基于帧填补的MMM Clos网络按序分组交换算法
2012-07-25邱智亮张茂森
高 雅 邱智亮 张茂森 黎 军
①(西安电子科技大学综合业务网理论及关键技术国家重点实验室 西安 710071)
②(空间微波技术国家重点实验室 西安 710100)
1 引言
Internet的持续爆炸性增长促进了可扩展快速交换结构的研究。Clos交换网络由于其在模块化和可扩展性方面的潜能,在构建大容量多端口交换网络的研究中受到越来越多的关注。Clos网络交换结构可以分为两类:无缓存 Clos网络和有缓存 Clos网络。无缓存 Clos网络,也称为空分交换结构(Space-Space-Space, SSS)。SSS Clos网络的交换模块设计简单,但交换时需要的配置相当复杂[1],这是由于每个时隙在信元传输之前都要解决输出端口竞争和路径选择的问题。为减少配置时间,通常在输入级和输出级模块设置缓存。依据中间级模块是否存储信元,将带缓存的Clos交换网络分为两类:MSM(Memory-Space-Memory)型 Clos网络和MMM型Clos网络。MSM Clos网络在输入级和输出级需要缓存加速,交换模块端口数越大,需要的缓存加速越高,这将极大限制MSM型Clos交换网络的应用范围。MMM型Clos网络不需要缓存加速,但是中间级缓存的存在会引起输出端口的信元乱序。乱序转发就需要在输出端口进行信元重排,这在缓存和分组处理上将带来极大消耗。
设计一个按序高效的交换网络调度方案是MMM 交换的研究重点。文献[2]提出了一种具有信元保序能力的三级Clos分布式调度算法——负载分配并发式调度算法。该算法首先按轮询方式选择一个中间级模块(Central Module, CM),然后根据该CM 的排队情况计算得到本时隙的调度匹配,并将结果广播给其它CM。这种方式下要求CM间有总线相连,通信开销较大。输出级模块(Output Module,OM)采用迭代式最早信元顺序输出调度算法,计算和通信代价比较高。TrueWay[3]是一种多平面MMM交换,可提供信元按序传递。该交换采用散列(hashing)函数为每个流选择平面和中间模块,这样一个流的信元遵循同一条路径。但是为达到较高性能,TrueWay需要1.6倍的缓存加速。MMM-IM算法[4]在信元进入输入模块(Input Module, IM)后加时间戳,分组选择CM是依据逐流设置的指针,以保证每个流均匀分布到中间级各模块。一个流的前一个分组离开CM时,需要向IM反馈流信息,这样同一个流的下一个分组才能发送到 CM。由于算法维序是通过逐分组反馈,复杂度较高,并且达不到100%吞吐率。
同样存在分组乱序问题的是基于负载均衡的两级交换结构。至文献[5]首次提出负载均衡交换的概念,这一领域获得了大量的关注[6-12]。典型的负载均衡交换包含两级:输入级用于均衡负载,将到达的业务转换成均匀业务,中间级用于交换均匀业务。两级交换的连接模式都是确定性和周期性的。负载均衡交换分组保序算法中具有代表性的就是基于帧的一类算法[6-8]。UFS[6](Uniform Frame Spreading)算法采用逐帧转发的概念,一帧由N个连续的属于同一个流的信元组成。如果每个输入端口的信元都按帧的方式,在N个连续的时槽内被顺序转发到各个对应的VOQ(Virtual Output Queue)中,则每个中间级对应的 VOQ的队长都相等,从而同一个帧的分组在中间级所经历的时延也相同。但是在中低负载下,一个 VOQ可能需要等待较长时间才能构成一个帧,因此UFS算法的时延性能较差。在此基础上,为减小低负载时分组时延,文献[7]提出了满帧填补(Padded Frame, PF)算法。其思想是在VOQ没有满帧时,增加“填充分组”凑成满帧,这样可减少业务量较少的队列成帧的时间,代价是需要使用额外的带宽来转发填充分组。
由于MMM交换天然存在多条路径,结合负载均衡交换的思想,本文提出了一种基于满帧填补的MMM Clos网络按序分组交换算法:PF扩展算法(EPF)。与传统两级负载均衡交换一帧长度为N不同,EPF算法里一帧长度为M,其中M为中间级模块数目。相比于满帧填补算法(PF), EPF算法构成满帧所需的分组数目减少,时延性能得到进一步改善。另外,由于填充分组的产生会增加中间级输入端口的分组到达率,本文证明了若控制填充分组的数量,交换网络仍能保持稳定。
2 基于帧填补的Clos网络按序分组传输
MMM Clos交换网络结构如图1所示。输入级有k个输入模块(IM),每个IM为n×m的输入排队交换结构,其中k=N/n,N为整个交换网络规模。中间级有m个中间模块(CM),每个CM为k×k的交叉点带缓存 Crossbar。输出级有k个输出模块(OM),每个OM为m×n的输入排队交换结构。通常将上述Clos网络记为C(m,n,k)。为讨论方便,取m=n=k=M。所有到达变长分组均被切割成定长信元,简称为分组,最后在输出端口进行重组。交换网络传输一个定长信元所需要的时间定义为一个时隙。

图1 MMM Clos网络交换结构
为避免填充分组的产生加剧中间级缓存的积压状态,设置阈值TC,当中间级缓存超过TC时,便不再产生填充分组,也就是说,此时输入级输入只可调度满帧分组。
EPF算法中填充分组的产生由IM模块的各输入端口调度器控制,CM和OM分别为自路由模式、各级模块分布式操作。下面分别介绍各级模块中算法的执行过程。
2.1 输入级模块
每个输入端口有N个VOQ队列,对应交换网络的N个输出端口。由输入端口IP(i,g)去往输出端口OP(j,h)的信元入队VOQ(i,g,j,h)。输入级模块内,当j=(i+t)%M时,输入端口i在时隙t与输出端口j相连。
输入端口发送队列的选择:
(1)每M个时隙,每个输入端口以轮询方式在VOQ(i,g,j,h)中寻找满帧队列。
(2)若不存在这样的 VOQ,则在非空队列中寻找最长队列。不失一般性,假设对于输入端口IP(i,g),VOQ(i,g,j′,h′)是最长队列,L′为CM(0)中CQ(i,0,j′,h′)的长度。进行下面的判断,若L′<TC,则调度VOQ(i,g,j′,h′),否则,不调度。之所以取CM(0)的队列状态是因为 IM 将业务均匀扩展,每帧时隙结束时各中间级的队列状态一致。
输入端口将选中队列的分组发送到中间模块,并始终从CM(0)开始,随后按照递增的方式,直到CM(M-1)。当服务一个非满帧时,若没有分组,则发送一个填充分组;否则,发送存储的分组。帧长为F的非满帧,0<F<M,需插入M-F个填充分组。
2.2 中间级模块
由IM(i)经由CM(r)去往OP(j,h)的信元,进入交叉点缓存CQ(i,r,j,h),如图 2。每个输出端口一个调度器,在一个帧时隙中,依次调度去往OM不同输出端口的分组。如:每一帧时隙的第k个时隙(1≤k≤M),在CQ(i,r,j,k-1)(其中0≤i≤M-1)中以最早信元优先(Oldest Cell First, OCF)方式选择一个去往OP(j,k-1)的分组。若相应的队列中均没有分组,则不发送。由于CM间相互独立,为保证各CM调度结果一致,启动时需要依次错开时隙。
2.3 输出级模块
每个输入端口有M个VOPQ(Virtual Output Port Queue),对应M个输出端口。由输入端口r去往输出端口h的信元,入队VOPQ(r,j,h)。输出级模块内,若r满足r=(h+t)%M,输入端口r在时隙t与输出端口h相连。这种配置方式保证每个输出端口在读取数据时,由CM(0)开始,并递增到CM(M-1)。输出端口接收到真分组,则将分组发送往输出线卡,若是填充分组,则丢弃。
3 算法稳定性及复杂度分析
3.1 稳定性
下面通过对采用EPF算法的MMM交换和理想输出排队(OQ)交换进行比较,证明 EPF算法可达100%吞吐率。其中,OQ交换在实现时输出端口需要N倍缓存加速,而EPF算法没有缓存加速的要求。
引理1对于一个工作守恒(work-conserving)服务器,令A(t)和D(t)分别表示截止时刻t到达和离开分组的累积和,服务器每时隙服务一个分组。则对于任意t≥0,有
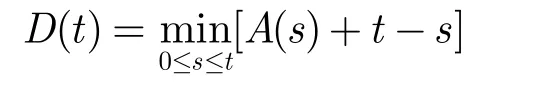
引理1在文献[13]中有证明。
定理1不管是何种业务到达过程,EPF算法具有与理想输出排队交换相同的吞吐率。
证明不失一般性,假设只有输出端口k,且t=0 时队列中没有分组。定义下面的变量:
Ak(t)(Bk(t)):在t时刻,MMM交换的输入级(中间级)输入端口去往目的端口k的累积到达分组数。
Ck(t):时刻t时,MMM交换的输出级输出端口k的累积离开分组数。

图2 CM(r)交换单元队列结构



由于离开分组的累积数目不大于到达分组的累积数目,很容易得到

观察每个输入,从满帧的最后一个分组到达时刻开始直到下一次这个 VOQ被调度,可能有至多M-1个时隙。另外,每个时隙只有一个输入端口可以发送分组到第 1个中间输入,因此一个 VOQ队列从被调度到实际得到服务,经历的最大时延为M-1个时隙。
首先证明输入级输入队列的队长是有界的。注意每个输入最多有N(M-1)个分组没有满帧。而一个满帧的出现使得输入端口开始服务分组(时延界为M-1+M-1=2M-2);因此,每个输入的最大分组数为N(M-1)+2M-2=MN-N+2M-2,开始服务后这个数目不会再增加。从而,所有输入最多有N(MN-N+2M-2)=MN2-N2+2MN-2N个分组去往输出端口k。令C1=MN2-N2+2MN-2N,则
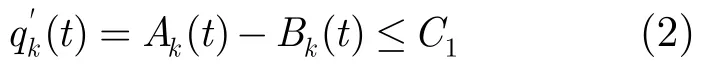
现在证明若输入过程由Bk(t)给出,则后两级交换与理想工作守恒服务器的累计离开分组数的差别是有限的;再结合式(2),可得出这样的结论:在输入由Ak(t)给出时,采用EPF算法的MMM交换和理想OQ交换在服务上的区别是有限的。
以每一帧时隙为单位,观察后两级缓存状态。以IM(i)为例,若CM(0)的第i个输入去往输出端口k的分组数目不大于TC-1,则IM(i)的每个输入将有机会在接下来M个时隙内发送M个分组(真分组或填充分组)去往中间级。而CM在接下来M个时隙中,每个输出端口至少离开1个分组。因此对于经过相同CM去往输出端口k的分组,在这一帧时隙内增加M2-1个,结果为(TC-1)M+M2-1。因而这一帧时隙结束时,经过M个CM去往k的积压分组数目为M3+(TC-1)M2-M。令C2=M3+(TC-1)M2-M。这意味着当(t)≥C2时,交换将只发送满帧到中间模块。
在每个时刻t, MMM交换只可能是下面两种状态:


因此,由式(1),引理1和式(2),有

并且由于OQ交换可以模拟单位交换能力的工作守恒服务器,存在

因此,对于式(3)有

进入式(4)的唯一路径是经过式(3),当到达新状态的第1个时隙,式(5)仍然成立。这之后,输入级交换不再产生填充分组,只服务中间级和输出级队列中剩下的分组。因此经过M个CM去往k的填充分组总数至多为(M.2+TC.M.-M.-1)(M.-1)。定义C3=M.3+(TC-1)M.2-TC.M+1。
因此,对于满足式(4)的任何时刻,采用引理1和式(2):

从而

综合式(6)和式(7),EPF算法与理想OQ交换在服务的分组数目上相差常数个,可得出结论:不管是何种到达过程,采用EPF算法的MMM交换与理想OQ交换具有相同吞吐率。 证毕
3.2 复杂度
输入级和输出级交换网络按照固定周期性的配置轮转,与传统负载均衡交换类似,只是轮转周期由两级交换网络的N减小为M,时间复杂度为O(1)。
输入级模块选择发送队列时,每输入端口首先需要在N个VOQ中轮询满帧分组,轮询寻找的时间复杂度为O(lgN)。若没有满帧,则需要寻找最长非空队列。采用比较树电路来实现,将会产生O(lgN)的门时延。接下来需要判定L′<TC是否满足。实际上IM不需要知道L′的值,只需要知道阈值是否达到。由于只有CM(0)更新L′值,所有输入模块需要能够访问该值,因此线卡之间的通信仅需要一个共享总线,广播M×N比特矢量,表示是否阈值已达到。这个实时读取需要O(1)时间。由于每帧只需一次更新,线卡之间的通信以线速的1/M发生。
中间级输出端口调度器需要在M个队列中以OCF方式选择一个分组发送,采用比较树电路来实现,将产生O(lgM)的门时延。
综上,EPF算法最高时间复杂度为O(lgN),比较树电路最高门时延为O(lgN)。
4 仿真结果
本节基于网络仿真系统OPNET对EPF算法的性能进行评估。对比项为采用 PF算法的负载均衡两级交换,采用 SRRD[14](Static Round-Robin Dispatching)算法的MSM交换,以及采用MMM-IM算法的 MMM 交换。仿真过程统计了各算法在Bernoulli均匀业务,突发均匀业务和不均衡业务下的性能。输入和输出都是可允许业务。交换网络的规模为N=16和N=64,对于Clos网络,分别对应C(4,4,4)和C(8,8,8)。每输入端口的业务负载定义为λ, 0≤λ≤1。则由输入i去往输出j的业务到达速率ai,j(0≤ai,j≤1)定义如下:

其中ω为不均衡系数,0≤ω≤1。Bernoulli均匀业务每个时隙以λ的概率产生分组,分组目的地址在N个输出端口间均匀分布。突发均匀业务由 ON/OFF源来模拟,突发长度服从指数分布,平均突发长度设置为16,一次突发中的目的地址相同。
4.1 中间缓存阈值对性能的影响
为考察阈值TC对于 EPF算法性能的影响,对不同负载下时延性能与阈值变化的关系进行了仿真。仿真结果如图3所示。阈值长度为0时只能发送满帧分组,因此低负载业务时延较大,如λ=0.05。对于中等负载业务,如λ=0.5,时延随着阈值的增加呈凹函数变化。阈值由0增加后,分组等待成帧的时延减少;阈值继续增加,越来越多的非满帧得到发送机会,填充分组数目增加,造成交换网络内的实际交换负载接近满负载,时延增加。选择合适的阈值,对交换网络的性能有重要影响。从图3中,交换网络C(4,4,4)和C(8,8,8)在TC=2时中等负载业务具有较小时延。下面的仿真中若没有特别说明,EPF和PF均取TC=2 。
4.2 填充分组占有比例
为考察输入级填充分组的产生与输入负载,交换规模的关系,统计了Bernoulli均匀业务下处于稳定状态后,较长时间段内产生的填充分组数目。NT和NF分别表示输出端口处统计到的真分组和填充分组的数目,纵坐标η=NF(NF+NT)。由图4可看出,当阈值TC增加,更多非满帧得到发送机会,从而产生更大比例的填充分组。填充比例η最大为(M-1)/M,也就是说低负载时填充分组的比例随着CM数目的增加而增加。在PF算法中,这一比例为(N-1)/N。
4.3 均匀业务时的性能
图5为Bernoulli均匀业务下各方案的端到端时延性能。由图5中可以看出,PF算法即使在低负载下时延仍然很高。EPF算法时延低于PF算法,但是比SRRD和MMM-IM算法的时延高。另外,由于帧长与交换网络规模有关,PF算法和EPF算法的时延随着交换规模的增加而大幅增加,SRRD算法和MMM-IM算法则受交换规模的影响较小。
图6给出了突发业务下各算法的仿真结果。对于PF和EPF方案,一次突发意味着形成满帧的概率增大,因此在突发低负载时的性能甚至优于Bernoulli均匀业务时的性能。EPF方案受突发业务的影响较小,高负载时的时延性能优于其它方案。
4.4 不均匀业务时的性能
图7为不均匀业务下各算法的吞吐率结果。基于负载均衡的两类算法 PF和 EPF,能达到接近100%的吞吐率。而SRRD算法和MMM-IM算法的最低吞吐率分别为75%和90%。

图3 不同阈值下的时延性能

图4 填充分组占有比例

图5 Bernoulli均匀业务下算法的时延性能

图6 突发业务下算法的时延性能(N=64)

图7 不均匀业务下的吞吐率(N=64)
5 结束语
本文提出了基于帧填补技术的MMM Clos网络的按序分组交换算法(EPF),通过增加填充分组使非满帧队列构成满帧,EPF算法避免了Clos网络中分组乱序问题和低负载下的饥饿问题。EPF算法采用分布式控制,具有复杂度低,不需要缓存加速的特点。线卡间需要共享的信息以1/M线速的速率交互,不会对高速交换的实现产生重要影响。分析和仿真结果表明在输入输出可允许业务下,EPF算法可达100%吞吐率。但相比于Clos网络传统的调度算法,EPF算法在均匀业务下的时延较高,设计具有更优时延性能的MMM Clos网络算法将作为本文的后续研究工作。
[1]Chao H J, Jing Z G, and Liew S Y. Matching algorithms for three-stage bufferless Clos network switches[J].IEEE Communications Magazine, 2003, 41(10): 46-54.
[2]杨君刚, 鲍民权, 刘增基, 等. 一种具有信元保序能力的Clos网络分布式调度算法[J]. 计算机学报, 2008, 31(3): 467-475.
Yang Jun-gang, Bao Min-quan, Liu Zeng-ji,et al.. A distributed scheduling algorithm maintaining cells order for three-stage Clos networks [J].Chinese Journal of Computers,2008, 31(3): 467-475.
[3]Chao H J, Jinsoo P, Artan S,et al.. TrueWay: a highly scalable multi-plane multi-stage buffered packet switch [C].Workshop on High Performance Switching and Routing,Hong Kong, 2005: 246-253.
[4]Dong Z Q, Rojas C R, Oki E,et al.. Memory-memorymemory Clos-network packet switches with in-sequence service[C]. Conference on High Performance Switching and Routing, Cartagena, 2011: 121-125.
[5]Chang C S, Lee D S, and Jou Y S. Load balanced Birkhoff-von Neumann switches, Part I: one-stage buffering[J].Computer Communications, 2002, 25(6):611-622.
[6]Keslassy I, Chuang S T, Yu K,et al.. Scaling internet routers using optics[J].Computer Communication Review, 2003,33(4): 189-200.
[7]Jaramillo J J, Milanf F, Srikant R,et al.. Padded frames: a novel algorithm for stable scheduling in load-balanced switches[J].IEEE/ACM Transactions on Networking, 2008,16(5): 1212-1225.
[8]Yu C L, Chang C S, Lee D S,et al.. CR: a load-balanced switch with contention and reservation[J].IEEE/ACM Transactions on Networking, 2009, 17(5): 1659-1671.
[9]Hu B and Yeung K L. Feedback-based scheduling for loadbalanced two-stage switches[J].IEEE/ACM Transactions on Networking, 2010, 18(4): 1077-1090.
[10]Lin B and Keslassy I. The concurrent matching switch architecture[J].IEEE/ACM Transactions on Networking,2010, 18(4): 1330-1343.
[11]申志军, 曾华燊, 高志江. 一种改进的反馈制两级交换结构FTSA-2-SS[J]. 电子与信息学报, 2011, 33(6): 1319-1325.
Shen Zhi-jun, Zeng Hua-shen, and Gao Zhi-jiang. An improved feedback-based two-stage switch architecture using 2-staggered symmetry connection pattern[J].Journal of Electronics&Information Technology, 2011, 33(6):1319-1325.
[12]Shi L, Liu B, Sun C,et al.. Load-balancing multipath switching system with flow slice[J].IEEE Transactions on Computers, 2012, 61(3): 350-365.
[13]Chang C S. Performance Guarantees in Communication Networks[M]. New York: Springer-Verlag, 2000: 6-7.
[14]Konghong P and Hamdi M. Static round-robin dispatching schemes for Clos-network switches[C]. Workshop on High Performance Switching and Routing, Kobe, 2002: 329-333.
