基于衰退理论的Flickr热点事件检测方法
2012-10-15韩晓晖陈竹敏
薛 冉,马 军,韩晓晖,陈竹敏
(山东大学 计算机科学与技术学院,山东 济南250101)
1 引言
数码技术的飞速发展推动了照片由模拟到数字化的过程。借助于社交媒体(Social Media),网络用户可以将个人拍摄的数字相片以公开的形式上传到图像社区网站(如Flickr,Picasa,Webshots等)上,使得这类网站上积累了海量的图像数据。对这些海量图像数据的管理、解释和分析已经成为当前信息检索和数据挖掘领域的研究热点之一[1-3]。在图像社区网站中,很大比重的用户上传数据与现实中的各类事件相关(即,图片拍摄于特定事件发生时)。这些事件既包括流行的全局性事件,如世界杯足球赛、奥林匹克运动会等,也包括小范围的局部性事件,如私人聚会、婚礼等。基于这一特点,本文将研究在图像社区网站的海量数据上进行热点事件检测的方法。所谓热点事件,指在一定事件段内被广泛关注的事件,在图像社区网站中体现为用户上传的与之相关的数据较多的事件。本文的研究意义在于:一方面,以事件为单位对数据进行组织,并根据热度对事件排序,将很大程度上方便用户对图像数据的浏览和检索;另一方面,本文的工作有助于基于Web上的信息来研究和分析现实事件的变化发展,在舆情分析中将会产生重要的作用。
事件检测最初为话题检测与追踪(Topic Detection and Tracking,TDT)的子任务之一。在TDT中,事件定义为发生在特定时间范围和地点的某件事。传统的TDT研究目的是在连续的新闻文档流中识别新闻事件[4-5],其研究对象是文本文档。这类研究对于图像社区中的数据并不有效,这是由于图像社区中的数据与文本文档相比有着明显的差别和新特性:首先,并不是每一张图片都与事件相关联。其次,图像社区网站通常提供标注服务,用户可以为图片提供文本信息,如标签(Tag)、标题(Title)和描述(Description)。研究证明,由于有大量的用户参与,这些文本标注有一定的一致性和可信性[6]。但这些文本远稀疏于新闻文档中的文本,并且存在噪声。第三,很多图像数据还包含拍摄时间、地理位置等元数据。根据事件的定义,合理地利用这些信息将有利于提高事件检测的效果。近期,已有文献专注于Flickr数据上的事件检测研究[7-10],但是这些研究大都只利用了与图像相关的文本数据而没有考虑图像本身的内容,并且局限于回顾式的事件检测,即在历史数据上检测事件。而事件的发生和发展是随时间变化的,需要实时、在线的检测方法。
针对上述问题,本文提出了一种基于衰退理论的热点事件检测方法,以Flickr数据为检测对象。该方法首先从Flickr图像中提取视觉词汇并与图像的文本信息结合构成文档,使用LDA模型将文档映射到主题空间形成文档的向量表示。使用改进的Single-Pass算法进行事件检测,该算法在事件检测过程中考虑了文档的地理位置信息。在事件检测过程之后,进一步检测出当前时间段的热点事件。热点事件是一个与时间相关的概念,随时间的变化而不断改变。因此本文基于衰退理论(Aging Theory)对检测到的事件进行生命周期建模,计算事件在每个时间段的能量值,能量值反映事件的热度。最后,根据能量值进行事件排序,获得给定时间段内的热点事件。
区别于以往的工作,本文的贡献在于:
1)在数据表示时同时考虑了图像本身的信息和与图像相关的文本信息,利用LDA模型将二者融合;
2)在事件检测中通过使用衰退理论和地理位置信息使得事件检测算法同时在时间和空间维度进行;
3)所提出的方法是一种实时的在线方法,将Flickr数据看作数据流,事件检测的输出随时间而变化;
4)将事件按热度排序,能使用户优先关注最为重要的信息,更加利于用户浏览。
本文余下部分的组织结构如下:第2节介绍与本文相关的研究工作;第3节讲述Flickr数据的表示方法;基于衰退理论的事件检测方法在第4节给出;第5节给出实验,分析了新方法的性能和效果;第6节总结全文并展望未来的工作。
2 相关工作
在TDT领域,热点事件检测研究已经取得了很大程度的进展。很多学者在事件发现过程中考虑到了特征词和事件在时间上的突发性。文献[11]认为同一个查询词可能与若干事件相关联,每一个事件又可以被划分成更小的事件。首先根据时间和文档的内容识别突发特征词,然后基于时间提取与突发特征紧密相关的文档,最后将这些文档归到事件,并以层次结构组织。文献[12]以主题句子表示事件,给定一个文集和查询q,首先得到与q相关的句子集合,并确定这些句子的时间,将句子按照时间排序,计算句子的兴趣度,最后得到表示事件的主题句子;文献[13]将事件和特征分为:周期性和非周期性的,重要的和极少报道的。认为事件由具有代表性的特征描述,同一事件的特征在时间上的分布相近。将特征在时间上的变化表示成向量,进而对特征进行分类。用分布相近的特征词还原事件;文献[14]提出了几个新的突发向量空间模型(B-VSM)。突发向量模型考虑了文档中候选词在文档发表时的突发性。一个突发的主题可以被一个突发的词集合表示,将单个词的突发性结合入向量表示模型,在每一时刻,对于突发词的权重加一个突发值,可以加强相似突发主题的内聚性,从而可以提高事件检测的质量。另有研究从仿生学角度进行热点话题发现,文献[15]提出了事件的衰退理论,将话题的发展过程看作是一个由诞生、发展、衰退并最终消亡的过程。文献[16]利用了衰退理论和TF-PDF模型,通过时间线分析和多维句子建模来识别热点话题。文献[17]指出用户对于话题的关心程度也是话题热度的一种反映,因此从衰退理论媒体报道的角度和用户关注的角度分别模拟话题的生命状态,将二者结合来找到热点话题。
上述研究均将新闻文档作为处理对象。近期,一些研究利用社会媒体网站中的数据进行事件检测。其中,部分研究在Flickr数据上进行。文献[7]利用Flickr用户提供的标记、标题和描述信息,提出一种新的图片分类方法,将图片按照事件进行分类。文献[8]利用Flickr中存在的文本信息,挖掘不同类型文本特征的表示形式来学习特征之间的相似度矩阵,以此进行事件检测。文献[9]提出了一种基于小波分析的算法对Flickr上的事件进行检测。该方法将图像的元数据(时间、地理位置)映射到三维空间,通过小波分析来获得标签的使用分布规律,以此进行标记聚类来发现事件。文献[10]通过分析Flickr中图像数量的变化来预测事件发展的趋势。然而,上述方法局限于仅仅利用了与图像相关的文本信息,而忽略了图像本身的内容。此外,文献[9]的方法属于回顾型的事件检测方法,并不具有实时性。
3 融合视觉和文本信息的数据表示
本节介绍如何对Flickr中的数据进行表示。本文将一幅图像及与其相关的文本信息(标记、标题和描述)视为一篇完整的文档,该文档由视觉词汇和文本词汇构成。视觉词汇通过对从图像中提取的SIFT描述子进行聚类得到。借助LDA模型将文档内容映射到主题空间,每一篇文档用其主题分布向量表示,作为事件检测算法的输入。
3.1 LDA基本理论
LDA(Latent Dirichlet Allocation)模型[18]假设文本集合中的每个文档是多个隐含主题z∈[1,K]的混合,每个隐含主题是分布在词汇表上的多项式分布(Multinomial Distribution),可由一组出现概率最高的词汇来描述。LDA的图模型表示如图1所示,可观察到的数据是每个文档中的词,隐含变量表示了潜在的主题结构。文档和词之间没有直接的联系,而是通过隐含变量z链接。
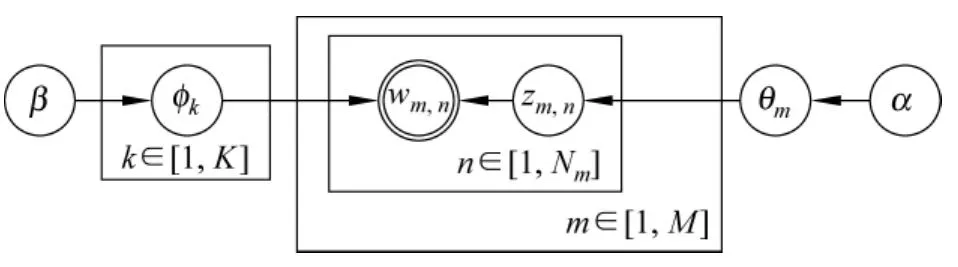
图1 LDA图模型
LDA模型假设文档中词汇的生成过程如下:
1)从参数为α的Dirichlet先验分布Dir(α)中为每个文档m∈[1,M]抽取多项式分布θm,共抽取M个;
2)从参数为β的Dirichlet先验分布Dir(β)中为每个主题k∈[1,K]抽取多项式分布φk,共抽取K个;
3)对于文档m中的第n个词:
(a)根据多项式分布θm确定一个主题zm,n=k。
(b)根据多项式分布φk产生一个词wm,n。
其中M为文档集合中文档的数量,K为隐含主题的数量,α、β为已知参数,θm和φk为需要估计的变量。θm为一个K 维的向量,表示文档m在主题上的后验概率分布,其第k维θ(k)m表示P(z=k|dm);令V为词汇表中词汇的数量,φk为一个V 维的向量,表示主题在词汇上的后验概率分布,其第i维φk(i)表示P(wi|z=k)。
直接使用EM算法通过最大化整个数据集合的似然度来估计θ和φ是比较困难的,本文采用了Gibbs采样法[19]来近似地估计参数。Gibbs采样是马尔可夫链-蒙特卡罗方法的简单实现形式,目的是构造收敛于目标概率分布的Markov链,从链中抽取被认为接近该概率分布值的样本。对于文档dm中给定的观察词wi,通过固定dm中其他词的主题分配(z-i),来计算wi被分配各种主题的后验概率P(zi=j|z-i,wi,α,β),计算公式如下:

其中,wi不仅代表词汇w,而且与该词在的文本中的位置相关,因此称其为词汇记号;zi=j表示将词汇记号wi分配给主题j,z-i表示所有wk(k≠i)的分配。是与wi相同的词汇被分配给主题j个数是分配给主题j 的所有词汇 的个数是文档dm中被分配给主题j的词汇个数是dm中所有被分配了主题的词汇个数;所有的词汇个数均不包括当前zi=j的分配。
采样过程首先为每个词汇指派[1,K]之间的一个随机主题,构成初始的Markov链,然后每次迭代根据式(1)为词汇重新分配主题,得到Markov链的下一个状态;迭代足够的次数后,Markov链达到稳定状态,取zi的当前值作为样本记录下来。以w表示词汇表中一个唯一性词,θ和φ 的值由式(2)估计:
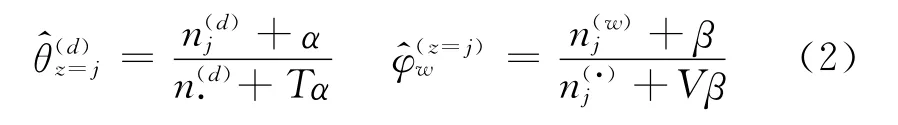
3.2 数据的向量表示
一篇Flickr文档由一幅图像以及用户标注的文本信息组成。首先使用BOW模型(Bag of Words)建立对文档的描述。BOW模型最初应用于文本处理领域,目前已广泛应用在场景分类等计算机视觉领域[20]。在BOW 模型中,文档被看作是装满了词语的袋子,忽略词语间的顺序和句法,每个词的出现都独立于其他词的出现。因此,一篇Flickr文档可以看作为一个集合D={VW,TW},其中VW为视觉词语(Visual Words)的集合,TW为文本词语的集合。
视觉词语通过从图像中提取SIFT(Scale Invariant Feature Transform)特征[21]描述并聚类获得,具体过程如下:
1)对每幅图像使用DoG(Difference-of-Gaussians)点检测器在不同的尺度和位置进行采样,将检测到的极值区域表示为SIFT描述子,每一个SIFT描述子为128维的特征向量。
2)设定视觉词典的大小Vvisual,使用K-Means算法对所有描述子进行Vvisual个簇的聚类,当KMeans收敛时,可以得到了每一个簇最后的质心,则这Vvisual个质心即为视觉词典中的词,每个视觉词语描述图像的一个局部模式,词典构建完毕。
3)将图像中的每个SIFT描述子映射到与其距离最近的视觉词语,这样每幅图像都可以视为由一系列的视觉词语构成。
文本词汇由与图像关联的文本信息获得。这样每幅图像又可以表示成一个由视觉词语和文本词语的频数组成的维数固定的初始向量dori。
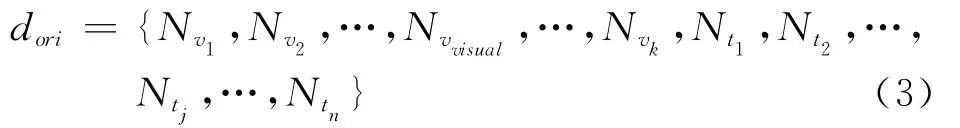
其中,Nvi表示视觉词汇vi在文档中出现的次数,Ntj表示文本词汇tj在文档中出现次数,n为文本词典中词汇的个数。观察发现,在一片Flickr文档中,文本词汇通常比较稀疏。虽然部分描述数据的词汇量比较丰富,但有相当一部分的文档没有描述部分。为平衡图像信息和文本信息在事件检测算法中的作用,这里通过对文本特征加权的方式来加强文本信息的影响力。对每一个文本词汇在文档中的出现次数Ntj赋予相同的权重ω,使得Ntj的值为原来的ω倍,则文档的加权向量表示为:
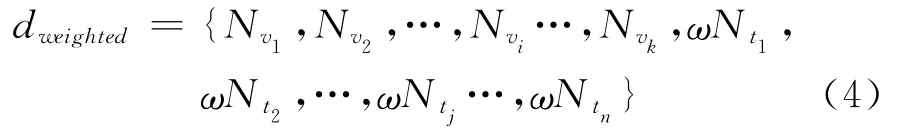
这种简单的向量表示并不能很好地将两类信息融合,本文使用LDA模型将一篇Flickr文档中的内容映射到主题空间来实现两类信息更好的融合。过程以Flickr文档集合的加权向量表示作为输入,对LDA模型进行估计。过程完成后,可以得到参数θ和φ的估计值。以每一篇文档dm的主题分布θm作为该文档的最终向量表示,即
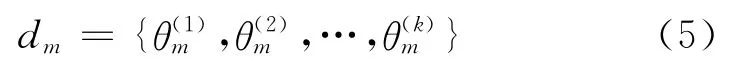
该向量为热点事件检测算法的输入数据形式,整个数据表示处理过程如图2(见下页)所示。
一个事件e为一个Flickr文档的集合,使用e的质心向量作为其向量表示,即:

其中向量dm表示属于事件e的一篇文档,Ne为属于事件e的Flickr文档的数量。
4 基于衰退理论的热点事件检测
本节介绍所提出的基于衰退理论的热点事件检测算法。算法是对Single-Pass聚类算法的改进,在事件检测过程中将地理位置信息作为判断条件之一;同时,结合衰退理论为已检测到的事件进行生命周期建模,计算事件的能量值,并将能量值作为事件热度的评价标准。基于上述两点改进,使得算法同时考虑了空间和时间维度的信息,从而能够提高事件检测的效果。

图2 数据表示处理过程
4.1 衰退理论
衰退理论[15]将事件看作为一个生命体,经历着产生、成长、衰退和消亡的过程。当与事件相关的第一篇文档出现时,事件产生。相关文档可以视为事件生命体的“食物”,随着这些文档不断地出现,事件生命体从这些食物中汲取“营养”,伴随着自身能量值的改变。能量值可以反映事件所处的生命阶段(即,事件的热度),高能量值表明事件处于热门时期,低的能量值表明事件处于衰减阶段。事件在通过汲取“营养”增强能量值的同时,也会有固定值的能量自然衰减。当相关文档越来越少出现时,能量的衰减大于新获取的能量,事件生命体处于衰退阶段。当相关文档不再出现时,事件生命体走向消亡。
具体的,首先将时间线划分为长度为s(本文试验中,s为1天)的时间段(time slot),对于每个时间段,定义以下三个函数来计算和更新事件的能量值:
1)getNutrition():计算事件从一个相关文档中获得的营养值。
2)energyFunction():能量函数,用于将积累的支持值转变成能量值。该函数必须满足三个条件约束:
(a)0≤energyFunction(x)≤1
(b)energyFunction(x)是x的一个单调递增函数;
(c)energyFunction(∞)=1,energyFunction(0)=0;
能量函数将范围无限的营养值积累转换到一个有限的能量值范围内[0,1],目的是能够更好地解释话题所处的状态。其反函数energyFunction-1()将能量值转换为营养值。本文使用Sigmod函数作为能量函数:

3)eneryDecay():计算了在每个时间段内话题能量的衰减。
在每一个时间段i,每一个已知事件的能量按照以下步骤进行更新:
1)将i-1时间段的能量值转换为营养值:Nutritioni-1=energyFunction-1(Energyi-1);
2)将i时间段获得的营养值累加到i-1时间段的营养值中:Nutritioni=Nutritioni-1+Nutritioni;
3)将i时间段Energyi=energyFunction(Nutritioni)。
4.2 热点事件检测算法
根据事件的定义,与同一事件相关的Flickr文档应在地理位置信息上有一定的相似性,并且在时间上应当有相近性和连续性。本文改进了传统TDT研究中使用最多的Single-Pass算法,在事件检测中利用了Flickr文档中所包含的GPS地理位置信息和拍摄时间信息,以确保所检测出的事件中的文档都满足上述两个约束。此外,在算法中嵌入衰退理论的思想,可以通过计算能量值获得给定时间段的热点事件。详细的热点事件检测过程如算法1所示。
算法1为一种实时在线的方法,将Flickr数据看作是随时间推移而源源不断有新文档到达的文档流。对时间段i到达的每一篇文档d,算法1首先获得d的地理信息,并将其地理位置信息与所有已检测到事件ej的地理位置范围进行比较,如果二者差异小于一个阈值δ,则将ej加入候选事件集合Ecandi(算法6~11行)。如果Ecandi不为空,则在Ecandi中找到与d最相似的事件e。如果d与e之间的相似度大于一个阈值thresholddetect,则将文档归入事件e。更新e的向量,并按照4.1节所述方法更新e的能量值(算法15~19行)。其中,d对事件e的营养值贡献由其与e的相似度sim(e,d)确定;γ为转换因子,指明新获得的营养中有多少被事件e所吸收。同时,更新e的地理位置范围(算法21~25行)。如果相似度小于阈值thresholddetect或者Ecandi为空,则创建一个新的事件,将d加入新创建的事件(算法26~35行)。在每一个时间段内事件的能量值减少固定的量λ(算法41行),λ称为衰减因子。当没有或者只有少量图片加入到事件中时,当能量值为0时,事件就被认为“消亡”并且从事件集合E中移除(算法39~47行),以此来确保相同事件中的文档在时间上的相近性和连续性。
在每一时间段,算法在执行完上述过程后都对当前事件集合E中的事件根据热度进行排序(算法48行),然后将热度最高的Top N个事件作为热点事件输出(算法49行)。


4.3 相似度计算
一篇Flickr文档对于一个事件的营养值贡献由二者之间的相似度确定。本文利用KL散度来计算Flickr文档与事件之间的相似度。对于Flickr文档di和事件ej,它们的向量表示分别为θi和θj,则它们之间的相似度按照式(8)计算。
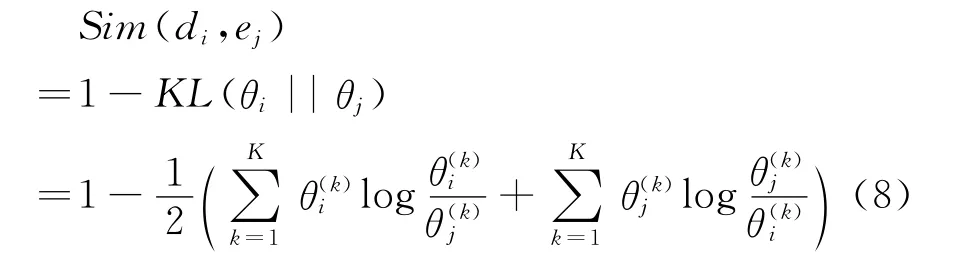
4.4 结果事件表示
为了能够以直观的形式展示事件检测的结果,对于一个已检测到的事件ei,使用四元组<CP(ei),TT(ei),LR(ei),TR(ei)>来对其进行表示,其中:
1)CP(ei)(Central Photo):与事件ei相关的Flickr文档中距离ei的质心最近(使用KL散度计算)的文档中的图像,形式化表示如式(7)所示,其中Ci是ei的质心,为一个k维的向量。

2)TT(ei)(Top Tags):在事件i所包含的文档中TF-IDF值最高的N个词的集合。
3)LR(ei)(Location Region):事件的地理分布范 围,即 LR(ei)= {[Minlo(ei),Maxlo(ei)],[Minla(ei),Maxla(ei)]}
4)TR(ei)(Time Region):事件所经历的时间范围,即TR(ei)=[Mintime(ei),Maxtime(ei)]。
5 实验分析
5.1 数据集建立
由于Flickr中的图片数量十分巨大,本文只收集了“体育”领域的数据作为实验数据集。我们以“sport”、“football”、“soccer”、“basketball”、“tennis”、“baseball”等体育常用词汇作为查询词,通过使用Flickr提供的API获取了2010年6月1日~2011年3月31日之间带有GPS信息的图片。对于每幅图片,除获取图片本身外,同时还获取了与之相关的文本信息,包括Tags,Title和Description。所获取的数据集共有130 897幅图片,其详细的统计信息如表1所示。

表1 数据集的统计信息
数据集由志愿者人工进行事件标注,标注结果中共包含了325个区分度较为明显的事件,另外有一部分图片并不适于分派给任何事件。这些事件中相关文档最多的事件包含4 802篇Flickr文档,最少的包含59篇Flickr文档;时间跨度最长的事件持续217天,最短持续1天。之后数据集被分为训练集和测试集两个部分。其中,训练集由2010年6月~2010年10月的数据组成,共包含191个事件。测试集由2011年10月~2011年3月的数据组成,共包含134个事件。训练集的主要作用如下:
1)提取视觉词汇。即使用训练集的数据建立图像的视觉词典。
2)训练LDA模型。使用训练集的数据对LDA模型进行参数估计,在获得参数θ和φ之后,对于测试集中的数据Gibbs采样的次数可以远低于参数估计时的采样次数,一般20~30次迭代就足够。因此,可以保证算法的实时性。
3)训练衰退模型的参数。即算法1中的γ和λ的值,采用文献[15]中给出的方法解得。
5.2 实验建立
实验共分为三个步骤。第一步为数据表示和参数估计。首先使用训练集建立视觉词典,视觉词典的大小设为200。然后,建立LDA模型用来进行图像信息和文本信息的融合。LDA的超参数取经验值α=0.5,β=0.1,Gibbs采样次数设为1 000次,主题的数目K=30。最后,使用训练集中的两个事件来获得热点事件监测算法中γ和λ的值,过程重复10次,取10次结果的平均值。
实验的第二步使用测试集验证事件检测算法的有效性。首先,测试在算法中加入地理位置信息和衰退理论是否能够提高事件检测的效果。参与比较的方法有原始Single-Pass算法(标记为SP),加入地理位置信息的算法(标记为SP+G),加入衰退理论的算法(标记为SP+A)以及本文提出的算法1(标记为SP+G+A)。然后,测试融合图像信息和文本信息的数据表示是否对事件检测算法有效,我们采用不同方法对数据进行表示,参与比较的方法有仅使用视觉词汇的TF-IDF向量表示(标记为VV),仅使用文本信息的TF-IDF向量表示(标记为TV),同时使用图像和文本词汇的TF-IDF向量表示(标记为VTV)和基于LDA的表示方法(标记为LDA)。
使用平均精确率(Precision)、召回率(Recall)和F1值作为事件检测结果的评价测度。然而,由算法得到的事件数量与人工标注的事件数量可能不相等,当结果的事件数目小于人工标注的事件数目时,对于结果中的每一个事件在人工标注的事件中找到与该事件包含相同文档的数量最多的一个,作为其真值事件参与评测;当结果事件的数目大于人工标注的事件数目时,对于每个人工标注的事件在结果事件中找到与其包含相同文档数量最多的事件,作为对应的检测结果参与评测。设有C个簇(事件)参与评测,令TPi表示分到事件i(i≤C)且结果正确的文档数目,FPi表示分到事件i但结果错误的文档数目,FNi为属于事件i但没有被分到事件i的文档数目,则:

准确率越高,算法在该事件上的错误率越小;查全率越高,则漏掉的相关文档越少;F1值将两者赋予同样的重要性来综合评价。实验取所有测试事件的结果平均值作为最终结果。
实验的第三步,通过算法在数据集上的运行结果,验证使用衰退理论为事件建立生命周期模型对于热点事件检测的有效性。
5.3 结果分析
实验在一台12核双CPU,12GB内存的服务器上完成。通过训练集得到的参数值分别为γ=0.479 31,λ=0.287 45。此外,通过多次实验发现参数ω=2,thresholddetect=0.231,δ=8.0时得到的结果较好。
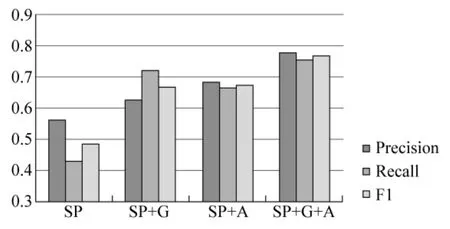
图3 地理信息和衰退理论对结果的影响比较
图3展示了是否加入地理位置信息和衰退理论对事件检测结果的影响。可以看出,在所有测度上,加入地理位置信息或衰退理论,得到的结果都优于仅使用Single-Pass算法。而本文提出的热点事件检测算法取得了最优的效果。单独使用Sing-Pass算法在三个测度上的值都非常低,这是由于与同一类事件相关文档在视觉和文本信息上都有很大的相似性,如与足球相关的Flickr文档的图像中大部分都会出现绿色草坪,文本中会出现“coach”、“Field”等词,导致难以很好的区分事件。单独加入地理位置信息,对结果有一定的提升。与SP+A相比,SP+G的精确率较低,这是因为由于没有时间条件,SP+G会将相隔时间很长,但在内容和地理位置上都相似的文档归为同一事件。而SP+A的召回率略低,经分析发现这是由于该方法容易漏掉一些属于某事件,但在视觉上与该事件内大部分文档相似性较低的文档。而本文提出的方法(SP+G+A)通过空间维度和时间维度的结合,精确率和召回率均优于二者。

图4 不同数据表示对事件检测结果的影响
图4展示了不同数据表示方式对于事件检测结果的影响。可以看出,单独使用视觉词汇表示文档的效果最差,原因如前面所述,这是由于与同一类事件相关的文档在视觉上的可区分性较差。单独使用文本词汇得到的结果要好一些。将视觉词汇和文本词汇结合表示成为TF-IDF向量,所得到的结果要优于单独使用一种词汇。而本文提出的数据表示方法,即通过LDA将文档内容映射到主题空间,在所有测度上均取得了最优的结果。
图5(a)展示了事件“世界杯”在2011年6月1日~2011年7月20日之间的生命周期模型变化曲线。该事件在6月11日之前的能量值非常低,在6月11日世界杯开幕时,能量值有一个明显的上升阶段。此后,能量值的变化基本平稳并呈逐渐趋势,在7月11日~7月13日世界杯决赛期间,能量值达到了最大值,之后逐渐地以能量衰减为主。图5(b)为事件“澳大利亚网球公开赛”在2011年1月15日~2月7日之间的生命周期模型变化曲线。公开赛在1月17日开始至1月30日结束,从曲线可以看出,该事件的生命值在比赛开始时间呈上升趋势,随后达到稳定,在公开赛全部结束后,该事件逐渐走向消亡。图5(c)为事件“NCAA美国大学橄榄球赛”的生命周期模型变化曲线,该事件历时5个月,在2010年9月1日开赛后,生命值逐渐增加并达到一个长期较为稳定的状态,在2011年1月决赛之后,事件逐渐消亡。显然,本文提出的热点事件算法可以很好地在Flickr数据上为事件的发展变化建模。从图5中也可以看出短期事件(图5(a)、(b))和长期事件(图5(c))在生命周期变化上的差别。短期事件的生命周期一般在经过一个“上升—最大值—下降”的过程后结束,而长期事件会经历一个生命值的长期稳定阶段,期间伴随着生命值的小幅波动。

图5 事件生命周期图
最后,表2给出了热点事件发现的一个结果展示。该结果列出了2011年6月4日热点事件输出结果(Top N=5),每个事件以4.4节给出的方式进行表示。这5个事件自上而下分别为“Hoogerheide自行车世界锦标赛”,“2010-2011英超联赛”,“喜力杯欧洲橄榄球联赛”,“澳大利亚网球公开赛”和“奥迪杯雪橇世界杯比赛”。由于没有标准化的测度,因此很难评价热点事件检测结果的优劣。尽管如此,我们请3位志愿者对多个时间段的热点事件检测结果进行了人工评价,志愿者均认为大部分的结果具有很高的合理性。

表2 2011年1月23日热点事件
6 结语
本文提出了一种基于衰退理论的Flickr热点事件检测方法。该方法将FLickr中的图片与用户提供的文本信息(标题、tag、描述)视为一篇文档,采用加权的方式增强文本信息在文档中的影响。利用LDA模型计算每个文档的隐含主题分布,作为文档的向量表示。提出了一种改进的Single-Pass算法进行事件检测,该算法首先根据内容相似度判断文档与已有事件的相似性,然后根据地理位置信息最终确定文档是否属于已有事件。使用衰退理论为每个事件进行生命周期建模,从而获得事件在每个时间段的能量值。以能量值为依据对事件进行排序,从而输出给定时间段内的热点事件。实验结果表明,通过结合内容、视觉和空间三维的信息,可以改善事件检测算法在Flickr数据集上的性能。此外,本文提出的方法可以有效地检测出给定时间段内的热点事件。我们以后的研究工作将专注于对多模态信息更加有效的融合。同时,更为高效的在线事件检测方法也是值得研究的问题之一。
[1]Melanie Aurnhammer,Peter Hanappe,LucSteels.Integrating Collaborative Tagging and Emergent Semantics for Information Retriveal[C]//Proceeding of WWW’06.New York:ACM Press,2006.
[2]Xirong Li,Cees G M Snoek,Marcel Worring.Learning Tage Relevance by Neighbor Voting for Social Image Retrieval[C]//Proceeding of the 1st ACM International Conference on Multimedia Information Retrieval.New York:ACM Press,2008:180-187.
[3]Eva Horter,Rainer Lienhart,Malcolm Slaney.Image Retreival on Large-Scale Image Database[C]//Proceeding of the 6th ACM International Conference Image and Video Retrieval.New York:ACM Press,2007:17-24.
[4]J Allan,R Papka,V Lavrenko.On-line new event detection and tracking[C]//Proceedings of the 21st Annual International ACM SIGIR Conference,Melbourne,Australia.ACM Press,1998:37-45.
[5]T Brants,F Chen,A Farahat.A System for New E-vent Detection[C]//Proceedings of the 26th Annual International ACM SIGIR Conference,New York,NY,USA.ACM Press.2003:330-337.
[6]H Halpin,V Robu,H Shepherd.The complex dynamics of collaborative tagging[C]//Proceedings of the 16th International Conference on World Wide Web.New York:ACM Press,2007:211-220.
[7]Claudiu S Firan,Mihai Georgescu,Wolfgang Nejdl,et al.Bringing Order to Your Photos:Event-Driven Classification of Flickr Images Based on Social knowledge[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.New York:ACM Press,2010:189-198.
[8]Hila Becker,Mor Naaman,Luis Gravano.Learning Similarity Metrics for Event Identification in Social Media[C]//Proceedings of 3rd ACM International Conference on Web Search and Data Mining.New York:ACM Press,2010:291-300.
[9]Ling Chen,Abhishak Roy.Event Detection from Flickr Data through Wavelet-based Spatial Analysis[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management.New York:ACM Press,2009:523-532.
[10]Xin Jin,Andrew Gallagher,Liangliang Cao,et al.The Wisdom of Social Multimedia:Using Flickr For Prediction and Forecast[C]//Proceedings of the International Conference on Multimedia.New York:ACM Press,2010:1235-1244.
[11]G P C Fung,J X Yu,H Liu,et al.Time-Dependent Event Hierarchy Construction[C]//Proceedings of KDD2007,California,USA,2007:300-309.
[12]H L Chieu,Y K Lee.Query Based Event Extraction along a Timeline[C]//Proceedings of the 27th Annual International ACM SIGIR Conference,Sheffield,UK,ACM Press.2004:425-432.
[13]Q He,K Chang,E P Lim.Analyzing Feature Trajectories for Event Detection[C]//Proceedings of the 30th Annual International ACM SIGIR Conference,Amsterdam,the Netherlands.ACM Press.2007:207-214.
[14]Q He,K Chang,E P Lim.Using Burstiness to Improve Clustering of Topics in News Streams[C]//Proceedings of the 7th IEEE International Conference on Data Mining,2007:493-498.
[15]C C Chen,Y T Chen,M C Chen.An Aging Theory for Event Life-Cycle Modeling[J].IEEE Transactions on Systems,Man,and Cybernetics-Part A:Systems and Humans,2007,Vol.37,No.2.
[16]Kuan-Yu Chen,Luesak Luesukprasert,Seng-cho T.Chou.Hot Topic Extraction Based on Timeline Analysis and Multidimensional Sentence Modeling[J].IEEE Transactions on Knowledge and Data Engineering,IEEE Computer Society,2007:1016-1025.
[17]Canhui Wang,Min Zhang,Liyun Ru,et al.Automatic Online News Topic Ranking Using Media Focus and User Attention Based on Aging Theory[C]//Proceeding of CIKM’08,ACM,California,USA.2008:1022-1042.
[18]D Blei,A Ng,M Jordan.Latent Dirichlet Allocation[J].JMLR,2003,3:993-1022.
[19]T L Griffiths,M Steyvers.Finding scientific topics[C]//Proceedings of the National Academy of Sciences of the USA.USA:PNAS Press,2004:5226-5235.
[20]Bosch A,Munoz X,Marti R.Which is the best way to organize/classiy images by content?[J].Image and Vision Computing,2007,25(6):778-791.
[21]Lowe DG.Distinctive image features from scale-invariant keypoints[J].Int’1Journal of Computer Vision,2004,60(2):91-110.
