图像文本识别中目标定位方法研究
2012-05-11杨新锋
杨新锋
0 引言
图像识别是人工智能领域的重要分支,它利用光学系统或者其它成像系统来获取图像信息,然后利用计算机来处理这些外界获取的大量的图像信息,以代替人类完成图像分类或辨识的任务。它所处理的对象的内容十分广泛,具体地说这些对象可以是各种物体的黑白或彩色图像、手写字符、遥感图像、声波信号、X射线透视胶片、指纹图案、空间物体投影等等。图像识别广泛应用于制造业、交通、邮政、天文气象、资源勘探、公安、以及军事等各行各业。
图像中的文字是图像内容的一个重要来源,数字图像和视频中的文本通常能给人们提供简短而重要的信息,因此图像文本识别在图像识别领域占有重要的地位。
1 图像文本识别概述
1.1 图像文本识别的类别
从文本的产生方式来分,图像文本可以分为人工文本和场景文本[1],人工文本是指人工加在图像上的文本(比如电影里的字幕),场景文本是图像上本身存在的文本(比如拍摄的交通图像里的车牌),场景文本图像具有较为复杂的背景,同时受光线和文本的字体、颜色、位置等因素影响较大,往往很难被检测,只有准确的定位文本区域才能保证进一步的文本识别正确性。
从文本的载体来源来分,又可以分为静态文本和动态文本,静态文本是指存于硬存储媒体里的单帧图像中的文本(比如OCR,一些存于计算机中的图片),动态文本则是变化的图像序列(或者说是视频流)中的文本。本质上说,动态文本是由一系列的静态文本组成的,动态文本的识别是在静态文本识别的基础上的进一步发展,更有实时性以及自动化的要求。
2 图像文本基本识别步骤
图像文本的识别主要分6部分:(1)从媒体上获取原始图像;(2)对原始图像做预处理;(3)检测图像中是否有符合要求的文本区,若有则从中定位并提取文本区;(4)对文本区进行处理,分割单字符;(5)提取单字符特征,进行识别;(6)将识别结果存储。其中2-5步是图像文本识别的关键步骤。
1.2 图像文本识别目标定位
图像文本识别的6个关键技术分别是文本的定位,单字符的分割以及字符的识别。文本定位的精确与否,直接影响着后续过程的进行。如果定位不准,例如:误定位、定位范围过大或定位范围过小,都可能误分割并导致识别的失败,它是字符分割和识别的基础,对整个系统的性能起着至关重要的作用,定位的准确程度决定着系统的识别率的高低。
定位过程是文本目标的检测过程,就是将目标的准确位置从一幅图像中找出并有效地提取出来。通常情况下,计算机实现的软件系统对目标的检测可称为有导师的检测,即对目标的定位之前都已经知道目标的特征,从目标特征的数学描述(比如目标的形状描述,颜色描述等等)上出发来进行定位。
1.常见的定位方法
常见的定位方法有基于灰度图像的文本定位方法和基于彩色图像的文本定位方法。
(1)基于灰度图像的文本定位[2]
绝大多数的定位算法都是基于灰度图像的,待定位的文本有固有特征,这些特征主要有形状特征,灰度变化特征和矢量量化特征。对应这3类重要的灰度图特征,灰度图像下的文本定位主要有3种方法:基于形状特征的定位算法、基于灰度变化特征的定位算法和基于矢量量化的定位算法。
(2)基于彩色图像的文本定位[3]
大部分的定位算法都是针对灰度图像的,对于彩色图像,相比于灰度图像有着更多的信息量,因此也有很多定位算法是基于彩色图像的。
通过色彩进行定位的算法,一般是目标的色彩特征比较明显,而这种特征又容易获取与区别。很多目标检测都利用了目标的色彩特征,在图像文本检测中,彩色图像中的文本定位主要有车牌的识别,道路警示标语的识别以及一些视频帧里的文本信息提取过程等等。常用的基于彩色图像的文本定位的方法有:彩色边缘检测方法[4]、HSV颜色空间色彩特征及纹理特征分析结合的方法以及神经网络方法。
2 改进的定位方法
对面临的采集环境基本可控,属于固定背景下的识别系统,同时需要满足实时处理识别要求的系统,可以选择常用的速度较快的边缘检测投影算法。而设计系统时,考虑到一定的适应性,使之可以实现在较复杂背景下的以及文本本身质量不高的情况下的文本定位,因此在定位算法的选择方面,可以采取基于形态学运算与轮廓检测相结合的算法,其定位流程,如图1所示:
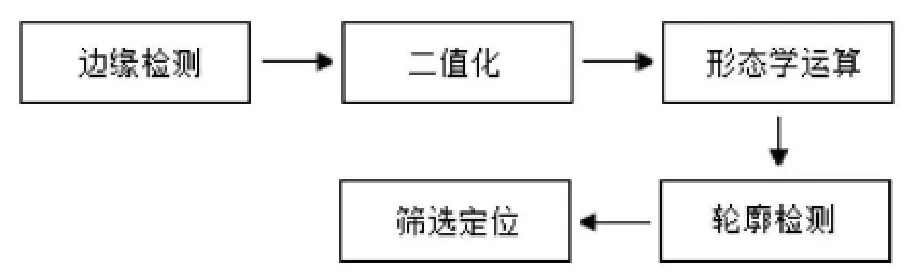
图1 定位过程流程
2.1 边缘的检测
直观上,边缘是一组相连的像素的集合,这些像素位于两个区域的边界上。本质上说,边缘是一个局部的概念,而边缘检测可以理解为在局部对灰度不连续点进行的测量,或者说是对灰度值突变(或某种程度的渐变)的区域的检测。
边缘的特性是,在边缘走向上,灰度值变化较小;在边缘垂直走向上,灰度值变化较大。可以用梯度来描述某处像素值的变化程度,图像边缘点的梯度值在垂直于边缘的方向上是最大的。通常都是根据边缘的这一特性来进行边缘检测以及边缘的走向。
常用的边缘检测方法有:差分、梯度边缘检测,Canny边缘检测,一些检测算子有Roberts、Sobel、Prewitt、Laplace等边缘检测算子。
以下给出Canny边缘检测算法的步骤:
①用高斯滤波器平滑图像;
②在x和y方向分别求一阶导数,然后在组合为4个方向上的导数,这些方向导数达到局部最大值的点就是组成边缘的候选点;
③对这些梯度幅值进行非极大值抑制,排除一些非边缘点,得到细化的边缘;
④通过高低阂值检测得到边缘图像。
Canny边缘检测法是基于数学特性的最优边缘检测器,通过对信噪比和边缘定位算法的结合,得到了最优边缘,该方法广泛应用于图像处理和模式识别问题中。
2.2 二值化
形态学运算之前。需要对图像进行二值化,灰度图像的二值化是一个图像分割的过程,分割的优劣程度在于能否准确的把目标与背景分割出来,而分割的依据是产生的阂值。阂值的确定方法一般分为3种:全局阂值法、局部阂值法、动态阂值法[5]。
①全局阂值法:全局阂值法对整张图像获得一个整体的阂值,并使用该阂值对图像进行分割。当目标与背景的灰度直方图呈现比较明显的双峰特性时,采用全局阂值法能得到很好的效果。而当图像中光照不均匀或者噪声较多时,其分割效果不很理想。常用的较经典的全局阂值法有最大嫡值法和Ostu方法。
②局部阂值法:局部阂值法通过将当前点的灰度与其周围像素的灰度值特征相结合来确定阂值,这种方法能很好地处理光照不均匀的图像,但其处理速度慢,并且对噪声的处理并不恰当,常产生相反的分割效果。常用的经典局部阂值法有Bernsen法和Niblack法。
③动态阂值法:动态阂值法考虑的因素更多,一方面考虑当前点以及周围像素点的灰度特征,另一方面还虑当前像素的位置,从而确定其自适应的阂值。动态阂值法能较好的处理噪声的问题,但其算法复杂,运算过程缓慢,难满足实时性的要求。
针对不同的情况,可以采用不同的二值化方法。
2.3 形态学的运算[6][7]
数学形态学最初是建立在集合论基础上的代数系统,它提出了一套独特的概念以及变换来描述图像的基本特征。运用数学形态学运算从图像中提取那些对表达以及描绘区域形状有用处的图像分量是它在图像处理中的主要任务。
数学形态学的核心运算是击中(Hit)与击不中(Miss)变换(HMT)。由此衍生出四个基本形态学操作:膨胀操作(Dilation)、腐蚀操作(Erosion)、开操作(Opening)、闭操作(Close)。膨胀操作通常会将目标区域变大,将一些背景元素转为目标区域,这么做的目的通常是是将一些断裂连接起来,或者将一些空洞填补起来;腐蚀操作通常会使目标区域缩小,将一些目标点转为背景点,这么做的目的通常是把二值图里一些不相干的细节削弱或者消除掉,或者可以将粘连的两个目标分开;开运算使对象的轮廓更平滑,同时打断细小的粘连,消除细小的突出;闭运算使对象的轮廓更平滑,同时连通细小的间断、填补细小的鸿沟,消除小的空隙,还能填补轮廓线中的断裂。
2.4 矩化的运算[8]
形态学运算之后,采用了矩化运算。矩化运算的目标是一幅二值图,所谓矩化就指的是将图中的不规则连通域矩化,变成矩形的连通域,其目的是为了找到某一个连通域的最大矩形。矩化以后采用轮廓跟踪来寻找矩形,再根据先验知识判断矩形区域是否符合要求。连续的斜长边缘可能引起多区域粘连,所以在矩化运算之前先统计一下每行的白点数,设置一个阂值,白点总数小于此阂值的行可以将该行像素全部赋值为0。矩化运算算法可以描述为:
①读入一幅二值图;
②扫描图像每个像素(可以不扫描四个边缘上的像素),如果当前像素灰度值为255,而该像素上下左右四点所有灰度值都为0,则令该像素灰度值为0;若当前像素灰度值为O,且该像素上下左右四邻像素灰度值之和至少大于510(至少存在2点灰度值为255),则令该像素灰度值为255;
③循环执行步骤②,例如设为100次循环,正常情况下矩化可以完成,使得所有不规则连通域变为矩形连通域。
2.5 轮廓形状表示与目标筛选
图像分割为不同的区域以后,对已经分割好的像素集通常有更好的表示和描述方法。基本上,表示一个区域有两种方法(或两种选择):可以用其外部特性来表达区域(比如其边界);或用其内部特性来表达(如组成区域的像素)。当关注的焦点集中于其形状特性上时,可以选择外部表示法;当其主要的焦点集中于内部性质时,则选择内部表示法,比如颜色,纹理等。有时也可以内部跟外部特征都做选择。
本文对经过形态学处理后的二值图,再进行矩化运算,然后得到许多的矩形连通域,再对这些连通域进行外部特性表示,也就是将这些矩形的外轮廓表示出来,接着从这些外轮廓中依据先验知识筛选要定位的目标。
此方法的使用范围,在背景较简单、边缘较少的情况下,定位效率较高,在背景复杂,边缘丰富的时候,定位效率低。
3 小结
在大多数字符识别任务里,字符区域的定位是要求最为苛刻的,是识别步骤里最为关键的一个步骤,定位质量的好坏直接影响整个系统的识别率,在复杂的情况下,这个问题就更加明显。因此,在进行定位之前,尽量多的去除干扰因素显得尤其重要,本文首先简介了各种文本定位的方法,然后依据系统面对的问题,采取了数学形态学运算和轮廓跟踪与依据先验知识进行筛选的文本定位方法。
从定位结果来看,在背景相对简单的情况下,能达到较好的定位效果;当背景较为复杂、图像中边缘丰富的情况下,定位的效果不理想。其中,干扰最为强烈的就是在文本周围出现的非相关边缘,此类边缘多能造成字符区域与干扰区域形成粘连,使得无法定位。
[1]王君.数字字符检测与识别方法研究[D].华中科技大学,2007.5:1.
[2]沈全鹏.基于数字图像处理的车牌定位研究[D].广东工业大学,2007.5:18-19.
[3]岳鹏.车牌定位识别关键算法的研究[D].西北大学,2010.6:12-13.
[4]张引,潘云.彩色汽车图像牌照定位新方法[J].中国图像图形学报(A),2001.6(4):374-377.
[5]朱虹.数字图像处理基础[M].北京:科学出版社,2005.
[6]冈萨雷斯.数字图像处理(第二版)[M].北京:电子工业出版社,2006:59-112.
[7]阮秋琦.数字图象处理学[M].北京:电子工业出版社,2001:130.
[8]冯国进,顾国华.车牌自动定位与模糊识别算法[J].光电子激光,2003:750-752.
