基于Davinci平台的SD卡读写优化
2012-05-11梁正和秦超陆国强
梁正和,秦超,陆国强
0 前言
随着嵌入式处理器速度的不断提高以及嵌入式系统功能的不断增加,嵌入式系统越来越多地被应用到网络音视频的处理上,在这种情况下,美国德州仪器公司(TI)推出了面向嵌入式网络音视频应用的Davinci解决方案。这个解决方案的提出使开发人员摆脱了数字视频的具体处理细节,加快了产品上市进程。Davinci解决方案也成为了国内的热门研究课题。
SD卡(Security Digital Memory Card)是由日本松下公司、东芝公司和美国SANDISK公司共同开发研制的全新存储卡产品。SD卡兼容MMC卡接口规范,并以其大容量、高性能、高安全性等特点成为了嵌入式环境中存储大容量数据的首选。对SD卡的操作也是Davinci解决方案里一个必不可少的组成部分。
1 Davinci平台的SD卡驱动程序
1.1 MMC/SD卡控制器
MMC/SD控制器通过MMC/SD协议与SD卡进行通信,MMC/SD卡控制器通过配置可以实现MMC控制器和SD卡控制器之间的转换。驱动程序可以通过读写控制器里的寄存器和FIFO,启动一次与SD卡的通信。通过设置寄存器,可以发送命令和参数、设置接受的应答的格式、事发后发送/接收数据以及是否产生同步时钟等SD卡操作所需要的功能。控制器还可以进行DMA操作,将控制的FIFO作为DMA控制器的目标或者源,实现后台的数据传输,从而提高系统效率。
Davinci的MMC/SD控制器结构,如图1所示:
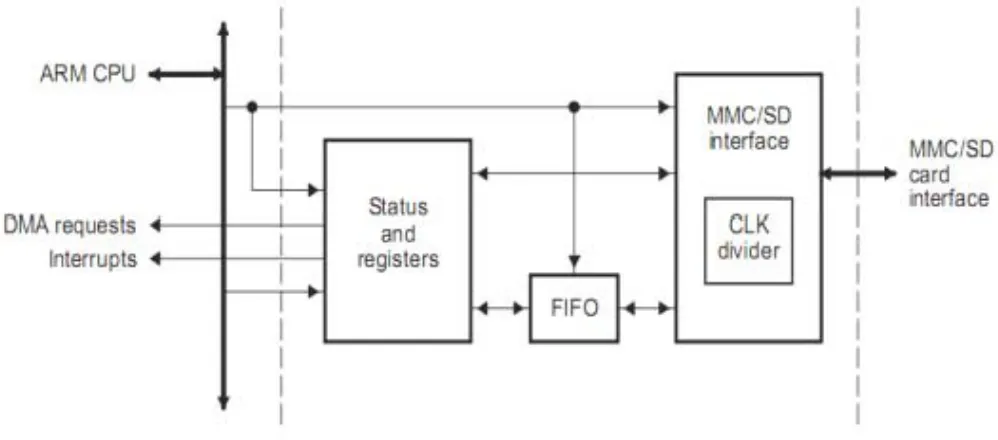
图1
1.2 Davinci平台的SD卡驱动程序
Linux2.6内核支持Davinci平台下的SD卡,在drivers/mmc/davinci-mmc.c里为其提供了具体对应于davinci平台的SD卡驱动程序。
SD卡是块设备,只能以块为单位来进行读写操作。因此SD卡驱动程序必须将SD卡实现为块设备。SD卡驱动程序可以分为4层,分别为:协议层、块设备驱动层、抽象设备层、具体设备层。
在协议层里,规定了控制器与卡通信的具体命令,以及每个命令的类型和返回类型等。
在块设备驱动层里,mmc_block.c首先通过register_blkdev()向内核注册自己,然后通过driver_register()来注册对应的驱动。驱动里包括probe函数、remove函数、suspend函数、resume函数,在其probe函数里完成了gendisk结构体的初始化,请求处理函数的设置等块设备驱动程序的核心。
在抽象设备层,mmc.c里实现了对SD卡的具体操作,如检测卡的状态、读取SD卡寄存器。
在具体设备层里,davinci-mmc.c注册了具体的SD卡设备和驱动程序。实现具体的中断处理、数据传输、请求函数。
当有用户向SD卡发出读写命令时,命令会被内核发送到块设备的请求队列里,调用在块设备驱动层里设置好的请求处理函数mmc_request(),mmc_request()会唤醒mmc_queue_thread线程,而mmc_queue_thread会调用mmc_blk_issue_rq()对请求进行处理,最后请求会被转换为标准协议并提交到mmc_davinci_request()进行命令和数据的发送与接收,具体过程,如图2所示:

图2
2 SD卡驱动优化
在Linux2.6内核里将驱动程序加载上之后,虽然能对SD卡进行正常的读写操作。
然而,在实际应用中发现,在进行读写操作时,CPU峰值会达到80%,读写速度仅为2.3MBps左右,在嵌入式系统资源有限和Davinci平台高实时性要求的情况下,如此高的CPU占用率无疑会影响系统的正常运行。
2.1 降低CPU峰值
2.1.1 原因分析:
由于SD卡的运行模式会影响其传输速率,因此,首先检查SD卡运行模式:
总线频率:25MHz(正确)
总线位宽:4bit(正确)
信令模式:多块传输(正确)
搬运模式:DMA(正确)
这说明了SD卡运行模式不是造成高CPU峰值的原因。开启内核profile功能,对IO请求处理过程进行分析,结果如表1所示:

表1
内核profile功能的原理是每次系统时钟中断时,获取并统计中断前内核PC指针的值。而__delay占用的系统tick数为2958远大于IO请求处理接口函数mmc_queue_thread所占用的tick数目,即等待请求处理函数对请求进行处理的时间远大于请求本身被处理所需要的时间。
2.1.2 优化
Linux内核提供了许多延迟方法处理各种延时请求。不同的方法有不同的特点,有些是在延迟任务时挂起处理器,而另外一些则会一直占有CPU。ndelay()、udelay()、mdelay()3个函数分别进行纳秒、微妙和毫秒级的延时。这3个函数都是用__udelay()实现的,而__delay是忙等待,也就是说在延迟4的过程中不会让出CPU,从而导致循环等待代码占用了过多的CPU时间。更为理想的方法是使用schedule_timeout()函数,该方法会让需要延迟执行的任务睡眠到指定的延迟时间耗尽后再重新运行,它由__schedule()实现的,而__schedule()并不是忙等待,它会在等待时让出CPU。
找到davinci-mmc.c里的轮询代码将循环占用CPU(udelay)修改为循环睡眠等待(schedule_timeout)。
3.1.3 测试修改后开启内核profile功能,如表2所示:
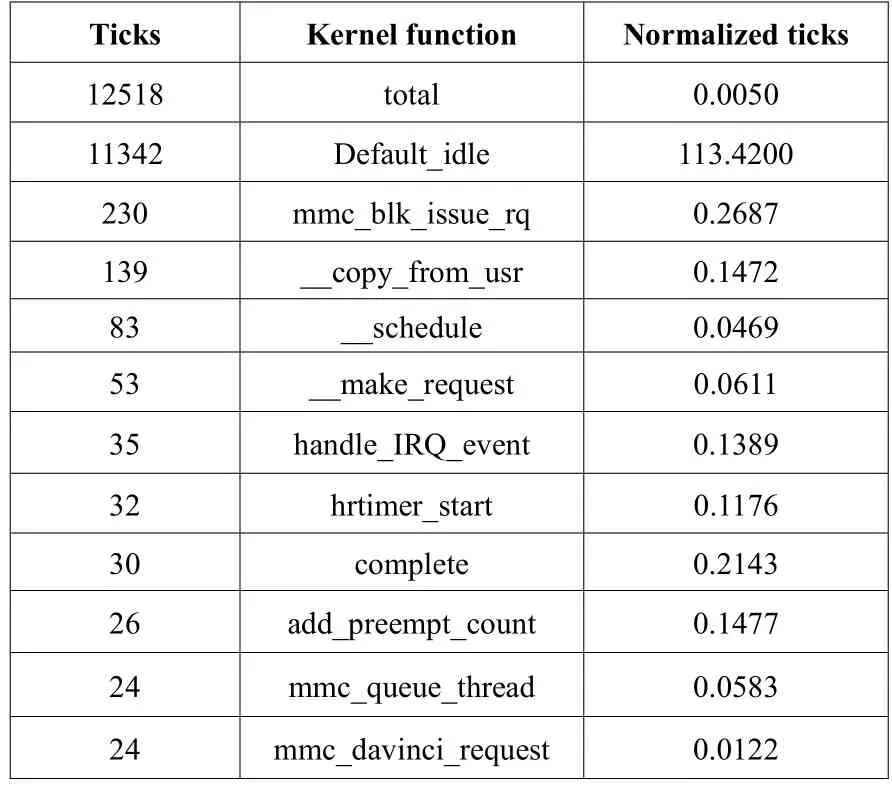
表2
上述数据说明轮询代码所占用的CPU时间已经大大减少,系统占用系统的瓶颈已经由轮询代码转移到了mmc_blk_issue_rq函数。
同时,用dd命令全力进行读写操作,CPU峰值降为20%,吞吐量为2.1MBps。
2.2 提高读写速度
2.2.1 原因分析
20%的CPU峰值依然很高,而且吞吐量也因此而下降。由于mmc_blk_issue_rq为SD卡驱动处理IO请求的入口函数,故CPU峰值过高的原因是IO请求过多或IO请求占用CPU时间过多。但是由于mmc_davinci_request占用的系统tick数很少,所以可以排除单个IO请求占用CPU时间过多的可能。运行blktrace观察IO请求的数量、结果,如表3所示:

表3
(其中:“179,0”代表SD卡块设备号,“D”代表issued,”C”代表complete,“W”代表write,“x+y”代表块设备上从偏移量x个扇区开始,长度为y个扇区的区域)
Blktrace的原理为对IO请求处理路径上的各个关键处理点进行实时统计,上述数据说明了SD卡驱动每次处理的IO请求仅为16个扇区,IO请求大小仅为8KB(16*512B=8KB),每次传输的数据量过小,导致传输效率低,IO请求过多,CPU峰值过高。
SD卡IO请求的大小受到DM365芯片的SD卡控制器和EDMA控制器的限制:
SD卡控制器:每次IO请求大小最大为64K*512B=32MB其中64K为最大的数据块个数(MMCNBLK),512B为块大小。
EDMA控制器:每次IO请求大小最大为4B*64K*64K*256=4TB其中4B为传输单元大小(ACNT),64K分别为传输行大小(BCNT)和传输块大小(CCNT),256为传输链表大小(LINK)。
因此,理想情况下IO请求大小最大应该为32M。
检查EDMA控制器的参数,发现EDMA设置传输链表大小为2,传输块大小为128KB,故可以断定,对传输链表大小设置过小,导致了IO请求过小。
2.2.2 优化
EDMA3提供了一种链接的DMA传输机制,允许整个PaRAM(ParameterRAM)重新加载,这种机制在ping-pong buffers、circular buffering和连续传输里很有效。由于EMDA3控制器最多支持256个PaRAM,故,理论上传输链表大小最大可以为256。
修改驱动程序里EDMA链表的设计,使其支持16个传输块(不采用256个传输块,因为其他程序也要用到DMA传输块)。
2.2.3 测试
开启内核profile功能、数据,如表4所示:
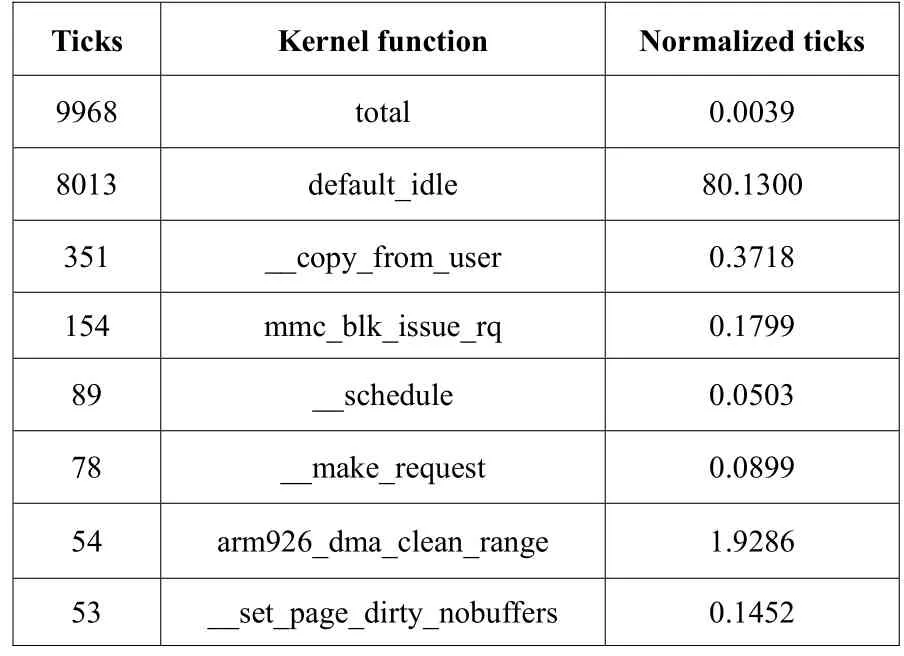
表4
上述数据说明系统的瓶颈已经由IO请求处理入口函数转移到了write系统调用的拷贝上。同时,用dd命令全力进行读写操作,CPU峰值降为10%,吞吐量为6MBps。相比于优化前的80%CPU峰值和2.3MBps吞吐量,有了很大的提高
3 总结
本文给出了Davinci平台的SD卡驱动程序的优化方案,经过优化后的SD卡驱动程序降低了CPU峰值,提高了读写速度,已经完全能够满足davinci平台下的应用。
但在改进的过程中发现,因为DMA连接数位2,传输块大小设置为128KB,因此IO请求的大小也应该为256KB,但实际上IO请求大小却只有8K,说明传输块的大小并没有达到所设置的128K。分析原因后发现由于系统采用4KB大小内存页存储IO请求数据,多个连续的内存页作为一个DMA传输块进行传输,当内存页不连续时,最坏情况下,每个传输块只有一个4KB内存页,无法达到预期的128K,所以IO请求实际大小只有8K(4KB*2)。未来优化方向为研究如何尽可能的将数据集中在一个传输块内进行传输,进一步提高效率。
[1](美)Corbet,J等著;魏永明,耿岳,钟属毅译.linux设备驱动程序[M].北京:中国电力出版社.2008
[2]TMS320DM36xDigital Media System-on-Chip(DMSoC)Multimedia Card/Secure Digital Card Controller User's Guide.www.ti.com.cn.2010
[3]纪竟舟,付宇卓;嵌入式linux下的MMC/SD卡的原理及其实现[M].上海:上海交通大学芯片7与系统研究中心.2005
