基于动态带宽分配的Hadoop数据负载均衡方法*
2012-06-25林伟伟刘波
林伟伟 刘波
(1.华南理工大学计算机科学与工程学院,广东广州510006;2.华南师范大学计算机学院,广东广州510631)
随着互联网的快速发展和数据规模的增大,出现了越来越多的数据密集型应用,这些应用常常涉及数千兆字节的数据,适合大规模分布式数据处理的Hadoop[1-6]随之产生.Hadoop 是 MapReduce[7]分布式编程模型和GFS[8]数据存储方式的开源实现,如今Hadoop已经有很多较为成功的应用,如Yahoo[9]和 Facebook,其它网站(如 Last.fm[10]和 Amazon[11]等)也都在部署Hadoop以管理基于大量数据的应用.
当一个Hadoop集群运行一定时间之后,节点的动态加入和退出会引起系统中数据负载的不均衡,新加入到集群中的数据节点需要进行负载均衡操作.数据负载均衡对云计算环境下的数据密集型应用的执行性能有着重要的作用[12],良好的负载均衡策略能有效地避免网络负载分布不均、数据流量拥挤、响应时间长等瓶颈,提高应用的执行效率.良好的负载均衡有两方面的含义:(1)大量的并发访问或数据流量分担到多个节点设备上分别处理,减少用户等待响应的时间;(2)单个重负载的运算分担到多个节点设备上并行处理,每个节点设备处理结束后,将结果汇总返回给用户,系统处理能力得到大幅提高.Hadoop默认的HDFS[13]负载均衡是以牺牲集群性能的方式来完成的.因此,需要设计一个在能保证HDFS性能最优的同时又能缩短整个负载均衡过程耗时的动态负载均衡方法.
虽然HDFS提供的数据负载均衡程序Balancer[12]可以对各个节点进行存储负载的平衡,但它采用静态负载均衡方法,需要手动调用该程序来实现数据负载均衡操作.此外,系统分配给Balancer的网络带宽是固定的,而且数据负载均衡需要占用大量的网络带宽和时间,从而影响系统的性能.文献[14-15]针对云计算环境下工作负载的不均衡问题进行研究,给出了动态再分配负载和基于模糊预测的方法来实现工作负载均衡,提高了系统的资源利用率和性能.然而,这些方法并不是针对数据负载均衡的.为此,文中提出了一种新的Hadoop数据负载均衡方法,引入控制变量来动态分配网络带宽,动态调整数据负载均衡和文件操作的网络带宽,以优化数据负载均衡,改善Hadoop数据负载均衡的性能.
1 数据动态负载均衡的基本思想
Hadoop数据负载均衡的过程本质上就是数据块的移动操作.数据负载均衡过程启动后,集群会寻找利用率过高的数据节点和利用率过低的数据节点,然后把集群HDFS中的数据块从利用率高的数据节点转移到利用率低的数据节点上.该负载均衡过程主要是输入/输出(I/O)密集型操作,在数据节点的CPU不是处于一个很高的占用率情况下,影响数据负载均衡过程的主要因素是网络宽带和磁盘I/O表现,其中网络宽带是影响负载均衡和整个Hadoop集群性能的制约性因素.
如在百兆交换机和百兆网卡的宽带网络环境中进行数据传输时,一台机器收发数据的速率有一个12.5MB/s的理论峰值.某个空白节点在进行负载均衡的过程中,由于负载均衡需要占用部分宽带,假如此时该节点要接收来自客户端的数据或来自HDFS上传的数据,则数据的传输效率会受到影响.
由于网络宽带是数据负载均衡及负载均衡时Hadoop集群性能的主要制约因素,因此可以对网络流量进行实时监测,并根据网络流量状况判断当前节点是否存在负载均衡以外的其它作业.如果不存在其它作业则继续进行数据负载均衡过程,否则先自动暂停数据负载均衡过程而优先处理其它作业.这样既能保证Hadoop作业的优先级和因负载均衡造成的性能损失,又能提高数据负载均衡速度.
2 数据负载均衡的理论推导
Hadoop的配置属性多达190个,其中有一个属性是“dfs.balance.bandwidthPerSec”,该属性是设置负载均衡的最大宽带,其实际作用是在负载均衡的过程中用于负载均衡的网络宽带不能超过该属性值.Hadoop中该属性的默认值是1MB/s,即在负载均衡期间,无论集群有没有负载均衡以外的作业,都只能以1MB/s的最大速度在不同数据节点之间传输数据块和实现数据负载均衡.文中对一个集群的数据负载均衡进行了测试,在负载均衡之前HDFS中本身有3.9GB的数据,当把此属性分别设置成1.0、1.5、2.0、4MB/s来进行负载均衡时,整个负载均衡过程的耗时分别为 33.80、21.50、16.80、8.98 min.这表明负载均衡过程主要是I/O密集型操作,网络宽带与负载均衡的速度息息相关.
2.1 默认的数据负载均衡方法
假设t(n)为数据负载均衡(简称负载均衡)操作的实际总耗时(单位s),C为默认的负载均衡宽带参数(常数项,C=1 MB/s),tB为集群在仅存在负载均衡操作的情况下以默认负载均衡宽带进行负载均衡操作的期望耗时(单位s),n为实际负载均衡宽带(为默认宽带的倍数),t1(n)为一次HDFS文件操作的实际总耗时(单位s),tO为集群在仅存在HDFS操作的情况下进行HDFS操作的期望耗时(单位s),BD为网络环境宽带峰值(单位 MB/s),E(n)为负载均衡过程中 HDFS的实际效率,则Hadoop在负载均衡过程中同时进行HDFS操作的情况下,负载均衡和HDFS操作的耗时及HDFS的实际效率为

假设Hadoop集群中添加了一个新的从节点,并随即进行负载均衡操作;默认负载均衡操作期望耗时tB=1800s,并且在负载均衡的过程中进行一次文件上传操作;在没有负载均衡的情况下,上传该文件期望耗时tO=300s;网络宽带峰值BD=12 MB/s,负载均衡宽带配置为默认的1MB/s(n=1).将这些参数代入式(1)-(3),可得负载均衡和HDFS操作的实际总耗时及HDFS的实际效率为t(n)=1800 s,t1(n)=327.27s,E(n)=91.67%.
图1(a)反映了在默认情况下负载均衡及上传文件的具体耗时情况.由于负载均衡的宽带为1MB/s,因而理想状态下HDFS操作的宽带为11MB/s.原本在集群没有负载均衡作业时需300 s的文件上传操作,现在需要327 s才能完成,HDFS的实际效率为原来的91.67%.
由于负载均衡过程宽带值与耗时呈线性关系,现将负载均衡的宽带配置从默认的1 MB/s更改为3MB/s(即n=3),其余参数保持不变,代入式(1)-(3),可得到更改负载宽带之后负载均衡和HDFS操作的实际总耗时及HDFS的实际效率,分别为t(n)=600s,t1(n)=400s,E(n)=75.00% .
更改负载均衡宽带为3 MB/s后,HDFS操作的宽带为9 MB/s.原本在集群没有负载均衡作业时需300s的文件上传操作,现在需要400 s才能完成,HDFS的实际效率仅为原来的75.00%.由此可见,单纯提高负载均衡的宽带并不明智,虽然负载均衡的耗时大大缩短,但对HDFS效率的影响非常大,并且HDFS操作的tO越大,受负载均衡影响的HDFS操作所需的额外时间t1(n)-tO越大,因为

图1(b)反映了在单纯更改宽带配置参数情况下负载均衡及上传文件操作的具体耗时情况.

图1 更改负载均衡宽带前后数据负载均衡及上传文件的耗时Fig.1 Time consumption of data load balancing and uploaded file before and after bandwidth change
2.2 动态的数据负载均衡方法
文中引入一个控制变量,为新节点的网络流量临界值.在理想状态下,假设某一30 s的时间段内,集群中的机器没有任何负载均衡以外的操作.按照Hadoop的默认配置,负载均衡过程中接收数据块迁移的目标机器(新的从节点)将会在此30 s内接收到不大于30MB的数据流量.如果把负载均衡的宽带设置为3 MB/s,则在此30 s内接收数据块迁移的目标机器将会接收到不大于90 MB的数据流量.在此基础上再乘以一个敏感系数,如1.1(110%,即允许10%误差),即如果按照默认配置,在负载均衡状态下,目标机器接收到的数据流量在33MB之内;如果按照3MB/s的配置,目标机器接收到的数据流量会在99MB之内.因此,可以定义网络流量监控变量的计算公式为
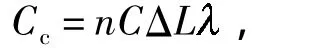
其中,Cc为网络流量临界值,ΔL为监控周期(单位s),敏感系数为常数.在负载均衡宽带为1 MB/s、监控周期为30s、敏感系数为1.1的情况下,网络流量临界值为33MB;而在负载均衡宽带为3MB/s、监控周期为30s、敏感系数为1.1的情况下,网络流量临界值为99 MB.这个网络流量临界值是作为判断当前参与负载均衡的节点是否参与到负载均衡以外作业的标准,它表示的是该节点仅参与负载均衡作业时所接收网络流量的上限值.如果接收数据块的节点在30s内所接收的数据量大于这个临界值,则判断此节点存在负载均衡以外的其它作业.敏感系数可以根据实际的集群环境作出修改,若此系数较大,则只能检测数据流量较大的连续HDFS操作,因为只有连续的HDFS操作时,才会在连续的30 s内使程序作出存在负载均衡以外作业的判断,此时程序对小型的突发性HDFS操作并不关心,但对于一个平均作业时间较长的集群来说,突发性的HDFS操作的性能损失亦可以忽略不计,因为这个性能损失的时间很短.
引入控制变量后的负载均衡流程如图2所示.监控从节点网络流量的动作通过捕获Linux下的/proc/net/dev完成.在新加入的节点上执行负载均衡时,根据实际的网络流量来控制负载均衡.当该节点上HDFS操作的数据流量超出临界值时,就会自动停止负载均衡,确保HDFS的优先级;否则,启动负载均衡.同时,为了避免因HDFS数据请求业务繁忙而一直不能进入负载均衡操作,增加了记录监听周期的功能.当监听周期k大于门限值d时,d值由管理员根据实际需要设置,若设置d=1200,则表示经过10h(1200×30s=36000s)后进行一次负载均衡操作.

图2 基于控制变量的数据负载均衡流程图Fig.2 Flowchart of data load balancing based on control variables
文中从数学角度来分析加入控制变量后的数据负载均衡及HDFS操作过程.假设t'(n)为数据动态负载均衡操作的实际总耗时,t'1(n)为一次HDFS文件操作的实际总耗时,E'(n)为数据动态负载均衡过程中HDFS的实际效率.假设负载暂停的滞后时间为ΔD(即需要ΔD才结束一次负载),当集群中出现HDFS操作时,程序需要ΔL的时间来监听网络流量,当检测到实际流量超过流量临界值时作出停止负载均衡的判断,即HDFS操作在前ΔL+ΔD时间内仍然受到负载的影响.在ΔL+ΔD内HDFS操作的完成量为
之后的HDFS操作因负载已经暂停而能以最高的网络宽带进行数据块的传输操作,因此余下的HDFS操作量与总的HDFS操作量的比例关系式为

其中,tr为HDFS操作的剩余时间,由上式得:
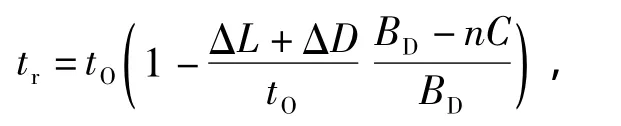
HDFS操作的总时间为

因为HDFS操作的最后一部分时间可能不足ΔL,但在ΔL内程序依然处于监听状态,负载并未重新启动,期间负载的暂停时间为

其中,LUB(·)为求最小上界运算.
由于HDFS操作结束后,程序需要再监听ΔL后才会作出重启负载平衡的判断,因此负载暂停的总时间
则整个负载的总耗时为


将负载均衡的宽带配置从1MB/s更改为3MB/s(n=3),其余参数保持不变,且引入流量控制,监听周期为30 s(ΔL=30 s),负载均衡暂停滞后60 s(ΔD=60s),则代入式(4)-(6)可得到采用文中方法后数据负载均衡和HDFS操作的实际总耗时及HDFS 的实际效率,分别为 t'1(n)=322.5s,t'(n)=870s,E'(n)=93.02%.采用文中方法后数据负载均衡及文件上传操作的耗时情况如图3所示.

图3 采用文中方法时数据负载均衡及文件上传总耗时Fig.3 Time consumption of data load balancing and uploading file using the proposed method
当负载均衡和文件上传操作同时开始时,在前30s内节点已经检测到实际流量超过临界值,随即停止负载均衡守护进程,在第30秒到第90秒期间是等待此次负载均衡完全结束的时间(期间数据块依然在传输),由于文件上传操作在这段时间内受到宽带的影响,故在90 s内上传的文件总量应该为22.5%(在没有负载均衡情况下,1 min内理论上可上传20%的文件).从第90秒开始负载均衡暂停,文件上传操作以原来的宽带继续进行(12 MB/s).到第270秒尚剩余17.5%的文件需要上传,按照12MB/s的速度理论上需要52.5s.因为敏感系数设置得比较小,如果在第270秒到第330秒内数据流量超过了临界值,则程序会在第330秒对此作出反映,并等待30 s.因第 330秒到第 360秒内没有HDFS操作,故数据负载均衡在第360秒再次启动.
表1给出了3种数据负载均衡方法的性能对比,通过更改Hadoop负载均衡网络宽带虽然能对提高负载均衡效率、减少负载均衡耗时起到立竿见影的效果,但节点会以很大的性能损失为代价;通过更改网络宽带且引入控制变量来实现动态负载均衡,节点的性能损失与Hadoop默认的负载均衡方法十分接近,而且能大大缩短完成整个负载均衡的总时间.

表1 3种数据负载均衡方法的性能对比Table 1 Performance comparison of three data load balancing methods
3 实验与结果分析
采用3种数据负载均衡方法在实际的Hadoop集群中进行负载均衡操作,以测试实际性能.在测试环境中,主节点和新加入集群的从节点均为Ubuntu 10.04 LTS的操作系统.主节点同时作为名字节点和数据节点,其配置如下:CPU为酷睿2双核T7300,2GHz主频;内存为2GB.从节点仅作为数据节点,其配置如下:CPU为酷睿2双核E4400,2 GHz主频;内存为3 GB.各节点之间的网络带宽为百兆宽带.在从节点加入到集群之前,集群HDFS中共有6.9GB数据(位于主节点的数据节点之上).向集群中加入从节点后,在从节点上进行负载均衡操作.负载均衡开始后,在某个随机时刻主节点的数据节点发起HDFS文件上传操作,上传的文件量为1.1GB.由于集群数据块副本放置数为2,当主节点的数据节点发起文件上传操作时,数据会同时写入主节点和从节点的HDFS目录中.
3种负载均衡方法的宽带分别为1、3、3 MB/s,其中文中动态负载均衡方法的网络流量临界值为90MB,实际测试结果如表2所示.
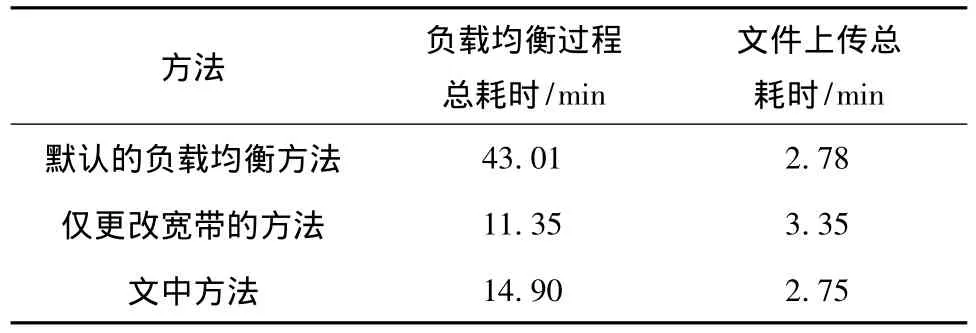
表2 3种数据负载均衡方法的实验结果Table 2 Experimental results of three data load balancing methods
从表2可知:(1)默认的负载均衡方法与动态负载均衡方法的文件上传耗时差别并不明显.这是因为前者虽然是在负载均衡的同时对HDFS进行操作,但90%以上的宽带依然是留给HDFS作业使用的;后者的HDFS操作虽然在大部分时间内不受负载均衡的影响,但在负载均衡未暂停的时间内HDFS所受的影响远大于前者;只有在更大型的集群中进行连续且耗时非常长的HDFS操作时,后者在性能损失的表现上才会比前者有更明显的优势.(2)单纯更改宽带的方法与动态负载均衡方法的文件上传耗时差别比较大.这是因为前者是以牺牲HDFS操作性能的代价来提高负载均衡效率的,而后者只是在整个负载均衡过程中所消耗的时间比前者多(因为这个时间包含了进行HDFS操作时负载均衡处于暂停并等待的时间).总之,文中动态负载均衡方法能在保证HDFS操作性能的情况下大大缩短了数据负载均衡的时间.
4 结语
文中在研究Hadoop集群数据负载平衡的原理和方法之后,对2种Hadoop集群的负载均衡方法(Hadoop默认的负载均衡方法和仅更改宽带的负载均衡方法)建立了数学模型并进行了分析,发现:默认的负载均衡方法虽然对Hadoop节点的性能影响较小,但整个负载均衡的过程较为缓慢;仅更改宽带的负载均衡方法虽然较默认的负载均衡方法能大大缩短负载均衡的时间,但对Hadoop节点性能的影响较大.为此,文中提出了一种根据节点网络流量进行动态负载均衡的方法,并建立其数学模型.分析结果表明,文中动态负载均衡方法能在保障节点性能的情况下,大大缩短集群数据负载均衡的耗时.3种负载均衡方法的实验结果表明,文中动态负载均衡方法既能保证HDFS系统的数据访问性能,又能提高集群加入新节点时的数据负载均衡效率.由于数据分布情况及数据副本的数量对数据负载均衡都有影响,故今后将重点综合多个因素来优化数据负载均衡的性能.
[1]Apache.Hadoop[EB/OL].[2012-01-03].http:∥lucene.apache.org/hadoop.
[2]林伟伟.一种Hadoop数据放置的优化策略[J].华南理工大学学报:自然科学版,2012,40(1):152-158.Lin Wei-wei.An improved data placement strategy for Hadoop [J].Journal of South China University of Technology:Natural Science Edition,2012,40(1):152-158.
[3]Prashant S,Kamalakar K.A multi-agent simulation framework on small Hadoop cluster[J].Engineering Applications of Artificial Intelligence,2011,24(7):1120-1127.
[4]Qiu Zhi,Lin Zhao-wen,Ma Yan.Research of Hadoopbased data flow management system [J].The Journal of China Universities of Posts and Telecommunications,2011,18(2):164-168.
[5]Ye Xianglong,Huang Mengxing,Zhu Donghai,et al.A novel blocks placement strategy for Hadoop[C]∥Proceedings of the 11th International Conference on Computer and Information Science.Washington D C:IEEE,2012:3-7.
[6]Sadasivam G S,Selvaraj D.A novel parallel hybrid PSOGA using MapReduce to schedule jobs in Hadoop data grids[C]∥Proceedings of the Second World Congress on Nature and Biologically Inspired Computing.Fukuoka:IEEE,2010:15-17.
[7]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[8]Ghemawat S,Gogioff H,Leung P T.The google file system[C]∥Proceedings of the 19th ACM Symposium on Operating Systems Principles.New York:ACM,2003:29-43.
[9]Jeremy Z.Yahoo!Launches world's largest Hadoop production application[EB/OL].(2008-02-19)[2012-01-03].http:∥marcboucher.ws/2008/02/hadoop-scales-reallywell-yahoo-launches-worlds-largest-hadoop-production-application.html.
[10]Loughran Steve.Applications powered by Hadoop [EB/OL].[2012-01-03].http:∥wiki.apache.org/hadoop/PoweredBy.
[11]Amazon.Amazon elastic compute cloud [EB/OL].[2012-01-03].http:∥aws.amazon.com/ec2.
[12]郑湃,崔立真,王海洋,等.云计算环境下面向数据密集型应用的数据布局策略与方法[J].计算机学报,2010,33(8):1472-1481.Zheng Pai,Cui Li-zhen,Wang Hai-yang,et al.A data placement strategy for data-intensive applications in cloud [J].Chinese Journal of Computers,2010,33(8):1472-1481.
[13]Borthakur D.The Hadoop distributed file system:architecture and design [EB/OL].[2012-01-03].http:∥hadoop.apache.org/common/docs/stable/hdfs_design.html.
[14]Jing Siyuan,She Kun.A novel model for load balancing in cloud data center[J].Journal of Convergence Information Technology,2011,6(4):171-179.
[15]Liu Yang,Li Maozhen,Alham Nasullah Khalid,et al.Load balancing in MapReduce environments for data intensive applications[C]∥Proceedings of the Eighth International Conference on Fuzzy Systems and Knowledge Discovery.Shanghai:IEEE,2011:2675-2678.
