实际应用中选择本体推理工具时需要根据应用需求进行评估.
本体推理工具; 评测; 准确性
本体推理工具在知识获取和发现过程中有重要作用,当前有很多本体推理工具用于推理和从语义WEB中查询数据,这些本体推理工具由于实现的推理算法、优化技巧不同,因此在性能、效率和准确性方面差别很大.已有报道[1-6]对本体推理工具进行了评测,主要重点是评测推理工具在推理和查询的响应时间,以及对推理规则的支持能力等,没有涉及到对推理结果的准确性进行评测 (如概念分类的准确性).而在很多使用到本体推理以获取隐形知识的应用中,对推理结果的准确性有一定的要求;如在本体映射中使用本体结构来计算本体中元素之间的结构相似性,本体结构需要通过推理工具来获取,如果推理工具获取的本体结构不准确,则计算出的本体元素中的结构相似性也不正确.因此,本文设计了本体推理工具评测系统,用于评测可编程本体推理工具(支持DIG和Jena接口)的准确性.
1 评测指标和方法
1.1 评测指标
本体的主要特征包括概念层次性(概念包含关系)、特殊和一般关系(概念和实例)、部分和整体关系(概念和属性);在本体层次上,推理问题大体分为本体的一致性检查、类的可满足性检查、确定类之间的包含关系或层次关系、本体之间的蕴含关系检查等[7],因此我们设计了以下5个评测指标[8]:
(1)概念层次推理性能.推理工具计算概念之间的继承关系称为概念层次性推理,概念层次性推理的响应时间是衡量推理工具性能的一个重要指标,特别是在推理复杂的本体和大本体时响应时间显得更加重要.
(2)概念层次推理准确性.不同的推理工具由于采用的推理算法不同,因此计算出的概念层次性结果也不相同,为了衡量不同推理工具的推理准确性,需要选择一个比较基准.本文选择比较基准是protégé(版本3.4.7)中所显示的类层次关系;protégé软件是斯坦福大学基于Java语言开发的本体编辑和知识获取软件,是目前使用最广泛的本体编辑工具之一.类层次准确性的计算公式为:准确性=∑sameHiereEle∑classEle,其中sameHiereEle表示在本体结构中,层次结构相同(上级节点和下级节点均相同)的类数量,classEle表示类的总数量,如图1表示的本体A和本体B,类层次准确性=3(层次相同节点数)/9(总节点数)=0.33.
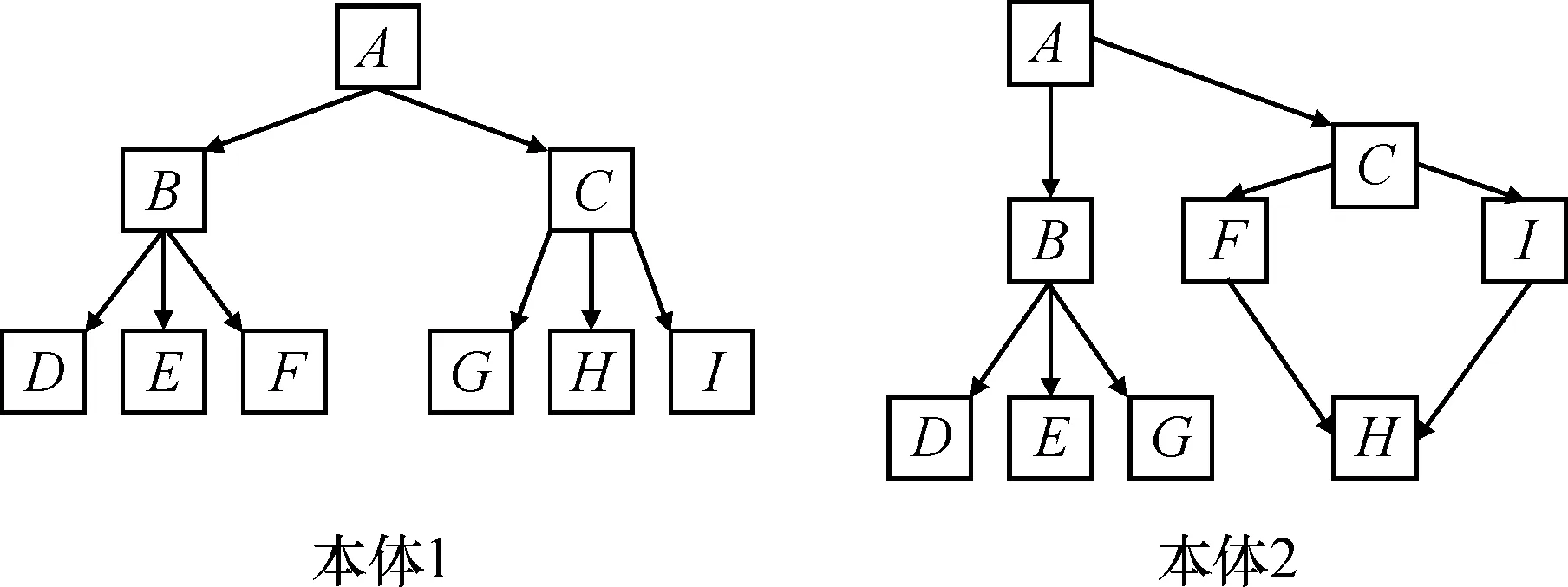
图1 2个本体结构图
(3)术语(TBox)一致性检查的性能.本体中一致性检查包括术语 (TBox)一致性检查和个体(ABox)一致性检查,本文只评测术语一致性检查的性能,大部分本体推理工具的术语一致性检查时基于Tableau算法.
(4)概念可满足性检查的性能.概念的可满足性检查是为了发现新定义的概念是否有意义或者相对于已定义的本体是否存在矛盾;概念之间的关系包括父-子关系和等价关系等.
(5)概念包含查询的性能.概念包含查询主要包括检查一个概念是否被另外一个概念包含或者获取一个概念包含的所有概念(包括直接包含和间接包含).
1.2 评测数据集
本文采用的评测数据集有以下3个来源:
(1)OAEI(Ontology Alignment Evaluation Initiative)使用的评测数据集.OAEI是ISWC(语义Web会议)中本体映射工作组举办的本体映射工具评测会议,主要是使用标准的评测数据集对参加比赛的本体映射工具在查全率、查准率和性能等方面进行比较.
(2)LUBM. LUBM[3]是Lehigh大学提出的语义Web数据测试集(基于大学这个领域),采用机器自动生成的数据作为测试数据,提供14个测试查询和一套性能指标,它可以根据用户指定的参数产生不同规模的数据.
(3)通过本体搜索引擎swoogle ( http://swoogle.umbc.edu / )随机选取的本体,主要是选择结构比较复杂的本体.
以上评测数据基本保证测评数据的一般性、广泛性和代表性.本文使用的评测数据见表1.

表1 评测数据Table 1 Evaluation data
1.3推理工具
选择可通过DIG接口和Jena接口访问的本体推理工具,便于通过编程进行自动评测.由文献[8]知,支持DIG接口的本体推理工具包括Pellet、Kaon2、RacerPro、Fact++和Ontobroker等5种,其中Ontobroker作为Ontoprise的一个组件,所以在评测时使用Hermit来代替.
本文评测的本体推理工具包括Pellet(版本2.2.0)、Kaon2(2008-06-29发布)、RacerPro(2.0试用版)、Fact++(版本1.5.2)和Hermit(版本1.3.5).
2 评测系统设计
本文中评测工具使用java实现,其中需要评测的本体推理工具以服务的方式启动,评测工具通过编程接口(DIG接口或Jena接口)连接服务器,发送推理或者查询请求给服务器并在前端处理服务器的返回结果,评测工具的主界面如图2所示,主要包括5个页面:
(1)设置页.选择本体推理工具并设置本体的URL地址.
(2)树状显示页.以树形结构显示类层次推理的结果(图3).
(3)图显示页.以图形的方式显示类层次推理的结构(图4、图5).
(4)结果页.显示推理任务的执行结果,如类层次推理的执行时间、本体一致性检查时间、类层次推理的准确率等.
(5)查询页.编写SPARQL查询提交给推理工具执行,显示查询的加载时间和执行时间.
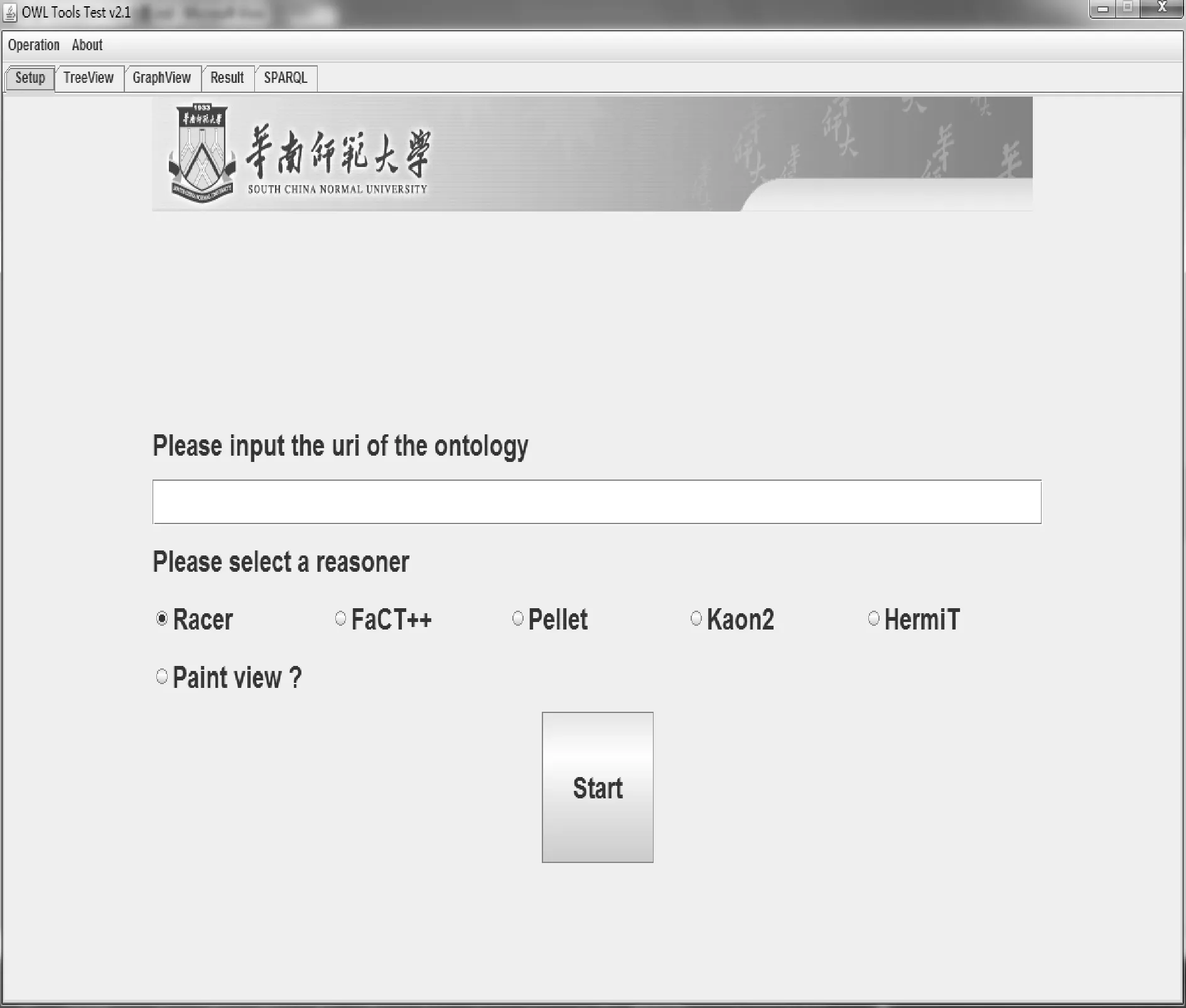
图2 评测工具主界面

图3 以树状图显示类层次推理结果
3 实验结果
本文的实验环境是Intel 双核 P3750 2.0 GHz,内存4 G,硬盘空间为250 G.
3.1概念层次推理
图6表示各推理工具运行类层次推理的执行时间,可以看出随着本体中类数量的增加,开始时(类数量小于3 000)推理时间增加并不明显,当本体中类数量达到一定规模时(如超过5 000)时计算时间大幅增加.在各推理工具中,Hermit的运行时间最短,Kaon2的推理时间最长;当本体中类数量比较多或类结构比较复杂时,Kaon2的计算时间是其他工具的10倍以上,所以在图6中并没有列出Kaon2的计算时间.

图4 Protégé中的类结构图

图5 RacerPro推理得到的类结构图

图6 计算类层次的计算时间
3.2 概念层次推理准确性
图7表示各推理工具运行层次推理的准确率,可以看到对相同的本体,不同推理工具计算出的准确率差别很大;对同一推理工具而言,计算不同本体得到准确率也差别很大(如Racepro,准确率最低的只有18%,最高的100%).经过分析发现,对结构比较复杂的本体(类之间的关系比较复杂的层次关系无法直接得到,如wine.owl),各推理工具得到的准确率均比较低(最低的31%,最高的42%),从图4、图5中可以明显看出推理工具退出的类层次结构和用作比较基准的protégé中类层次结构之间的差异.

图7 计算类层次的准确率
各推理工具关于概念层次推理的平均准确率如图8所示,可以看出,平均准确率最低的是Kaon2,最高的是Hermit.同时在计算过程中,各推理工具对本体文件中错误兼容性也不同,Kaon2和Fact++对错误的兼容能力相对比较差(Fact++的推理成功率是90%,Kaon2的推理成功率是70%).在对资源的占用方面各推理工具基本相同,只有Kaon2在资源的占用比较大,尤其是在推理结构比较复杂的本体时(如推理pizza.owl的类层次结构时至少需要占用1.5 G的内存).

图8 推理工具的平均准确率
3.3 概念可满足性检查
概念可满足性检查响应时间见表2,可以看出,概念可满足性检查响应时间差别比较大(对同一本体,比如NCI_ANATOMY最长的RacerPro为32 s,最短的FACT++为1.5 s),对概念可满足性检查来说,FACT++的响应时间最短,RacerPro响应时间最长;经过分析发现,由于RacerPro是将一致性检查和可满足性检查合并在一起考虑的,所以响应时间比较长.

表2 概念可满足性检查响应时间
3.4概念包含查询
本文使用“列出概念包含的所有概念”来构造SPARQL查询,如对NCI_ANATOMY本体,SPARQL查询部分的WHERE字句为” where {?s rdfs:subClassOf :NCI_C12229.}”,概念包含查询的结果见表3.

表3 概念包含查询响应时间
由于测评程序的原因无法测试Hermit,RacerPro和Fact++在执行概念包含查询时各有一次出错的情况,在图中以”-”表示.从结果可以看出,在执行概念包含查询方面,RacerPro和Kaon2的响应时间相对比较长(特别是对元素比较多的本体如swoogle_2,响应时间均在60 s以上);在针对大本体(如swoogle_2)的概念包含查询时,Fact++和Pellet的响应时间比其他本体工具要快很多(均为3 s左右),但Pellet比Fact++更稳定.
4 结论和展望
如何根据应用需求选择合适的本体推理工具是语义Web应用面临的一个共同问题,本文从概念层次推理、概念层次推理正确性、术语一致性推理、概念可满足性检查和概念包含查询等5个方面对目前常用的本体推理工具进行了比较分析.实验结果显示在推理本体中概念层次结构时,不同的推理工具在准确率方面差别很大;特别是推理层次结构负责的本体时,各推理工具得到的准确率均比较低.在评测的各推理工具中,Hermit在平均准确率、运行时间、复杂结构本体准确率方面均比较好,Pellet在平均准确率方面和Hermit相同,但稳定性和提供的接口类型比Hermit好(Pellet支持JENA接口、DIG接口并提供API);在术语一致性检查和概念可满足性检查方面,各推理工具的差别不大;在概念包含查询方面,Fact++和Pellet的响应时间比其他本体工具要快,但Pellet比Fact++更稳定.因此在实际应用中选择本体推理工具时需要根据应用需求进行仔细评估,以选择合适的本体推理工具.
本文设计的评测指标和评测系统只评测了概念层次推理的准确性,没有评估其他推理任务(如包含查询、对推理规则的支持等)的准确性,因此下一步的工作需要在评测系统中增加对其他推理任务的准确性评测,同时扩大对其他本体推理工具的评测.
[1] LEE Chulki, PARK Sungchan, LEE Dongjoo, et al. A comparison of ontology reasoning systems using query sequences[C]∥Proceedings of the 2nd international conference on Ubiquitous information management and communication. New York: ACM, 2008:543-455.
[2] GUO Yuanbo, PAN Zhengxiang, HEFLIN Jeff. LUBM: A benchmark for OWL knowledge base systems[J]. Journal of Web Semantics, 2005,3(2): 158-182.
[3] TOM Gardiner, IAN Horrocks, DMITRY Tsarkov. Automated benchmarking of description logic reasoners[C]∥2006 International Workshop on Description Logics. Windermere, Lake District, UK, 2006:1-8.
[4] BAIL Samantha, PARSIA Bijan, SATTLER Ulrike. JustBench: a framework for OWL benchmarking[C]∥Proceedings of the 9th international semantic web conference on the semantic web. Shanghai:Springer,2010:32-47.
[5] 徐德智.当前主要本体推理工具的比较分析与研究[J]. 现代图书情报技术,2006(12):12-15.
[6] DENTLER Kathrin, CORNET Ronald, TEN TEIJE Annette, et al. Comparison of reasoners for large ontologies in the OWL 2 EL profile[J].Semantic Web ,2011(1):1-17.
[7] 徐贵红,张健. 语义网的一阶逻辑推理技术支持[J].软件学报,2008,19(12):3091-3099.
[8] Wikipedia. Semantic reasoner [EB/OL]. (2012-01-23)[2012-02-05]. http://en.wikipedia.org/wiki/ Semantic_reasoner.
ComparisonandAnalysisofProgrammingOntologyReasoners
LI Yeda
(Guangdong Justice Police Vocational College,Guangzhou 510520,China)
A comparison method and evaluation system to compare the accuracy and performance of programming ontology reasoners (supporting DIG and Jena interface) are presented. Experimental results show that ontology reasoners are varied widely at accuracy, and therefore a critical assessment and evaluation of requirements are needed before selecting a reasoner for real-life applications.
2012-03-07
广东省政法网基金资助项目(ZFW2011011)
*通讯作者,guangdonglyd@163.com
1000-5463(2012)03-0059-05
TP393
A
10.6054/j.jscnun.2012.06.013
Keywords: ontology reasoner; evaluation; accuracy
【责任编辑 庄晓琼】
