基于自适应模糊神经网络的机器人路径规划方法
2012-03-13宋爱国章华涛熊鹏文
钱 夔 宋爱国 章华涛 熊鹏文
(东南大学仪器科学与工程学院,南京210096)
在机器人研究中,反应式导航是提高移动机器人在未知环境中的实时性与灵活性的重要手段.目前已提出了基于模糊控制[1-2]、神经网络[3-4]的移动机器人反应式导航方法来构建移动机器人的反应式导航控制器.神经网络因容错性强与具有自适应学习的特点,可以更好地在非结构化环境下进行感知信息的分析与融合[5],而模糊控制具有逻辑推理能力,对处理结构化知识更为有效.
然而反应式导航缺乏对环境的全局认识,易使机器人陷入局部陷阱而无法到达终点.针对这一问题,目前提出的有效方法有行为融合、虚目标[6]、沿轮廓跟踪[7]等方法.但行为融合方法需要计算各行为的权值,增加了系统复杂度; 沿轮廓跟踪方法受障碍物形状、大小影响较大; 虚目标在复杂环境下不易去除虚拟子目标及易产生冗余路径.文献[8]采用改进的虚目标方法解决复杂陷阱区域中路径往复及路径冗余问题,但其虚目标去除条件计算仍极为复杂.
本文将神经网络与模糊控制的优点相结合,融合神经网络[9]的自学习能力与模糊控制的模糊推理能力,提出基于自适应模糊神经网络的机器人导航控制器.另外,为解决反应式导航中的复杂陷阱问题,提出了一种改进型虚目标方法,该方法在较好地完成了未知环境下的移动机器人路径规划的同时,有效减少了虚目标计算的复杂性.
1 移动机器人运动学模型
本文使用美国ActivMedia Robotics 公司开发的Pioneer3 机器人为实验平台,配置16 路超声传感器检测障碍物距离,传感器均匀分布于机器人本体周围(见图1).为避免各传感器相互干扰,超声传感器分组依次循环启动,任何紧密相邻的传感器不会同时工作.在不考虑机器人后退运动的情况下,本文仅使用机器人前端8 路传感器信息.为避免镜面反射造成的测量误差,这些传感器被分为左(0~3 号传感器)、右(4~7 号传感器)2 组,每组中取最小测量值作为这一方向的障碍物距离.
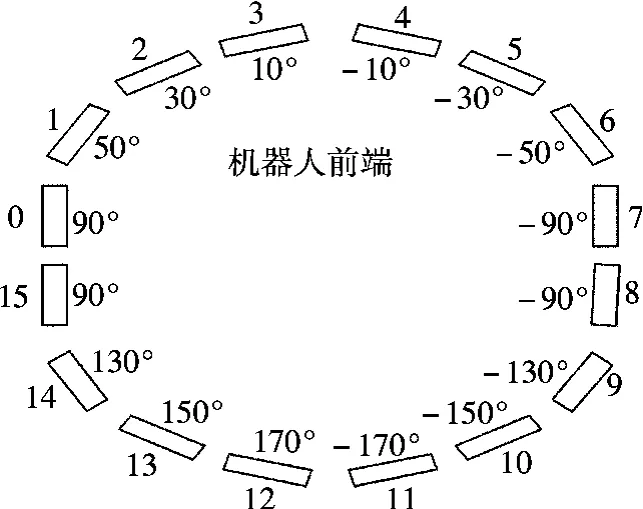
图1 超声传感器分布图
1.1 运动学模型
机器人的当前坐标为(xr,yr)[10],目标点的坐标为(xt,yt).如图2所示,E 是机器人(xr,yr)指向目标点(xt,yt)的矢量,矢量E 的模与方向角分别为

式中,En为机器人在目标距离势场中的势能;φn为当前机器人与目标点的夹角,根据机器人当前位置不断修正,始终指向目标位置;下标n 为时刻.

图2 移动机器人运动学模型
1.2 扰动规则
在反应式导航[11]中,移动机器人根据传感器信息进行局部路径规划.一般分为趋向目标行为与避障行为.在行进中,若周围没有障碍物,机器人朝目标点以φ 角度前进.当前方有障碍物时,则需人为加入一个扰动噪声δ,机器人需无碰撞趋向目标,由此建立如下等式:

式中,φn为移动机器人预瞄准方向;k 为比例系数;δn为加入的扰动噪声大小,其值由自适应模糊神经网络控制器根据机器人当前所处的环境确定.
当δn=0 时,机器人朝向目标位置前进; 当δn≠0 时,移动机器人将按照附加扰动偏移后的目标方向前进.
1.3 速度模型
移动机器人在导航任务中的速度由机器人本体与周围障碍物之间的距离决定.当在空阔地行驶时,机器人全速前进,当遇到障碍物时减速行驶.其计算公式如下:
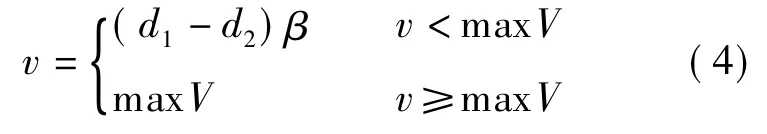
式中,v 为机器人速度;d1为机器人距障碍物距离;d2为机器人紧急停止距离; β 为速度比例系数;maxV 为设定的机器人最大行驶速度.
2 自适应模糊神经网络控制器
2.1 模糊神经网络结构
本文利用神经网络引入学习机制,为模糊控制器自动提取模糊规则及模糊隶属函数,使整个系统成为自适应模糊神经网络系统.其样本数据是基于实际训练的数据,客观地反映了输入参数与待预测变量的非线性关系,减少了逻辑推理工作量.采用的自适应模糊神经网络的结构为5 层ANFIS 网络,构建Takagi-Sugeno 型模糊推理系统.其结构如图3所示.为降低系统复杂性,本文选择2 输入1输出系统,输入数据为移动机器人左右两边传感器采集到的障碍物距离信息,输出为根据当前机器人所处环境增加的扰动角度,值域为[-20°,20°].5 层ANFIS 网络具体结构如图3所示.
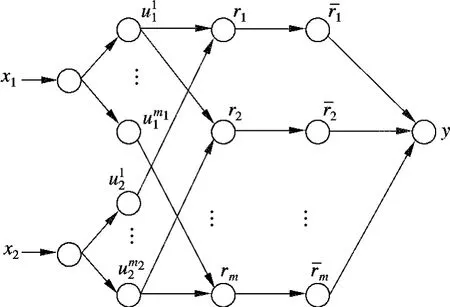
图3 自适应模糊神经网络基本结构
第1 层为输入层,该层各个节点直接与输入向量的各分量xi连接,将输入值x={x1,x2}T传送到下一层.本文中节点数为2.
第2 层中的每个节点代表一个语言变量值,该层用来计算各输入分量属于各语言变量值模糊集合的隶属函数uji,为了提高平滑度,本文选取高斯函数作为隶属度函数.以u11点为例,u11 =exp(-(x1-c11)2/σ211),c11,σ11分别为隶属函数的中心和宽度.
第3 层中的每一个节点代表一条模糊规则,以匹配模糊规则的前件,该层将计算出每条规则的适用度.
第4 层主要是归一化计算:
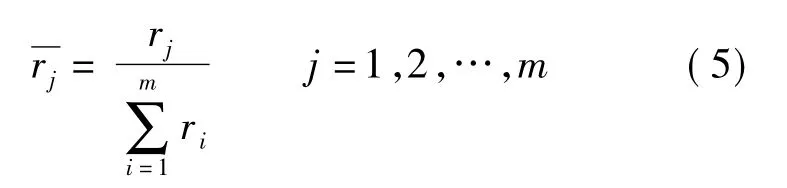
第5 层为输出层,完成去模糊化.去模糊化方法一般有平均最大隶属度法、中位数法、加权平均法等,这里选用加权平均法去模糊化.输出量为对机器人增加的扰动角度.
2.2 模糊神经网络的学习算法
模糊神经网络系统利用BP 反向传播算法和最小二乘法来完成对输入/输出数据对的建模.该方法能够从数据集中提取相应信息(模糊规则),使得生成出来的Takagi-Sugeno 型模糊推理系统能够更好地模拟出希望或是实际的输入/输出关系.模糊神经系统在学习时,根据系统实际输出值与期望输出值可以计算出学习误差,再通过误差反向传播对系统参数进行调整.其调整的系统参数主要为权值w、高斯函数中心c 与宽度σ.设学习误差函数为

式中,ti与yi分别为期望输出与实际输出.
学习过程中对参数的调整方法为
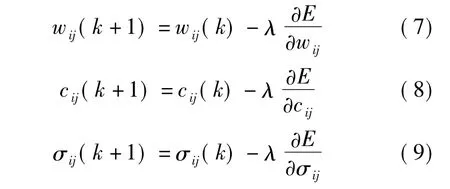
式中,k 为迭代次数; λ >0 为学习速率,本文中λ取0.1.
2.3 训练结果
由于反向传播算法需要用到各个神经元[12]传输函数的梯度信息,当神经元的输入太大时,相应的该点自变量梯度值就过小,无法顺利实现权值和阈值的调整.因此在进行训练前,需要对输入参数进行归一化处理,以保证收敛性.
本文训练的自适应神经模糊系统2 输入隶属度函数均为高斯函数,其输入隶属度函数个数均为5,训练次数为400.
如图4所示,机器人距左边障碍物距离取分布在机器人前端的超声传感器0~3 号中最小测量值.机器人距右边障碍物距离取分布在机器人前端的超声传感器4~7 号中最小测量值.图4(b)为训练后的隶属函数.输出结果为根据当前机器人所处环境增加的扰动角度,值域为[-20°,20°],是模糊量,非量化值.
图5为神经网络训练误差,在训练400 次后,误差值已降至0.073°以下.
3 虚目标方法
3.1 导航状态
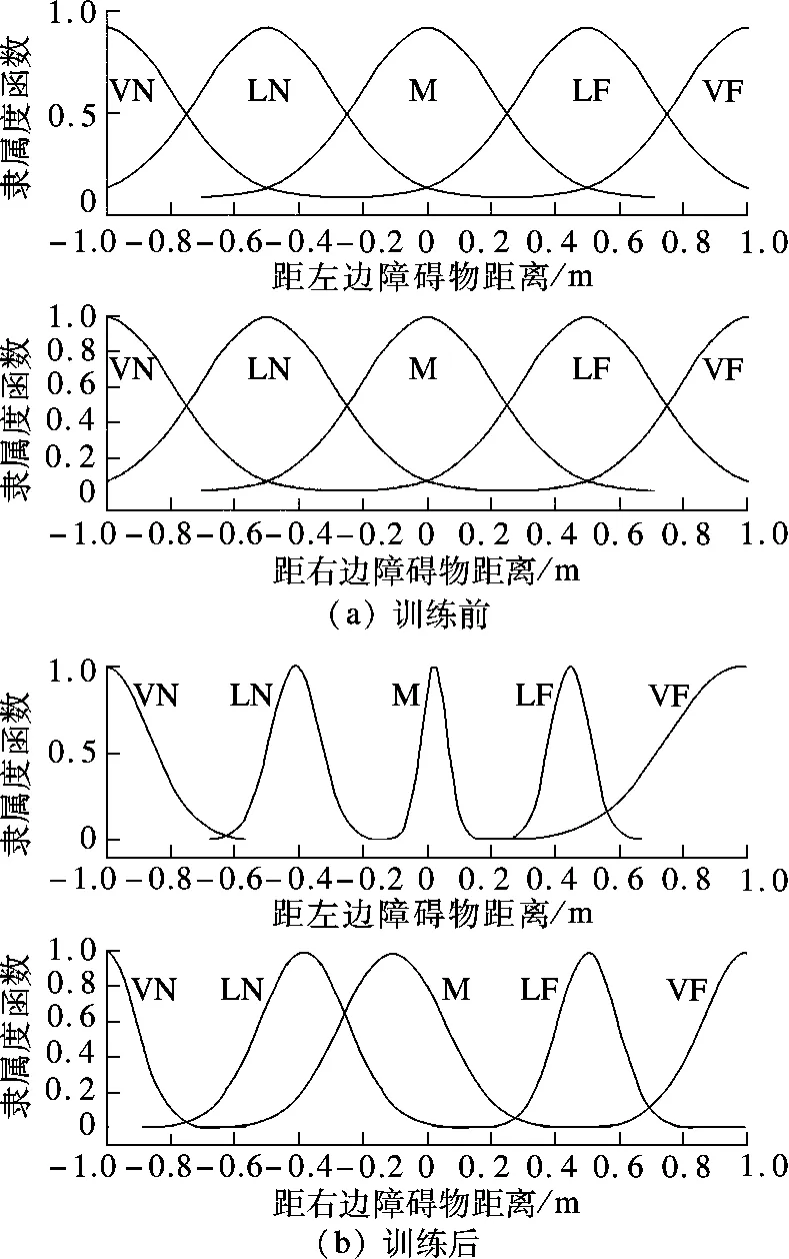
图4 训练前后输入隶属度函数

图5 训练误差
反应式导航可根据机器人当前的环境信息采取相应的动作,提高了机器人在未知环境下的实时性与灵活性.但反应式导航只能达到局部最优,不能累积达到全局最优,因而在复杂环境下易陷入路径循环反复状态,即陷阱状态.机器人在朝目标点移动时,经常遇到的障碍物情况有4 种,如图6所示.在导航过程中,机器人所处环境都可以由以上4 种状态组合构成.
3.2 改进型虚目标建立规则
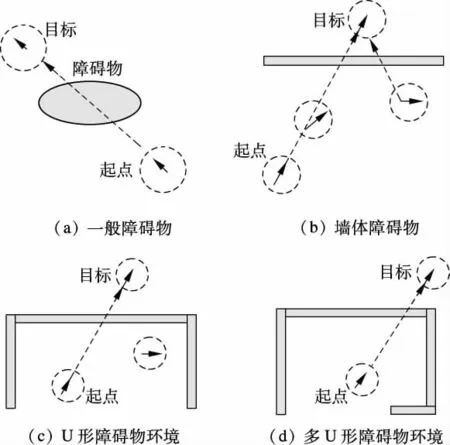
图6 机器人导航任务中的几种典型环境
以图6(b)为例,机器人朝右上方目标移动,根据式(3)确定移动机器人预瞄准方向.其中δn是本文构建的自适应模糊神经网络系统输出,值域为[-20°,20°],负数表示机器人向右边扰动量的增加,正数表示机器人向左边扰动量的增加.机器人越靠近障碍物,δn绝对值越大.当前方没有障碍物时,δn=0,移动机器人预瞄准方向φn=φn,当机器人逐渐接近障碍物时,φn随之减小,在距障碍物某一距离时φn减小为0,即机器人沿着障碍物行进;当机器人运动至目标的右下方时,φn值域为[90°,180°),本文中k 取9 时,沿φn方向仍能继续前进.可以得出机器人只要在前进方向上不同时被2 个方向的障碍物阻挡时,总能到达目标点,这种情况下无需建立虚目标.
为减小传统虚目标方法可能会造成的路径冗余问题及复杂的条件计算,本文提出虚目标递变的方法.即虚目标坐标根据移动机器人当前所处位置进行小范围调整,以期能摆脱陷阱状态,当在朝虚目标行进方向受阻时,再对虚目标进行调整,最终完成对目标点的导航.本方法优势在于只要在机器人行进方向上不同时出现2 个方向的障碍阻挡,机器人都能沿φn=φn+kδn方向通过,若同时出现2个方向的墙体障碍物阻挡,根据机器人当前所在位置决定虚目标的坐标,无需使用传统方法进行角度换算及去除虚目标等复杂运算,给设计人员减轻了负担,其中δn需要自适应模糊神经网络控制器输出.
本文中虚目标的建立以优先选择机器人可能逃脱陷阱状态的路径为原则.如图7所示,当机器人向目标点运动时,如果前方不同时出现2 个方向上的墙体障碍物,机器人能自行调整角度无碰撞趋向目标点.当前方出现2 个方向上的墙体障碍物,机器人应尽量越过其中一个障碍物,且方向与目标点方位不同.以图7(a)为例,目标点在机器人右上方,机器人朝右上方移动,当右前方同时出现墙体障碍物后,机器人优先选择可能逃脱陷阱状态的路径,即越过右方墙体障碍物,则虚目标建立在机器人右下方.图7(b)表示目标点在机器人右下方时,虚目标建立在机器人左下方,以此类推得到机器人建立虚目标规则.

图7 虚目标建立规则
4 实验结果
本文使用美国ActivMedia Robotics 公司开发的Pioneer3 机器人为实验平台,搭建测试环境(见图8).

图8 实验环境
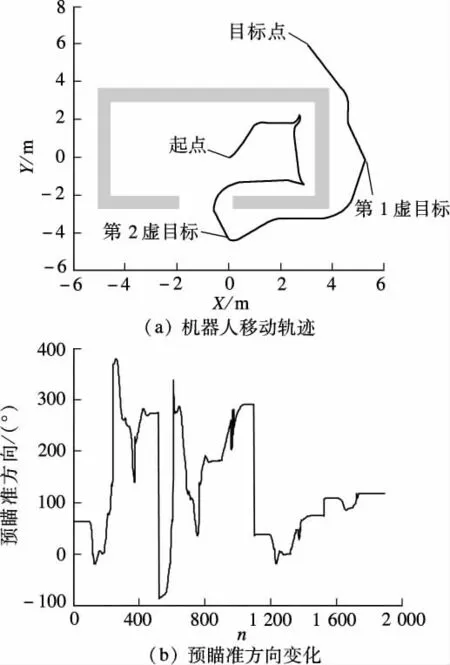
图9 多U 形墙体障碍物环境
如图9所示,当移动机器人从起点向目标移动时,面对第1 堵墙壁时沿φn方向前进,遇到第2 堵墙时,通过建立虚目标方式,引导机器人朝可能存在出路的方向前进,以此类推,直至机器人成功到达目标点.
图10为更加复杂的多U 形障碍物环境,移动机器人根据自适应模糊神经网络控制器的输出实时调节机器人预瞄准方向,并成功到达目标点.
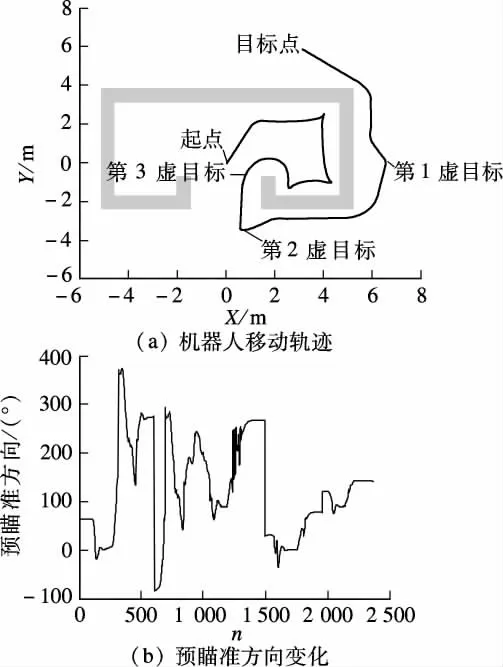
图10 复杂多U 形墙体障碍物环境
文献[6]提出基于目标切换的方法来解决反应式导航中的陷阱问题,设定陷阱状态检测条件和脱离条件,当检测条件满足时,引入虚拟子目标代替实际目标进行局部路径规划,直到脱离条件满足并恢复实际目标.但在复杂环境如多U 形区域,多次引入虚目标后,最终的虚目标与实际目标重合,文献[6]中的脱离条件“发现开放点”会导致实际目标没有在正确的位置恢复,从而无法真正脱离陷阱区域.文献[8]采用目标方向变化作为虚目标引入、去除条件,并建立目标栈判断陷阱区域,从而在合理的位置恢复实际目标,使机器人有效脱离复杂陷阱,但引入条件与去除条件由多规则限定.以图10为例,机器人在复杂多U 形障碍物环境中导航,文献[8]对于复杂多U 形陷阱环境,虚目标引入条件多次出现,在原有虚目标未去除之前,新的虚目标产生,形成先入后出的目标栈,栈底为实际目标.机器人需不断计算虚目标建立次数及建立条件,根据栈的状态得到机器人当前位置信息,计算复杂.
本文优势在于只要在机器人行进方向上不同时出现2 个方向的障碍物阻挡,机器人都能沿φn方向趋向目标点.如图9、图10所示,若出现2 个方向的阻挡,根据机器人优先选择可能逃脱陷阱状态的路径为原则决定虚目标的坐标,无需使用传统方法进行角度换算及去除虚目标等复杂运算,给设计人员减轻了负担,且总能沿着可能到达目标点的方向移动,有效避免了路径冗余.
由图9、图10可见,该方法可以帮助机器人在全局信息未知的复杂环境中导航,趋近目标点的过程中能有效避障,无冗余路径产生,且轨迹平滑,具有实用性.
5 结语
本文将神经网络与模糊控制的优点相结合,融合神经网络的自学习能力与模糊控制的模糊推理能力,提出基于自适应模糊神经网络的机器人导航控制器,构成2 输入1 输出的Takagi-Sugeno 型模糊推理系统,减少了逻辑推理工作量.输入为机器人距左右两边障碍物距离信息,输出为机器人的扰动角度.同时,为了解决传统反应式导航中的复杂陷阱问题,提出了一种改进型虚目标方法,机器人能沿φn方向趋向目标点,利用简单的虚目标建立规则使机器人能够摆脱陷阱状态,降低了计算复杂度.
References)
[1]Chiu S L.Fuzzy model identification based on duster estimation[J].Journal of Intelligent and Fuzzy systems,1994,2(3): 267-278.
[2]Wang M,Liu J N K.Fuzzy logic-based real-time robot navigation in unkown environment with dead ends[J].Robotics and Autonomous Systems,2008,56(7):625-643.
[3]乔俊飞,樊瑞元,韩红桂,等.机器人动态神经网络导航算法的研究和实现[J].控制理论与应用,2010,27(1): 111-115.
Qiao Junfei,Fan Ruiyuan,Han Honggui,et al.Research and realization of dynamic neural network navigation algorithm for mobile robot[J].Control Theory and Application,2010,27(1): 111-115.(in Chinese)
[4]Er M J,Gao Y.Robust adaptive control of robot manipulators using generalized fuzzy neural networks[J].IEEE Transactions on Industrial Electronics,2003,50(3): 620-628.
[5]Wang J S,Lee C S G.Structure and learning in selfadaptive neural fuzzy inference systems[J].International Journal of Fuzzy Systems,2000,2(1): 12-22.
[6]Xu W,Tso S.Sensor-based fuzzy reactive navigation of a mobile robot through local target switching [J].IEEE Transactions on Systems,Man and Cybernetics,1999,29(3): 451-459.
[7]Toibero J M,Roberti F,Carelli R.Stable contour-following control of wheeled mobile robot[J].Robotica,2009,27(1): 1-12.
[8]刘宏林,罗杨宇,李成荣.基于模糊控制器的未知环境下移动机器人导航[J].计算机仿真,2011,28(1):201-205.
Liu Honglin,Luo Yangyu,Li Chengrong.Fuzzy controller for mobile robot navigation under unknown environments[J].Computer Simulation,2011,28(1):201-205.(in Chinese)
[9]István E,Gábor H.Artificial neural network based mobile robot navigation[C]//Proceedings of 6th IEEE International Symposium on Intelligent Signal Processing.Budapest,Hungary,2009: 241-246.
[10]张惠娣,刘士荣,俞金寿.基于动力学系统方法的自主移动机器人行为设计[J].华东理工大学学报: 自然科学版,2008,34(6): 843-849.
Zhang Huidi,Liu Shirong,Yu Jinshou.Designing behaviors of autonomous mobile robots based on dynamical system approach[J].Journal of East China University of Science and Technology: Natural Science Edition,2008,34(6):843-849.(in Chinese)
[11]蔡自兴,贺汉根,陈虹.未知环境中移动机器人导航控制研究的若干问题[J].控制与决策,2002,17(4):385-390.
Cai Zixing,He Hangen,Chen Hong.Some issues for mobile robots navigation under unknown environments[J].Control and Decision,2002,17(4): 385-390.(in Chinese)
[12]王永骏,涂键.神经元网络控制[M].北京:机械工业出版社,1998:204-207.
